使用 SEED RL 大规模扩展强化学习
Posted 雨夜的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 SEED RL 大规模扩展强化学习相关的知识,希望对你有一定的参考价值。
强化学习 (RL) 在过去几年取得了令人瞩目的进步,最近在解决围棋和Dota 2等游戏方面取得了成功。模型或代理通过探索环境(例如游戏)来学习,同时针对特定目标进行优化。然而,当前的 RL 技术需要越来越多的训练才能成功学习即使是简单的游戏,这使得迭代研究和产品创意在计算上既昂贵又耗时。
在“ SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference”,我们提出了一个可扩展到数千台机器的 RL 代理,它能够以每秒数百万帧的速度进行训练,并显着提高计算效率。这是通过一种新颖的架构实现的,该架构通过集中模型推理和引入快速通信层来大规模利用加速器(GPU或TPU)。我们在流行的 RL 基准测试(例如Google Research Football、Arcade Learning Environment和DeepMind Lab)上展示了 SEED RL 的性能,并表明通过使用更大的模型可以提高数据效率。代码已在Github上开源以及使用GPU在 Google Cloud 上运行的示例。
当前的分布式架构上一代分布式强化学习代理,如 IMPALA,利用专门用于数值计算的加速器,利用(非)监督学习多年来受益的速度和效率。RL 代理的架构通常分为参与者和学习者. Actor 通常在 CPU 上运行,并在环境中采取步骤和在模型上运行推理以预测下一个动作之间进行迭代。通常,actor 会更新推理模型的参数,并在收集到足够数量的观察后,将观察和动作的轨迹发送给学习器,然后学习器优化模型。在这种架构中,学习者使用来自数百台机器上的分布式推理的输入在 GPU 上训练模型。
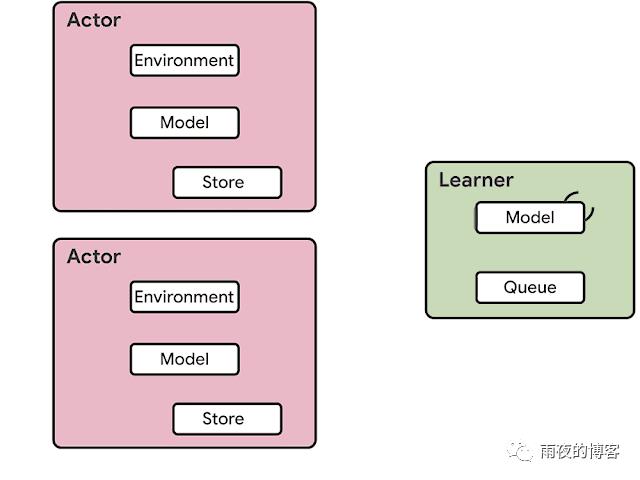
RL 代理(例如 IMPALA)的架构有许多缺点:1.与使用加速器相比,使用 CPU 进行神经网络推理的效率和速度要低得多,并且随着模型变得更大且计算成本更高而变得有问题。2.在参与者和学习者之间发送参数和中间模型状态所需的带宽可能是一个瓶颈。3.在一台机器上处理两个完全不同的任务(即环境渲染和推理)不太可能以最佳方式利用机器资源。
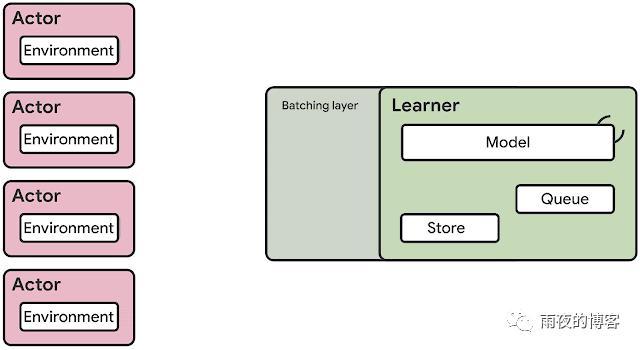
SEED RL 架构SEED RL 架构旨在解决这些缺点。通过这种方法,神经网络推理由学习器在专用硬件(GPU 或 TPU)上集中完成,通过确保模型参数和状态保持在本地,可以加速推理并避免数据传输瓶颈。虽然在每个环境步骤将观察结果发送给学习器,但由于基于gRPC的非常高效的网络库,延迟保持在较低水平具有异步流式 RPC 的框架。这使得在单台机器上每秒可以实现多达一百万次查询。学习器可以扩展到数千个内核(例如,在 Cloud TPU 上最多 2048 个),参与者的数量可以扩展到数千台机器以充分利用学习器,从而可以以每秒数百万帧的速度进行训练。SEED RL 基于TensorFlow 2 API,在我们的实验中,由TPU加速。
为了使该架构取得成功,两种最先进的算法被集成到 SEED RL 中。第一个是V-trace,一种基于策略梯度的方法,首先由 IMPALA 引入。一般来说,基于策略梯度的方法可以预测动作分布,从中可以对动作进行采样。然而,由于参与者和学习者在 SEED RL 中异步执行,参与者的政策稍微落后于学习者的政策,即,他们变得离政策。通常的基于策略梯度的方法是on-policy,这意味着他们对参与者和学习者有相同的政策,并且在非政策环境中存在收敛和数值问题。V-trace 是一种 off-policy 方法,因此在异步 SEED RL 架构中运行良好。
第二种算法是R2D2,这是一种Q 学习方法,它使用循环分布式重放根据该动作的预测未来值来选择该动作。这种方法允许 Q 学习算法大规模运行,同时仍然允许使用循环神经网络,该网络可以根据情节中所有过去帧的信息预测未来值。
实验SEED RL 以常用的 Arcade 学习环境、DeepMind Lab 环境和最近发布的 Google Research Football 环境为基准。
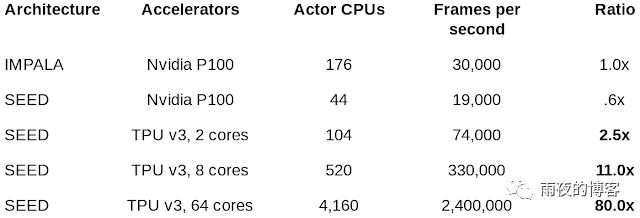
在 DeepMind Lab 上,我们使用 64 个 Cloud TPU 内核实现了每秒 240 万帧,这比之前最先进的分布式代理 IMPALA 提高了 80 倍。这导致挂钟时间和计算效率的显着加速。IMPALA 需要 3-4 倍于 SEED RL 的 CPU,才能获得相同的速度。
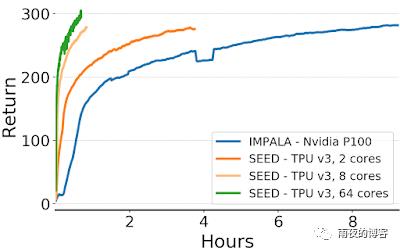
使用针对现代加速器优化的架构,自然会增加模型大小以尝试提高数据效率。我们表明,通过增加模型的大小和输入分辨率,我们能够解决以前未解决的 Google Research Football 任务“Hard”。

论文中提供了更多详细信息,包括我们在 Arcade 学习环境上的结果。我们相信 SEED RL 和所呈现的结果表明,强化学习在利用加速器方面再次赶上了深度学习领域的其他领域。
强化学习论文Ada开放式任务空间中的人类时间尺度适应
- 文章题目:Human-Timescale Adaptation in an Open-Ended Task Space
- 作者:Deepmind
- 时间:2013
摘要
- 基础模型在监督和自我监督学习问题中表现出令人印象深刻的适应性和可扩展性,但到目前为止,这些成功还没有完全转化为强化学习 (RL)。 在这项工作中,我们证明了大规模训练 RL 智能体会产生一种通用的上下文学习算法,该算法可以像人类一样快速地适应开放式新颖的具身 3D 问题。 在广阔的环境动态空间中,我们的自适应代理 (AdA) 展示了即时假设驱动的探索、对所获得知识的有效利用,并且可以通过第一人称演示成功地得到提示。 适应性来自三个要素:(1) 在广泛、平滑和多样化的任务分布中进行元强化学习,(2) 参数化为大规模基于注意力的记忆架构的策略,以及(3) 一种有效的自动化课程,可以优先考虑代理人能力前沿的任务。 我们展示了关于网络大小、内存长度和训练任务分布丰富度的特征缩放法则。 我们相信我们的结果为越来越通用和自适应的 RL 代理奠定了基础,这些代理在越来越大的开放域中表现良好。
引言
- 在几分钟内适应的能力是人类智能的一个决定性特征,也是通向通用智能道路上的一个重要里程碑。 给定任何级别的有限理性,都会有一个任务空间,在这个任务空间中,智能体不可能仅通过概括其策略零样本来取得成功,但是如果代理能够从反馈中非常快速地进行上下文学习,那么进展是可能的。 为了在现实世界中以及与人类的互动中发挥作用,我们的人工智能体应该能够在仅进行少量互动的情况下进行快速灵活的适应,并且应该随着更多数据的可用而继续适应。 为了使这种适应概念实用化,我们试图训练一个代理人,在测试时在一个看不见的环境中给定几个情节,可以完成一项需要反复试验探索的任务,然后可以改进其解决方案以实现最佳行为。
- Meta-RL 已被证明对快速的上下文适应有效(例如 Yu 等人 (2020);Zintgraf (2022))。 然而,元强化学习在奖励稀疏且任务空间广阔且多样化的环境中取得的成功有限(Yang 等人,2019 年)。 在 RL 之外,半监督学习中的基础模型引起了极大的兴趣(Bommasani 等人,2021 年),因为它们能够适应广泛任务中演示的少量镜头。 这些模型旨在提供坚实的常识和技能基础,可以通过微调或演示提示来建立和适应新情况(Brown 等人,2020 年)。 这一成功的关键是基于注意力的内存架构,如 Transformers(Vaswani 等人,2017 年),它显示了性能随参数数量的幂律缩放(Tay 等人,2022 年)。
- 在这项工作中,我们为训练 RL 基础模型铺平了道路; 也就是说,一个代理已经在大量任务分布上进行了预训练,并且在测试时可以使少量镜头适应广泛的下游任务。 ==我们介绍了自适应代理 (AdA),这是一种能够在具有稀疏奖励的巨大开放式任务空间中进行人类时间尺度适应的代理。 AdA 不需要任何提示(Reed 等人,2022 年)、微调(Lee 等人,2022 年)或访问离线数据集(Laskin 等人,2022 年;Reed 等人,2022 年)。 相反,AdA 表现出假设驱动的探索行为,使用即时获得的信息来改进其策略并实现接近最佳的性能。 AdA 有效地获取知识,在几分钟内适应具有挑战性的稀疏奖励任务,==在具有第一人称像素观察的部分可观察的 3D 环境中。 一项人类研究证实,AdA 适应的时间尺度与受过训练的人类玩家相当。 AdA 在具有代表性的保留任务中的适应行为如图 1 所示。AdA 还可以通过第一人称演示的零样本提示来提高性能,类似于语言领域的基础模型。
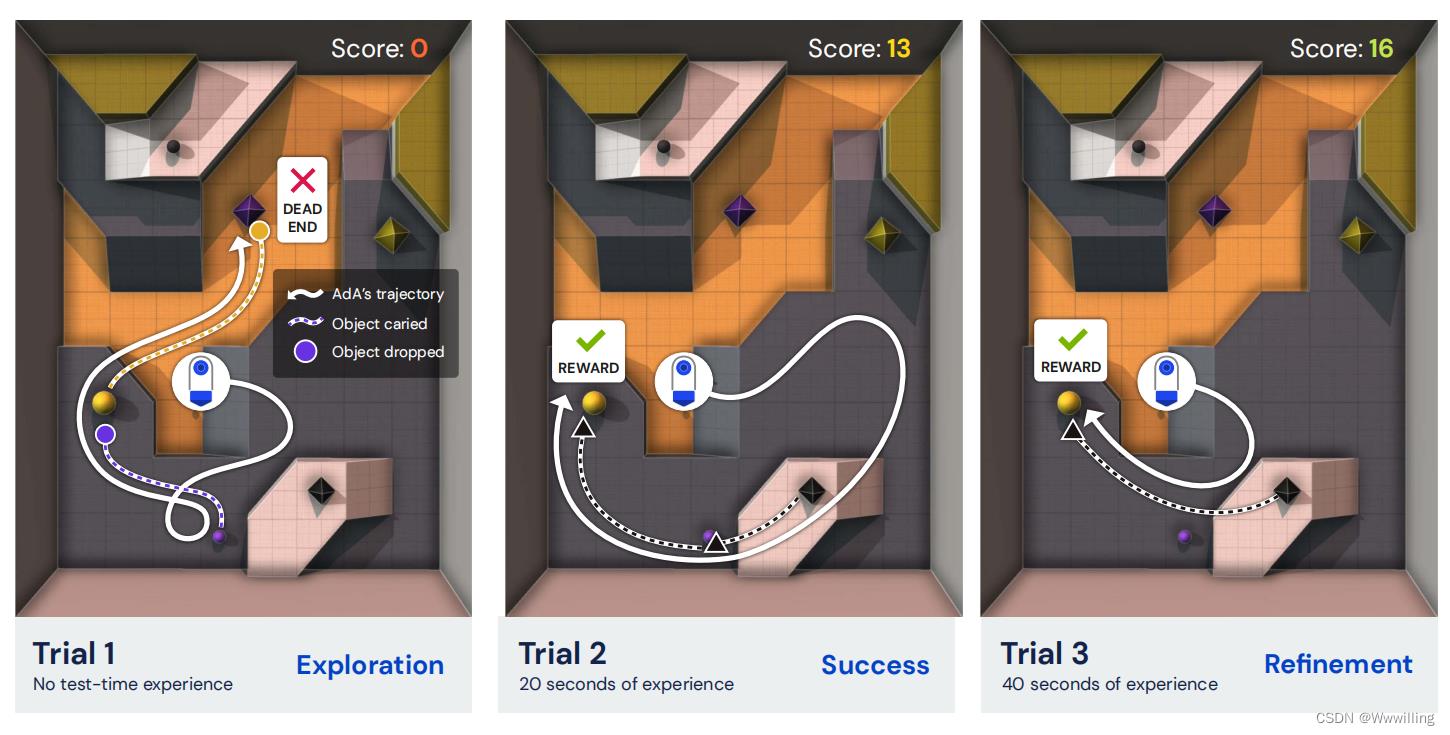
- 图 1 | 人类时间尺度适应。 我们的智能体 (AdA) 在测试时间经验的几分钟内解决复杂 3D 环境中的保留任务的示例轨迹,无需任何进一步的智能体培训。 初始试验(探索)显示了一种揭示隐藏环境动态的策略。 经过几秒钟的测试时间经验(成功)后,AdA 找到了任务的有效解决方案。 后来(改进),它改进了这个解决方案,逐渐找到更有价值的行为。 白色实线表示代理移动。 彩色虚线表示携带相应颜色物体的代理。 有关任务的完整描述,请参见图 B.1。 AdA 行为的视频可在我们的微型网站和随附的结果卷轴上找到。
- 我们使用 Transformers 作为架构选择,通过基于模型的 RL2 扩展上下文快速适应(Duan 等人,2017 年;Melo,2022 年;Wang 等人,2016 年)。 基础模型通常需要大型、多样化的数据集来实现它们的通用性(Brown 等人,2020 年;Mahajan 等人,2018 年;Schuhmann 等人,2022 年;Sun 等人,2017 年;Zhai 等人,2022 年)。 为了在智能体收集自己的数据的 RL 设置中实现这一点,我们扩展了最近的 XLand 环境(OEL Team 等人,2021 年),生成了一个包含 1040 多个可能任务的广阔开放世界。 这些任务需要一系列不同的在线适应能力,包括实验、导航、协调、分工和应对不可逆性。 鉴于可能的任务范围很广,我们使用自适应自动课程,它会优先考虑智能体能力前沿的任务(Jiang 等人,2021a;OEL Team 等人,2021)。 最后,我们利用蒸馏(Schmitt et al., 2018),它可以扩展到具有超过 500M 参数的模型,据我们所知,这是发布时使用 RL 从头开始训练的最大模型(Ota et al., 2021 年)。 图 2 显示了我们方法的高级概述。
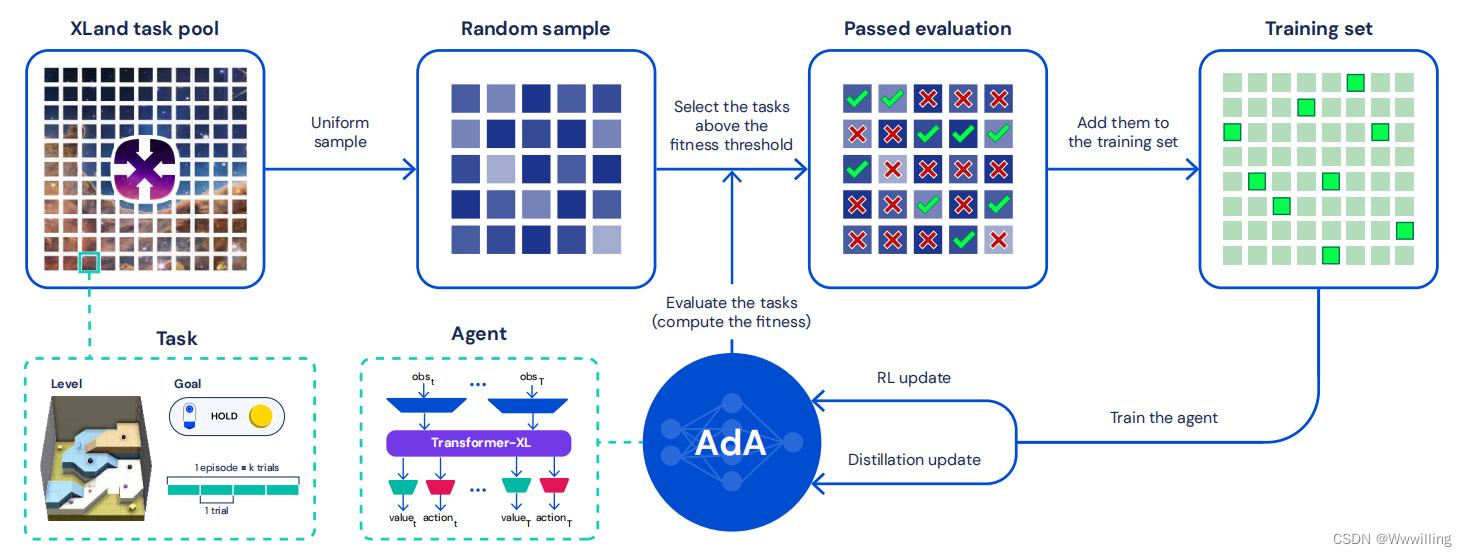
- 图 2 | 训练我们的自适应代理 (AdA)。 我们在 XLand 中使用元强化学习训练大型 Transformer 模型。 在训练过程中,任务被统一采样,随后进行过滤,以在代理能力的前沿产生一个不断变化的任务训练池。 在对这些任务进行培训后,代理能够像人类一样有效和高效地适应看不见的手写任务。
- 我们的主要贡献如下:
- • 我们介绍了 AdA,它是一种能够在各种具有挑战性的任务中进行人类时间尺度适应的代理。
- • 我们在具有自动化课程的开放式任务空间中使用元强化学习大规模训练 AdA。
- • 我们表明适应受记忆结构、课程以及训练任务分布的大小和复杂性的影响。
- • 我们在模型大小和内存中生成比例定律,并证明 AdA 通过零样本第一人称提示提高了性能。
Adaptive Agent (AdA)
- 为了在广阔而多样的任务空间中实现人类时间尺度适应,我们提出了一种通用且可扩展的基于内存的元 RL 方法,生成自适应代理 (AdA)。 我们在 XLand 2.0 中训练和测试 AdA,这是一个支持程序生成多样化 3D 世界和多人游戏的环境,具有需要适应的丰富动态。 我们的训练方法结合了三个关键组成部分:指导代理学习的课程、基于模型的 RL 算法来训练具有大规模基于注意力的记忆的代理,以及蒸馏以实现扩展。 我们的方法概述如图 2 所示。在以下部分中,我们将描述每个组件以及它如何有助于高效的少镜头自适应。
Open-ended task space: XLand 2.0
- 为了展示在开放式任务空间中的快速适应,我们扩展了程序生成的 3D 环境 XLand(OEL Team 等人,2021),我们在这里将其称为 XLand 1.0。 在 XLand 中,任务由游戏、世界和合作玩家策略列表(如果有)组成。 游戏由每个玩家的目标组成,定义为环境状态的布尔函数(谓词)。 当且仅当目标得到满足时,代理才会收到奖励。 目标以合成语言定义,代理接收编码。 世界指定静态地板拓扑、玩家可以与之交互的对象以及玩家的生成位置。 智能体通过第一人称像素观察来观察世界,以及其中的任何合作者。 游戏、世界和合作玩家系统的所有基本细节都继承自最初的 XLand; 参见 OEL 团队等。 (2021) 获取完整说明,附录 A.1 获取我们添加的新功能的详细信息。
- XLand 2.0 使用称为生产规则的系统扩展了 XLand 1.0。 每个生产规则都表达了一个额外的环境动态,导致比 XLand 1.0 中更丰富、更多样化的不同转换函数。 生产规则系统可以被认为是一种领域特定语言(DSL)来表达这种多样化的动态。 每个生产规则包括:
- 一个条件,也就是一个谓词,比如near(yellow sphere,black cube),
- 生成物列表(可能为空),它们是对象,如紫色立方体、黑色立方体。
- 当条件满足时,存在于条件中的对象将从环境中移除,并且出现在生成中的对象。 每个游戏可以有多个生产规则。 生产规则可以被玩家观察到,或者部分或完全被屏蔽,具体取决于任务配置。 更准确地说,有三种不同的机制可以向玩家隐藏生产规则信息:
- 隐藏完整的生产规则,玩家只能得到规则存在的信息,但既不知道条件也不知道生成什么。
- 隐藏对象,其中特定对象对所有生产规则都是隐藏的。 隐藏的对象被编号,如果隐藏了多个对象,代理可以区分它们。
- 隐藏条件的谓词,让代理知道需要满足的对象
一些谓词,但它不知道是哪一个。 隐藏的谓词也被编号。
- 我们不是按程序即时生成任务,而是对大量任务进行预采样。 有关我们用于预采样任务的具体机制的更多详细信息,请参阅附录 A.2。 我们在图 3 中可视化 XLand 2.0 任务空间。
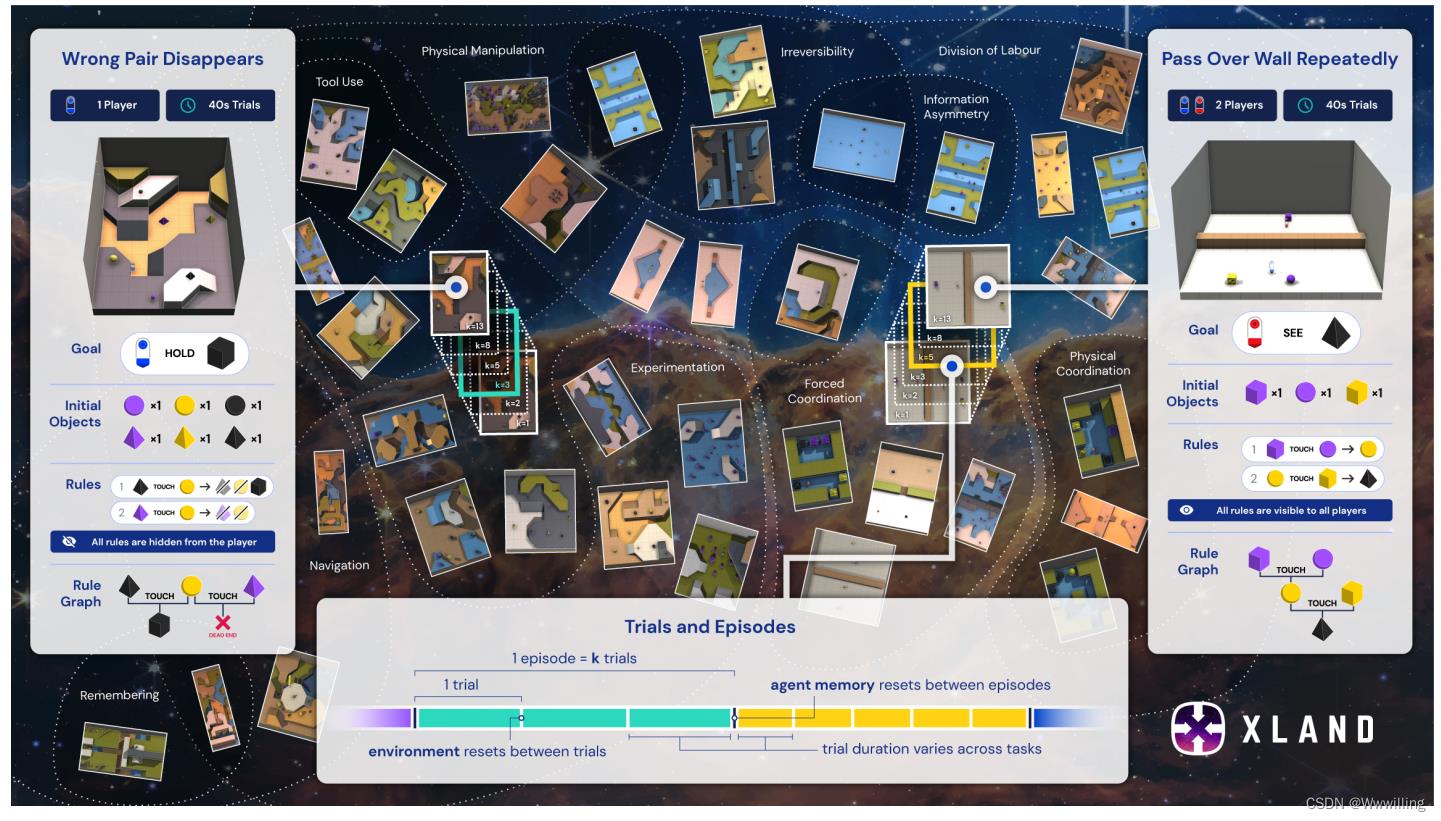
- 图 3 | XLand 2.0:适应问题的广阔、平滑和多样化的任务空间。 不同的任务有不同的适应要求,例如实验、工具使用或分工。 例如,在一项需要实验的任务中,玩家可能需要确定哪些对象可以有效地组合,避免死胡同,然后优化他们组合对象的方式,就像实验化学的玩具版本。 每个任务都可以运行一次或多次试验,在试验之间重置环境,但代理内存不会。 突出显示的是两个示例任务,Wrong Pair Disappears 和 Pass Over Wall Repeatedly,显示了目标、初始对象、生产规则(图中的“规则”)以及代理需要如何与它们交互以解决任务。 有关完整的任务描述,请参阅附录 F.1。
Meta-RL
- 我们使用黑盒元强化学习问题设置(Duan 等人,2017 年;Wang 等人,2016 年)。 我们将任务空间 M 定义为一组部分可观察的马尔可夫决策过程 (POMDP)。 对于给定的任务𝑚∈M,我们将试验定义为从初始状态𝑠0 到终端状态𝑠𝑇 的任何转换序列。请注意,我们使用与Duan 等人(2017)相反的命名约定。 在我们的惯例中,术语“试验”很好地映射到人类行为文献中的相关概念 (Barbosa et al., 2022)。 在 XLand 中,任务终止当且仅当某个时间段𝑇∈[10s,40s]已经过去,每个任务指定。 环境以每秒 30 帧的速度滴答,代理每 4 帧观察一次,因此以时间步长为单位的任务长度在 [75, 300] 范围内。
- 一个episode 由给定任务 𝑚 的一系列 𝑘 试验组成。 在试验边界,任务被重置为初始状态。 在我们的领域中,初始状态是确定性的,除了代理的旋转,它是随机均匀采样的。 试验和剧集结构如图 3 所示。
- 在黑盒元 RL 训练中,代理使用与广泛分布的任务交互的经验来更新其神经网络的参数,该参数参数化代理在给定状态观察的动作上的策略分布。== 如果代理拥有动态内部状态(记忆),则元强化学习训练会通过利用重复试验的结构,为该记忆赋予隐式在线学习算法==(Mikulik 等人,2020 年)。
- 在测试时,这种在线学习算法使代理能够调整其策略,而无需进一步更新神经网络权重。 因此,agent 的记忆不会在试验边界重置,而是在情节边界重置。 为了生成一个情节,我们对一对 (𝑚, 𝑘) 进行采样,其中 𝑘 ∈ 1, 2, . . . 6。 正如我们稍后将讨论的那样,在测试时,AdA 会针对各种 𝑘 值的未见、保留任务进行评估,包括在训练期间未看到的保留 𝑘。 有关 AdA 的元强化学习方法的完整详细信息,请参阅附录 D.1。
Auto-curriculum learning
- 鉴于我们预采样任务池的广泛性和多样性,代理人通过均匀采样有效地学习是一项挑战。 大多数随机抽样的任务可能会太难(或太容易)而无益于代理的学习进度。 相反,我们使用自动方法在代理能力的前沿选择“有趣”的任务,类似于人类认知发展中的“最近发展区”(Vygotsky,1978)。 我们建议对两种现有方法进行扩展,这两种方法都可以显着提高代理性能和样本效率(见第 3.3 节),并导致出现课程,选择随着时间的推移复杂性增加的任务。
- No-op filtering。 我们将 OEL Team 等人(2021,第 5.2 节)中提出的动态任务生成方法扩展到我们的设置中。 当从池中抽取新任务时,首先对其进行评估以评估 AdA 是否可以从中学习。 我们评估了 AdA 的政策和“No-op”控制政策(在环境中不采取任何行动)的一些情节。 当且仅当两个策略的分数满足多个条件时,该任务才用于训练。 我们从原始的无操作过滤中扩展了条件列表,并使用归一化阈值来说明不同的试验持续时间。 有关详细信息,请参阅附录 D.5。
- 优先级别重播 (PLR)。 我们修改“Robust PLR”(此处称为 PLR,Jiang 等人 (2021a))以适应我们的设置。 与空操作过滤相比,PLR 使用适应度分数 (Schmidhuber, 1991),该分数近似于代理对给定任务的遗憾。 我们考虑了代理后悔的几种潜在估计,范围从 Jiang 等人 (2021b) 中使用的 TD 错误,到使用 AdA 中的动力学模型错误的新方法(参见附录 D.5 和图 D.1)。
- PLR 通过维护一个固定大小的存档来运行,其中包含具有最高适应性的任务。 我们只在从档案中抽样的任务上训练 AdA,这种情况的发生概率为 𝑝。 以概率 1 − 𝑝 随机抽样和评估新任务,并将适应度与档案中的最低值进行比较。 如果新任务具有更高的适应度,则将其添加到存档中,并丢弃适应度最低的任务。 因此,PLR 也可以看作是一种过滤形式,使用动态标准(档案的最低适应值)。 它与 no-op 过滤的不同之处在于,任务可以从存档中重复采样,只要它们保持高适应性。 为了在我们的异构任务空间中应用 PLR,我们通过使用滚动均值和方差对每个试验指数的适应度进行归一化,并使用每个时间步长的平均适应度值而不是总和来解释不同的试验持续时间。 最后,由于我们对跨试验适应后代理能力前沿的任务感兴趣,因此我们仅使用上次试验的适应度。 有关详细信息,请参阅附录 D.5。
RL agent
- 学习算法。 我们使用 Muesli(Hessel 等人,2021)作为我们的 RL 算法。 我们在这里简要描述了该算法,但请读者参阅原始出版物以了解详细信息。 将依赖于历史的编码作为输入,在我们的例子中是 RNN 或 Transformer 的输出,AdA 学习序列模型(LSTM)来预测值𝑣ˆ𝑖、动作分布𝜋ˆ𝑖 并为接下来的𝐼 步骤奖励𝑟ˆ𝑖。 这里,𝑖 = 0, . . . , 𝐼 表示预测 𝑖 前进的步骤。 𝐼 通常很小,在我们的例子中𝐼 = 4。对于每个观察到的步骤𝑡,模型展开𝐼 步骤并更新到各自的目标:
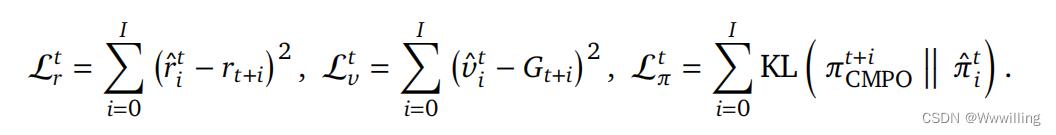
- 这里,𝑟𝑡+𝑖 指的是观察到的奖励。 𝐺𝑡+𝑖 是指基于从模型的一步预测中获得的 Q 值使用 Retrace(Munos 等人,2016)获得的价值目标。
- 行动目标 𝜋𝑡 CMPO 是通过使用剪裁的、归一化的、指数转换的优势重新加权当前策略 2 获得的。 Muesli 还基于这些优势结合了额外的辅助策略梯度损失,以帮助优化动作概率的即时预测。 最后,Muesli 维护一个跟踪序列模型的目标网络,用于执行和计算 Retrace 目标和优势。
- 内存架构。 记忆是适应的重要组成部分,因为它允许代理存储和回忆过去学习和经历的信息。 为了让智能体有效地适应任务要求的变化,记忆应该允许智能体回忆起最近和更久远的过去的信息。 虽然缓慢的基于梯度的更新能够捕获后者,但它们通常不够快以捕获前者,即快速适应。 基于记忆的元强化学习的大部分工作都依赖于 RNN 作为快速适应机制(Parisotto,2021)。 在这项工作中,我们表明 RNN 无法适应我们具有挑战性的部分可观察的体现 3D 任务空间。 我们试验了两种内存架构来解决这个问题:
- 带注意力的 RNN 在情景记忆中存储了一些过去的激活(在我们的例子中是 64 个)并关注它,使用当前的隐藏状态作为查询。 然后将注意力模块的输出与隐藏状态连接起来并送入 RNN。 我们通过仅在其情景记忆中存储每 8 次激活来增加代理的有效记忆长度。
我们得出这些数字是性能和速度之间的折衷。 请注意,生成的架构比同等大小的 Transformer 慢 - Transformer-XL (TXL)(Dai et al., 2019)是 Transformer 架构(Vaswani et al., 2017)的一个变体,它允许使用更长的、可变长度的上下文窗口来增加模型捕获的能力 长期依赖。 为了提高使用 RL 训练 Transformer 的稳定性,我们遵循 Parisotto 等人 (2020) 在每一层之前执行归一化,并像 Shazeer (2020) 一样在前馈层上使用门控。
- 两个内存模块都对一系列学习的时间步长嵌入进行操作,并生成一系列输出嵌入,这些嵌入被馈送到 Muesli 架构中,如图 4 中的 Transformer-XL 模块所示。 在第 3.2 节中,我们展示了两种基于注意力的记忆模块在需要适应的任务中都显着优于普通 RNN。 Transformer-XL 表现最好,因此除非另有说明,否则在我们的所有实验中都用作默认内存架构。
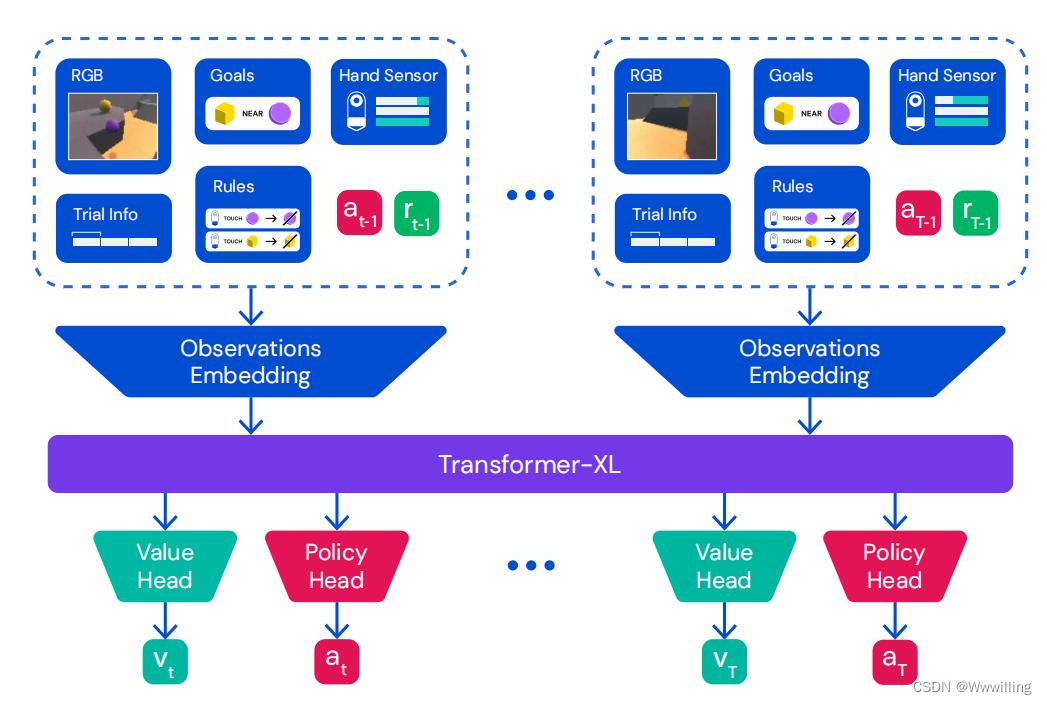
- 图 4 | 代理架构。 对于每个时间步,我们将像素观察、目标、手、试验和时间信息、生产规则、先前的动作和先前的奖励嵌入并组合到一个向量中。 这些观察嵌入按顺序传递给 Transformer-XL,其输出嵌入馈送到 MLP 值头、MLP 策略头和 Muesli LSTM 模型步骤(为简洁起见在图中省略)。 有关我们的代理架构的更多详细信息,请参阅附录 C.1。
- Going beyond few shots.。 我们建议对我们的 Transformer-XL 架构进行简单修改,以增加有效内存长度而无需额外的计算成本。 由于视觉 RL 环境中的观察结果往往在时间上高度相关,我们建议按照 RNN 中描述的注意力对序列进行子采样,允许代理参加 4 倍以上的试验。 为了确保仍然可以关注落在子采样点之间的观察结果,==我们首先使用 RNN 对整个轨迹进行编码,==目的是在每一步总结最近的历史记录。 我们表明,额外的 RNN 编码不会影响我们的 Transformer-XL 变体的性能,但可以实现更长范围的记忆(参见第 3.7 节)。
Distillation
- 对于前 40 亿步的训练,我们使用额外的蒸馏损失(Czarnecki 等人,2019 年;Schmidhuber,1992 年;Schmitt 等人,2018 年)通过预训练教师的策略来指导 AdA 的学习,在 称为启动的过程; 迭代此过程会产生代际训练机制(OEL Team 等人,2021 年;Wang 等人,2021 年)。 教师通过 RL 从头开始预训练,使用与 AdA 相同的训练程序和超参数,除了缺少初始蒸馏和更小的模型大小(教师的 23M Transformer 参数和多智能体 AdA 的 265M)。 与上述先前的工作不同,我们在前几代中不采用塑造奖励或基于人口的培训(PBT,Jaderberg 等人(2017))。 在蒸馏过程中,AdA 根据自己的策略行事,教师根据 AdA 观察到的轨迹提供目标 logits。 蒸馏使我们能够分摊原本昂贵的初始训练期,并且它允许代理人克服在训练初始阶段获得的有害表征; 参见第 3.6 节。
- 为了将蒸馏损失与Muesli相结合,我们从学生观察到的每个转变中展开模型。 我们最小化模型预测的所有动作概率与教师策略在相应时间步预测的动作概率之间的 KL 散度。 类似于 (1) 中定义的 Muesli 策略损失 L𝜋,我们定义

- 其中 π ^ \\hat\\pi π^ 对应于教师在给定相同观察历史的情况下提供的预测动作逻辑。 此外,我们发现在蒸馏过程中添加额外的 L 2 L^2 L2 正则化很有用。
以上是关于使用 SEED RL 大规模扩展强化学习的主要内容,如果未能解决你的问题,请参考以下文章