使用 Mesh-TensorFlow 进行超高分辨率图像分析
Posted 雨夜的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Mesh-TensorFlow 进行超高分辨率图像分析相关的知识,希望对你有一定的参考价值。
深度神经网络模型构成了大多数最先进的图像分析和自然语言处理算法的支柱。随着数据和模型并行等大规模深度学习技术的最新发展,大型卷积神经网络(CNN) 模型可以在数分钟内对数百万张图像的数据集进行训练。然而,在超高分辨率图像上应用 CNN 模型,例如 3D计算机断层扫描(CT) 图像,最多可以有 10 8像素,仍然具有挑战性。使用现有技术,处理器仍需要承载至少 32GB 的部分中间数据,而单个 GPU 或 TPU 通常只有 12-32GB 内存。一种典型的解决方案是将图像块彼此分开处理,这会导致复杂的实现和由于信息丢失而导致的次优性能。
在与Mayo Clinic合作的“ High Resolution Medical Image Analysis with Spatial Partitioning ”中,我们通过使用Mesh-TensorFlow推动了海量数据和模型并行的边界框架,并演示如何将这种技术用于超高分辨率图像分析,而不会影响实际可行性的输入分辨率。我们实现了一个光环交换算法来处理跨空间分区的卷积操作,以保持相邻分区之间的关系。因此,我们能够在具有 256 路模型并行性的超高分辨率图像(每个维度 512 像素的 3D 图像)上训练 3D U-Net。我们还为 GPU 和 TPU开源了基于 Mesh-TensorFlow 的框架,供更广泛的研究社区使用。
使用 Mesh-TensorFlow 实现数据和模型并行我们的实现基于 Mesh-TensorFlow 框架,以实现简单高效的数据和模型并行性,使用户能够根据用户定义的图像布局在设备网格上拆分张量。例如,用户可以为总共 256 个处理器提供 16 行 x 16 列的计算设备网格,每个处理器有两个内核。然后他们定义布局以将图像的空间维度x映射到处理器行,将空间维度y映射到到处理器列,并将批处理维度(即要同时处理的图像段的数量)映射到内核。训练批次的划分和分配由 Mesh-TensorFlow 在张量级别实现,用户无需担心实现细节。下图通过一个简化示例展示了该概念:

的卷积操作通常应用一个超出帧边缘的过滤器。虽然在处理单个图像时有办法解决这个问题,但标准方法没有考虑到帧边缘之外的分割图像信息可能仍然相关。为了产生准确的结果,对空间分区和跨处理器重新分布的图像的卷积运算必须考虑每个图像段的邻居。
一种潜在的解决方案可能是在每个空间分区中包括重叠区域。但是,由于后续的卷积层很可能很多,而且每层都引入了重叠,所以重叠会比较大——事实上,在大多数情况下,重叠可以覆盖整个图像。此外,所有重叠区域必须从一开始就包含在第一层,这可能会遇到我们试图解决的内存限制。
我们的解决方案完全不同:我们实施了一个名为halo exchange的数据通信步骤. 在每次卷积操作之前,每个空间分区与其邻居交换(接收和发送)边距,有效地扩展其边距处的图像片段。然后在每个设备上本地应用卷积操作。这确保了整个图像的卷积结果在有或没有空间分区的情况下保持相同。

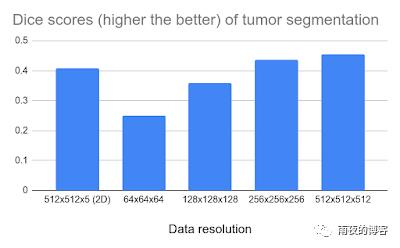
然后我们将该框架应用于肝肿瘤 3D CT 扫描的分割任务(LiTS 基准)。对于评估指标,我们使用Sørensen-Dice 系数,其范围为 0.0 到 1.0,得分为 0 表示分割的和真实的肿瘤区域之间没有重叠,1 表示完美匹配。下面显示的结果表明,更高的数据分辨率会产生更好的结果。尽管在使用全 512 3分辨率(x、y、z方向各为 512 个像素)时,收益趋于减少,但这项工作确实为超高分辨率图像分析开辟了可能性。
现有的数据和模型并行技术能够训练具有数十亿个参数的神经网络,但无法处理约 10 8像素以上的输入图像。在这项工作中,我们探索了 CNN 在这些超高分辨率图像上的适用性,并展示了有希望的结果。
处理超高分辨率图像的最佳方法是啥?
【中文标题】处理超高分辨率图像的最佳方法是啥?【英文标题】:What is the Best way to Handle Very High Resolution Images?处理超高分辨率图像的最佳方法是什么? 【发布时间】:2012-09-17 11:35:24 【问题描述】:我正在开发一个应用程序,它需要使用分辨率高于 (2000 x 2000) 的图像来实现文本清晰度。
我有一个背景图像,我需要在其上显示具有相同分辨率的叠加图像。覆盖的数量是可变的,从 2 到 30。
由于使用 UIImage 加载图像,每个像素需要 4 字节,因此如果一张图像的分辨率为 3000x3000,则最多需要 34 MB 内存,2000 x 2000 需要 15 MB。
这就是问题所在,应用在 3GS 上加载 4-5 张图片后崩溃,在 iPhone 4 上加载 11-13 张图片后崩溃。
叠加层需要准确地放置在背景图像上。它们就像我们在谷歌地图交通叠加中看到的一样。这并不排除平铺,但会使任务相对复杂。
我应该如何处理这个问题?
【问题讨论】:
这个问题可以通过平铺或者重新考虑业务逻辑来解决。 是的,我想知道是否有一种方法可以在不平铺的情况下解决这个问题。 我假设您正在使用 MapKit,因为您同时提到了 Overlays 和 Google Maps。 MKOverlayView 是一个平铺视图,因此您可能不应该排除平铺。 MK 框架将在您的叠加视图上调用drawMapRect:zoomScale:inContext:,作为最佳实践,您应该仅根据提供的边界矩形渲染到内容。
试试苹果的this,它在不影响分辨率的情况下缩小图像。
查看 WWDC2010 的 Advanced Scrollview 演示文稿 - 其中包括使用 UIScrollView 平铺大图像。对于这种尺寸的图像,除了平铺之外真的别无选择。
【参考方案1】:
当然,您不能一次将整个图像集加载到内存中。 您只需要加载图像数据的可见部分,并应尽快卸载不可见部分。
如果你想在 QuartzCore 级别解决这个问题,CATiledLayer 类就是为了这个目的。
苹果参考:https://developer.apple.com/library/mac/#documentation/GraphicsImaging/Reference/CATiledLayer_class/Introduction/Introduction.html
Apple 示例代码:https://developer.apple.com/library/mac/#samplecode/CALayerEssentials/Introduction/Intro.html#//apple_ref/doc/uid/DTS40008029
其他信息:http://red-glasses.com/index.php/tutorials/catiledlayer-how-to-use-it-how-it-works-what-it-does/
要使用此层,您需要将源图像拆分为多个图块。并在层需要时提供它们。 (drawLayer:inContext: 方法。)该方法将在非主线程上调用,因此不会阻塞用户界面。不要忘记释放不可见磁贴的图像以节省内存。
此外,您可以使用后台线程动态加载资源的低级 OpenGL 代码来实现这一点。在这种情况下,您可以使用 PVRTC 有损内存压缩,这可以大大节省视频内存的使用,但这确实是一项痛苦且耗时的工作。我推荐使用CATiledLayer。这对于大多数情况来说已经足够了。
【讨论】:
以上是关于使用 Mesh-TensorFlow 进行超高分辨率图像分析的主要内容,如果未能解决你的问题,请参考以下文章