开源 BiT:探索计算机视觉的大规模预训练
Posted 雨夜的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源 BiT:探索计算机视觉的大规模预训练相关的知识,希望对你有一定的参考价值。
计算机视觉研究人员的普遍感觉是,现代深层神经网络总是渴望更多的标签数据-国家的最先进的电流细胞神经网络需要对接受培训数据集,例如OpenImages或Places,其中包含超过 100 万个标记图像。然而,对于许多应用程序,收集如此大量的标记数据可能会让普通从业者望而却步。
缓解计算机视觉任务缺少标记数据的一种常见方法是使用已在通用数据上预先训练的模型(例如ImageNet)。这个想法是在通用数据上学习的视觉特征可以重新用于感兴趣的任务。尽管这种预训练在实践中效果很好,但它仍然缺乏快速掌握新概念并在不同上下文中理解它们的能力。与BERT和T5在语言领域表现出的进步类似,我们相信大规模预训练可以提高计算机视觉模型的性能。
在“ Big Transfer (BiT): General Visual Representation Learning ”中,我们设计了一种方法,使用超出事实标准(ILSVRC-2012)的图像数据集对一般特征进行有效的预训练)。In particular, we highlight the importance of appropriately choosing normalization layers and scaling the architecture capacity as the amount of pre-training data increases. 我们的方法展现出前所未有的性能,适用于广泛的新视觉任务,包括少镜头识别设置和最近推出的“真实世界” ObjectNet基准测试。我们很高兴与大家分享在公共数据集上预训练的最佳 BiT 模型,以及TF2、Jax 和 PyTorch 中的代码。这将允许任何人在他们感兴趣的任务上达到最先进的性能,即使每个类只有少量标记图像。
预训练为了研究数据规模的影响,我们使用三个数据集重新审视了预训练设置的常见设计选择(例如激活和权重的归一化、模型宽度/深度和训练计划):ILSVRC-2012(1.28M 图像与1000 个类)、ImageNet-21k(1400 万张图片,约 21k 类)和JFT(3亿张图片,约 18k 类)。重要的是,通过这些数据集,我们专注于以前未充分探索的大数据机制。
我们首先研究数据集大小和模型容量之间的相互作用。为此,我们训练经典ResNet架构,性能良好,同时简单且可重复。我们在上述每个数据集上训练从标准 50 层深度“R50x1”到 4 倍宽和 152 层深度“R152x4”的变体。一个关键观察是,为了从更多数据中获利,还需要增加模型容量。下图左侧面板中的红色箭头说明了这一点

第二个更重要的观察是训练持续时间变得至关重要。如果在一个更大的数据集上预训练而不调整计算预算和训练时间,性能可能会变得更糟。但是,通过使计划适应新的数据集,改进可能是显着的。
在我们的探索阶段,我们发现了另一个对提高性能至关重要的修改。我们表明,替换批标准化(BN,即通常使用的层通过正火激活稳定训练)与组归一化(GN) 有利于大规模的预训练。首先,BN 的状态(神经激活的均值和方差)需要在预训练和转移之间进行调整,而 GN 是无状态的,因此避开了这个困难。其次,BN 使用批量级别的统计数据,这对于大型模型不可避免的每设备批量小而变得不可靠。由于 GN 不计算批次级别的统计数据,因此它也回避了这个问题。有关更多技术细节,包括使用权重标准化技术来确保稳定的行为,请参阅我们的论文。

遵循BERT在语言领域建立的方法,我们根据来自各种“下游”感兴趣任务的数据对预训练的 BiT 模型进行微调,这些任务可能带有很少的标记数据。因为预先训练的模型已经很好地理解了视觉世界,所以这个简单的策略非常有效。
微调有很多超参数可供选择,例如学习率、权重衰减等。我们提出了一种启发式来选择这些超参数,我们称之为“BiT-HyperRule”,这仅基于高级数据集特征,例如图像分辨率和标记示例的数量。我们成功地将 BiT-HyperRule 应用于 20 多种不同的任务,从自然图像到医学图像。
当将 BiT 转移到具有很少示例的任务时,我们观察到,随着我们同时增加用于预训练和架构容量的通用数据量,生成的模型适应新数据的能力显着提高。在 1-shot 和 5-shot CIFAR(见下图)上,在 ILSVRC(绿色曲线)上进行预训练时,增加模型容量产生的回报有限。然而,通过在 JFT 上进行大规模预训练,模型容量的每一次提升都会产生巨大的回报(棕色曲线),直到 BiT-L 达到 64% 的 1-shot 和 95% 的 5-shot。

为了更普遍地验证这个结果,我们还在VTAB-1k上评估了 BiT ,这是一套 19 个不同的任务,每个任务只有 1000 个标记的例子。我们将 BiT-L 模型转移到所有这些任务中,总体得分为 76.3%,与之前的最新技术相比绝对提高了 5.8% 。
我们通过在牛津宠物和花卉、CIFAR等几个标准计算机视觉基准上评估 BiT-L,表明即使在有适量数据可用时,这种大规模预训练和简单转移的策略也是有效的。其中,BiT-L 达到或超过了最先进的结果。最后,我们使用 BiT 作为主干RetinaNet在MSCOCO-2017检测任务上,并确认即使对于这样的结构化输出任务,使用大规模预训练也有很大帮助。

需要强调的是,在我们考虑的所有不同下游任务中,我们不执行每个任务的超参数调整,而是依赖于BiT-HyperRule。正如我们在论文中所展示的,通过在足够大的验证数据上调整超参数可以获得更好的结果。
使用 ObjectNet进行评估 为了在更具挑战性的场景中进一步评估BiT的稳健性,我们评估了在最近推出的ObjectNet上的 ILSVRC-2012 上微调的 BiT 模型数据集。该数据集非常类似于现实世界的场景,其中对象可能出现在非典型的上下文、视点、旋转等中。有趣的是,随着 BiT-L 模型达到前所未有的 80.0 的 top-5 准确率,数据和架构规模的好处更加明显%,比之前的最先进技术提高了近 25% 。

我们表明,给定对大量通用数据的预训练,一个简单的转移策略会导致令人印象深刻的结果,无论是在大型数据集上还是在数据很少的任务上,每类只有一个图像。我们发布了 BiT-M 模型,一个在 ImageNet-21k 上预训练的 R152x4,以及用于在 Jax、TensorFlow2 和 PyTorch 中传输的 colab。除了代码发布之外,我们还向读者推荐了有关如何使用 BiT 模型的TensorFlow2动手教程。我们希望从业者和研究人员发现它可以替代常用的 ImageNet 预训练模型。
清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!...
关注公众号,发现CV技术之美

我爱计算机视觉
专业计算机视觉技术分享平台,“有价值有深度”,分享开源技术与最新论文解读,传播视觉技术的业内最佳实践。知乎/微博:我爱计算机视觉,官网 www.52cv.net 。KeyWords:深度学习、机器学习、计算机视觉、人工智能。
公众号
本篇分享论文『CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers』,油清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.15868
项目链接:https://github.com/THUDM/CogVideo
01
摘要
大规模预训练Transformer在文本(GPT-3)和文本到图像(DALL-E和CogView)生成方面创造了里程碑。它在视频生成中的应用仍然面临着许多挑战:潜在的巨大计算成本使得从头开始的训练难以负担;文本视频数据集的稀缺性和弱相关性阻碍了模型对复杂运动语义的理解。
在这项工作中,作者提出了9B参数Transformer——CogVideo,通过继承预训练文本到图像模型CogView2进行训练。作者还提出了多帧率分层训练策略,以更好地对齐文本和视频片段。作为(可能)第一个开源的大规模预训练文本到视频模型,CogVideo在机器和人工评估方面大大优于所有公开可用的模型。
02
Motivation
自回归Transformer,如DALL-E和CogView,最近彻底改变了文本到图像的生成。研究自回归Transformer在文本到视频生成中的潜力是很自然的。之前的工作遵循这一基本框架,例如VideoGPT,验证了其优于基于GAN的方法,但仍远不能令人满意。
一个常见的挑战是,生成的视频帧往往会逐渐偏离文本提示,使生成的角色难以执行所需的操作。Vanilla自回归模型可能擅长合成具有规则(例如直线移动的汽车)或随机模式(例如,通过随机移动的嘴唇说话)的视频,但在文本提示上失败,例如“狮子正在喝水”。这两种情况之间的主要区别在于,在前一种情况下,第一帧已经为后续的更改提供了足够的信息,而在后一种情况下,模型必须准确理解“喝”的动作,以便正确生成所需的动作——狮子将玻璃杯举到嘴唇,喝下,然后放下玻璃杯。
为什么自回归Transformer很好地理解文本-图像关系,但却很难理解视频中的文本-动作关系?作者认为数据集和利用它们的方式是主要原因。
首先,可以从互联网上收集数十亿对高质量的文本图像,但文本视频数据更为稀缺。最大的带标注文本视频数据集VATEX只有41250个视频。基于检索的文本-视频对(如Howto100M)相关性较弱,大多数只描述场景,没有时间信息。
其次,视频的持续时间变化很大。以前的模型将视频分割为固定帧数的多个片段进行训练,这会破坏文本与其在视频中的时间对应物体之间的对齐。如果将一段“饮酒”视频分为四个单独的片段,分别是“拿着杯子”、“举起”、“饮酒”和“放下”,并使用相同的文本“饮酒”,那么模型将被混淆,无法了解饮酒的准确含义。

在本文中,作者提出了一个大规模的预训练文本到视频生成模型CogVideo,该模型有94亿个参数,在540万个文本-视频对上进行训练。为了继承从文本图像预训练中学习到的知识,作者基于预训练的文本到图像模型CogView2构建了CogVideo。
为了保证视频中文本与其时间对应物之间的对齐,作者提出了多帧率分层训练。文本条件的灵活性使得可以简单地将一段描述帧率的文本前置到原始文本提示中,以建模不同的帧率。为了保持文本视频对齐,作者选择适当的帧率描述,以便在每个训练样本中包含完整的动作。帧率token还控制生成中整个连续帧的更改强度。
具体来说,作者训练了序列生成模型和帧插值模型。前者根据文本生成关键帧,后者通过改变帧率递归填充中间帧,使视频连贯。如上图所示,CogVideo可以生成高分辨率(480×480)视频。人类评估表明,CogVideo在很大程度上优于所有公开可用的模型。本文的主要贡献如下:
提出CogVideo,它是通用领域中最大也是第一个用于文本到视频生成的开源预训练Transformer。
CogVideo优雅而高效地微调了文本到图像生成的预训练用于文本到图像的生成,避免了从头开始昂贵的完全预训练。
提出了多帧率分层训练来更好地对齐文本片段对,这显著提高了生成精度,尤其是对于复杂语义的运动。这种训练策略赋予CogVideo控制生成过程中变化强度的能力。
03
方法
作者首先在3.1节中介绍了多帧率分层训练,以更好地对齐文本和视频语义,然后在3.2节中说明了一种有效的方法,即双通道注意,以继承用于视频生成的预训练文本图像模型中的知识。为了克服大模型和长序列造成的大内存和时间开销,作者参考了Swin注意力,并将其扩展到3.3节中的自回归视频生成。
3.1 Multi-frame-rate Hierarchical Training
作者遵循VQV AE的框架,首先将每个帧token为图像token。每个训练样本由5帧token组成,但本文的训练方法在训练序列的构造和生成过程上有所不同。
Training
关键的设计是在文本和样本帧中添加一个帧率token,以此帧率组成一个固定长度的训练序列。动机有两个方面:
直接将长视频以固定的帧率分割成片段通常会导致语义不匹配。作者仍然使用了全部文本,但截断的片段可能只包含不完整的操作。
相邻帧通常非常相似。与前一帧相比的巨大变化可能会导致巨大的loss。这将导致模型不太倾向于探索长期相关性,因为简单地复制前一帧就像一条捷径。
因此,在每个训练样本中,作者希望文本和帧尽可能匹配。作者预定义了一系列帧速率,并为每个文本视频对选择最低帧率,所以作者在视频中以该帧率至少采样5帧。
尽管上述方法增加了文本和视频的对齐,但在低帧率下的生成可能不连贯。因此,作者训练另一个帧插值模型,将过渡帧插入到序列生成模型的生成样本中。由于CogLM的通用性,这两个模型可以共享相同的结构和训练过程,只需使用不同的注意力mask。
Generation
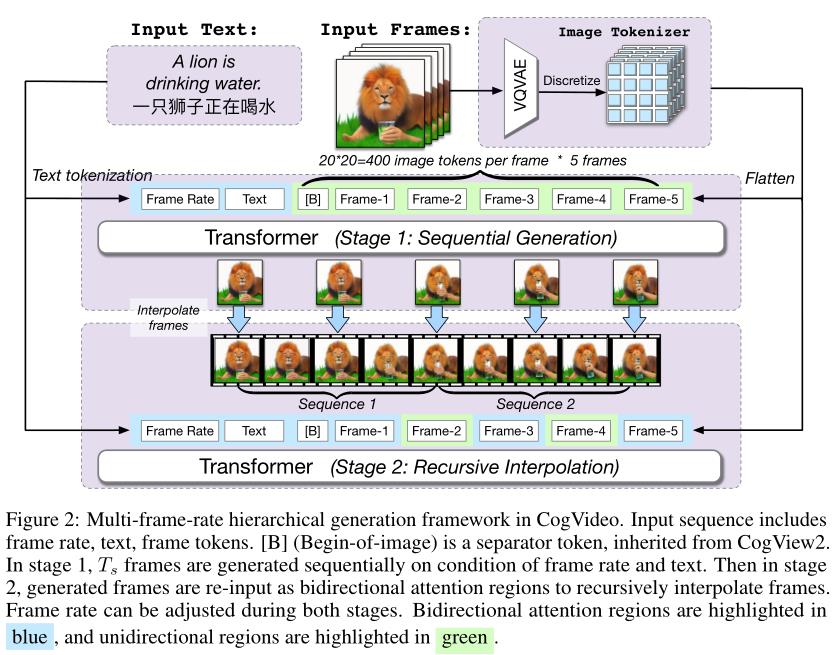
多帧率分层生成是一个递归过程,如上图所示。具体而言,生成管道包括顺序生成阶段和递归插值阶段:
基于低帧率和文本顺序生成个关键帧。输入序列是。在实验中,作者将设置为5,并将最小采样帧速率设置为1 fps。
基于文本、帧率和已知帧进行递归插值帧。输入序列是,其中帧将自动回归生成。通过递归对半,可以进行越来越精细的插值来生成多帧的视频。
The effect of CogLM
诸如帧插值之类的任务严重依赖于双向信息。然而,以前的大多数作品都使用GPT,这是单向的。为了了解双向上下文,作者采用了跨模态通用语言模型(CogLM)中将token划分为单向和双向注意区域的思想,将双向上下文感知mask预测和自回归生成结合起来。
双向区域可以处理所有双向区域,但单向区域可以处理所有双向区域和以前的单向区域。如上图所示,第1阶段中的所有帧以及第2阶段的第2、4帧,和所有其他帧都属于双向区域。这样,在文本和给定帧中充分利用双向注意上下文,而不会干扰自回归帧预测。
3.2 Dual-channel Attention
大规模的预训练通常需要大量的数据集。对于开放域文本到视频生成,理想情况下,需要数据集覆盖足够的文本-视频对,以推断视频和文本之间的空间和时间相关性。然而,收集高质量的文本-视频对通常是困难、昂贵和耗时的。
一个自然的想法是利用图像数据来促进空间语义的学习。Video Diffusion Model和NÜWA模型尝试将文本图像对添加到文本视频训练中,在多个指标上取得了更好的效果。然而,对于仅视频生成模型的训练,添加图像数据将显著增加训练成本,尤其是在大规模预训练场景中。
在本文中,作者提出利用预训练图像生成模型来代替图像数据。预训练的文本到图像模型,例如CogView2,已经很好地掌握了文本图像关系。用于训练这些模型的数据集的覆盖率也比视频的覆盖率大。
本文提出的技术是双通道注意力,只在每个Transformer层的预训练CogView2中添加一个新的时空注意通道。CogView2中的所有参数都在训练中冻结,只有新添加的注意力层中的参数(上图中的attention-plus)是可训练的。
作者发现,直接微调CogView2以生成文本到视频不能很好地继承知识,因为时间注意力遵循不同的注意模式,并在大梯度训练的初始阶段迅速破坏预训练的权重。
具体而言,带Sandwich-LN 的双通道注意力块可计算为:

混合因子α是一个向量,其中d是输入特征的隐藏大小。为了将α的范围限制在(0,1)之内,作者将其重新参数化为,其中是一个可学习的参数。attention plus块的参数形状与正常的多头注意力块attention base相同,但计算过程不同。
在本文的训练中,作者尝试了两种注意力方式,3D局部注意力和3D Swin注意力块。在3D局部注意力中,(t,x,y)(其中(t,x,y)对应于沿时间、高度和宽度的协调)处token的感受野(RF)是一个范围为的3D区块:
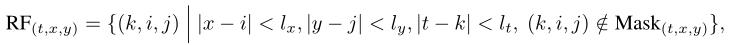
其中,表示token(t,x,y)的注意力mask。在序列生成模型(第1阶段)中,mask确保了自回归顺序;在插值模型(第2阶段)中,mask按照aCogLM的设计,以使所有帧都可以看到已知帧。
值得注意的是,由于FFN是一个包含大量视觉知识的重参数模块,因此两个通道被融合并在每一层中共享相同的FFN。由于图像和视频之间的相似性,将其知识引入时间通道将有助于视频建模。最后,共享FFN可以减少参数,从而加快训练并减少显存开销。
3.3 Shifted Window Attention in Auto-regressive Generatio
为了进一步缓解训练和推理过程中时间通道中的大量时间和内存开销,作者参考了Swin注意力。原来的Swin注意力只适用于非自回归场景,作者通过在移动窗口中应用自回归注意力mask将其扩展到自回归和时间场景。
一个有趣的发现是,Swin注意力为在不同帧的远距离区域进行并行生成提供了机会,这进一步加速了自回归生成。特定token的生成依赖于1)自回归mask。token只能处理前一帧或当前帧中自身之前的token。2)Shifted window。只有在宽度和高度维度的窗口大小距离内的token才能直接注意力。

如上图所示,帧的生成可以并行工作。假设X,Y是每个帧的高度和宽度,是移动窗口的高度和宽度。对于位于和的两个token,
,后者不能直接或间接attend到前者,如果:

这意味着第t帧中的第i个token可以和第t+1帧的第个token并行生成。这样,最多可以并行生成个token,与一次只能生成一个token的标准注意力自回归相比,大大增强了并行性,加快了推理速度。
04
实验

上表展示了UCF-101和Kinetics-600数据集上的生成结果。
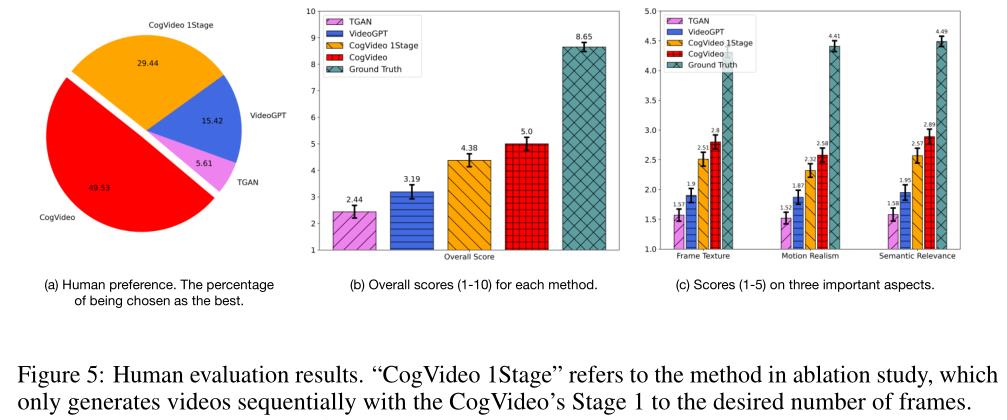
上图中的结果显示,CogVideo在多个重要方面(包括帧纹理、运动真实感和语义相关性)都显著优于baseline,并且在总体质量上取得了最高分。可以看出,49.53%的评估者选择CogVideo作为最佳方法,只有15.42%和5.6%的人分别支持VideoGPT和TGANv2。
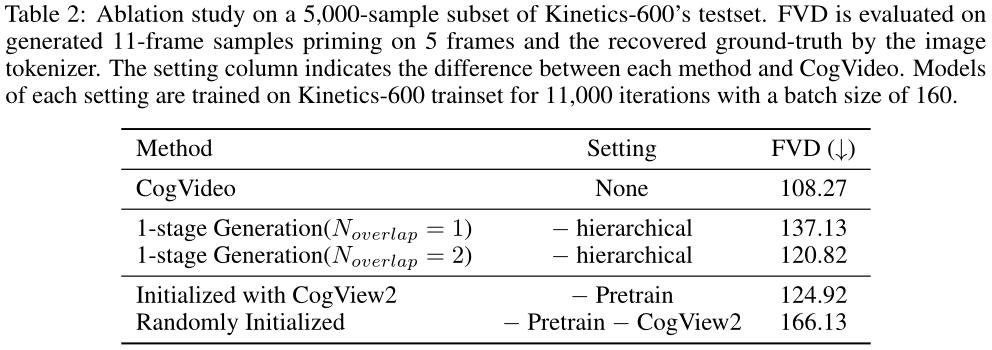
定量结果如上表所示。可以看到,分层方法明显优于具有不同的一阶段生成,并且使用CogView2权重初始化的模型的FVD低于随机初始化的模型。

上图绘制了(1)微调CogVideo的训练损失曲线;(2) 随机初始化训练模型;(3) 使用CogView2初始化训练模型并部分固定。可以看出 CogView2赋予了模型很好的初始化参数。

定性比较如上图所示。虽然从随机初始化训练的模型往往会产生不合理的变形,但包含CogView2的模型能够生成真实的对象,并且层次生成在内容一致性和运动真实性方面表现更好。
05
总结
CogVideo是通用领域中最大、也是第一个用于文本到视频生成的开源预训练Transformer。CogVideo也是第一次尝试在不损害其图像生成能力的情况下,将预训练的文本到图像生成模型有效地利用到文本到视频生成模型。通过提出的多帧率分层训练框架,CogVideo能够更好地理解文本-视频关系,并能够控制生成过程中的变化强度。作者将Swin注意力扩展到CogLM,它可以实现训练和推理的加速。
参考资料
[1]https://arxiv.org/abs/2205.15868
[2]https://github.com/THUDM/CogVideo

END
欢迎加入「计算机视觉」交流群👇备注:CV

以上是关于开源 BiT:探索计算机视觉的大规模预训练的主要内容,如果未能解决你的问题,请参考以下文章