美团商品知识图谱的构建及应用
Posted 美团技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美团商品知识图谱的构建及应用相关的知识,希望对你有一定的参考价值。

总第469篇
2021年 第039篇

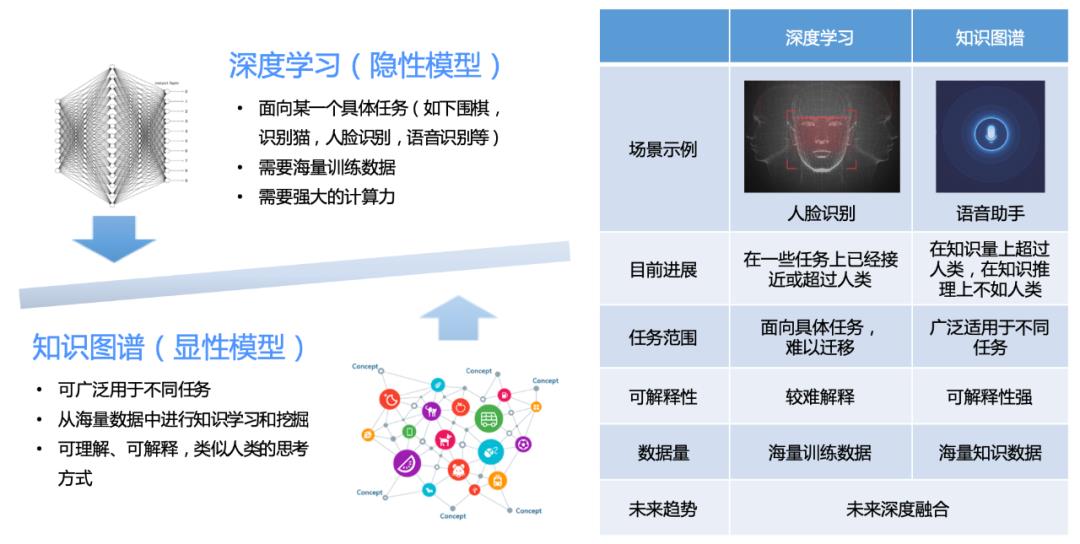
背景
美团大脑
在新零售领域的探索
商品图谱建设的目标
商品图谱建设的挑战
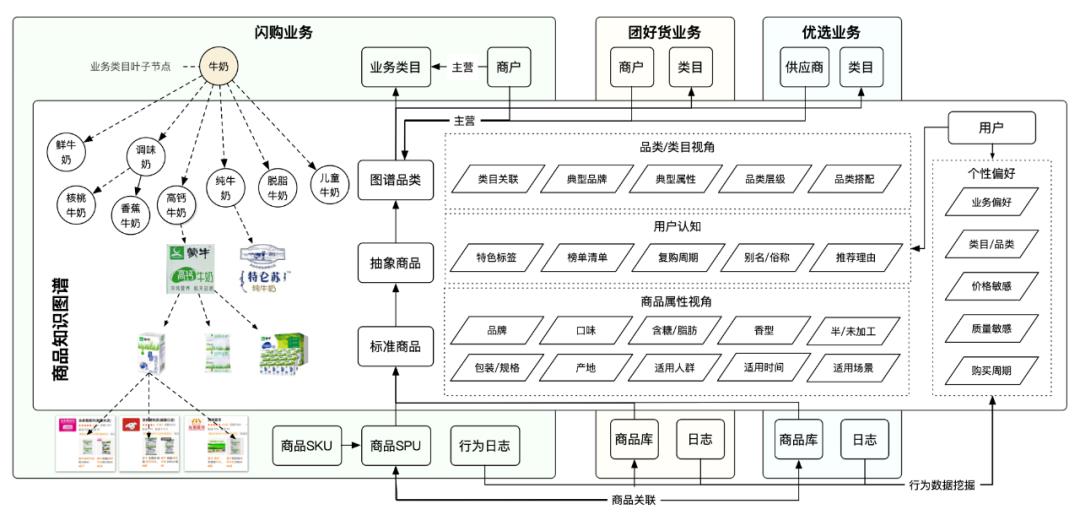
商品图谱建设
层级体系建设
属性维度建设
效率提升
人机结合-专业图谱建设
商品图谱的落地应用
结构化召回
排序模型泛化性
多模态图谱嵌入
用户/商家端优化
作者简介
招聘信息

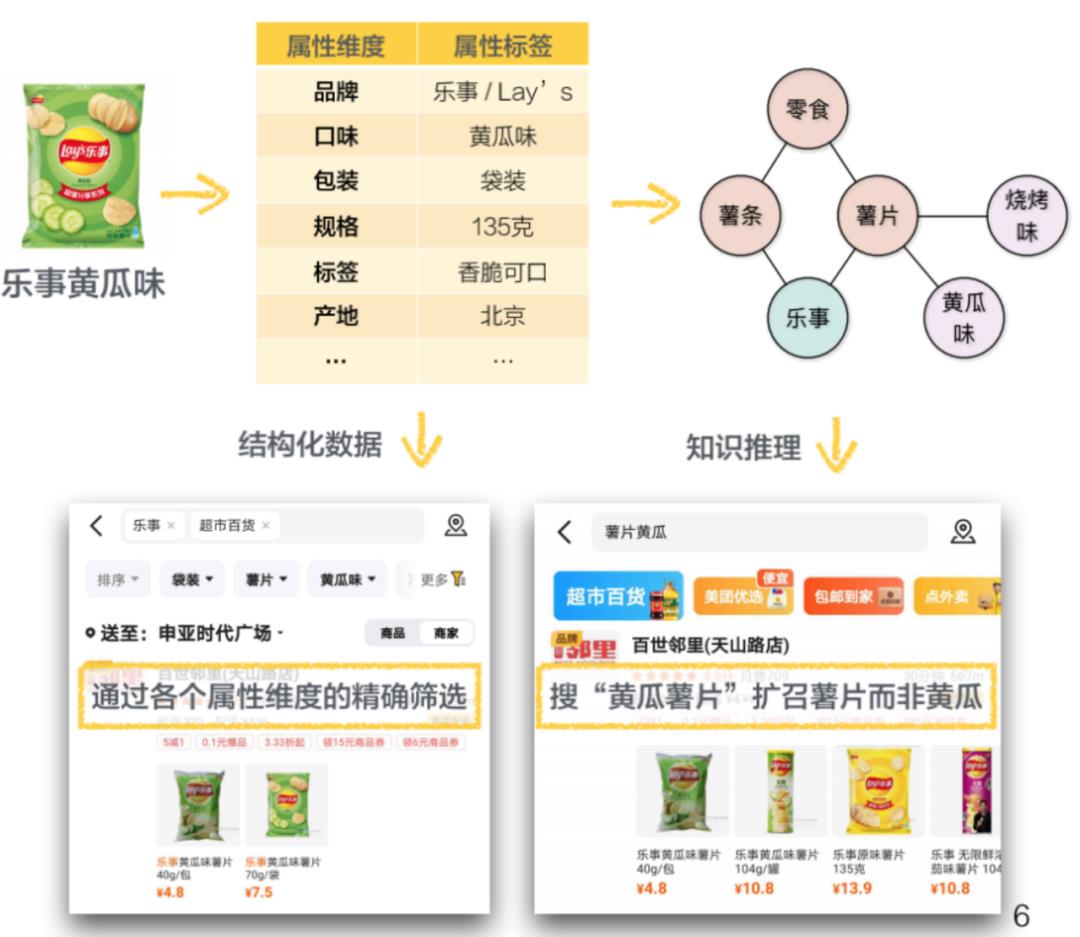
信息来源质量低:商品本身所具有的信息比较匮乏,往往以标题和图片为主。尤其在美团闪购这样LBS的电商场景下,商户需要上传大量的商品数据,对于商品信息的录入存在很多信息不完整的情况。在标题和图片之外,商品详情虽然也蕴含着大量的知识信息,但是其质量往往参差不齐,并且结构各异,从中进行知识挖掘难度极高。 数据维度多:在商品领域有众多的数据维度需要进行建设。以商品属性部分为例,我们不仅需要建设通用属性,诸如品牌、规格、包装、口味等维度,同时还要覆盖各个品类/类目下特定关注的属性维度,诸如脂肪含量、是否含糖、电池容量等,整体会涉及到上百维的属性维度。因此,数据建设的效率问题也是一大挑战。 依赖常识/专业知识:人们在日常生活中因为有很丰富的常识知识积累,可以通过很简短的描述获取其背后隐藏的商品信息,例如在看到“乐事黄瓜”这样一个商品的时候知道其实是乐事黄瓜味的薯片、看到“唐僧肉”的时候知道其实这不是一种肉类而是一种零食。因此,我们也需要探索结合常识知识的语义理解方法。同时,在医药、个护等领域中,图谱的建设需要依赖较强的专业知识,例如疾病和药品之间的关系,并且此类关系对于准确度的要求极高,需要做到所有知识都准确无误,因此也需要较好的专家和算法相结合的方式来进行高效的图谱构建。
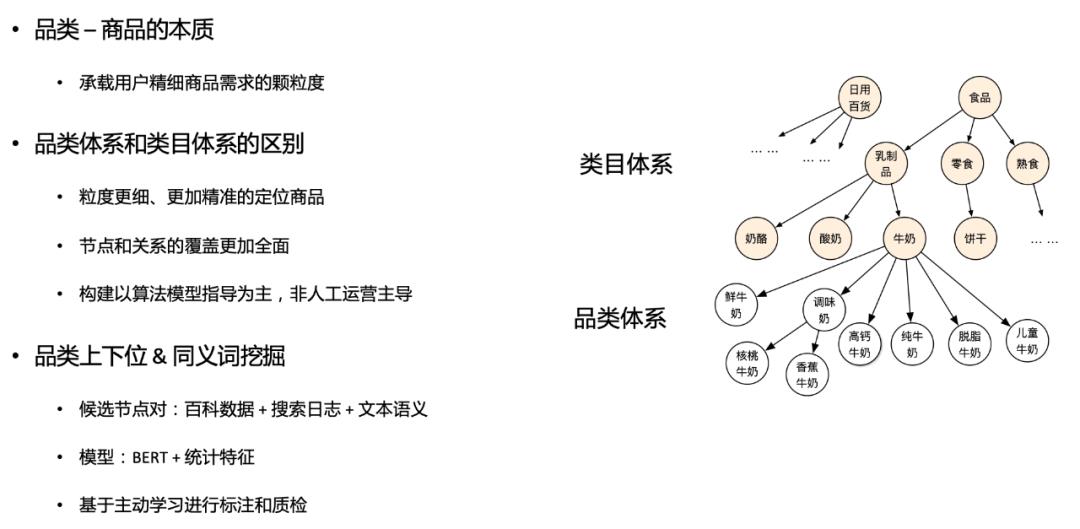
品类词表构建:品类打标首先需要构建一个初步的商品品类词表。首先,我们通过对美团的各个电商业务的商品库、搜索日志、商户标签等数据源进行分词、NER(参见文章《美团搜索中NER技术的探索与实践》)、新词发现等操作,获得初步的商品候选词。然后,通过标注少量的样本进行二分类模型的训练(判断一个词是否是品类)。此外,我们通过结合主动学习的方法,从预测的结果中挑选出难以区分的样本,进行再次标注,继续迭代模型,直到模型收敛。 品类打标:首先,我们通过对商品标题进行命名实体识别,并结合上一步中的品类词表来获取商品中的候选品类,如识别“蒙牛脱脂牛奶 500ml”中的“脱脂牛奶”、“牛奶”等。然后,在获得了商品以及对应的品类之后,我们利用监督数据训练品类打标的二分类模型,输入商品的SPU_ID和候选品类TAG构成的Pair,即<SPU_ID,TAG>,对它进行是否匹配的预测。具体的,我们一方面利用结合业务中丰富的半结构化语料构建围绕标签词的统计特征,另一方面利用命名实体识别、基于BERT的语义匹配等模型产出高阶相关性特征,在此基础上,我们将上述特征输入到终判模型中进行模型训练。 品类标签后处理:在这一步中,我们对模型打上的品类进行后处理的一些策略,如基于图片相关性、结合商品标题命名实体识别结果等的品类清洗策略。
基于规则的品类关系挖掘。在百科等通用语料数据中,有些品类具有固定模式的描述,如“玉米又名苞谷、苞米棒子、玉蜀黍、珍珠米等”、“榴莲是著名热带水果之一”,因此,可以使用规则从中提取同义词和上下位。 基于分类的品类关系挖掘。类似于上文中提到的品类打标方法,我们将同义词和上下位构建为<TAG, TAG>的样本,通过在商品库、搜索日志、百科数据、UGC中挖掘的统计特征以及基于Sentence-BERT得到的语义特征,使用二分类模型进行品类关系是否成立的判断。对于训练得到的分类模型,我们同样通过主动学习的方式,选出结果中的难分样本,进行二次标注,进而不断迭代数据,提高模型性能。 基于图的品类关系推理。在获得了初步的同义词、上下位关系之后,我们使用已有的这些关系构建网络,使用GAE、VGAE等方法对网络进行链路预测,从而进行图谱边关系的补全。




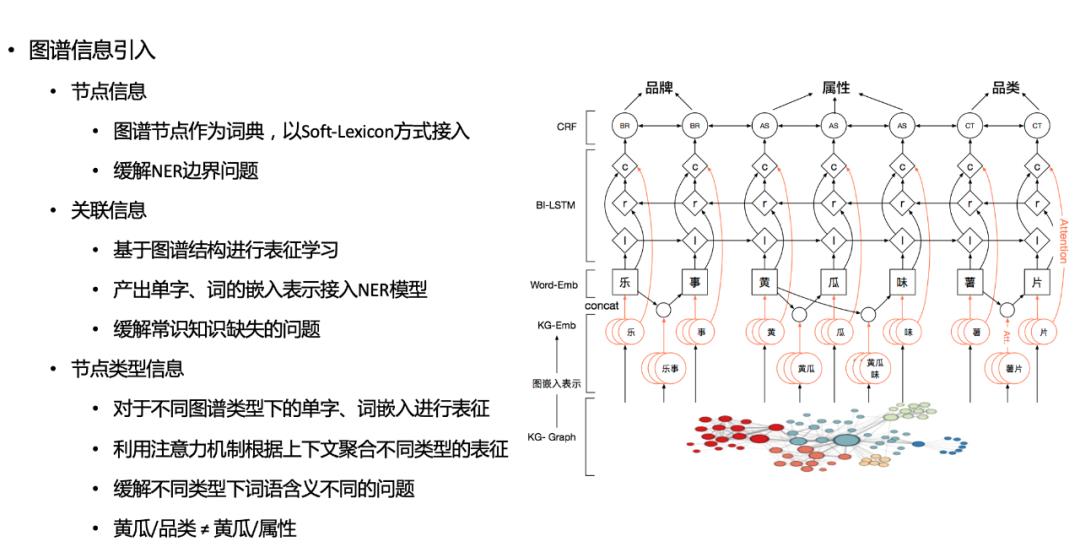


规则模板型特征主要是利用人工先验知识,融合规则模型能力。 统计分布型特征,可以充分利用各类语料,基于不同语料不同层级维度进行统计。 句法分析型特征则是利用NLP领域的模型能力,引入分词、词性、句法等维度特征。 嵌入表示型特征,则是利用高阶模型能力,引入BERT等语义理解模型的能力。

通过半监督学习,充分的利用未标注的数据进行预训练。 通过主动学习技术,选择对于模型来说能够提供最多信息增益的样本进行标注。 利用远程监督方法,通过已有的知识构造远监督样本进行模型训练,尽可能的发挥出已有知识的价值。
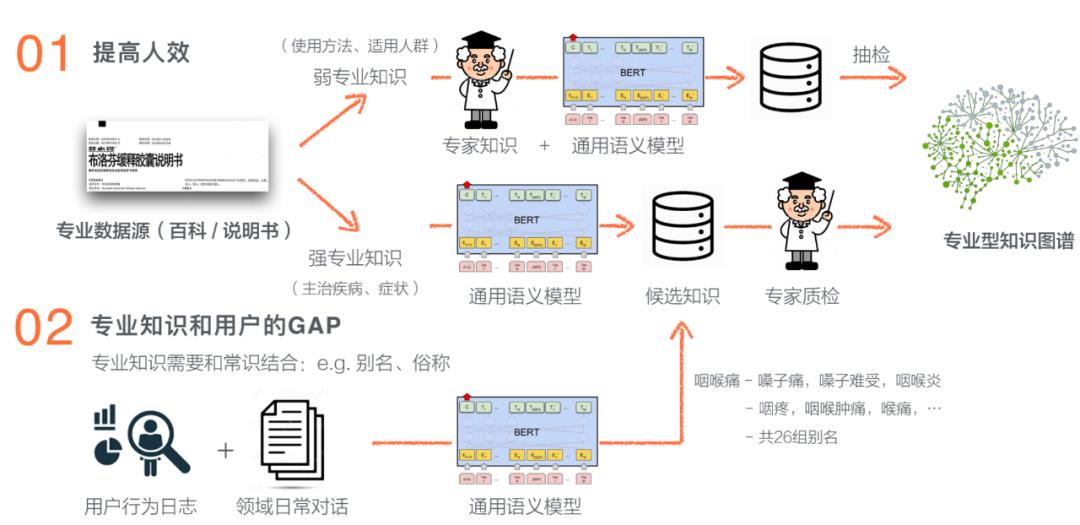

通过各颗粒度进行商品聚合,以ID化特征接入排序模型。 在各颗粒度聚合后进行统计特征的建设。 通过图嵌入表示的方式,将商品的高维向量表示和排序模型结合。
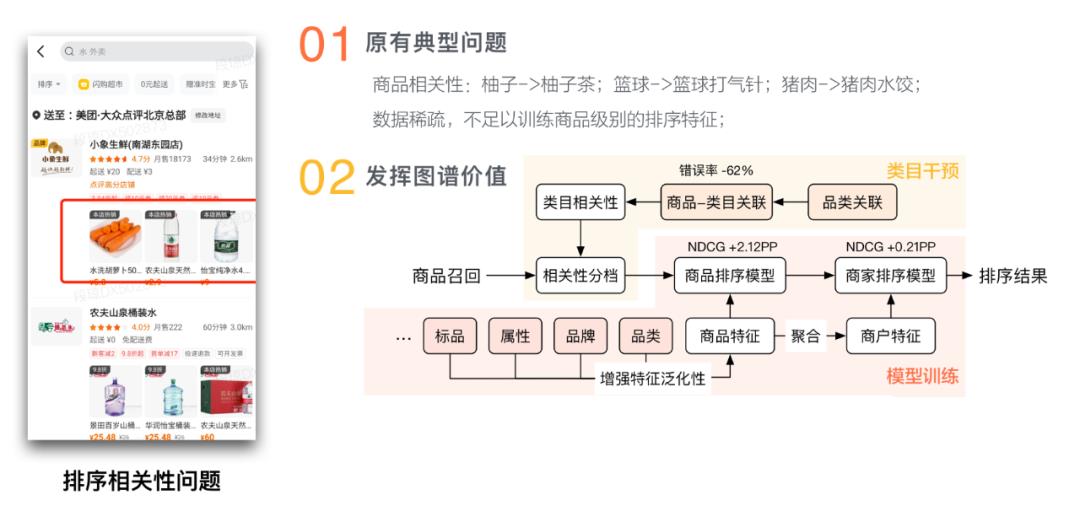

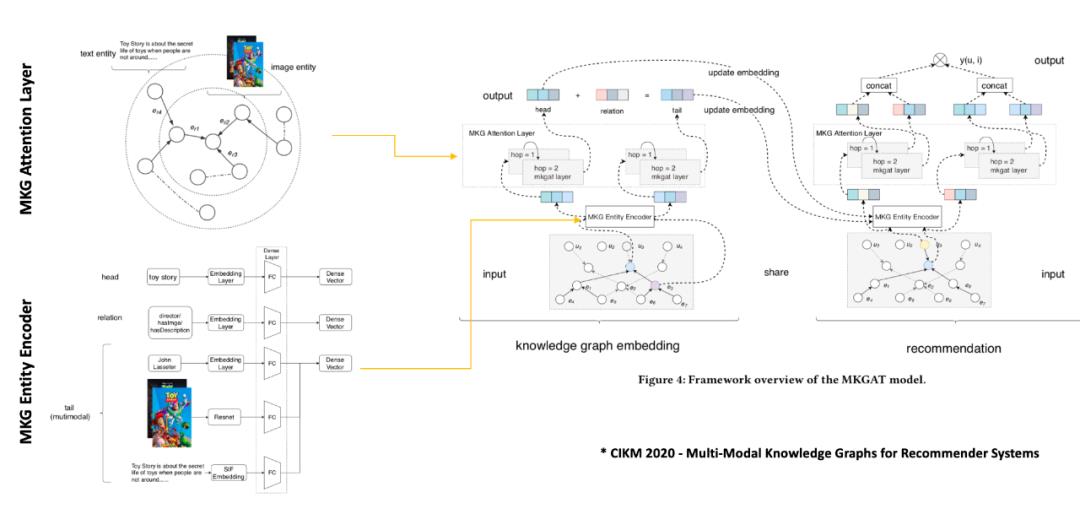
美团科研合作
阅读更多
美团外卖美食知识图谱的迭代及应用
菜品是外卖交易过程的核心要素,对菜品的理解也是实现外卖供需匹配的重点。今天我们将一次推送三篇文章,系统地介绍了美团外卖美食知识图谱的构建和应用。《美团外卖美食知识图谱的迭代及应用》会介绍外卖知识图谱的体系全貌,包括菜品类目、标准菜品、美食基础属性和美食业务主题属性。《外卖商品的标准化建设与应用》将重点介绍外卖菜品标准化建设思路、技术方案和业务应用。由于外卖的业务特点是搭配成单,而《外卖套餐搭配的探索和应用》一文会针对性地介绍外卖套餐搭配技术的迭代以及应用实践。希望对从事相关工作的同学能够带来一些启发或者帮助。
本文系外卖美食知识图谱系列的第一篇文章,这篇文章系统地介绍了美团外卖美食知识图谱的标签体系结构,包括菜品类目标签、标准菜品名、美食基础属性(食材、口味等)和美食业务主题属性(商家招牌、类目经典等)。在技术层面,举例对标签体系的具体构建方法进行介绍,例如基于BERT预训练的分类模型。在应用方面,介绍了美食知识图谱在美团外卖业务的具体应用,包括支撑套餐搭配的菜品表征、提升搜索和商家推荐等业务的用户体验。
1. 背景
知识图谱,旨在描述真实世界中存在的各种实体和实体之间的关系。在美团外卖业务中,美食商品是美团向用户提供服务的基础,美食知识图谱的建设,可以帮助我们向用户提供更加准确、更加丰富、更加个性化的美食服务。另外,美团外卖业务向用户提供“到家”吃饭的服务,到店餐饮业务则向用户提供“到店”吃饭的服务,而外卖和到店的商家和菜品有相当程度的重合,菜品数据的对齐,为我们进行线上(外卖场景)线下(到店场景)数据的对比分析也提供了一个很好的“抓手”。
本文介绍了外卖美食知识图谱的建设,基于对外卖业务数据(外卖交易数据、商家录入的商品标签信息、专业描述PGC、用户评论UGC、商品图片等)的挖掘和分析,形成了针对外卖美食的分类体系(美食类目标签)和标准化体系(标准菜品名标签),并进一步针对不同类型的美食商品,构建包含口味、食材等众多美食基础属性体系。同时,依托美团外卖的业务特性,构建美食商品在外卖业务中涉及的主题属性体系,例如商家招牌、商家主营、类目经典等。目前,外卖美食知识图谱的标签结构如下图1所示:
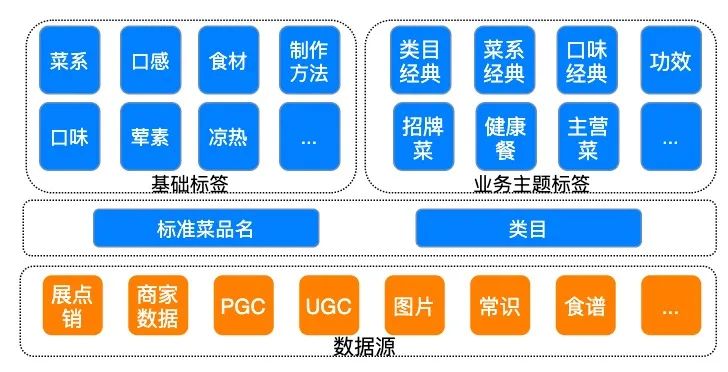
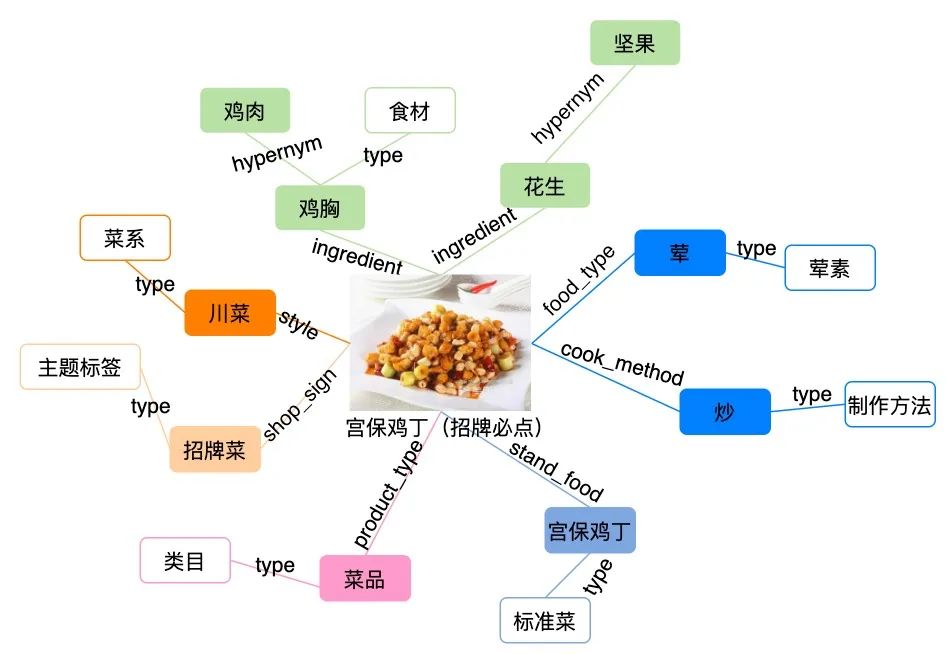
外卖美食知识图谱包含以下四种维度的标签(以“宫保鸡丁”为例,如下图2所示):
-
类目标签:包括主食、小吃、菜品等类目,并在每个类目下,形成了层级化的三百多种细分类目。例如“宫保鸡丁”的类目是“菜品”。类目标签是美食商品的基础分类信息,根据类目的不同,美食商品的基础属性也不同。例如“菜品”类目存在“荤素”、“菜系”之分,而“酒水饮品”类目则没有这种属性标签。
-
标准菜品名标签:标准菜品名标签主要为标准商品信息,例如“宫保鸡丁(招牌必点)”的标准商品是“宫保鸡丁”。因商家输入商品的多样性,标准菜标签的建设,实现了相同美食的聚合。
-
基础属性:根据美食商品的类目不同,构建包括美食的食材、菜系、口味、制作方法、荤素等基础属性。例如“宫保鸡丁”的菜系是“川菜”,食材有“鸡胸”和“花生”,荤素标签是“荤”。基础属性的挖掘对我们理解商品起到关键作用,在商品的筛选、展示、商品表征等业务需求方面,提供基本的数据特征。
-
主题属性:主题属性主要体现美食的业务主题,包括美食在外卖的交易行为、美食在商家的定位、美食在用户反馈中的好评度等。例如某商家的“宫保鸡丁(招牌必点)”是该商家的“招牌菜”。
菜品对齐,涉及到菜品数据,来自外卖在线菜品、点评推荐菜品、美团商家套餐等。
2. 需求及挑战
目前,外卖美食知识图谱已经应用于美团外卖的多个场景,例如推荐、搜索、套餐搭配、运营分析等。业务的深入发展,对美食知识图谱的建设和迭代也提出了更加复杂的要求,例如:
-
美食商品越来越多样,相应的美食知识图谱则需要越来越精细和准确。例如美食知识图谱的类目标签从零开始,建设了包含一百多种类目的类目标签体系。但随着业务发展,部分类目存在明显的可细化空间。
-
图谱标签的挖掘,偏向于静态标签的挖掘,对于相同图谱标签下的美食,缺少业务相关的主题属性描述。例如同样包含“花生”的“酒鬼花生”,相比“宫保鸡丁”,更能代表“花生”相关的美食。
-
外卖美食知识图谱主要描述外卖美食商品,而同一商家的美食商品,也可能会出现在该店的线下收银等业务中。通过对齐不同业务的美食商品,可以在美食实体层面,完善美食知识图谱对商家美食的描述,从而指导商品和商家运营。
为满足业务需求,我们对类目标签和基础属性进行了迭代和优化;同时,构建了业务相关的主题属性。另外,我们将外卖菜品和到餐菜品进行了实体对齐。其中,挖掘主题属性,即挖掘业务相关的图谱知识,是一个需要综合考虑外卖业务和商品本身属性的复杂过程。外卖菜品和到餐菜品的对齐,则需要综合考虑菜品多样性表述和菜品主体归一。
外卖美食知识图谱的迭代难点主要体现在以下几点:
-
业务相关的主题属性挖掘,并没有现成的体系可以参考,在构建过程中,涉及大量的分析和体系设计工作。
-
主题属性的挖掘,最重要的是需要从用户的需求出发,分析用户对商品的需求点,并将其反映在商品的图谱层面,形成相应的主题属性标签。同时,商家的商品信息是一个动态变化的过程,例如销量、供给、商品标签等,前后两天的信息可能就会完全不同。因此业务性主题属性的挖掘,一方面需要建设相对完善的体系,另一方面也需要适配业务数据的动态变化过程,也就在图谱挖掘和需求匹配上带来了极大的挑战。
-
商家录入菜品时,对菜品存在多样性表述,例如同一道菜在分量、口味、食材等方面存在的差异。菜品对齐时,则需要对这些多样性表述进行平衡,例如是否忽略分量因素等。但目前并没有现成的对齐标准可以参考。
3. 外卖美食知识图谱的迭代
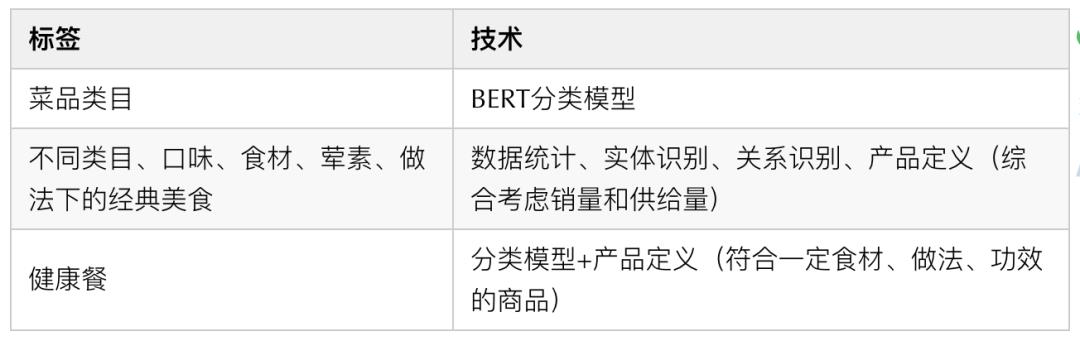
因篇幅受限,本文主要对其中菜品类目,不同类目、口味、食材、荤素、做法下的经典美食,健康餐等图谱标签的挖掘进行介绍。其中,在图谱标签挖掘中涉及到的数据来源和采用的技术,大致如下表所示:
3.1 菜品类目
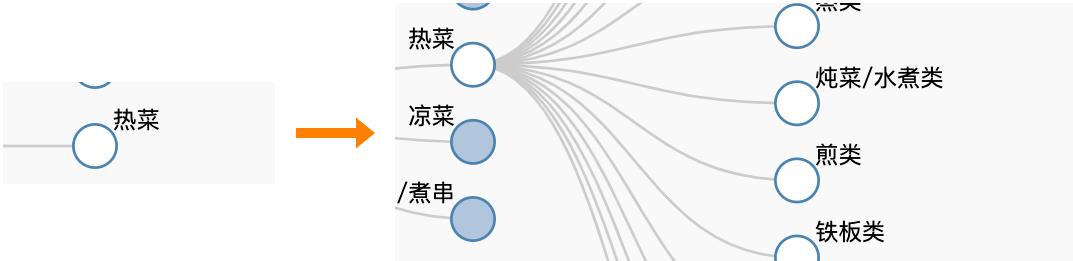
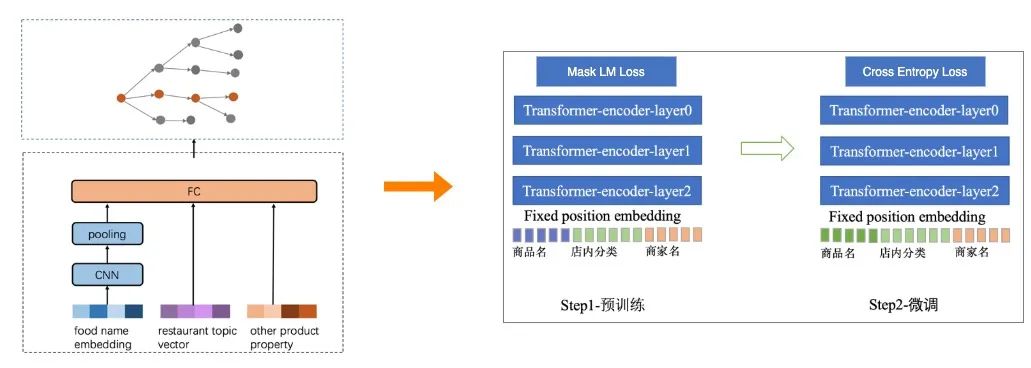
菜品类目标签的挖掘,主要解决美食菜品是什么类别的问题。实现这一目标的挑战有两方面:首先是类目体系如何建立,其次是如何将商品链接到相应的类目节点。在最开始的体系构建时,我们从美食商品的特点以及业务的具体需求出发,从零开始建立起包含一百多种类别的层次化类别体系,部分实例如图3(左)所示。同时,构建基于CNN+CRF的分类模型,对美食商品进行类目分类,如图4(左)所示。
然而,随着业务的发展,已有分类目已经无法支持现有业务的需求。例如:原先的类目体系,对热菜描述不够详细,譬如没有区分热菜的做法等。为此,我们与外卖的供给规划部合作,将类目体系扩充到细分的三百多种类目标签,划分更加详细,覆盖也更加全面,部分实例如图3(右)所示。
类目的细分,要求模型更加精确。在进行类目识别时,可用的数据包括菜品名、商家店内侧边栏分类名称、商家名等。考虑到可使用的信息大多为文本信息,并且,商家录入的文本并没有一定的规范,菜品名也多种多样,为提高模型精度,我们将原先的CNN+CRF的分类模型进行了升级,采用模型容量更大的BERT预训练+Fine-Tuning的模型。模型结构如下图4(右)所示。
3.2 不同类目、口味、食材、荤素、做法下的经典美食标签
我们在建设主题属性时,首先在基础属性标签维度,综合考虑商品的销量和供给情况,对菜品进行选优。例如类目下的经典美食等。
类目经典美食等指的是销量较高、供给量丰富的类目美食商品,例如主食经典美食、小吃经典美食。口味、食材、做法经典美食标签等也是相似的定义。
在建设过程中,我们发现,假如直接在商品维度进行识别,因为商品的更新频率相对较高,对新录入的暂时没有销量或者暂时销量低的美食商品不友好,销量水平需要考虑在线时间的影响。因此我们使用标准菜品进行类目、口味经典等的识别,并通过标准菜品,泛化到具体的美食商品上。
其中,“标准菜品”借用其它类电商业务中的“标品”概念,虽然绝大部分菜品的生产都不是标准化的过程,但是这里我们只关注主要的共性部分,忽略次要的差异部分。例如“西红柿鸡蛋”、“番茄炒蛋”都是同一类菜品。从结果上看,目前我们聚合出来的“标准菜品”达到几十万的量级,并且能够覆盖大部分美食商品。
借助标准菜品,我们将类目、口味、食材、荤素、做法等标签聚合到标准菜品维度,并将销量、供给量进行标准菜品维度计算,这样就解决了商品在线时间长短的问题。在具体打标过程中,例如类目经典,我们基于销量和供给,在类目维度对标准菜进行排序,并选择Top n%标准菜进行打标,作为类目经典下的商品。例如在“面食”类目下,“西红柿鸡蛋面”的销量和供给量均在Top n%的水平,因此就认为“西红柿鸡蛋面”是一个面食类经典美食。
3.3 健康餐
这里的健康餐主要指低脂低卡餐,即低卡路里、低脂肪、高纤维、制作简单、原汁原味、健康营养的食物,一般为蔬菜水果(如罗勒、甘蓝、秋葵、牛油果等),富含优质蛋白的肉类(如三文鱼、虾、贝类、鸡胸等),谷物(主要以粗粮为主,如燕麦、高粱、藜麦等)。烹饪方法也坚持“少油,少盐,少糖”的原则,主要做法为蒸、煮、少煎、凉拌等。
健康餐的识别,主要挑战在于本身的样本较少,但是因为健康餐的特殊性,商家在进行商品录入时,一般会对其进行描述,例如指出这个美食商品是“健康”的、“低卡”的、“健身”类型的,因此我们构建了一个分类模型,对健康餐进行识别。可使用的数据,包括商品名、商家导航栏、商家名称、商家对商品的描述等。而商家类目与商品的类目处于迭代状态,因此并没有对这部分信息进行使用。
识别过程如下:
-
训练数据构建:因健康餐本身的占比相对较少,因此首先总结和健康餐相关的关键词,使用关键词进行文本匹配,采样概率相对较高的健康餐数据,进行外包数据标注。此处,我们总结出“沙拉、谷物饭、谷物碗、低油、低卡、无糖、减脂、减肥、轻食、轻卡”等关键词。
-
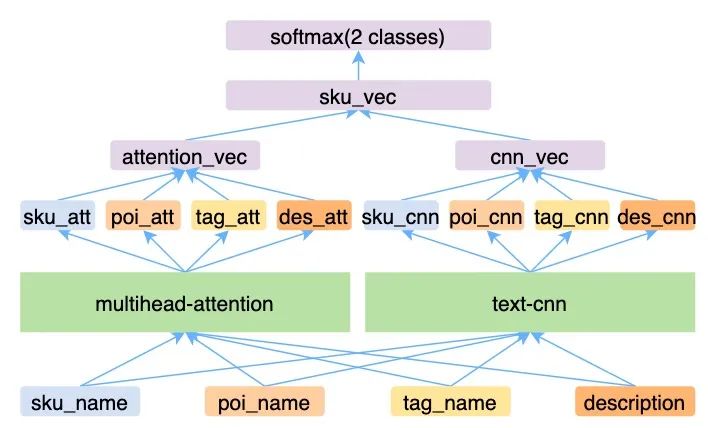
模型构建:同一个商品因其中使用的配料不同,在健康餐识别方面也会不同,例如菜名为“招牌沙拉”的商品,假如沙拉中添加了芝士,则有可能商品就不会被识别成健康餐。为了综合考虑商家录入的商品信息,使用商品名、商家名、导航栏名称、商家录入的商品描述等。这四种数据为不同尺度的数据源,商品名等为相对较短的文本,因此在模型构建时,考虑使用类似Text-CNN[1]的结构进行字级别的特征提取;商品描述则是相对较长的文本,因此在构建时,考虑使用类似Transformer[3]的结构进行特征提取,使用Multi-head Attention的机制,提取长文本中,“字”层面的特征。具体结构如下:
-
采用了两种结构:Multihead-attention(Transformer)和Text-CNN。实验发现,采用两种结构联合的方式,比采用单一结构准确率高。
-
在建模时,均使用字级别特征处理,避免因为分词造成的误差,同时也避免未登录词的影响。
-
-
数据迭代增强:因为使用关键词进行样本构建,在模型训练时,模型会朝着包含这些关键词的方向学习,因此存在漏召回的情况。在这里,我们进行了一定的训练数据增强,例如在评估时,选取可识别出健康餐的商家,对该商家中漏召回的数据进行训练数据补充;同时,对部分特征明显的关键词,进行补充并扩充正例。通过对训练样本的多次扩充,最终完成健康餐的高准确率识别。
3.4 菜品实体对齐
考虑到同一商家菜品在不同业务线的菜品名可能略有差异,我们设计了一套菜品名匹配的算法,通过拆解菜品名称的量词、拼音、前后缀、子字符串、顺序等特征,利用美食类目识别、标准菜品名抽取、同义关系匹配等进行菜品实体对齐。例如:碳烧鸽=炭烧鸽、重庆辣子鸡=重庆歌乐山辣子鸡、茄子肉泥盖饭=茄子肉泥盖浇饭、番茄炒蛋=西红柿炒蛋等。目前,形成如下图的菜品归一体系:

4. 应用
这里对外卖美食知识图谱的应用,进行举例说明。主要涉及套餐搭配、美食商品展示等。
4.1 套餐搭配-表征菜品
为满足用户的搭配成单需求,进行套餐搭配技术的探索。套餐搭配技术的关键在于,对美食商品的认知,而外卖美食知识图谱,则提供了最全面的数据基础。我们基于同商家内的商品信息和历史成单信息,对商品的搭配关系进行拟合,参考指针网络[2]等结构,构建了基于Multi-Head Attention[3]的Enc-Dec模型,具体的模型结构如下:
① Encoder:对商家菜单进行建模,因菜单为无序数据,因此采用Attention的方式进行建模。商品的信息主要包括商品名、商品图谱标签、交易统计数据等三部分。
a. 对菜名、商品标签分别进行Self-Attention计算,得到菜名和商品标签对应的向量信息,然后与交易统计数据进行Concat,作为商品的初步表示。
b. 对商品的初步表示进行Self-Attention计算,以对同商家的商品有所感知。
② Deocoder:对搭配关系进行学习,基于当前已选择的商品,对下一个可能的搭配进行预估。
a. 在搭配输出时,使用Beam-Search进行多种搭配结果的输出。
b. 为了保证输出搭配中的商品的多样性,添加Coverage机制[2]。
③ 训练之后,将Encoder部分分离,进行离线调度,可实现每天的向量产出。
具体的模型结构如下图7所示:

基于外卖美食知识图谱构建的套餐搭配模型,在多个入口(“满减神器”、“对话点餐”、“菜品详情页”等)取得转化的提升。
4.2 交互式推荐
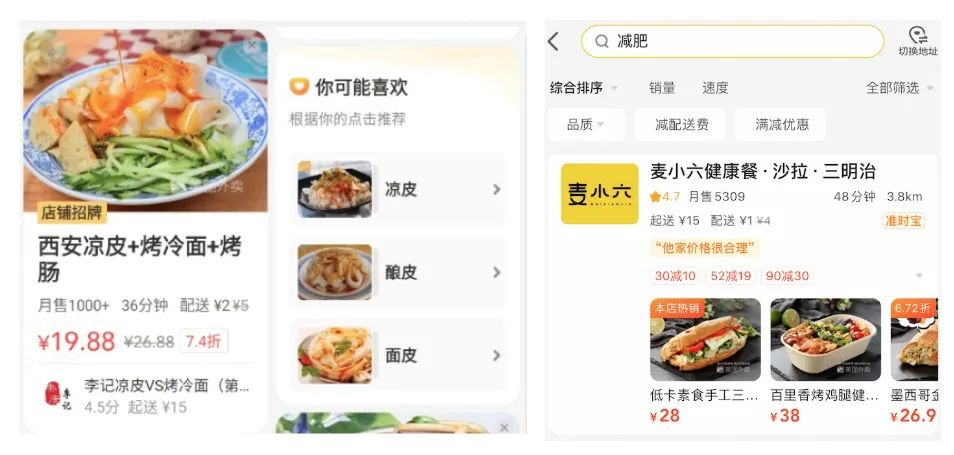
通过分析外卖用户的需求,发现用户存在跨店相似商品对比的需求,为打破商家界限的选购流程特点,提供便捷的跨店对比决策方式。交互式推荐,通过新的交互模式,打造推荐产品的突破点。在用户的交互过程中,根据用户的历史偏好、实时的点击行为,向用户推荐可能喜欢的美食商品。如下图8(左)所示,在向用户进行同类美食的推荐时,美食知识图谱中的标准菜品标签提供了主要的数据支撑。
4.3 搜索
搜索作为外卖核心流量入口,承载了用户明确的外卖需求。用户通过输入关键词,进行菜品检索。在实际使用中,从搜索的关键词类型看,可能是某个具体的菜品,也可能是某种食材、某种菜系。在美食知识图谱中,图谱标签的高准确率和高覆盖,有助于提升搜索入口的用户体验,最新的实验也表明了这一点(新增部分食材、菜系、功效等标签,在搜索的线上实验效果正向)。
5. 未来规划
5.1 场景化标签的挖掘
美食与我们的生活息息相关,美团外卖每天为千万用户提供美食方面的服务。然而,用户的需求是多种多样的,在不同的环境、不同的场景下,对美食的需求也不尽相同。目前美食知识图谱挖掘,在场景相关的标签较为缺失,例如某些节气、节日等图谱知识;特定天气情况下的图谱知识;特定人群(增肌人群、减肥人群)等的图谱知识。接下来我们会在场景化标签的挖掘方面进行探索。
在挖掘方法方面,目前的挖掘数据主要为文本信息。在商品图片、描述、结构化标签等信息的融合方面,挖掘不够深入,模型的效果也有待提升。因此在多模态识别模型方面,我们也会进行相应的探索。
5.2 基于图谱的推荐技术研究
美团外卖在理解美食的基础上,向用户进行美食推荐,以更好地满足用户对美食的需求。外卖美食知识图谱和外卖业务数据,作为实现这一点的数据基础,包含上亿的节点信息和十几亿的关系数据。通过对用户的商品搜索、点击、购买等行为进行建模分析,可以更加贴合用户的需求,向用户进行商品推荐,例如,将美食知识图谱和外卖行为数据融合,以用户为起点,进行随机游走,向用户推荐相关的美食。在接下来的图谱应用方面的探索中,我们也会更加深入的探索基于美食知识图谱和用户行为的推荐技术。
6. 参考文献
[1] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[2] See A, Liu P J, Manning C D. Get to the point: Summarization with pointer-generator networks[J]. arXiv preprint arXiv:1704.04368, 2017.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[4] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]//Advances in Neural Information Processing Systems. 2017: 1024-1034.
7. 作者简介
杨林、郭同、海超、懋地等,均来自美团外卖技术团队。
阅读更多
---
---------- END ----------
招聘信息
美团外卖知识图谱组,致力于更全面精准的刻画外卖供需关系,赋能外卖推荐、搜索、营销等业务。欢迎感兴趣的同学发送简历至:mayunan@meituan.com。
也许你还想看

以上是关于美团商品知识图谱的构建及应用的主要内容,如果未能解决你的问题,请参考以下文章