智能写作v2.0
Posted 无界社区mixlab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能写作v2.0相关的知识,希望对你有一定的参考价值。

- 主要涉及的NLP技术
智能写作
智能写作,指人工智能模型自己能根据一定的条件或者是无任何条件下自由地生成内容。
因为很多文章的写作都需要投入不小的精力,但是阅读量却非常小,这样的内容投入产出效率就比较低。
这部分内容如果用机器来创作的话,成本就会比人来写小很多。
比如今日头条开发的写作机器人开始时是做奥运比赛的报道,把实时的比分、图片、热门比赛的文字直播结合起来生成对应文章,后来延伸到了包括更多的体育赛事、房产新闻以及国际热点新闻的报道。
我们让计算机写文章,可以直接用现成的工具 GPT-3,也可以自己训练模型来实现。
现成工具:GPT - 3
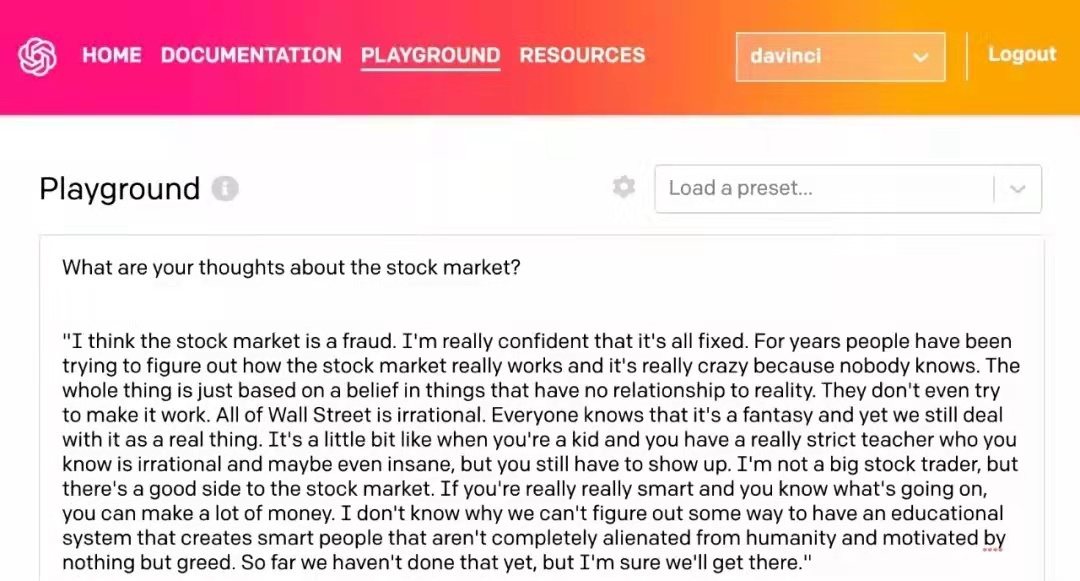
比如问 GPT-3:你对股票市场是怎么看的?
- What are your thoughts about the stock market?
GPT-3 自动生成的结果是这样的:
比如,让 GPT-3 根据命题 “上 Twitter 的重要性” 为题,做分析:

文章有观点、有立场、有理有据,符合逻辑,和真人写出来的没什么差异。
······
使用 GPT-3 前,必须要先取得Open AI 授与的 API Secret key。
可以用下面的连接申请,填完表以后,等待Open AI 的邀请(我等了三个月)。
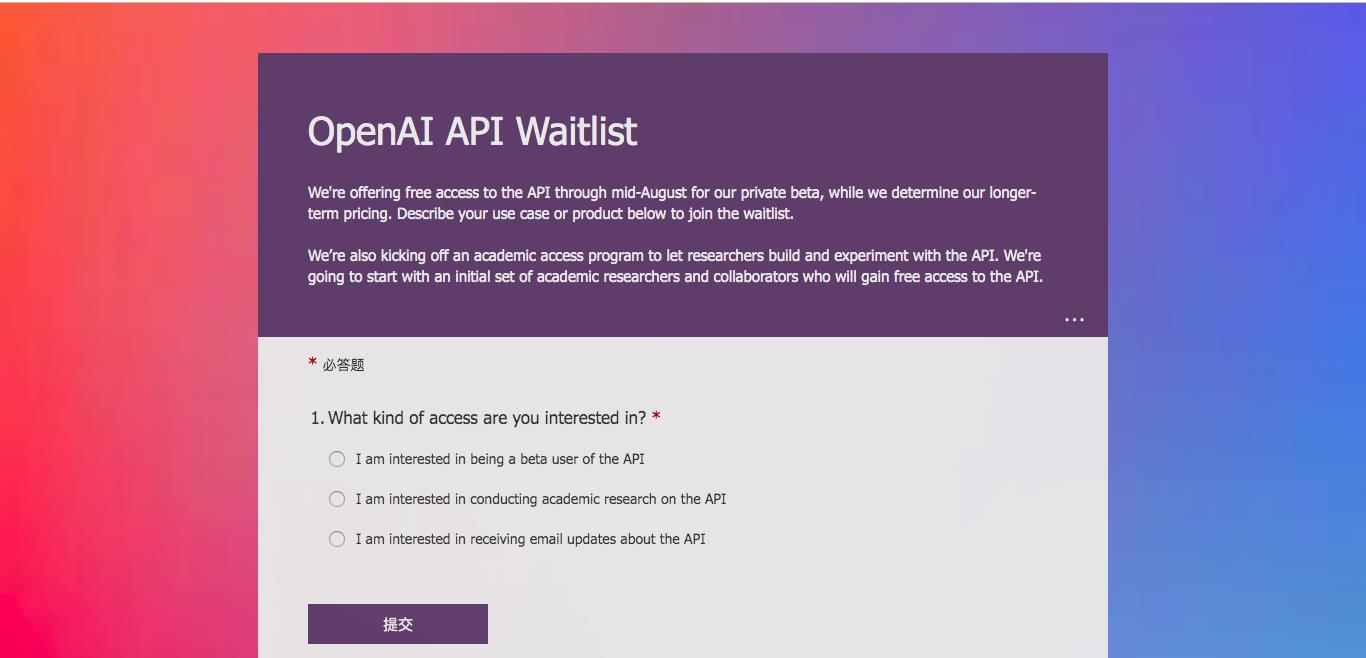
获邀以后,就可用下面的连接注册,然后取得你的API Secret key。
有了API Secret key就可用编程,比如给一个开头语:Once upon a time(很久以前),让 GPT-3说故事。
使用 GPT-3时,有两个变数可用:模式和温度。
- 模式有四种选择 :ada、babbage、curie、davinci,通常davinci 是最好的选择。
- 温度是用来决定创意,数字越大表示文字的创造力越强。
温度 0.0
- Once upon a time, there was a little girl who was very sad. She was sad because she had no friends. She was sad because she had no one to play with. She was sad because she had no one to talk to. She was sad because she had no one to love.
温度 1.2
- Once upon a time, I moved from Ukraine to London. The journey is supposed to be a very difficult one: 24 hours of travelling in opposite direction and time changes of 2 hours. The border is different too: from Europe into the EFTA countries is like entering a different continent. All the signs, money and communication seemed to be in a new language. But, I actually managed to arrive on a new country calmly: 0 defeats, no panic attacks or anxiety. It all happened thanks to Orto (Arktan2) and his absolutely great methods.
······
其实,GPT-3 支持中文。
一个最好的参考网站就是 GPT-3 Demo:https://gpt3demo.com/。
人工智能文案(AI Copywriting)是目前人们在 GPT-3 上用的最多的一个商业应用,在 GPT-3 Demo 中就有 34 个产品。这些商业应用产品绝大部分是要付费的,但是它们也提供免费的试用期间。
在 34 个人工智能文案产品中,有三个产品强烈推荐:
-
Shortly AI:https://shortlyai.com/?fp_ref=earlybird
比如,用上面的 CopyAI 给另一半写生日快乐的文稿:
-
你一直是我生命中快乐和欢笑的源泉。有你在我的生命中,我感到非常幸运。我想让你知道,我感谢你为我所做的一切。你是我生命中最耀眼的明星,生日快乐。
-
今天是你的生日。我真诚地祝愿你幸福和健康。希望你能得到生活中所有最好的东西。
-
我没有什么可说的了,只是说我爱你胜过一切!。愿你的生日充满一生的幸福。
-
你一直是我的力量支柱,在我需要你的支持时,你从未怀疑过我。没有你,我将一事无成。我祈祷上帝继续将他的祝福洒在你身上。生日快乐!
智能取名
恐龙起名哪家强?
实现一个为恐龙起名的程序,这个程序是一个字(母)级别的 RNN 模型,也就是 RNN 的每个时间步只输出一个字(母)。
训练模型前,我们需要爬取一些恐龙的名字,像霸王龙(Tyrannosaurus)、迅猛龙(Velociraptor)。
- 恐龙名字数据集:
直接秀代码吧 — 以下是项目完整代码(自定义工具模块 + 项目代码模块)。
自定义工具模块:
# utils.py
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def smooth(loss, cur_loss):
return loss * 0.999 + cur_loss * 0.001
def print_sample(sample_ix, ix_to_char):
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
txt = txt[0].upper() + txt[1:]
print ('%s' % (txt, ), end='')
def get_initial_loss(vocab_size, seq_length):
return -np.log(1.0/vocab_size)*seq_length
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def initialize_parameters(n_a, n_x, n_y):
np.random.seed(1)
Wax = np.random.randn(n_a, n_x)*0.01
Waa = np.random.randn(n_a, n_a)*0.01
Wya = np.random.randn(n_y, n_a)*0.01
b = np.zeros((n_a, 1))
by = np.zeros((n_y, 1))
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b,"by": by}
return parameters
def rnn_step_forward(parameters, a_prev, x):
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
a_next = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b) # hidden state
p_t = softmax(np.dot(Wya, a_next) + by)
return a_next, p_t
def rnn_step_backward(dy, gradients, parameters, x, a, a_prev):
gradients['dWya'] += np.dot(dy, a.T)
gradients['dby'] += dy
da = np.dot(parameters['Wya'].T, dy) + gradients['da_next']
daraw = (1 - a * a) * da
gradients['db'] += daraw
gradients['dWax'] += np.dot(daraw, x.T)
gradients['dWaa'] += np.dot(daraw, a_prev.T)
gradients['da_next'] = np.dot(parameters['Waa'].T, daraw)
return gradients
def update_parameters(parameters, gradients, lr):
parameters['Wax'] += -lr * gradients['dWax']
parameters['Waa'] += -lr * gradients['dWaa']
parameters['Wya'] += -lr * gradients['dWya']
parameters['b'] += -lr * gradients['db']
parameters['by'] += -lr * gradients['dby']
return parameters
def rnn_forward(X, Y, a0, parameters, vocab_size = 27):
x, a, y_hat = {}, {}, {}
a[-1] = np.copy(a0)
loss = 0
for t in range(len(X)):
x[t] = np.zeros((vocab_size,1))
if (X[t] != None):
x[t][X[t]] = 1
a[t], y_hat[t] = rnn_step_forward(parameters, a[t-1], x[t])
loss -= np.log(y_hat[t][Y[t],0])
cache = (y_hat, a, x)
return loss, cache
def rnn_backward(X, Y, parameters, cache):
gradients = {}
(y_hat, a, x) = cache
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
gradients['dWax'], gradients['dWaa'], gradients['dWya'] = np.zeros_like(Wax), np.zeros_like(Waa), np.zeros_like(Wya)
gradients['db'], gradients['dby'] = np.zeros_like(b), np.zeros_like(by)
gradients['da_next'] = np.zeros_like(a[0])
for t in reversed(range(len(X))):
dy = np.copy(y_hat[t])
dy[Y[t]] -= 1
gradients = rnn_step_backward(dy, gradients, parameters, x[t], a[t], a[t-1])
return gradients, a
项目代码:
import numpy as np
from utils import *
import random
data = open('dinos.txt', 'r').read()
data = data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
char_to_ix = { ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = { i:ch for i,ch in enumerate(sorted(chars)) }
# 梯度值裁剪函数
def clip(gradients, maxValue):
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
# 采样函数
def sample(parameters, char_to_ix, seed):
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
x = np.zeros((vocab_size, 1))
a_prev = np.zeros((n_a, 1))
indices = []
idx = -1
counter = 0
newline_character = char_to_ix['\\n']
while (idx != newline_character and counter != 50):
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
np.random.seed(counter + seed)
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
indices.append(idx)
x = np.zeros((vocab_size, 1))
x[idx] = 1
a_prev = a
seed += 1
counter +=1
if (counter == 50):
indices.append(char_to_ix['\\n'])
return indices
np.random.seed(2)
_, n_a = 20, 100
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
# 优化函数
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
loss, cache = rnn_forward(X, Y, a_prev, parameters)
gradients, a = rnn_backward(X, Y, parameters, cache)
gradients = clip(gradients, 5)
parameters = update_parameters(parameters, gradients, learning_rate)
return loss, gradients, a[len(X)-1]
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [None,3,5,11,22,3]
Y = [3,5,11,22,3,0]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
def model(ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
n_x, n_y = vocab_size, vocab_size
parameters = initialize_parameters(n_a, n_x, n_y)
loss = get_initial_loss(vocab_size, dino_names)
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
np.random.seed(0)
np.random.shuffle(examples)
a_prev = np.zeros((n_a, 1))
for j in range(num_iterations):
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\\n"]]
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
loss = smooth(loss, curr_loss)
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\\n')
seed = 0
for name in range以上是关于智能写作v2.0的主要内容,如果未能解决你的问题,请参考以下文章