宣布 ScaNN:高效的向量相似性搜索
Posted 雨夜的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了宣布 ScaNN:高效的向量相似性搜索相关的知识,希望对你有一定的参考价值。
假设有人想要使用需要精确匹配标题、作者或其他易于机器索引的条件的查询来搜索大型文学作品数据集。这样的任务非常适合使用 SQL 等语言的关系数据库。但是,如果想要支持更抽象的查询,例如“内战诗”,则不再可能依赖朴素的相似度指标,例如两个短语之间的共同词数。例如,查询“科幻”与“未来”的相关性比与“地球科学”的相关性更高,尽管前者与查询相同的词为 0,而后者只有一个。
机器学习 (ML) 极大地提高了计算机理解语言语义并回答这些抽象查询的能力。现代 ML 模型可以将文本和图像等输入转换为嵌入、高维向量训练,以便更多相似的输入聚集在一起。因此,对于给定的查询,我们可以计算其嵌入,并找到嵌入最接近查询的文学作品。通过这种方式,ML 将一项抽象且以前难以指定的任务转变为一项严格的数学任务。然而,一个计算挑战仍然存在:对于给定的查询嵌入,如何快速找到最近的数据集嵌入?对于穷举搜索而言,嵌入集通常太大,并且其高维度使得修剪变得困难。
在我们的ICML 2020论文“使用各向异性向量量化加速大规模推理”,我们通过关注如何压缩数据集向量以实现快速近似距离计算来解决这个问题,并提出了一种新的压缩技术,与之前的工作相比,该技术显着提高了准确性. 这种技术在我们最近开源的向量相似性搜索库(ScaNN) 中得到了利用,使我们能够在ann-benchmarks.com 上测得的性能比其他向量相似性搜索库高两倍。
矢量相似性搜索的重要性基于嵌入的搜索是一种有效地回答依赖语义理解而不是简单的可索引属性的查询的技术。在这种技术中,机器学习模型被训练以将查询和数据库项目映射到公共向量嵌入空间,从而嵌入之间的距离带有语义意义,即相似的项目更接近。
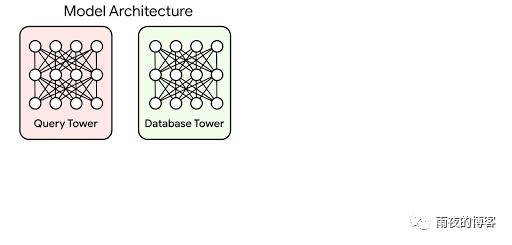
要使用这种方法回答查询,系统必须首先将查询映射到嵌入空间。然后它必须在所有数据库嵌入中找到最接近查询的嵌入;这是最近邻搜索问题。定义查询-数据库嵌入相似度的最常见方法之一是通过它们的内积;这种最近邻搜索称为最大内积搜索(MIPS)。
由于数据库规模很容易达到数百万甚至数十亿,MIPS往往是推理速度的计算瓶颈,穷举搜索是不切实际的。这需要使用近似的 MIPS 算法,该算法将一些准确性交换为比蛮力搜索显着的加速。
一种新的 MIPS 量化方法 MIPS 的几种最先进的解决方案基于压缩数据库项,以便可以在很短的时间内计算出它们的内积的近似值。这种压缩通常是通过学习量化完成的,其中向量的码本是从数据库中训练出来的,用于近似表示数据库元素。
以前的矢量量化方案量化了数据库元素,目的是最小化每个矢量x与其量化形式x̃之间的平均距离. 虽然这是一个有用的指标,但对此进行优化并不等同于优化最近邻搜索精度。我们论文背后的关键思想是,具有更高平均距离的编码实际上可能会导致更高的 MIPS 精度。
我们的结果的直觉如下所示。假设我们有两个数据库嵌入x 1和x 2,并且必须将每个嵌入到两个中心之一:c 1或c 2。我们的目标是将每个x i量化为x̃ i使得内积 < q , x̃ i> 尽可能类似于原始内积 < q , x i > 。这可以被可视化为使得突出部的大小X我到q尽可能相似的投影X我到q。在传统的量化方法(左)中,我们会为每个x i选择最近的中心,这会导致两个点的相对排名不正确:< q , x̃ 1 >大于< q , x̃ 2 >,甚至虽然 < q , x1 >小于< q , x 2 >!如果我们改为将x 1分配给c 1并将x 2分配给c 2,我们会得到正确的排名。这如下图所示。
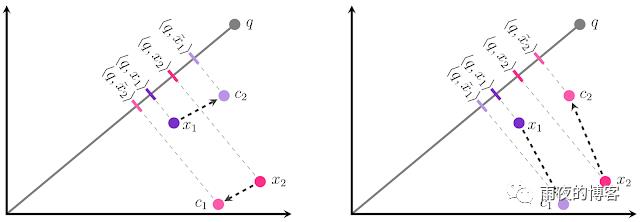
事实证明,方向事项以及大小-即使Ç 1是从更远的X 1比Ç 2,c ^ 1从偏移X 1的方向上几乎完全正交于X 1,而c ^ 2的偏移量是平行(对于x 2,同样的情况适用但翻转)。平行方向的误差在 MIPS 问题中危害更大,因为它不成比例地影响高内积,根据定义,这是 MIPS 试图准确估计的内积。
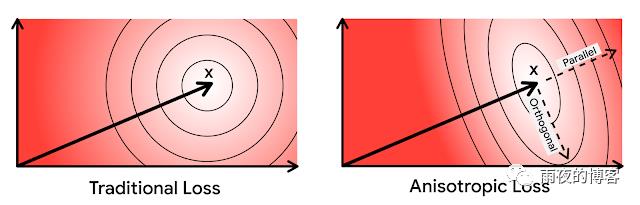
基于这种直觉,我们更严厉地惩罚与原始向量平行的量化误差。由于其损失函数的方向依赖性,我们将我们的新型量化技术称为各向异性矢量量化。这种技术能够用较低内积的增加的量化误差来换取高内积的卓越精度,这是关键创新和其性能提升的来源。
各向异性矢量量化 各向异性矢量量化允许 ScaNN 更好地估计可能出现在 top- k MIPS 结果中的内积,从而实现更高的精度。在来自ann-benchmarks.com的glove-100-angular 基准测试中,ScaNN 的表现优于其他 11 个经过精心调整的向量相似性搜索库,在给定精度下每秒处理的查询数量大约是次快库的两倍。*
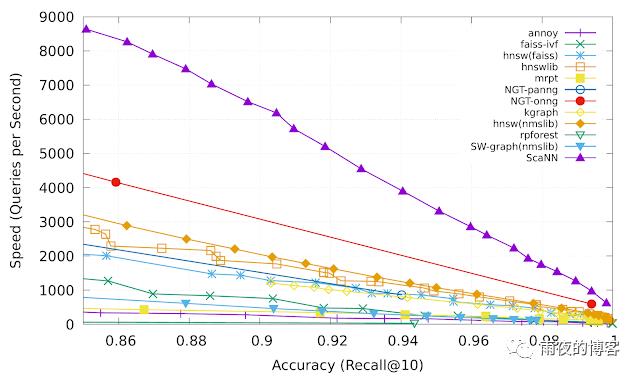
Recall@k 是最近邻搜索准确度的常用指标,它衡量算法返回的 k 个邻居中存在的真实最近 k 个邻居的比例。ScaNN(上紫色线)在速度-精度权衡的各个点上始终如一地实现了卓越的性能。ScaNN 是开源软件,您可以在GitHub 上自行试用。该库可以通过 Pip 直接安装,并具有用于 TensorFlow 和 Numpy 输入的接口。有关安装和配置 ScaNN 的进一步说明,请参阅 GitHub 存储库。
结论通过修改矢量量化目标以符合 MIPS 的目标,我们在最近邻搜索基准上实现了最先进的性能,这是基于嵌入的搜索性能的关键指标。尽管各向异性矢量量化是一项重要技术,但我们认为这只是通过优化算法以提高搜索精度的最终目标而不是诸如压缩失真等中间目标来实现性能提升的一个例子。
揭开 ScaNN 的神秘面纱:高效的向量相似性搜索

文 / 软件工程师 Philip Sun,Google Research
人们要从大量的文学作品中进行搜索,一般需要使用与标题、作者或其他易于机器索引的标准完全匹配的查询条件。那么使用 SQL 等语言的关系型数据库可以轻松完成此类任务。
但是,如果想要查询如 ‘内战期间的诗歌’ 这类比较抽象的内容,就无法再依赖如对比短语之间共同单词数量等简单的 相似性指标。如,“科幻小说 (Science Fiction)”与“未来 (Future)”的关系比与“地球科学 (Earth Science)”的关系更紧密,尽管,后者有一个相同单词 Science,而前者没有。
机器学习 (ML) 极大地提高了计算机理解语言语义以及响应这些抽象查询的能力。现代 ML 模型可以将文本和图像等输入转换为嵌入向量,对高维向量进行训练,使更相似的输入更紧密地聚集在一起。因此,对于给定的查询,我们可以计算其嵌入向量,并找到嵌入向量与查询最接近的文学作品。通过这种方式,ML 已经将以前难以指定的抽象任务转变为严格的数学任务。
然而,计算难题依然存在:对于给定的查询嵌入向量,如何快速找到数据集中最接近的嵌入向量呢?嵌入向量集合通常太大,无法进行穷尽式搜索,并且通常嵌入向量的维数很高。这使得很难对向量本身进行修剪。
在我们的 ICML 2020 论文“Accelerating Large-Scale Inference with Anisotropic Vector Quantization”中,我们通过关注如何压缩数据集向量来实现快速近似距离计算解决这一问题,并提出了一种新的压缩技术,与以前的工作相比,这项技术可以大大提高准确率。我们在近期开源的向量相似性搜索库 (ScaNN) 中应用了这项技术,与其他向量相似性搜索库相比,我们的性能高出两倍(在 ann-benchmarks.com 上测得)。
向量相似性搜索的重要性
基于嵌入向量的搜索技术能够有效响应依赖于语义理解的查询,这比简单的可索引属性的查询更为高效。在这种技术中,机器学习模型被训练成将查询和数据库项映射到公共向量嵌入空间,使得嵌入向量之间的距离带有语义含义,即相似项更接近。
要用这种方法响应查询,系统必须先将查询映射到嵌入空间。然后是最近邻搜索 (Nearest Neighbor Search) 问题:它需要在所有数据库嵌入向量中找到最接近查询的嵌入向量。定义查询数据库嵌入向量相似性的最常见方法之一是通过它们的内积;这种最近邻搜索被称为最大内积搜索 (Maximum Inner-Product Search,MIPS)。
数据库的大小很容易达到数百万甚至数十亿量级,这种情况下 MIPS 通常是推理速度的计算瓶颈,进行穷尽式搜索不切实际。而使用近似的 MIPS 算法虽然会牺牲一些精度,但能大幅提高蛮力搜索速度。
MIPS 的新量化方法
MIPS 的几种最新解决方案均基于压缩数据库项,可以超越蛮力搜索,迅速计算出它们的内积近似值。这种压缩通常通过学习量化 (Learned Quantization) 来完成,其中向量的 码本 (Codebook) 基于数据库训练得出,并用于近似表示数据库元素。
先前的向量量化方案对数据库元素进行了量化,目的是最小化每个向量 x 及其量化形式 x̃ 之间的平均距离。尽管这是一个有用的指标,但为此进行优化并不等同于优化最近邻搜索精度。论文背后的关键理论是,编码的平均距离 越大 ,实际上 MIPS 精度也可能越高。
我们对结果的分析如下所示。假设我们有两个数据库嵌入向量 x1 和 x2,并且必须将每个量化到两个中心之一:c1 或 c2。我们的目标是将每个 xi 量化为 x̃i ,以使内积 <q, x̃i> 尽可能接近原始内积 <q, xi>。可将此过程可视化为使 x̃i 在 q 上的投影幅度尽可能类似于 x̃i 在 q上的投影幅度。在传统的量化方法(左)中,我们将为每个 xi 选择最近的中心,这将导致两个点的相对排名不正确:<q, x̃1> 大于 <q, x̃2>,但是实际上 <q, x1> 小于 <q, x2>!如果我们改为将 x1 赋给 c1,将 x2 赋给 c2,则会得到正确的排名。如下图所示。
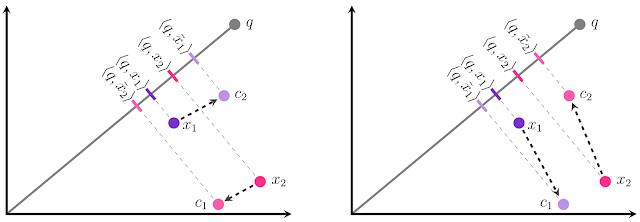
目标是将每个 xi 量化为 x̃i = c1 或 x̃i = c2:传统的量化(左)导致该查询的 x1 和 x2 的排序不正确。尽管我们的方法(右)选择的中心距数据点较远,但这实际上降低了内积误差、提高了精度
事实证明,方向和幅度同样重要——即使 c1 与 x1 的距离超过 c2 与它的距离, c1 在几乎与 x1 完全正交的方向上偏离 x1,而 c2 的偏离是平行的(对于 x2,情况相同,但方向相反)。平行方向上的误差在 MIPS 问题中危害更大,因为它严重影响高内积,根据定义,高内积是 MIPS 试图精确估计的内积。
基于这种认知,我们会更加严厉地惩罚与原始向量平行的量化误差。由于其损失函数的方向依赖性,我们将这种新型量化技术称为 各向异性向量量化 (Anisotropic Vector Quantization) 。它能够用较低内积增加的量化误差来换取较高内积的超高精度,这是创新的关键所在,也是其性能提升的源泉。
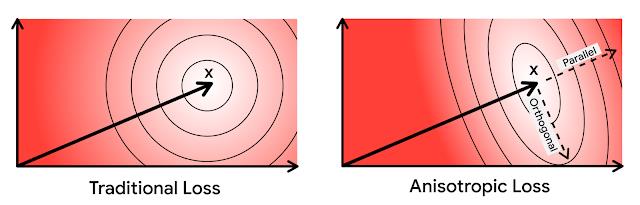
在上图中,椭圆表示等损失的轮廓:在各向异性向量量化中,平行于原始数据点 x 的误差会受到更大的惩罚
ScaNN 中的各向异性向量量化
各向异性向量量化使 ScaNN 可以更好地估计前 k 个 MIPS 结果中的内积,从而实现更高的精度。在来自 ann-benchmarks.com 的 glove-100-angular 基准测试中,ScaNN 的性能优于其他 11 个经过精心调整的向量相似性搜索库,在给定的精度下,每秒处理的查询数量大约是第二快的库的两倍。*
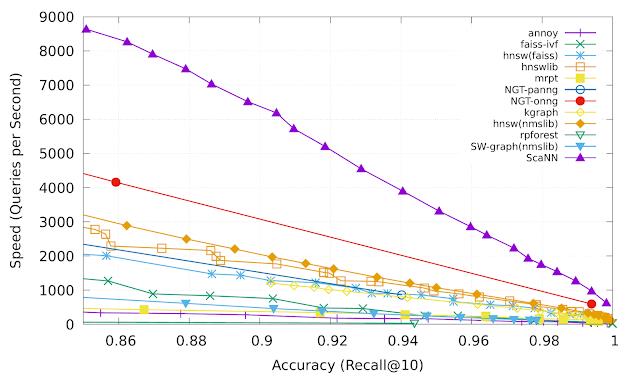
Recall@k 是最近邻搜索精度的常用指标,用于衡量算法返回的 k 个近邻中存在的真正的最近 k 个近邻的比例:ScaNN(上面的紫色线)在速度-精度权衡的各个方面始终展现出优异的性能
我们已经将 ScaNN 在 GitHub 上开源。ScaNN 可以通过 Pip 直接安装,并具有用于 TensorFlow 和 Numpy 输入的接口。有关安装和配置 ScaNN 的更多说明,请参见 GitHub 代码库。
结论
通过修改向量量化目标以与 MIPS 的目标保持一致,我们在最近邻搜索基准上获得了 SOTA 性能,这是基于嵌入向量的搜索性能的关键指标。
各向异性向量量化是一项重要技术,我们今天主要讨论的是通过优化算法实现性能提升的一个例子,其最终目标是实现提高搜索精度,而不是压缩失真等中间目标。
致谢
这篇文章是整个 ScaNN 团队共同努力的成果:David Simcha、Erik Lindgren、Felix Chern、Nathan Cordeiro、Ruiqi Guo、Sanjiv Kumar 以及 Zonglin Li。我们还要感谢 Dan Holtmann-Rice、Dave Dopson 和 Felix Yu。
* ScaNN 在 ann-benchmarks.com 的其他数据集上也有类似的出色表现,但该网站目前显示的是过时、较低的数据。
有关其他数据集上更具代表性的性能数据,请参阅此 PR (https://github.com/erikbern/ann-benchmarks/pull/172)。
登陆官网了解更多 TensorFlow 搭建推荐系统内容,可登录 B 站 Google 中国 TensorFlow 频道观看《使用 TensorFlow 搭建推荐系统系列(全八讲)》视频,也可关注 TensorFlow 官方公众号获取更多资讯。

以上是关于宣布 ScaNN:高效的向量相似性搜索的主要内容,如果未能解决你的问题,请参考以下文章