看得见的机器学习:零基础看懂神经网络
Posted 张铁蕾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看得见的机器学习:零基础看懂神经网络相关的知识,希望对你有一定的参考价值。
关于机器学习,有一个古老的笑话:
Machine learning is like highschool sex. Everyone says they do it, nobody really does, and no one knows what it actually is. [1]
翻译过来意思大概是:
机器学习就像高中生的性爱。每个人都说他们做了,但其实没有人真的做了,也没有人真正知道它到底是什么。
总之,在某种程度上,机器学习确实有很多晦涩难懂的部分。虽然借助TensorFlow、sklearn等工具,机器学习模型以及神经网络通常能被快速地运行起来,但真正弄清背后发生了什么,仍然不是一件容易的事。在本篇文章中,我会试图用直观的方式来解释神经网络。俗话说,「耳听为虚,眼见为实」,本文的目标就是,利用「可视化」的方法,让你亲眼「看到」神经网络在运行时到底做了什么。
本文不会出现一个公式,希望非技术人员也能看懂。希望如此^-^
当今在图像识别或NLP中使用的深度神经网络,都发展出了非常复杂的网络结构,网络层次多达几十层,模型参数多达数十万、上百万个。这样的神经网络理解起来,难度极大,而且计算起来也需要很强的算力。
因此,我们由简入繁,先从最简单的情况入手。
首先,我们考虑一个简单的「二分类」问题。下面展示了一个随机生成的数据集:
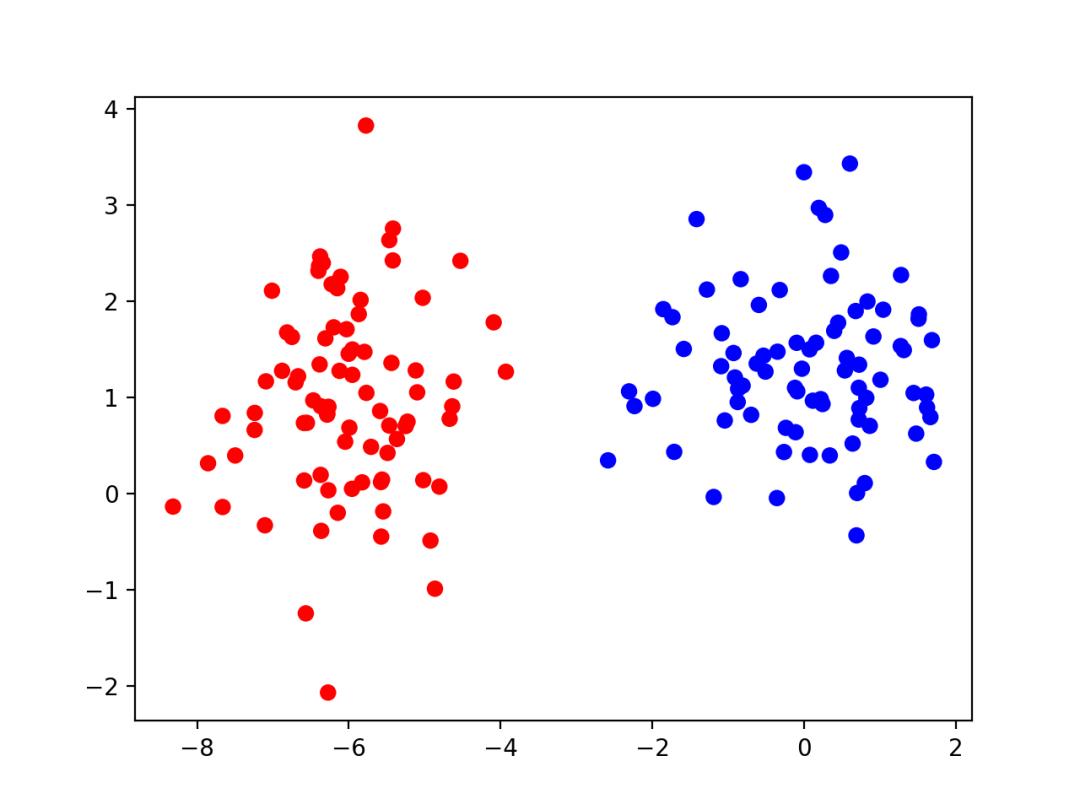
上图展示的是总共160个点(包括红色和蓝色),每个点代表一个数据样本。显然,每个样本包含2个特征,这样每个样本才能够在一个二维坐标系中用一个点来表示。红色的点表示该样本属于第1个分类,而蓝色的点表示该样本属于第2个分类。
二分类问题可以理解成:训练出一个分类模型,把上图中160个样本组成的训练集按所属分类分成两份。注意:这个表述并不是很严谨。上图中的样本只是用于训练,而训练出来的模型应该能对「不属于」这个训练集的其它样本进行分类(不过我们现在不关注这一点,可以先忽略掉这个表述上的细节)。
为了完成这个二分类任务,我们有很多种机器学习模型可供选择。但现在我们的目的是为了研究神经网络,所以我们可以设计一个最简单的神经网络,来解决这个分类问题。如下图:
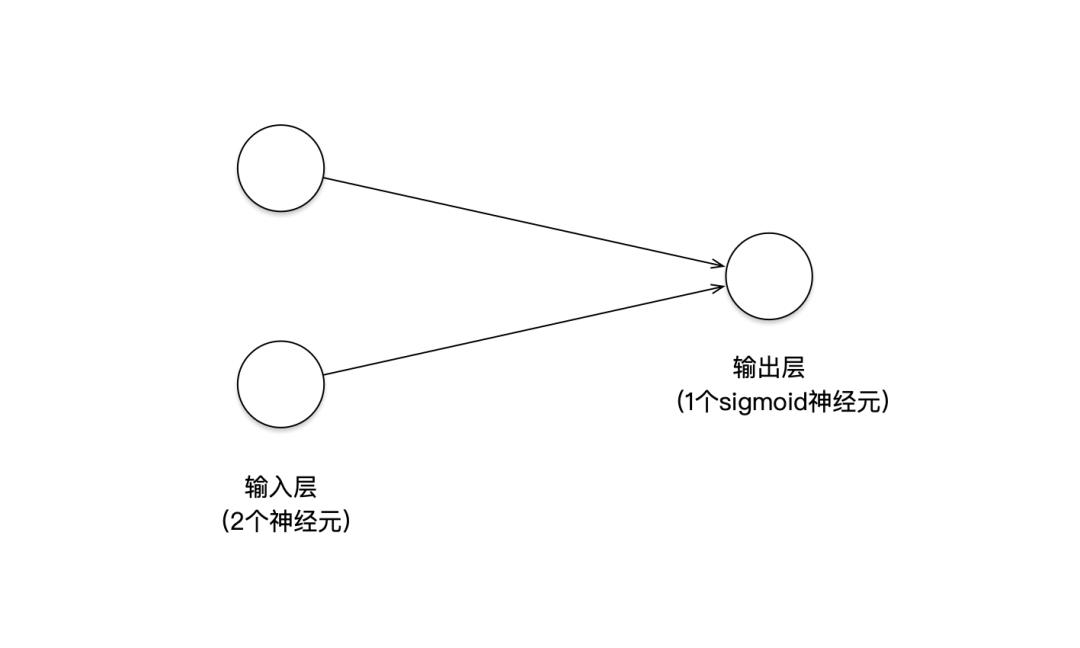
这个神经网络几乎没法再简单了,只有1个输入层和1个输出层,总共只有3个神经元。
经过简单的数学分析就容易看出,这个只有2层的神经网络模型,其实等同于传统机器学习的LR模型(逻辑回归)。也就是说,这是个线性分类器,对它的训练相当于在前面那个二维坐标平面中寻找一条直线,将红色点和蓝色点分开。
根据红色点和蓝色点的位置分布,我们很容易看出,这样的一条直线,很容易找出来(或学习出来)。实际上,上图中这个简单的神经网络,经过训练很容易就能达到100%的分类准确率(accuracy)。
现在,假设我们的数据集变成了下面的样子(红色点分成了两簇,分列蓝色点左右):
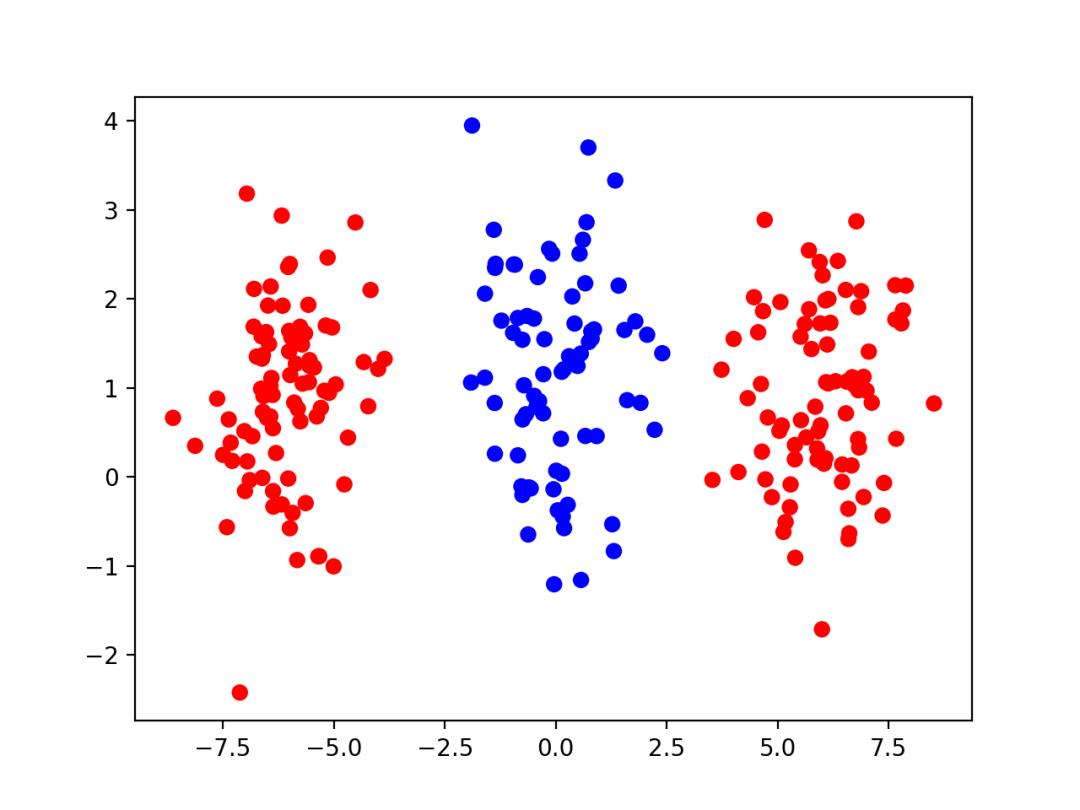
如果我们还是使用前面的2层的神经网络,试图画一条直线来把红色点和蓝色点分开,显然就做不到了。我们说,现在这个分成三簇的数据集已经不是「线性可分」的了。实际上,针对最新的这个数据集,前面这个只有2层的神经网络,不管你怎么训练,都只能达到60%~70%左右的分类准确率。
为了提高分类的准确率,比较直观的想法也许是画一条曲线,这样才能把红色点和蓝色点彻底分开。这相当于要对原始输入数据做非线性变换。在神经网络中,我们可以通过增加一个隐藏层(hidden layer)来完成这种非线性变换。修改后的神经网络如下图:
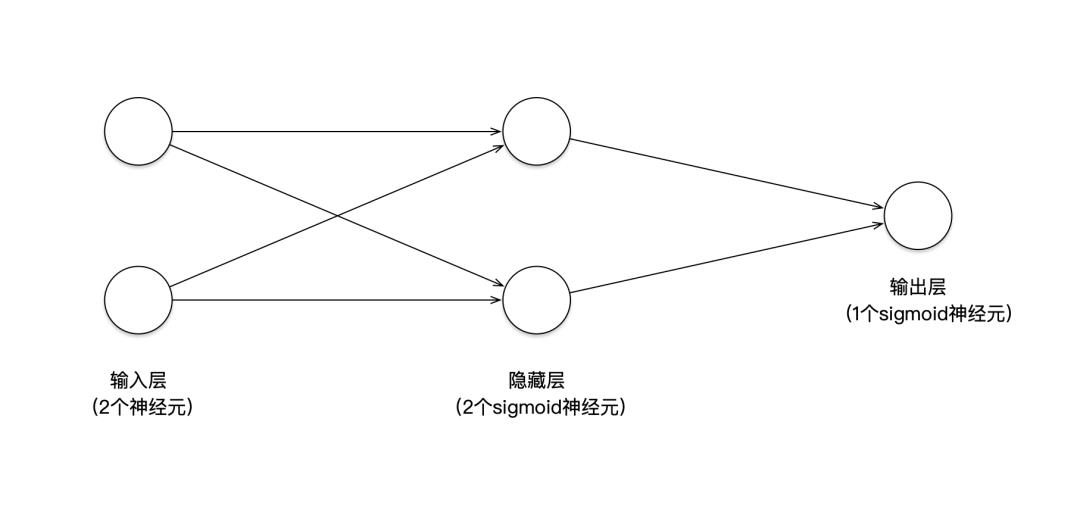
我们看到,修改后的神经网络增加了一层包含2个sigmoid神经元的隐藏层;而输入层和隐藏层之间是全连接的。实际上,当我们重新训练这个带隐藏层的神经网络时,会发现分类的准确率又提升到了100%(或者非常接近100%)。这是为什么呢?
我们可以这样来看待神经网络的计算:每经过一层网络,相当于将样本空间(当然也包括其中的每个样本数据)进行了一次变换。也就是说,输入的样本数据,经过中间的隐藏层时,做了一次变换。而且,由于隐藏层的激活函数使用的是sigmoid,所以这个变换是一个非线性变换。
那么,很自然的一个问题是,经过了隐藏层的这一次非线性变换,输入样本变成什么样了呢?下面,我们把隐藏层的2个神经元的输出画到了下图中:
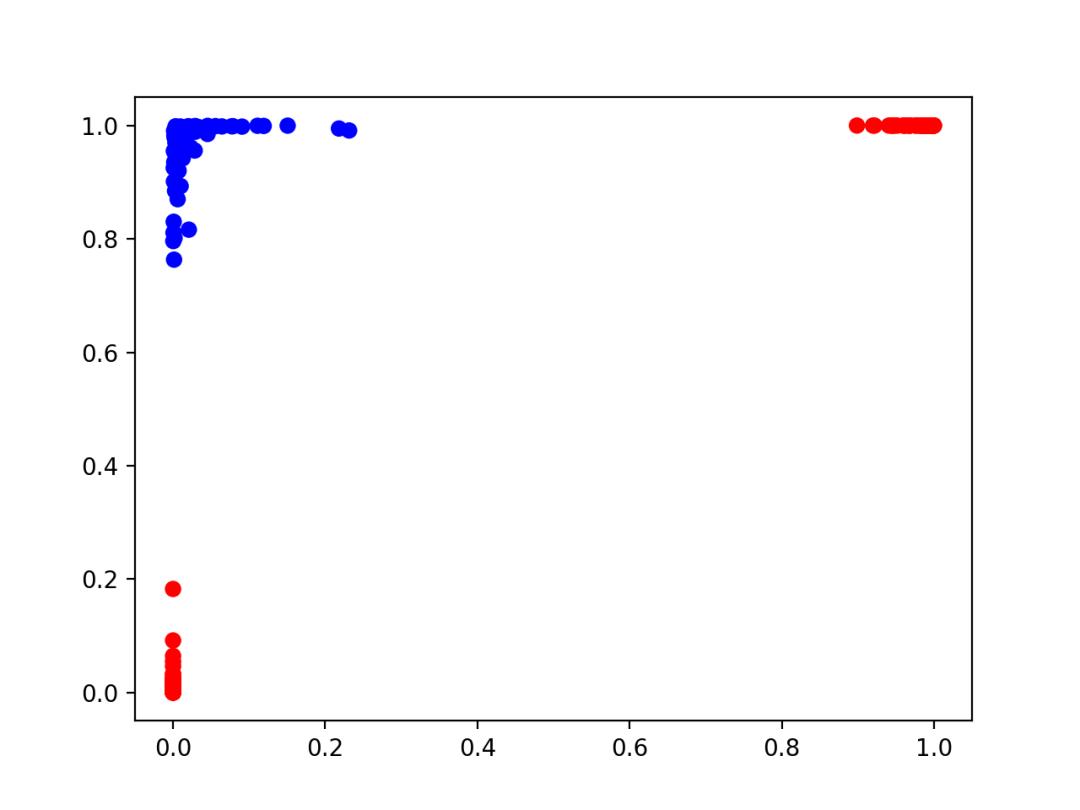
我们发现了一个有趣的现象:变换后的样本数据点,还是分成了三簇,但红色点再也不是分列蓝色点的两侧了。两簇红色点被分别逼到了一个角落里,而蓝色点被逼到了另外一个不同的角落里。很容易看出,现在这个图变成「线性可分」的了。而隐藏层的输出数据,再经过神经网络最后一个输出层的处理,刚好相当于经过了一个线性分类器,很容易用一条直线把红色点和蓝色点分开了。
从隐藏层的输出图像,我们还能发现一些细节:
所有的数据坐标(不管是X轴还是Y轴),都落在了(0,1)区间内。因为sigmoid激活函数的特性,正是把实数域映射到(0,1)之间。
我们发现,所有的数据都落在某个角落里。这不是偶然,还是因为sigmoid激活函数的特性。当充分训练到sigmoid神经元「饱和」时,它一般是会输出接近0或1的值,而极少可能输出一个接近(0,1)中间的值。
总结一下:从前面的分析,我们大概可以看到这样一个变换过程,就是输入样本在原始空间内本来不是「线性可分」的,而经过了隐藏层的变换处理后,变得「线性可分」了;最后再经过输出层的一次线性分类,成功完成了二分类任务。
当然,这个例子非常简单,只是最简单的神经网络结构。但即使是更复杂的神经网络,原理也是类似的,输入样本每经过一层网络的变换处理,都变得比原来更「可分」一些。我们接下来就看一个稍微复杂一点的例子。
现在我们来考虑一下「手写体数字识别」的问题。
在机器学习的学术界,有一个公开的数据集,称为MNIST[2]。使用神经网络对MNIST的数据进行识别,堪称是神经网络和深度学习领域的「Hello World」。
在MNIST的数据集中,共有70000张手写体数字图片。它们类似下面的样子:

每一张图片都是28像素×28像素的黑白图片,其中每个像素用一个介于[0,255]之间的灰度值表示。
MNIST的数字识别问题,就是给你一张这样的28像素×28像素的图片,用程序区分出它具体是0到9哪一个数字。
对于这个问题,历史上的最佳成绩是99.79%的识别率,方案使用了卷积神经网络(CNN)。我们这里不想让问题复杂化,因此还是采用普通的全连接的神经网络来求解。我们使用的网络结构如下:
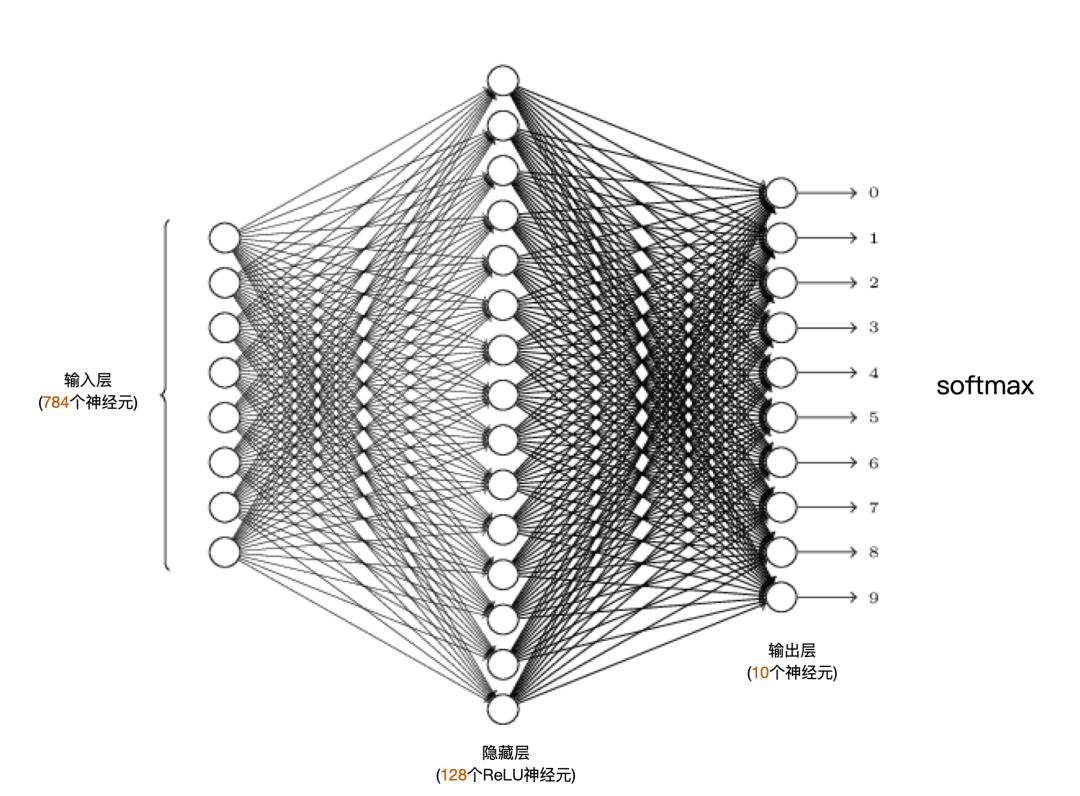
这个神经网络的输入和输出是这样定义的:
输入:每次输入一张图片。图片的每个像素的灰度值,除以255后得到一个[0,1]之间的归一化的灰度值,然后输入到输入层的每个神经元上。也就是说,输入层有784个神经元,正好对应一张图片28×28=784个像素。
输出:输出层共10个神经元,各个神经元的输出分别对应0到9这几个数字。哪个神经元输出的值最大,我们就可以认为预测结果是对应的那个数字。另外,10个输出值再经过softmax处理,就得到了当前输入图片是各个数字的概率。
对这个神经网络进行训练后,可以很轻松地获得98%左右的正确识别率。那针对这个更宽的神经网络,我们还能使用前面的方法来对它进行可视化的图像绘制吗?
在前面的一小节中,我们的简单神经网络输入层和隐藏层都只有2个神经元,因此可以在一个二维坐标平面中绘制它们的图像。而对于MNIST的这个神经网络,当我们想对它的输入层进行图像绘制的时候,发现它有784维!
如何把784维的特征向量绘制出来?这涉及到对于高维数据可视化的问题。通常来讲,人的大脑只能理解最高3维的空间,对于3维以上的空间,就只能靠抽象思维了。
我们想象一个简单的例子,来感受一下对高维空间进行直观的理解有多么困难:
首先,在一个平面内(也就是2维空间),我们可以找到3个两两等距的点,以它们为顶点可以组成一个等边三角形。
在一个3维空间内,我们可以找到4个两两等距的点,以它们为顶点可以组成一个正四面体,这个正四面体的每个面都是一个等边三角形。
现在,我们上升到4维空间,理论上我们可以找到5个两两等距的点,以它们为顶点可以组成一个我们姑且称之为「正五面体」的东西。继续类比,这个所谓的「正五面体」,它的每个「面」,也就是由5个点中的任意4个点组成的「面」,严格来说不能称它为一个「面」,因为它是一个正四面体。另外需要注意,当我们在这里用「正五面体」这样一个名不副实的名字来命名的时候,还带来了很大的误导性,因为它听起来像是3维空间中的一个「正多面体」。但如果你对数学的历史有所了解的话,那么就应该知道,早在2000多年前,欧几里得就在他的《几何原本》中提出了,3维空间中根本不存在正五面体(实际上3维空间中只有5种正多面体)。
好了,如果你还能跟得上前面最后这一段关于4维空间的描述,那么说明你一定阅读得非常仔细,而且正在一边阅读一边思考^-^但不管怎么说,4维空间的情形已经让人足够恼火了(它们符合逻辑但却不可想象),更别说让我们来想象784维空间中的几何结构了!
因此,我们需要降维(dimensionality reduction)的技术,把高维空间中的数据降低到3维或2维空间内,然后才能可视化地绘制出来,达到一定的「直观理解」的目的。
那降维到底是怎样的一种操作呢?我们仔细回想一下,其实在现实世界中,我们已经碰到过很多降维的情况了。比如下面这张图片:

这是100多年前的一幅名画,名字叫《大碗岛的星期天下午》。在这幅画作中,我们可以感受到海滩远处强烈的纵深感。但任何一幅画作,都是在一张二维的平面上绘制的。所以,画家需要把三体景物投影到二维上,这就是一种「降维」处理。与此类似,我们平常用相机拍出的照片,也是把三维空间「降维」到了二维平面上。这种降维处理普遍存在,可以称为「投影变换」,是线性变换的一种。
我们再来看一个例子:
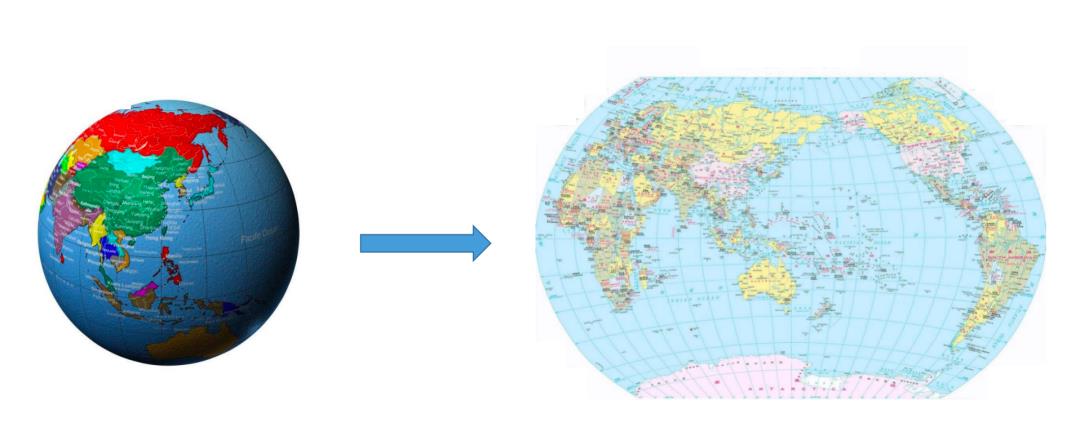
图中右侧是一张世界平面地图。本来地球的表面是个三维空间中的球面,但上面的世界地图把整个球面绘制到了一个二维平面上。为了做到这一点,显然地图的绘制者需要把球面摊平,部分区域需要进行一定的拉伸和扭曲。我们把这个绘制过程想象成一个映射:地球表面的一个点,映射到世界平面地图上的一个点上。但所有的点的映射并不满足同样的线性关系,所以这是一个非线性变换。
上面不管是画作、照片的例子,还是世界平面地图的例子,都是把三维降维到二维。但在机器学习中,我们经常需要把从更高维降维到三维或二维。人们发明了各种各样的降维方法,比如PCA (Principal Component Analysis),是一种线性降维方法;MDS (Multi-dimension Scaling)、t-SNE (t-Distributed Stochastic Neighbor Embedding),都是非线性降维方法。
前面提到的各种降维方法,做法不同,也各有侧重点。任何一种解释起来,都要花去很大的篇幅,因此本文不一一详述。考虑到我们接下来的目标,是为了对前一节引入的MNIST神经网络进行直观的可视化展示,所以我们这里采取一种更为直接(也易理解)的方法——一种基于k-NNG (k-Nearest Neighborhood Graph,k近邻图)和力学模型(Force-Directed)的降维可视化方法[3][4]。
这种方法的过程可以如下描述:
对于高维空间中的节点计算两两之间的距离,为每个节点找到离它最近的k个节点,分别连接起来建立一条边。这样就创建出了一个由节点和边组成的图数据结构。这个新创建的图有这样的特性:有边直接相连的节点,它们在原高维空间中的位置就是比较接近的;而没有边直接相连的节点,它们在原高维空间中的位置就是比较远的。这个图称为「k近邻图」,也就是k-NNG (k-Nearest Neighborhood Graph)。另外还有一个问题:高维空间中两个节点的距离怎么计算?这其实有很多种计算方法,比较常见的有「欧几里得距离」、「明可夫斯基距离」等。
将前面一步得到的k近邻图在二维平面中绘制出来。这变成了一个常见的绘图布局的问题,从某种程度上跟电路板的元器件布局有点像。为了让绘制出来的图像清晰易观察,这个绘制过程需要尽量满足一定的条件,比如,边线的交叉应该尽量少;有边相连的节点应该尽可能离得近一些;节点之间不能离得太近(聚在一起),应该尽量均匀地散布在整个坐标系平面上。为了达到这样的要求,我们采用了Fruchterman和Reingold发明的Force-Directed Graph Drawing这种算法。它模拟了物理世界的力学原理,如下图所示:
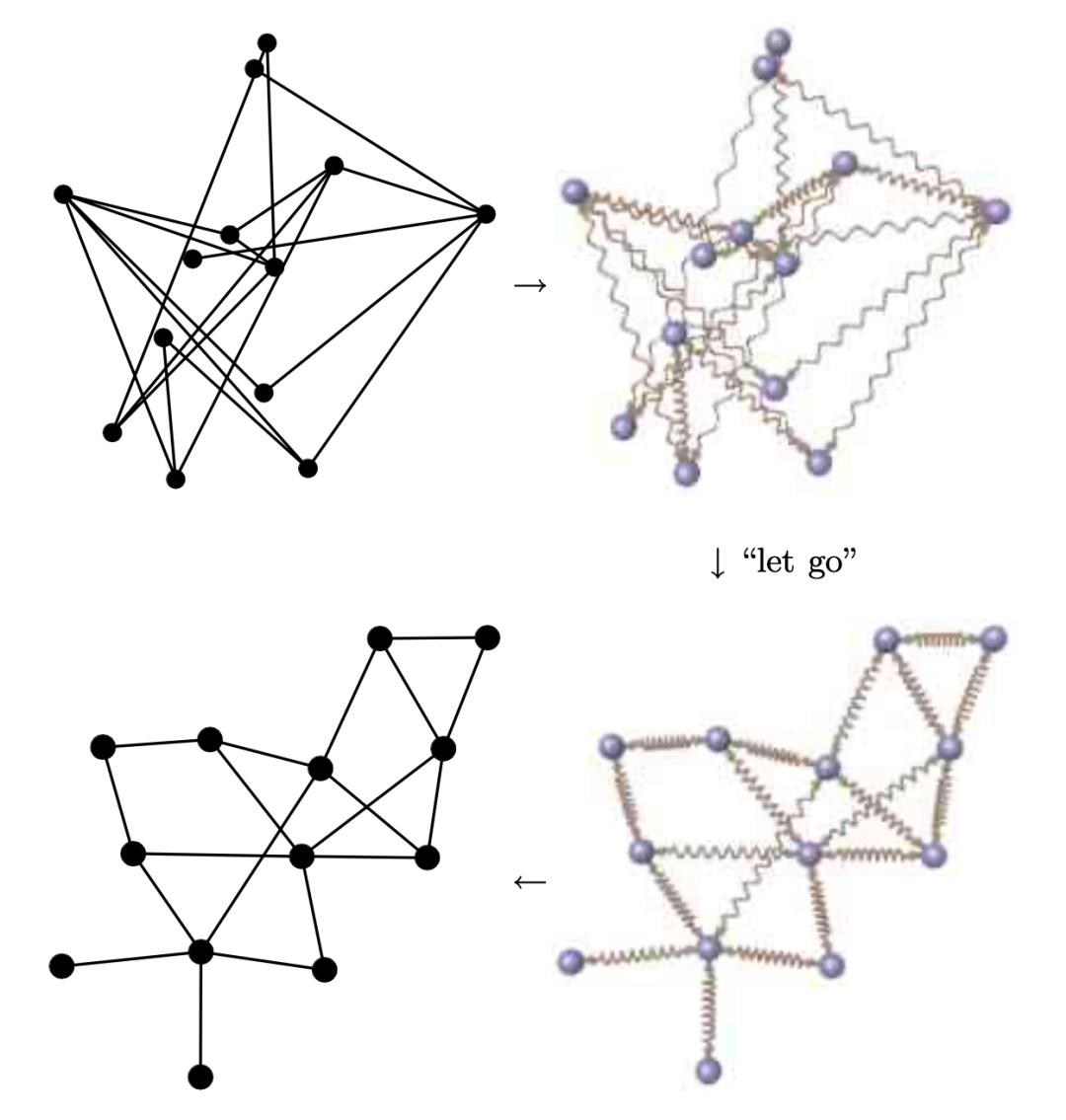
想象左上角的图,把边换成弹簧,把节点换成带电小球;
弹簧会倾向于把相邻节点(即有边相连的节点)固定在一个自然长度上(对应原高维空间中的距离),不能太远也不能太近;
所有「带电小球」都互相保持斥力,让不相邻的节点互相远离,并促使所有节点尽量散布整个画面;
放开手,让各个节点在弹簧和斥力的作用下自由移动,最后达到总体能量最小的状态,这时就得到了左下角那个更好的节点布局。
对于这种方法,我们需要重点关注的是:从高维降到低维,原来高维空间中的哪些几何特性被保持住了?从前面绘制过程的描述容易看出:在原高维空间中距离比较近的节点,在最后绘制的二维图像中,也会在弹簧拉力的作用下离得比较近。只有搞清楚这一点,我们才能通过观看低维的图像,来理解高维的结构。
现在,我们终于做好准备来对MNIST神经网络进行可视化了。
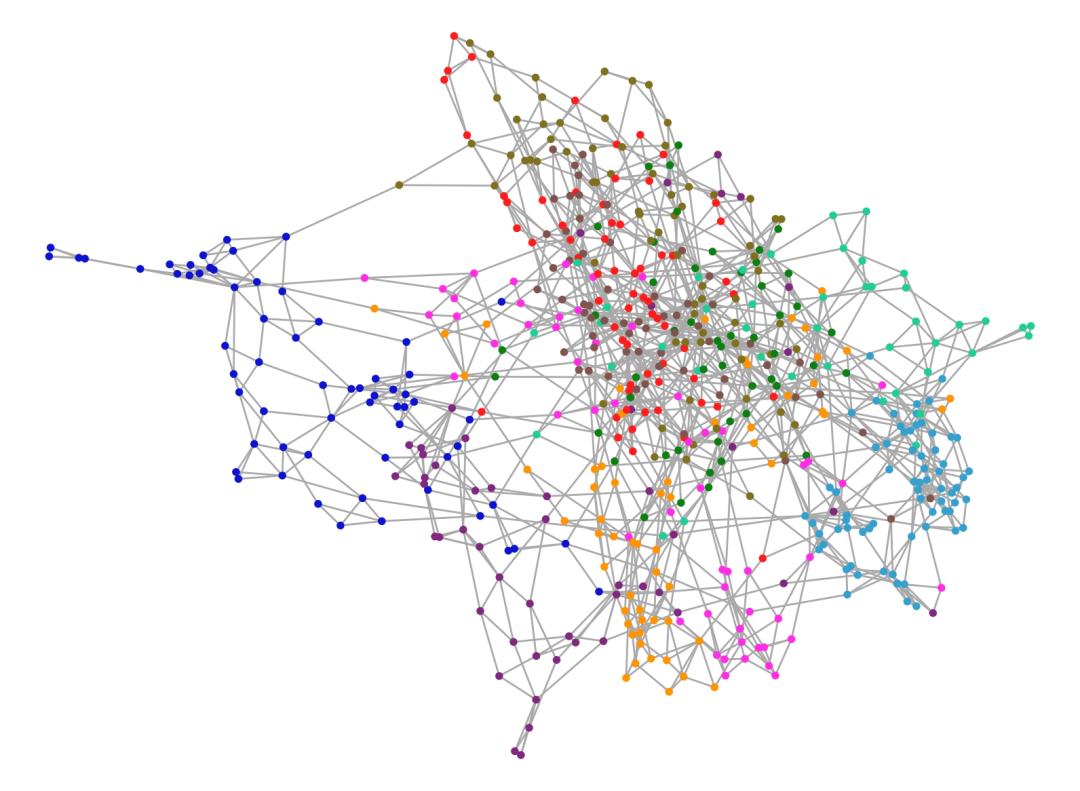
上图是对于MINST神经网络输入层数据的可视化图像(784维)。图中每一个节点都表示一张图片,用一个784维的向量表示;图中每一种颜色表示0到9数字中的一个,相当于节点总共有10种分类。我们可以看出:
MNIST的原始数据集中,自发展示出了一些结构。表示相同数字的节点,它们在原784维空间中,也会比较接近,因此会自然地聚集成簇。比如,左侧的蓝色节点群,表示数字0;右下角的靛蓝色节点群,表示数字1;而左下角的绛紫色节点群,表示数字6。
中间右侧有多种不同类的节点混杂的一起。比如,表示数字9的红色节点,表示数字7的深褐色节点,还有表示数字4的黄绿色节点,相互交织在一起。这表示它们不太容易互相区分开。

上图则是对于MINST神经网络中间隐藏层输出数据的可视化图像(128维)。图中每一个节点还是对应一张图片(即对应原始图片数据经过了隐藏层的变换之后的数据),变成了用一个128维的向量表示;图中每一种颜色仍是表示0到9数字中的一个,还是总共有10种分类。我们可以看出:
与前面的MINST原始输入数据相比,节点的混乱程度降低了(我们也可以说,熵值降低了)。这也包括在前面图像中混杂在一起的数字7、数字4和数字9,现在它们都各自聚集成簇了:左侧突出来的深褐色节点群,是数字7;左上角的黄绿色节点群,是数字4;红色节点群,是数字9。这表示更容易把它们相互分开了。

上图是对于MINST神经网络最终的输出层输出数据(经过了softmax处理之后的)的可视化图像(10维)。图中每一个节点还是对应一张图片(即对应原始图片数据经过了整个神经网络的变换之后的数据),变成了一个只有10维的向量;图中每一种颜色仍是表示0到9数字中的一个,还是总共有10种分类。我们可以看出:
节点混乱程度极大降低,每类数字都各自聚集在一起。考虑到这张图像里面的节点数量跟前面两张图像里面的节点数量是完全一样的,但散布空间小了很多,说明按照分类的聚集程度达到了很高的程度。实际上,这时候只需要对最后这个10维向量做一个简单的argmax判断,就可以以很高的准确率识别出具体数字了。这表示,最后的输出具有很高的「可分」度。
在本文中,通过对神经网络的可视化研究,我们发现:从原始的特征输入出发,神经网络每经过一层的变换处理,都在抽象程度上离问题的目标更接近一点。拿MNIST的手写体数字识别问题来说,目标是一个多分类问题,即把图片归到0到9这10个类别中的一个。最开始输入的是原始的图片像素数据,每经过一次网络层变换处理之后,数据就变得比原来更「可分」一点,也就是离分类的目标更接近一点。
这是一种典型的对信息进行整合的过程。就像许多现实世界中的情形一样,庞杂的细节,只有经过有效地整合,我们才能获得真正的「感知」或「认知」。
而对于类似图像识别这样的简单的感知行为,人类甚至意识不到这个信息整合过程的存在。把人眼看到物体这个过程拆解开来看,物理世界的光子进入人眼感光细胞,会产生大量的细节数据。而这些数据势必经过了人脑中一个类似神经网络(肯定比神经网络更高级)的结构来处理,将这些细节数据经过整合之后,才让我们在宏观层面认识到眼前看到了什么物体。对人脑来说,这个过程是瞬间发生的,它快速、准确,而且低能耗。如果我们要设计一种能识别物体的模型,最好的方法也许是完全复制人脑的处理机制。但这些机制都是未知,或者至少我们所知非常有限。因此,我们只能近似、参考、模仿人脑的机制。
最后,我们今天所讨论的可视化技术,只是对于机器学习追求可解释性的技术(Interpretability Techniques)中非常初级的一部分。它可能会对我们如何修正现有模型或者如何更好地训练模型,提供参考价值,但是,它很可能无法帮助我们从头发明出一个颠覆式的学习机制。就像我们在上一篇文章《程序员眼中的「技术-艺术」光谱》中所讨论的那样,新模型的设计,或者一种崭新学习机制的发明,仍然是一门需要灵感的「艺术」。
(正文完)
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」,与我互动。
参考文献:
[1] https://github.com/antirez/neural-redis
[2] MNIST data set. http://yann.lecun.com/exdb/mnist/
[3] Computes the (weighted) graph of k-Neighbors. https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.kneighbors_graph.html
[4] Fruchterman-Reingold force-directed algorithm.https://networkx.github.io/documentation/stable/reference/generated/networkx.drawing.layout.spring_layout.html#networkx.drawing.layout.spring_layout
其它精选文章:
在技术和业务中保持平衡
用统计学的观点看世界:从找不到东西说起底
优化理论简介
深度学习、信息论与统计学
科学精神与互联网A/B实验
蓄力十年,做一个成就
三个字节的历险
漫谈分布式系统、拜占庭将军问题与区块链
知识的三个层次
扫码或长按关注微信公众号:张铁蕾。

有时候写点技术干货,有时候写点有趣的文章。
这个公众号有点科幻。
Python爬虫超详细讲解,零基础入门,老年人都看得懂
讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
为什么我们要使用爬虫
互联网大数据时代,给予我们生活的便利以及海量数据爆炸式地出现在网络中。
过去,我们通过书籍、报纸、电视、广播或许信息,这些信息数量有限,且是经过一定的筛选,信息相对而言比较有效,但是缺点则是信息面太过于狭窄了。不对称的信息传导,以致于我们视野受限,无法了解到更多的信息和知识。
互联网大数据时代,我们突然间,信息获取自由了,我们得到了海量的信息,但是大多数都是无效的垃圾信息。
例如新浪微博,一天产生数亿条的状态更新,而在百度搜索引擎中,随意搜一条——减肥100,000,000条信息。
在如此海量的信息碎片中,我们如何获取对自己有用的信息呢?
答案是筛选!
通过某项技术将相关的内容收集起来,在分析删选才能得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等……都能够借助这个技术获取更精准有效的信息加以利用。
网络爬虫技术,虽说有个诡异的名字,让能第一反应是那种软软的蠕动的生物,但它却是一个可以在虚拟世界里,无往不前的利器。
爬虫准备工作
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP,JAVA,C#,C++,Python,选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
首先我们需要下载python,我下载的是官方最新的版本 3.8.3
其次我们需要一个运行Python的环境,我用的是pychram
也可以从官方下载,
我们还需要一些库来支持爬虫的运行(有些库Python可能自带了)
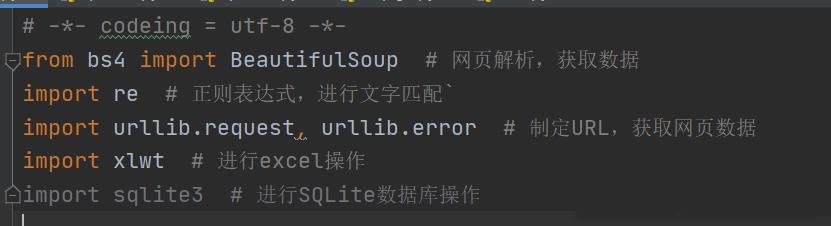
差不多就是这几个库了,良心的我已经在后面写好注释了

(爬虫运行过程中,不一定就只需要上面几个库,看你爬虫的一个具体写法了,反正需要库的话我们可以直接在setting里面安装)
爬虫项目讲解
我做的是爬取豆瓣评分电影Top250的爬虫代码
我们要爬取的就是这个网站:
https://movie.douban.com/top250
这边我已经爬取完毕,给大家看下效果图,我是将爬取到的内容存到xls中

我们的爬取的内容是:电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息。
代码分析
先把代码发放上来,然后我再根据代码逐步解析
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\\s+)?/>(\\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")
下面我根据代码,从上到下给大家讲解分析一遍

– codeing = utf-8 --,开头的这个是设置编码为utf-8 ,写在开头,防止乱码。
然后下面 import就是导入一些库,做做准备工作,(sqlite3这库我并没有用到所以我注释起来了)。
下面一些find开头的是正则表达式,是用来我们筛选信息的。
(正则表达式用到 re 库克,也可以不用正则表达式,不是必须的。)
大体流程分三步走:
1. 爬取网页
2.逐一解析数据
3. 保存网页
先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
这段时间大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。

然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观的感受
def askURL(url):
head = # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?

这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度一下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶

所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。

来,我们继续往下走,
html = response.read().decode("utf-8")
这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果

成了,成了!

如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦
本篇文章讲解到这里啦,我感觉我讲的还算细致吧,爬虫我也是最近才可以学,对这个比较有兴趣,我肯定有讲的不好的地方,欢迎各位大佬来指正我 。
我也在不断的学习中,学到新东西第一时间会跟大家分享
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


这份完整版的Python全
以上是关于看得见的机器学习:零基础看懂神经网络的主要内容,如果未能解决你的问题,请参考以下文章