开域聊天机器人技术介绍(现实篇)
Posted Chatbots技术与产品
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开域聊天机器人技术介绍(现实篇)相关的知识,希望对你有一定的参考价值。
微软小冰是最“成功”的开域聊天机器人,应该也是跟最多人聊过天的机器人吧,它的架构和技术水平也基本可以认为是工业界的SOTA。不论是百度小米阿里toC的音箱,还是爱因互动等toB企业为客户定制的商用对话机器人,内部使用的技术架构都和小冰类似。当然,架构高度雷同的原因并不是其他企业都参考了小冰的架构设计,而是这套技术框架是实用聊天机器人目前唯一可行的架构。接下来我们就以小冰为例来细说目前实用聊天机器人使用的架构和技术。
本文以下内容主要参考小冰团队发表的这篇文章:“The Design and Implementation of XiaoIce, an Empathetic Social Chatbot, Li Zhou et al., Microsoft”。
小冰的这篇文章是18年12月份放出来的,文章把对话机器人的构建思路和小冰的整体结构都讲的非常清楚。按照这个流程就可以自己从0开始构建一个“工业级”对话机器人。
小冰的设计理念是让机器人具备 IQ + EQ + Personality的能力。
IQ就是智商,指能做很多事,有很多技能。
EQ是情商,主要指对话答复要考虑到对方的情绪和兴趣,也即常说的“会聊天”。用户难过就要安慰鼓励他,高兴就要陪着高兴。
Personality是指小冰的答复要符合小冰的人设。小冰的人设是可靠、有同情心、有爱心、有幽默感的18岁少女。所以她说的话不能偏离这个人设。
小冰的优化目标是用户长时间段内的session对话轮次:Conversation-turns Per Session (CPS) 。优化过程会使用增强学习EE策略,探索已知好的策略的同时,也会去尝试未知效果的策略。
数据统计2014年5月发布
使用情况
至2018年5月:使用历史包含了 300亿个qr对
至2018年7月:6.6亿用户
小冰已发布了 230 个技能
覆盖大概 80 个IoT设备,涉及约 300 个场景
最长聊天记录

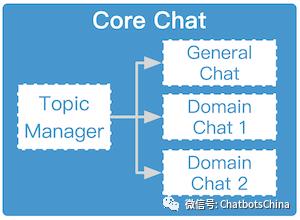
小冰的能力包含两大块:核心闲聊(Core Chat) 和各类技能(Skills)。核心闲聊就是一般的闲聊(开域聊天)。而技能是小冰在某些方面的能力,如天气咨询、讲笑话、看图作诗等等。整个系统结构如下图:
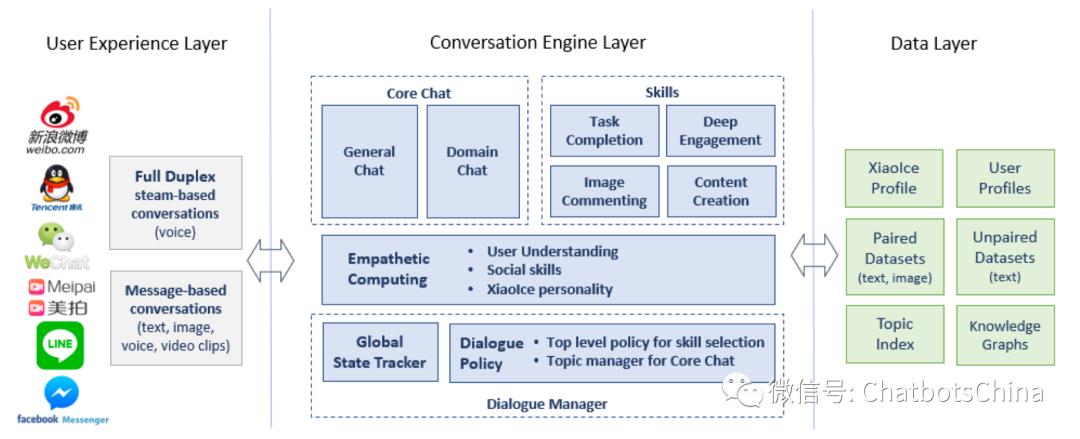
上面的图看不出系统整体流程,所以我又重画了一个:
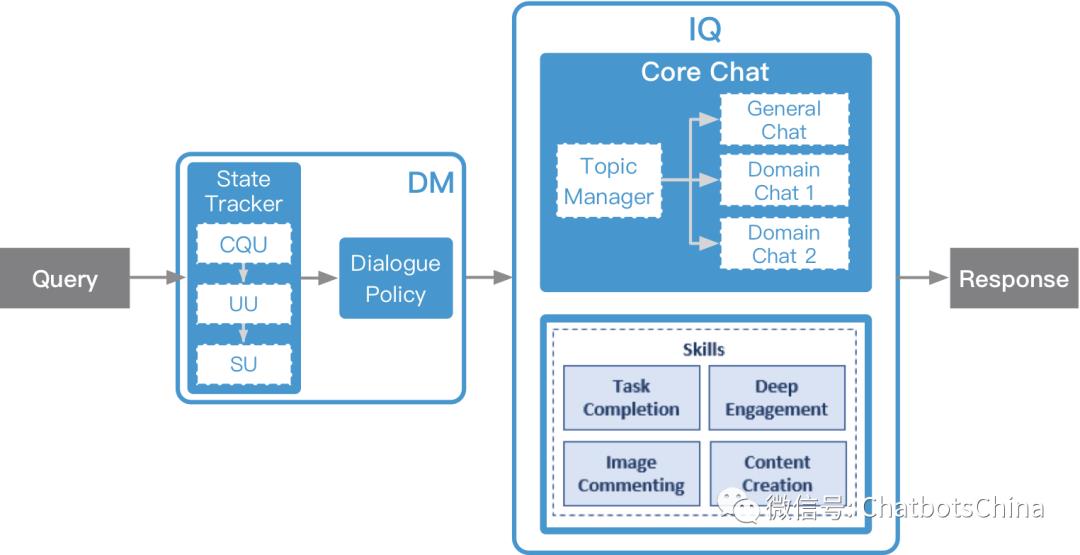
其中DM是对话管理模块,而IQ则是小冰的各种技能库。DM决定当前query交给IQ中的哪个技能处理,对应的技能产生答复返回给用户。
这个结构和爱因的 DeepBot 架构(见下图)是类似的。都有一个总控(DM vs RouteBot)决定把当前对话分配给哪个(些)技能,技能也都采用了可插拔的设计。
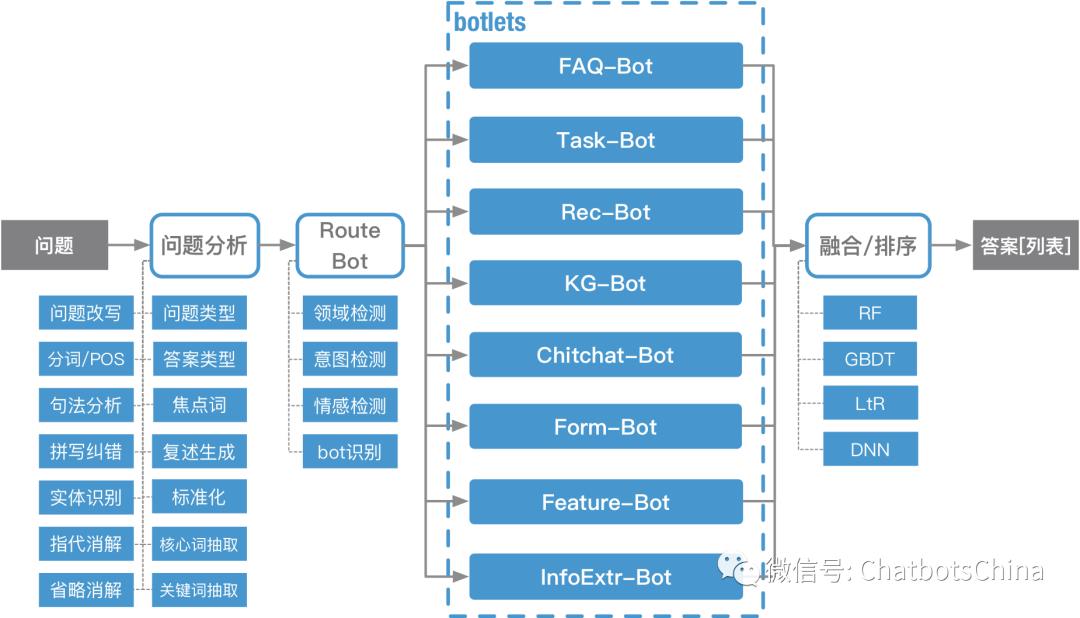
DeepBot架构稍微复杂灵活一些。DeepBot中每次query可以并行由多个技能响应,也可以串行循环被多个技能响应。技能能够更新全局的对话状态,保证对话状态在不同技能之间共用流动。DeepBot流程前面的问题分析模块也会对用户query做更细致的分析。
但小冰的闲聊技能比爱因的闲聊技能(Chitchat-Bot)强大很多。这也是由于小冰和爱因要解决的对话问题截然不同所导致的。
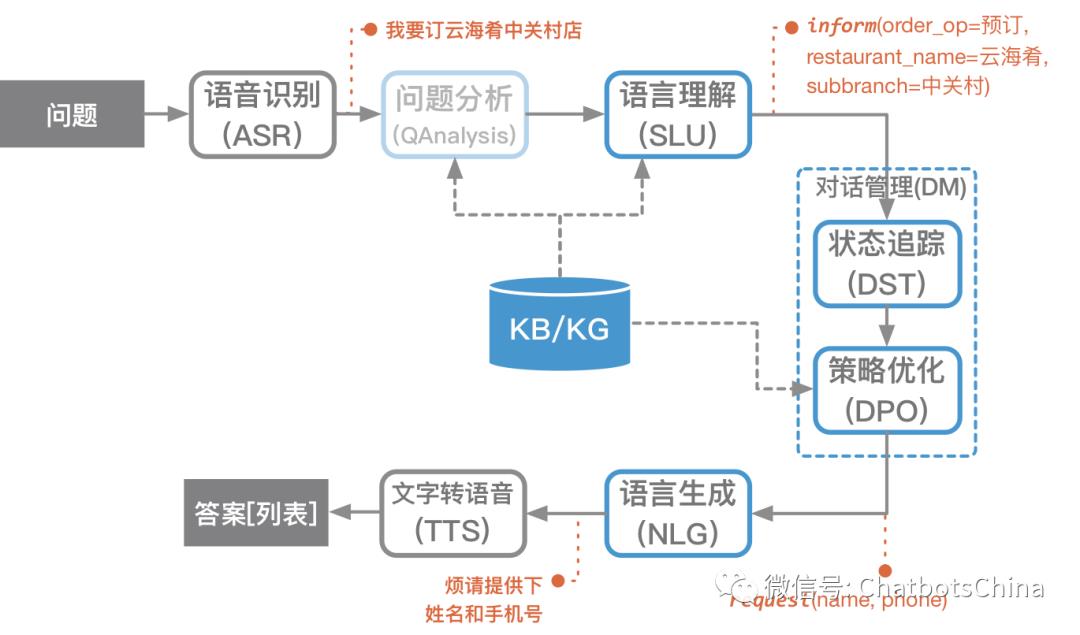
对话管理(Dialogue Manager)当收到用户的对话信息后,系统会经过一个对话管理的模块,对话管理模块有两个功能:状态追踪模块(Global State Tracker) 更新系统状态 s,对话策略模块(Dialogue Policy) 依据更新后的对话状态来决定接下来的策略 π(s),也即决定这个信息是交由核心闲聊还是某个技能来回答。激活某个功能后,这个功能也会有自己的对话策略或者流程,来最终决定返回什么信息作为回复。
这是典型的对话管理模块的结构,常在任务型对话机器人中被使用和强调。
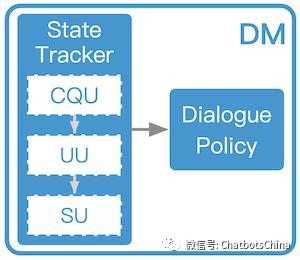
对话状态追踪
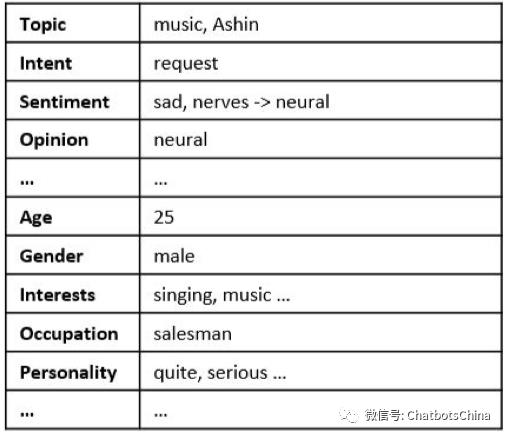
对话状态 s由四部分组成:s=(Q_c, C, e_Q, e_R),其中 C 表示对话背景,Qc 是利用 C对用户当前用户query Q 进行改写后的版本。而 e_Q 存储了用户相关的各种信息,如当前情绪、对话题的观点(兴趣读)、长期的兴趣爱好、个人资料等。e_R 和 e_Q 有类似的结构,只是存储的是小冰的信息。
作者把计算 s=(Q_c, C, e_Q, e_R) 的过程,称为同理心计算(Empathetic Computing)。同理心计算包含三个步骤:带背景query理解、用户理解和系统理解,分别对应 Q_c、e_Q、e_R的产生过程。
带背景query理解(Contextual Query Understanding (CQU))
CQU利用背景信息 C 对用户当前消息 Q 进行改写,得到 Q_c。改写的步骤包括:
实体链接:识别出 Q 中的实体,并与之前的状态中存储的实体进行链接(就是对上号)。
指代消解:把 Q 中所有代词替换为它们指代的实体。
句子补全:如果 Q 不是一个完整的句子,就使用 C 对它进行补全。
下图是论文中给出的一个示例:

用户理解(User Understanding (UU))
UU 基于 Q_c 和 C 产生 e_Q。e_Q 是有一系列kv对组成的,其中包括:
话题记录了用户当前对话的话题。
意图存储的是用户当前对话的动作,如greet,request,inform等。就是任务型对话NLU中的动作(act)。
情感记录了用户当前的情绪,如高兴,伤心,生气,中立等。
观点存储了用户对当前话题的观点,如正向,负向,中立。
如果用户可辨认,可以获取到他的个人资料,如年龄,性别,兴趣,职业等。
下图是论文中给出的一个示例(对应CQU中的示例):
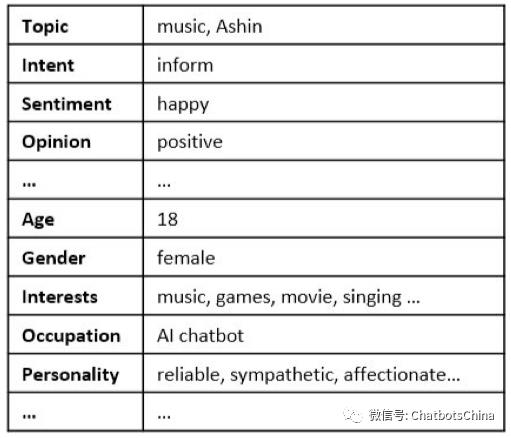
系统理解(System Understanding (SU))
SU 就是为了产生 e_R 向量。(原文中不叫这个名字,而是 Interpersonal Response Generation。)
UU完成后,SU就比较简单。有些和UU相同的信息直接从UU拷过来即可,如话题。有些基于小冰的人设,就可以知道,如情感和观点永远是正向的,个人资料也都是设定好固定不变的。
下图是论文中给出的示例(对应CQU和UU中的示例):
对话策略
对话策略模块(Dialogue Policy) 依据更新后的对话状态来决定接下来的策略 π(s),也即决定这个信息是交由哪个功能处理,是核心闲聊还是某个技能。激活某个功能后,这个功能也会有自己的对话策略或者流程,来最终决定返回什么信息作为回复。作者称这个决策过程为分层决策(Hierarchical Dialogue Policy)。
优化过程会使用RL模型和EE策略,探索已知好的策略的同时,也会去尝试未知效果的策略。
本文没提具体细节,但作者之前的一些工作专门在说这个事。除了RL,当然也可以用其他更简单的方法,如启发式规则,单轮分类,或者多轮分类等。
核心闲聊(Core Chat)核心闲聊(Core Chat)面向开域对话,它还会分为两类:通用闲聊(General Chat)和领域闲聊(Domain Chat)。通用闲聊主要回答一般性的信息,而领域闲聊主要是回答某些带主题的闲聊,例如”你喜欢王菲的歌么“、”全聚德的烤鸭味道怎么样“。
话题管理(Topic Manager)
核心闲聊中有一个重要的模块,叫话题管理模块(Topic Manager) 。话题管理模块包含一个分类模型,来决定小冰是继续当前话题聊下去,还是开启一个新话题。
什么时候该开启新话题?比如小冰发现她没法产生一个有意思的回复信息,或者用户对当前对话感觉无聊了:
核心闲聊使用了设定好的处理异常情况的编辑回复。
产生的回复信息只是简单重复用户的输入,或者没包含什么新信息量。
用户开始给出灌水性的回复,如“嗯”,“哦”,“呵呵”,“知道了”等。
如果要开启一个新话题,系统会从话题库中找出一个新话题。话题库是利用一些高质量的论坛(如Instagram和豆瓣)爬取的数据构建起来的。
选择新话题的流程是典型的 检索 + 排序过程。检索使用当前的对话状态 s,排序使用了boosted tree模型,主要基于以下类型特征:
与背景信息的相关性:新话题要与对话背景相关,且还没被使用过。
新鲜度:新话题要够新鲜,在当前时间点讨论要比较合适。
用户感兴趣:用户要对新话题感兴趣。
流行度:网上或者小冰用户中热议的话题。
接受度:从历史数据上可以知道小冰用户对此话题的接受度。
利用话题管理模块,对话就可以在通用闲聊和领域闲聊之间切换。通用闲聊和领域闲聊使用了相同的框架,只是数据不同。所以论文中以通用闲聊为例做了具体介绍。
通用闲聊(General Chat)
通用闲聊的整体流程也是 检索 + 排序,流程图如下:
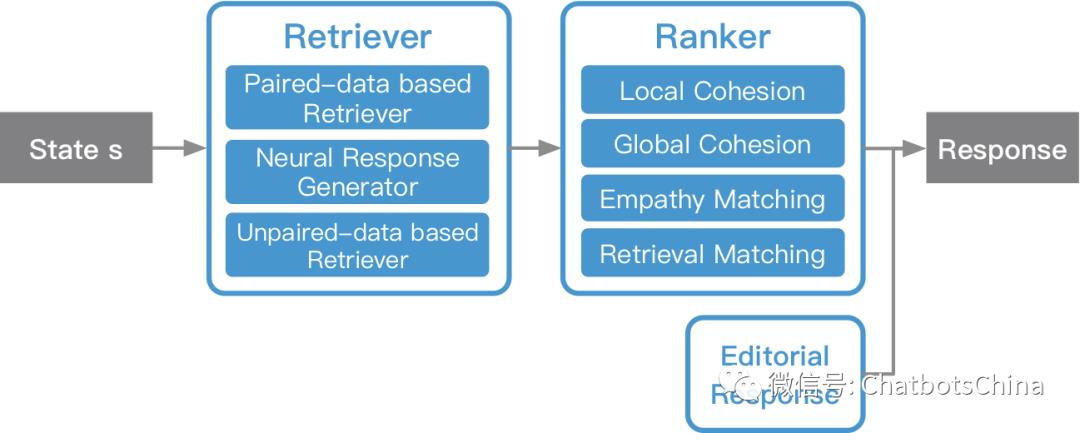
检索主要是产生response候选集,这些候选集再由排序模块进行排序。小冰有三种候选集产生方式,下面分别介绍。
检索
1. Paired-Data based Retriever (PDR)
系统收集了很多 query-response 对,此检索器就是从这些qr对中检索出最相关的一些候选。这些qr对来自两个方面:1) 从网上各种平台(社交网络、论坛、公告栏、新闻评论等)爬取的数据;2) 从小冰的使用日志中挖掘。时至今日,小冰 70%的回复是从她的聊天历史中获得的。
获得的qr对首先用同理心计算模块转化成 (Q_c, R, e_Q, e_R) 的形式。然后基于小冰的人设和其他规则过滤掉不合适结果。剩下的qr对就作为知识存入Lucene供线上使用。
线上使用时,Q_c 作为检索输入,然后利用关键词搜索和语义搜索从候选库中检索出 400个最相关的qr对。
PDR产生的response效果很好,但覆盖面比较小。
2. Neural Response Generator (NRG)
NRG使用了标准的GRU-RNN seq2seq框架,训练数据就是上面收集到的qr对。输入上除了使用 Q_c 外,还会使用到 e_Q和 e_R。先使用以下方式把 e_Q 和 e_R 合并为 v:
v=σ(W^T_Q e_Q+W^T_R e_R)
然后把 v 注入到解码器的每个时间点。模型结构如下图。
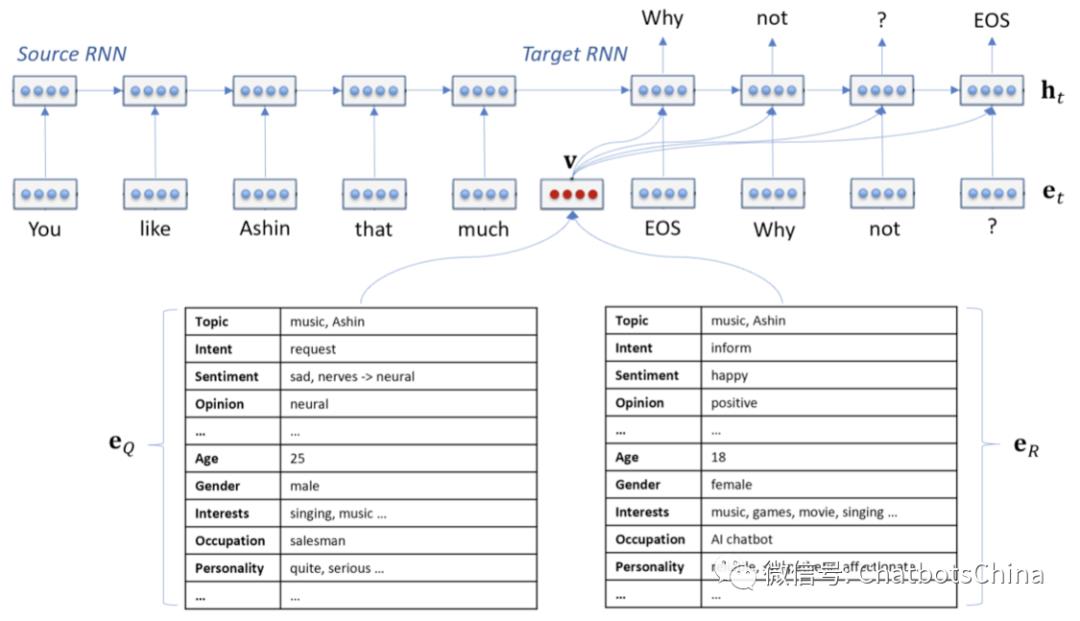
NRG使用 beam search 产生 20 个候选response。
NRG产生的response覆盖面广,但效果较差,生成的response一般会比较短。
3. Unpaired-Data based Retriever (UDR)
除了PDR中从网上爬取的qr对信息,网上有更庞大的unpaired数据。作者从网上的公开演讲和新闻报道的引用(双引号扩起来的那种)中搜集unpaired句子。所以这些句子是谁说的我们是知道的,这样就可以计算 e_R。
然后基于小冰的人设和其他规则过滤掉不合适结果。剩下的数据存入Lucene供线上使用。
和PDR不同的是,UDR中只有候选response数据,而没有对应的候选query数据。所以线上使用光靠用户queryQ_c 是无法确定哪些候选response更合适的。q跟r之间需要一个桥梁。作者的解决方案是引入知识图谱(KG)来搭起这座桥。
微软自己有个很大的KG叫Satori,用于对话只需要其中的一部分就好。作者使用PDR中搜集的qr对数据集来进行筛选。如果Satori中的一个三元组 head-relation-tail (h, r, t) 中的 h 和 t 分别在qr对中 q(Q_c)和 r(R)出现的次数超过指定的阈值,才保留这个三元组。所谓 h 在 q 中出现,是指 q 中包含了 h 这个话题。例如下图是保留KG的一个片段。
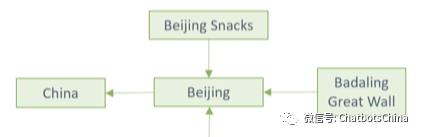
线上使用时,小冰会利用前面构建的KG对用户的query Q_c 进行话题扩展,具体步骤如下(以query “Tell me about Beijing”为例):
识别出 Q_c 中包含的所有话题。本句query中只有“Beijing”一个话题。
对于每个话题,从KG中检索出
20个最相关的话题。如 “Badaling Great Wall” 和 “Beijing snacks”。最相关是利用 boosted tree 模型排序得到的,模型的训练数据是人为标注的。query中的所有topic和上一步检索出的相关topic一起作为检索输入,从收集的unpaired数据集中检索出
400个最相关的句子作为候选response。例如:“Beijing’s Badaling Great Wall is best known in the Ming Great Wall, and it can be overlooked from Guanritai.” 和 “When you come to Beijing, you must try authentic Beijing snacks. There are always a few that you like.”。
UDR的候选质量没有PDR好,但加入UDR后话题覆盖面要广很多。UDR的结果也比NRG生成的结果包含更多文字。
排序
PDR、NRG和UDR生成的所有候选response,利用 boosted tree 模型统一进行排序。最终的response是从那些排序分值高于设定阈值的responses中随机选出来的。这样可以保证小冰的结果不会一成不变,更有“人性”。
给定状态 s=(Q_c, C, e_Q, e_R) ,模型基于以下几类特征为每个 R′ 计算一个排序分数:
局部凝聚力(Local Cohesion) 特征:R′ 要与 Q_c 语义一致。R′ 与 Q_c 之间的局部凝聚力分数通过语义匹配模型DSSM计算得到。DSSM的训练数据来自历史对话qr对。
全局凝聚力(Global Cohesion) 特征:R′ 要与 Q_c、C 语义一致。R′ 与 (Q_c, C) 之间的全局凝聚力分数通过另一个语义匹配模型DSSM计算得到。DSSM的训练数据来自历史对话session。
同理心匹配(Empathy Matching) 特征:好的 R′ 应当符合小冰的人设。可以把 R′ 当作query,(C, Q_c) 作为背景,通过同理心计算模块中的 CQU 和 UU 计算得到 e_R’。然后再把
检索匹配(Retrieval Matching) 特征:这类特征仅用在 PDR 产生的候选response上。记与候选responseR′ 对应的q为 Q′。可以利用各种方法计算 Q_c 与 Q′ 的匹配分数,如BM25、Tf-Idf、或者各种意义匹配方法如DSSM等。
排序模型的训练数据是 (s, R) 对集合。为每个 (s, R) 标注一个 0~2 的分数值。0表示 R 不相关;1表示还行,可接受;2表示很合适。
编辑回复(Editorial Response)
编辑回复即所谓的异常时兜底回复,或者默认回复。当前面的机制没法产生回复时,编辑回复就会作为最终回复返回给用户。小冰的编辑回复期望能让对话继续下去,所以通常不会用“I don’t know”这种话术,而会更倾向于类似“Hmmm, difficult to say. What do you think?”这种。
对话技能(Skills)技能又分为这几类: 图片评论(Image Commenting) ,内容创建(Content Creation),互动(Deep Engagement) 和 任务完成(Task Completion)。到目前为止,小冰已发布了 230 个技能,基本一周发布一个新技能的节奏。
多个技能如果同时被触发,则会有个排序过程,最终把query分给分数最高的技能。排序会用到设定好的技能优先级,技能confidence和session context。
图片评论(Image Commenting)
图片评论指的是用户发了一张图,然后小冰看图回话。整体架构类似通用闲聊,先用检索和生成的方式产生候选response,然后再对候选结果做排序。
图片评论和一般的图片描述略有不同,它需要让结果文字更适合对话场景。从论文中给出的下图可以看成差异。所以它不仅会使用图片中识别出的对象,还会使用图片中展示出的事件、动作、情绪(如竞技、赢)。

Retrieved-based Retriever (RR)
RR 首先从社交网站上收集(图片,评论)对。然后线上一张新图片来了以后,首先把它向量化(CNN等各种模型都行),然后从库中检索出 3 张与之最相似的候选图片,它们对应评论就是候选评论了。
Generator-based Retriever (GR)
GR 基本就是image-to-text的结构,只是会融入对生成结果的情感和形式要求。
Ranker
排序还是用的 boosted tree 模型。和通用闲聊里排序一样,给定状态 s=(Q_c, C, e_Q, e_R) ,模型为每个 R′ 计算一个排序分数。这里的 Q_c 是图片的向量表达。模型使用的特征也类似。
内容创建(Content Creation)
小冰可以和用户一起做一些创造性的事,比如看图写诗、FM频道创建、电子书生成、儿童故事生成等。用户设定好创建条件,由小冰完成创建。
下图是论文中给出的看图写诗流程:
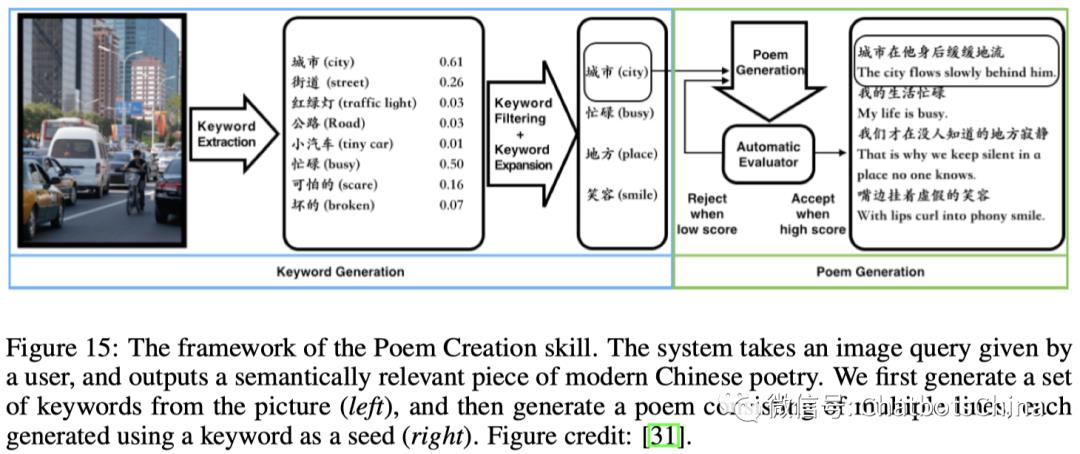
据说小冰已经出了两本诗集。
互动(Deep Engagement)
互动技能主要指小冰和用户一起做情绪或者智力方面的互动。按照一对一、多人互动,和EQ、IQ互动两个方向,可以把各种互动技能放在四个象限,如下:

任务完成(Task Completion)
任务机器人应该用的还是 Frame-based 的经典框架。这块就不再多说,值得提的是,小冰会依据用户画像给出个性化的答复。例如一个美国人问中国面积多大时,答复里的面积单位是平方英里,而中国人问答复里的面积单位是平方公里。
在答复里小冰也会尝试把对话做些延伸。比如调完灯的亮度后,再问一句亮度是否满意;回答完天气后推荐一些用户感兴趣的户外去处。
总结这篇文章详细介绍了小冰对话机器人的构建思路和整体结构。按照对应流程完全可以从0开始构建一个“工业级”对话机器人。虽然整体框架和爱因的DeepBot相似,但因为解决的目标问题不同而各有取舍。
总结几点我认为比较重要的信息:
对话状态使用了这样的结构:s=(Q_c, C, e_Q, e_R)。使用同理心计算模块计算对话状态。
使用话题管理模块决定什么时候该切换到新话题,以及切换到哪个新话题。
从互联网公开演讲和新闻报道的引用中搜集unpaird data,作为paired data的补充。
任务机器人依据用户画像给出个性化的答复。
看References,有更详细的资料。
本文最初发表在知乎专栏《智能对话机器人技术》(https://zhuanlan.zhihu.com/breezedeus)。
用机器学习打造聊天机器人 接入篇
本文是用机器学习打造聊天机器人系列的第五篇,在特性介绍中提到过,我们采用非侵入式设计,通过几个简单的 API 就可以接入聊天机器人到其他项目中,下面来看看具体步骤。
接入步骤
- 提供符合要求的领域问答语料的 txt 文件,按照意图类型划 分成不同的txt文件,替换本引擎自带的txt语料文件,txt语料文件示例如下:

可以看到,闲聊的语料文件以QA_talk-开头,业务类的以QA_sf_开头,内容的格式就如图中所示,每个问题占一行,每个回答占一行。 - 我们可以参考接口说明中的接口在自己的项目中开发自己的聊天界面或者直接使用本系列文章提供的聊天Demo页面。
接口说明
- 回复接口
用于接收用户的提问。
POST : replier/ask
参数:
{"q":"你什么星座呀?"}
响应:
(1)如果只有一个匹配项,就直接放在"a"中做为答案:
{
"a": "双鱼??~",
"c": "QA_talk"
}
(2)如果有多个匹配项,就放在"q_a_guess"中:
{
"c": "QA_sf_withdrawal_cargo",
"q_a_guess":[
"问题1?","回答1",0.95,
"问题2?","回答2",0.85,
]
} - 标注接口
本接口会让 SkyAAE 学习接收到的问答,下次问类似问题的时
候,就会给出此次学到的答案。用户标注一般分为添加新答案、
修订答案、标注最佳答案,这三类都可以调用该接口来实现。
POST : kbqa_sf/qac/record
参数:(q:问题;a:答案;c:类别)
[ {"q": "xxx", "a": "xxx", "c": "xxx"}, {"q": "xx", "a": "xx", "c": "xx"}]
响应:
"success" - 获取可选类别
GET : qac/all_classify
参数:无。
响应:
[ {"code": "QA_sf_xx1","text": "xx1"}, {"code": "QA_sf_xx2","text": "xx2"},…] - 在线学习接口
GET : qac/learn/batch
参数:无。
响应:
学习成功,返回:"success";
没有需要学习的内容,返回:"nothing"
本篇介绍了聊天机器人的接入方法,下一篇将对代码中用到的相关算法的原理做一个简单的介绍,有助于更好的理解聊天机器人的运行机制。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
以上是关于开域聊天机器人技术介绍(现实篇)的主要内容,如果未能解决你的问题,请参考以下文章