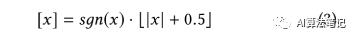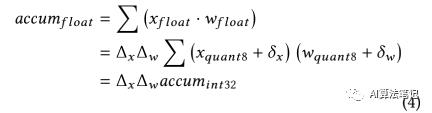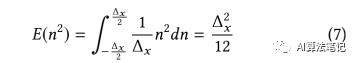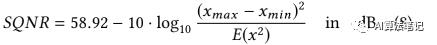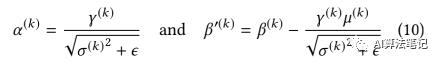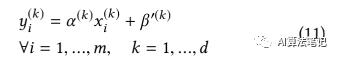15. MobileNetV1 量化效果差?试试高通提出的这个方法吧!
Posted AI算法笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了15. MobileNetV1 量化效果差?试试高通提出的这个方法吧!相关的知识,希望对你有一定的参考价值。
等,它们会生成 32 位的累计结果,然后通过激活反量化(activation re-quantization)步骤转成一个 8bit 的输出,然后这个输出再传给下一个操作。
表示浮点输入 x,而 TensorFlow 量化后的 8bit 数值表示为 表示的就是量化步长,b 表示位宽,比如本文提到的 8bit,就是 b=8,而 表示偏置值,而 分布表示浮点数值范围的最小值和最大值,另外 表示最近的凑整操作,在 TensorFlow 中的实现是如下所示: 基于上述的定义,对于一个卷积操作的累计结果的计算如下所示:
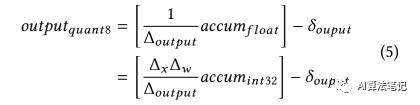
最后,给定输出的已知的最大值和最小值,将上述 (1)-(4) 公式结合起来,反量化得到的输出可以通过下述公式计算得到:
,所以一个合理的假设是量化误差是一个服从 0 均值的均匀分布,并且其概率密度函数(PDF) 是结合为 1,因此,对于一个 8bit 的线性量化器,其噪音能量可以如下计算得到: 结合(2),(7)和(6),可以得到如下公式:
SQNR 和信号的分布关系很大,根据(8)式,SQNR 很明显是由x 的能量以及量化范围决定的,因此增加输入信号的能力或者减少量化的范围都可以提升输出的 SQNR。
表示经过归一化的在通道 k 的第 i 个输入值 表示整个 batch 的均值和方差,表示大小和转移值。而是一个设定好的非常小的常数,在 TensorFlow 的实现中,其数值是 0.0010000000475。在定点流程中,BN 的转换可以被折叠起来,首先令:
则(9)式可以重写为:
在 TensorFlow 的实现中,每个通道 k 中,可以结合权重并折叠到卷积操作中从而减小计算消耗。
虽然深度卷积是单独应用到每个通道中,但是权重量化的最小值和最大值的选择范围是所有的通道,这会导致一个问题就是某个通道的一个离群点很可能导致整个模型的巨大的量化损失,因为离群点会加大了数据的数值范围。
此外,没有跨通道的修正操作,深度卷积很可能在一个通道里产生全 0 的数值,这导致该通道的方差是 0,并且这种情况在 MobileNetV1 种是很常见的。而根据公式(10),方差是 0 的时候由于设置的非常小的常数,会非常大,如下图所示,测量了32 个通道中的 数值,由于零方差导致的 6 个离群点是增大了量化范围,这导致的结果就是量化位数会由于要保持这些来自全 0 通道的巨大的数值而浪费了,相反那些带有信息的通道的较小的反而没有被保留下来,使得整个模型的表征能力变差很多。
从实验中可以知道,在没有重新训练的情况下,通过将这些全 0 通道的方差改为其余通道的方差的均值,可以很好的解决这个问题,这可以让量化后的 MobileNetV1 模型在 ImageNet2012 验证集上的精度从之前的 1.8%提升到 45.73%。
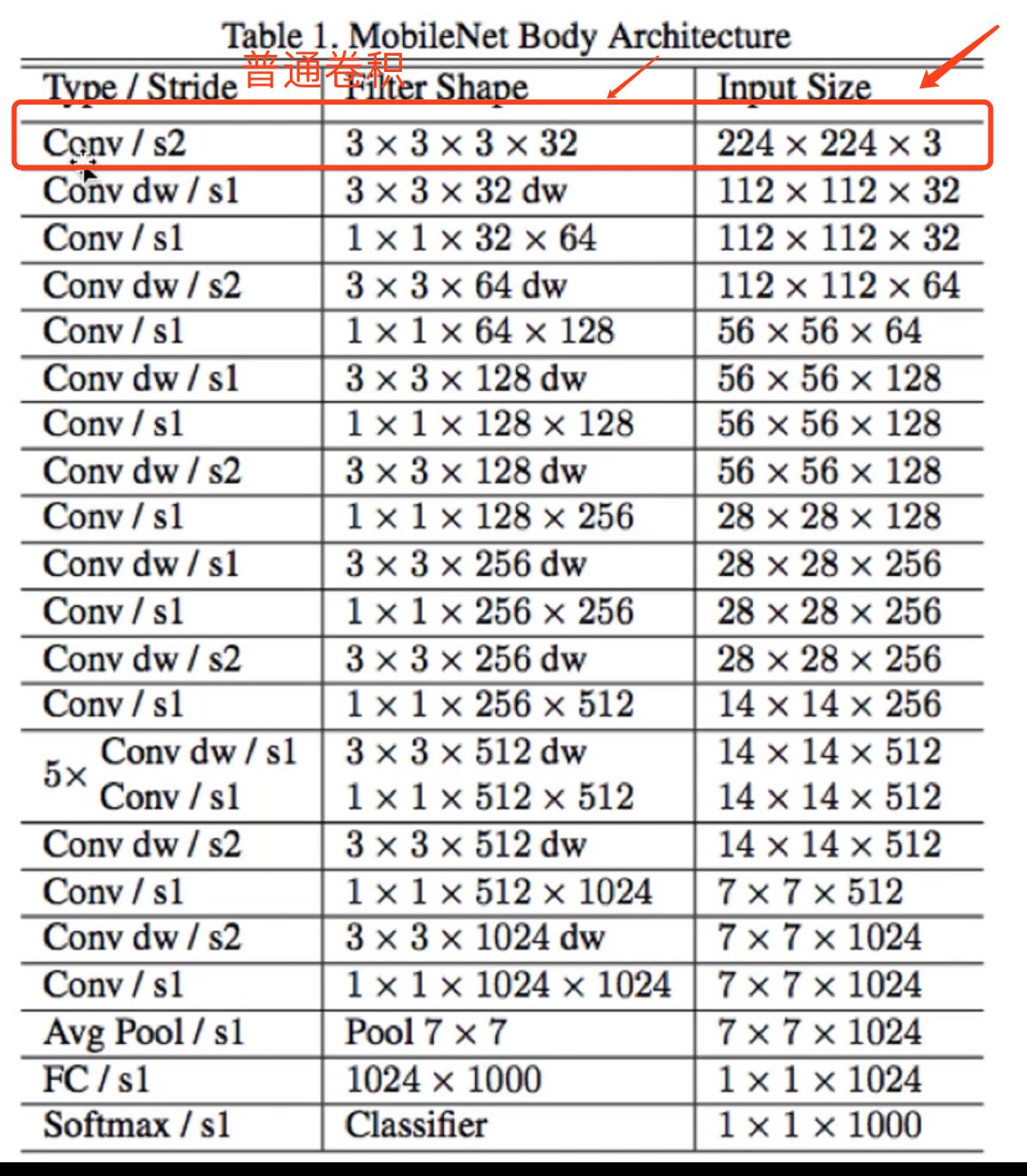
标准的卷积层是在一个步骤中完成了对输入的滤波和合并得到新的输出数值,而在 MobileNetV1 中深度可分离卷积将这个操作分成两层,深度卷积实现滤波的操作,而逐点卷积实现合并的操作,从而大大减小了计算代价和模型大小,并且可以保持模型精度。
基于上述的原则,本文是考虑移除了深度卷积后的 BN 和 ReLU6,让深度卷积来学习合适的权重从而替代了 BN 的作用,这样的操作即可以保持特征的表征能力,又使得模型能很好实现量化操作。
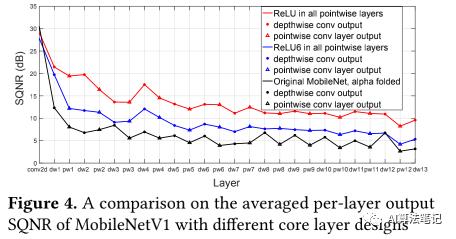
如下图所示,这里使用 SQNR 来观察每层的量化损失,其中黑线表示原始版本的将 折叠到卷积权重里的 MobileNetV1,蓝线则表示在所有深度卷积层中移除了 BN 和 ReLU6 ,红线表示的是在移除深度卷积层的 BN 和 ReLU6 后,还在逐点卷积层中使用 ReLU 而不是 ReLU6,另外保留逐点卷积层中的 BN 和 ReLU6,然后使用的图片是从 ImageNet2012的验证集中每个类别随机选择 1 张图片,总共 1000 张图片,从实验结果可以知道保留深度卷积层里的 BN 和 ReLU6 会大大降低每层输出的 SQNR。
非常大,即产生了较大的离群点,这会影响量化范围,使得信息量较大但数值较小的数值都量化到同个定点,而这些离群点并不包含或者包含较少信息,反而被保留下来,这会大大降低量化模型的特征表征能力,从而降低了量化模型的精度。
基于这个发现,作者是直接移除了深度卷积的 BN 和 ReLU6,并且实验结果也验证了这个操作的可行性,而之后做的两个改变,使用 ReLU 代替其它层的 ReLU6 的提升效果也很明显,而 L2 正则化提升则比较一般,当然这里作者似乎没有做个实验来比较 L2 正则化对量化模型提升更大,还是都使用 ReLU 提升更大;
此外,目前仅在 MobileNetV1 上做了实验,作者也提到需要在其他也使用了可分离卷积的网络中验证这个方法,比如 MobileNetV2,ShuffleNet,以及本文做的是分类,还需要验证在其他的任务,比如检测、分割上是否也有效果。
推荐阅读的学习笔记
14. Focal Loss 论文笔记
11.神经网络不收敛怎么办?看看是不是这些原因
09. MCN 搭配评价模型论文笔记
公众号后台回复这些关键词,可以获得相应的资料:
回复”入门书籍“,获取机器学习入门资源,包括书籍、视频以及 python 入门书籍;
回复”数据结构“,获取数据结构算法书籍和 leetcode 题解;
回复”多标签“,获取使用 keras 实现的多标签图像分类代码和数据集
回复“pytorch 迁移学习”,获取 pytorch 的迁移学习教程代码
回复“py_ml",获取初学者的机器学习入门教程代码和数据集
如果想评论可以点击阅读原文,进行评论互动,谢谢!
动手记录模型:mobilenetv1
轻量级网络:mobilenetv1
神经网络在实际应用的问题
- 可解释性差(黑盒子)
- 没法微调(百分之99%,剩余的百分之1%没法更改)
- 内存和CPU使用较高
解决内存CPU高
- 二值化网络(Binary)
- 轻量级网络
- Mobilenets
- Shufflenet
- EffNet
mobilenetv1
亮点
- Depthwise separable convolution(输入通道独立卷积)
详解
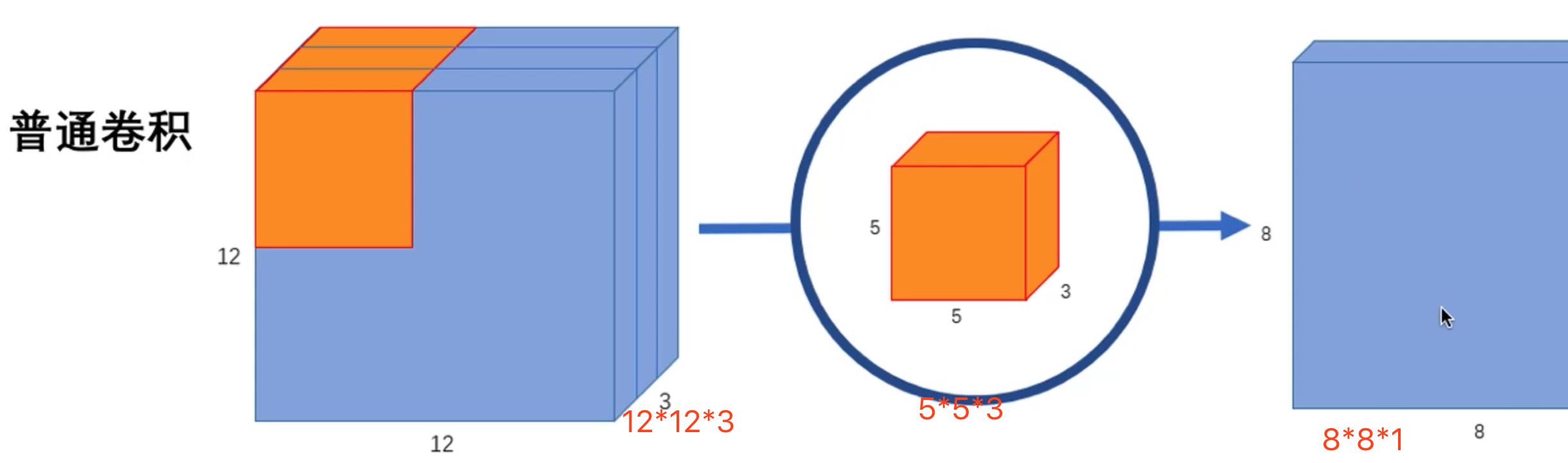
普通卷积
输出层数 10层:
需要5*5*3 * 10分离卷积
输出层10层
1*1*3 * 10计算量比较
- 输出图像12*12*3
- 输出图像8*8*256
Convolution
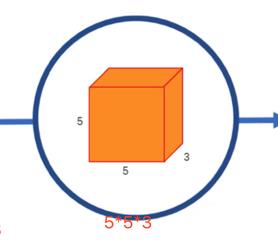
卷积核大小 5*5*3 256个
数据量:5*5*3*256 =19200
计算量:8*8*5*5*3*256 =1228800
`
- 输出端的每个点 8*8
- 输出端的层数 256
- 每个点做的卷积运算(这里只算了乘法) 5*5*3
`
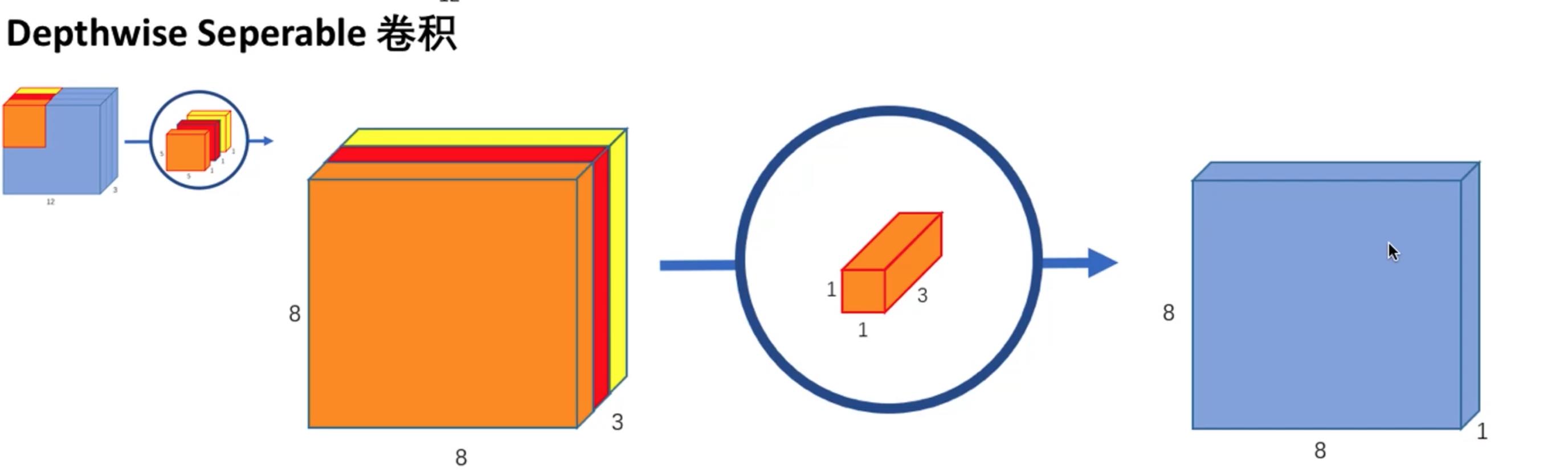
Depthwise separable convolution
第一步:卷积核大小 5*5*1. 3个
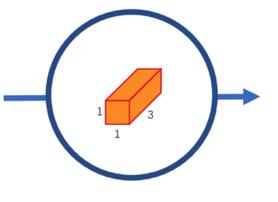
第二步:卷积核大小 1*1*3. 256个
数据量:5*5*1*3 + 1*1*3*256 = 843
计算量:5*5*1*3*8*8+8*8*1*1*3*256 = 53952
计算量对比公式
5 ∗ 5 ∗ 1 ∗ 3 ∗ 8 ∗ 8 + 8 ∗ 8 ∗ 1 ∗ 1 ∗ 3 ∗ 256 8 ∗ 8 ∗ 5 ∗ 5 ∗ 3 ∗ 256 \\frac5*5*1*3*8*8+8*8*1*1*3*2568*8*5*5*3*256 8∗8∗5∗5∗3∗2565∗5∗1∗3∗8∗8+8∗8∗1∗1∗3∗256
1 256 + 1 5 ∗ 5 \\frac1256+\\frac15*5 2561+5∗51
网络块
网络结构
第一层使用普通卷积
网络效果
参见论文
代码实现
pytorch
tensorflow
caffe
注意
以上是关于15. MobileNetV1 量化效果差?试试高通提出的这个方法吧!的主要内容,如果未能解决你的问题,请参考以下文章