特征提取+分类模型4种常见的NLP实践思路
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征提取+分类模型4种常见的NLP实践思路相关的知识,希望对你有一定的参考价值。
每日干货 & 每月组队学习,不错过
作者:陈琰钰,清华大学,Datawhale成员
越来越多的人选择参加算法赛事,为了提升项目实践能力,同时也希望能拿到好的成绩增加履历的丰富度。期望如此美好,现实却是:看完赛题,一点思路都木有。那么,当我们拿到一个算法赛题后,如何破题,如何找到可能的解题思路呢。
本文针对NLP项目给出了4种常见的解题思路,其中包含1种基于机器学习的思路和3种基于深度学习的思路。
一、数据及背景
https://tianchi.aliyun.com/competition/entrance/531810/information(阿里天池-零基础入门NLP赛事)
我们直接打开数据下载地址,看到的是这样一个页面:
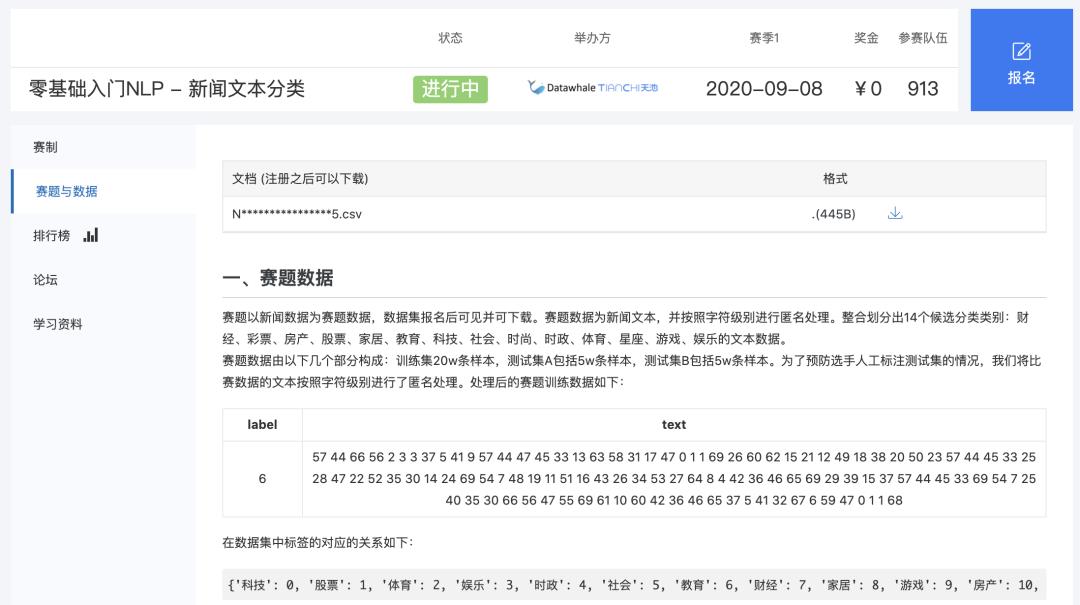
接着就三步走:注册报名下载数据,查看数据前五行可以看到我们获得的数据如下:
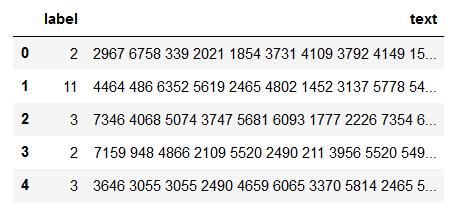
其中左边的label是数据集文本对应的标签,而右边的text则是编码后的文本,文本对应的标签列举如下:

同时我们还应该注意到官网有给出结果评价指标,我们也需要根据这个评价指标衡量我们的验证集数据误差:

既然该拿到的我们都拿到了,我们接下来就开始构思我们都应该使用哪些思路来完成我们的预测。
2.2 常见思路
因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。为了减低参赛难度,我们提供了一些解题思路供大家参考:
思路4:Bert词向量:Bert是高配款的词向量,具有强大的建模学习能力。
三、基于机器学习的文本分类
3.1 TF-IDF+机器学习分类器(思路1)
3.1.1. 什么是TF-IDF?
当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。
3.2.2. TF-IDF算法步骤
第一步,计算词频:


这时,需要一个语料库(corpus),用来模拟语言的使用环境。
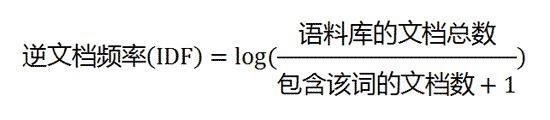
第三步,计算TF-IDF:
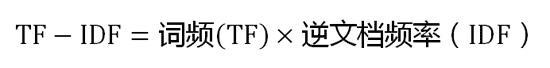
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
3.3.3. 优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。
四、基于深度学习的文本分类
4.1 FastText(思路2)
4.1.1 FastText的核心思想
将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级N-gram特征的引入以及分层Softmax分类。
4.1.2 字符级N-gram特征
我来到达观数据参观
相应的bigram特征为:我来 来到 到达 达观 观数 数据 据参 参观
相应的trigram特征为:我来到 来到达 到达观 达观数 观数据 数据参 据参观
注意一点:n-gram中的gram根据粒度不同,有不同的含义。它可以是字粒度,也可以是词粒度的。上面所举的例子属于字粒度的n-gram,词粒度的n-gram看下面例子:
我 来到 达观数据 参观
相应的bigram特征为:我/来到 来到/达观数据 达观数据/参观
相应的trigram特征为:我/来到/达观数据 来到/达观数据/参观
4.1.3 分层Softmax分类
下图是一个分层Softmax示例:
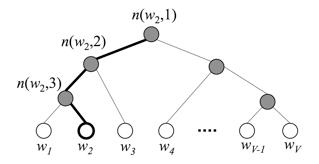
通过分层的Softmax,计算复杂度一下从|K|降低到log|K|。
4.2 Word2Vec+深度学习分类器(思路3)
4.2.1 Word2Vec
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
4.2.2 优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
1、Negative Sample(负采样)
2、Hierarchical Softmax
4.2.3 优缺点
优点:
由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
比之前的 Embedding方 法维度更少,所以速度更快
通用性很强,可以用在各种 NLP 任务中
缺点:
由于词和向量是一对一的关系,所以多义词的问题无法解决。
Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
4.3 Bert词向量(思路4)
BERT(Bidirectional Encoder Representations from Transformers)词向量模型,2018年10月在《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》这篇论文中被Google提出,在11种不同nlp测试中创出最佳成绩,包括将glue基准推至80.4%(绝对改进7.6%),multinli准确度达到86.7% (绝对改进率5.6%)等。
4.1.1 特征
1、通过联合调节所有层中的左右上下文来预训练深度双向表示
2、the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many systems with task-specific architectures
3、所需计算量非常大。Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。
4、预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的state-of-the-art模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
5、一词多义问题

数据预处理:分类变量实体嵌入做特征提取
实体嵌入(embedding)目的将表格数据中的分类属性(一个至多个)向量化。
1.实体嵌入简介:
- 实体嵌入是主要应用于深度学习中处理表格分类数据的一种技术,或者更确切地说NLP领域最为火爆,word2vec就是在做word的embedding。
- 神经网络相比于当下的流行的xgboost、LGBM等树模型并不能很好地直接处理大量分类水平的分类特征。因为神经网络要求输入的分类数据进行one-hot处理。当分类特征的水平很高的时候,one-hot经常带来维度爆炸问题,紧接着就是参数爆炸,局部极小值点更多,更容易产生过拟合等等一系列问题。
- 实体嵌入是从降维这一角度来考虑改善这些问题的。它通过将分类属性放入网络的全连接层的输入单元中,后接几个单元数较输入层更少的隐藏层(连续型变量直接接入第一个隐藏层),经过神经网络训练后输出第一个隐藏层中分类变量关联的隐层单元,作为提取的特征,用于各种模型的输入。
2.用实体嵌入做特征提取的网络结构(示例)
(暂略)
3.实体嵌入代码(示例)
1 2 3 import math 4 import random as rn 5 import numpy as np 6 from keras.models import Model 7 from keras.layers import Input, Dense, Concatenate, Reshape, Dropout 8 from keras.layers.embeddings import Embedding 9 10 11 #传入分类变量数据(没有one-hot)和连续变量数据,返回一个model对象(它根据数据的组成定义好了网络框架类,这个类之后可以调用,喂入数据训练) 12 def build_embedding_network(category_data, continus_data): 13 14 #获取分类变量的名称 15 cat_cols = [x for x in category_data.columns] 16 17 #以字典形式存储分类变量的{名称:维度} 18 category_origin_dimension = [math.ceil(category_data[cat_col].drop_duplicates().size) for cat_col in cat_cols] 19 20 #以字典形式存储分类变量 计划 在embed后的{名称:维度} 21 category_embedding_dimension = [math.ceil(math.sqrt(category_data[cat_col].drop_duplicates().size)) for cat_col in cat_cols] 22 23 # 以网络结构embeddding层在前,dense层(全连接)在后;2.训练集的X必须以分类特征在前,连续特征在后。 24 inputs = [] 25 embeddings = [] #嵌入层用list组织数据 26 27 #对于每一个分类变量,执行以下操作 28 for cat_val, cat_origin_dim, cat_embed_dim in list(zip(cat_cols, category_origin_dimension, category_embedding_dimension)) : 29 30 # 实例化输入数据的张量对象 31 input_cate_feature = Input(shape=(1,)) #batch_size, 空(维度) 32 33 #实例化embed层的节点:定义输入的维度(某个分类变量的onehot维度),输出的维度(其embed后的维度),同时传入input数据对象 34 embedding = Embedding(input_dim = cat_origin_dim, 35 output_dim = cat_embed_dim, 36 input_length=1)(input_cate_feature) 37 38 # 将embed层输出的形状调整 39 embedding = Reshape(target_shape=(cat_embed_dim,))(embedding) 40 41 #每遍历一个分类变量就将输入数据添加在inputs对象中 42 inputs.append(input_cate_feature) 43 44 #每遍历一个分类变量就扩展一个embedding层的节点 45 embeddings.append(embedding) 46 47 #dda于连续特征执行以下操作: 48 49 #获取连续特征的变量个数 50 cnt_val_num = continus_data.shape[1] 51 #连续特征原封原样迭代地加入与分类变量embedding后的输出组合在一起(没有embedding操作) 52 for cnt_val_num in range(cnt_val_num) : 53 input_numeric_features = Input(shape=(1,)) 54 55 #输入的连续型数据不经过任何一种激活函数处理直接 与embed + reshape后的分类变量进行组合 56 embedding_numeric_features = Dense(units = 16)(input_numeric_features) 57 inputs.append(input_numeric_features) 58 embeddings.append(embedding_numeric_features) 59 60 #把有不同输入的embedding 层的数据链接在一起 61 x = Concatenate()(embeddings) #这种写法表明concatenate返回的是一个函数,第二个括号是传入这个返回的函数的参数 62 63 x = Dense(units = 16, activation=‘relu‘)(x) 64 65 #丢弃15%的节点 66 x = Dropout( 0.15 )(x) 67 68 #输出层包含一个节点,激活函数是relu 69 output = Dense(1, activation=‘relu‘)(x) 70 model = Model(inputs, output) 71 model.compile(loss=‘mean_squared_error‘, optimizer=‘adam‘) 72 73 return model 74 75 76 # 训练 77 NN = build_embedding_network(category_features_in_trainset, continus_features_in_trainset ) 78 NN.fit(X, y_train, epochs=3, batch_size=40, verbose=0) 79 80 #读取embedding层数据 81 cate_feature_num = category_features_in_trainset.columns.size 82 83 model = NN # 创建原始模型 84 for i in range(cate_feature_num): 85 # 如果把类别特征放前,连续特征放后,cate_feature_num+i就是所有embedding层 86 layer_name = NN.get_config()[‘layers‘][cate_feature_num+i][‘name‘] 87 88 intermediate_layer_model = Model(inputs=NN.input, 89 outputs=model.get_layer(layer_name).output) 90 91 # numpy.array 92 intermediate_output = intermediate_layer_model.predict(X) 93 94 intermediate_output.resize([train_data.shape[0],cate_embedding_dimension[i][1]]) 95 96 if i == 0: #将第一个输出赋值给X_embedding_trans,后续叠加在该对象后面 97 X_embedding_trans = intermediate_output 98 else: 99 X_embedding_trans = np.hstack((X_embedding_trans,intermediate_output)) #水平拼接 100 101 102 #显示分类变量向量化后的数据 103 X_embedding_trans
4.个人观点
高levels的分类变量而言,多是用户ID、地址、名字等。变量如‘地址’可以通过概念分层的办法获取省、市之类的维度较少的特征;‘商品’也可以通过概念分层获取其更泛化的类别,但是这种操作实质是在平滑数据,很可能淹没掉有用的信息。我可能不会选择这种方式来建立预测模型(做细分统计、透视图的时候会经常使用到)。也有的人会不用这些分类变量,但是我觉得会损失一些有用的影响因素,所以最好物尽其用。
实体嵌入跟word2vector一样会让output相似的对象在隐藏层中的数值也相近。使用低纬度、连续型变量的数据训练模型,效果也会比用高维、稀疏的数据训练好得多。
这种针对分类变量特征提取的方法对于提升预测准确率来说是很有效的,跟模型堆叠一样有效。
以上是关于特征提取+分类模型4种常见的NLP实践思路的主要内容,如果未能解决你的问题,请参考以下文章