JVM调优的几种场景(建议收藏)
Posted Java充电社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM调优的几种场景(建议收藏)相关的知识,希望对你有一定的参考价值。
最近很多小伙伴跟我说,自己学了不少JVM的调优知识,但是在实际工作中却不知道何时对JVM进行调优。今天,就为大家介绍几种JVM调优的场景。
点击上方,关注我,java干货及时送达
cpu占用过高在阅读本文时,假定大家已经了解了运行时的数据区域和常用的垃圾回收算法,也了解了Hotspot支持的垃圾回收器。
cpu占用过高要分情况讨论,是不是业务上在搞活动,突然有大批的流量进来,而且活动结束后cpu占用率就下降了,如果是这种情况其实可以不用太关心,因为请求越多,需要处理的线程数越多,这是正常的现象。话说回来,如果你的服务器配置本身就差,cpu也只有一个核心,这种情况,稍微多一点流量就真的能够把你的cpu资源耗尽,这时应该考虑先把配置提升吧。
第二种情况,cpu占用率长期过高,这种情况下可能是你的程序有那种循环次数超级多的代码,甚至是出现死循环了。排查步骤如下:
(1)用top命令查看cpu占用情况
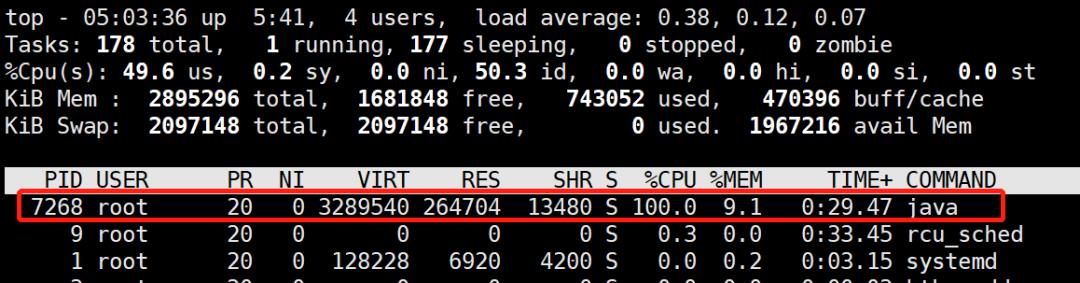
这样就可以定位出cpu过高的进程。在linux下,top命令获得的进程号和jps工具获得的vmid是相同的:

(2)用top -Hp命令查看线程的情况

可以看到是线程id为7287这个线程一直在占用cpu
(3)把线程号转换为16进制
[root@localhost ~]# printf "%x" 7287
1c77
记下这个16进制的数字,下面我们要用
(4)用jstack工具查看线程栈情况
[root@localhost ~]# jstack 7268 | grep 1c77 -A 10
"http-nio-8080-exec-2" #16 daemon prio=5 os_prio=0 tid=0x00007fb66ce81000 nid=0x1c77 runnable [0x00007fb639ab9000]
java.lang.Thread.State: RUNNABLE
at com.spareyaya.jvm.service.EndlessLoopService.service(EndlessLoopService.java:19)
at com.spareyaya.jvm.controller.JVMController.endlessLoop(JVMController.java:30)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:190)
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:138)
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:105)
通过jstack工具输出现在的线程栈,再通过grep命令结合上一步拿到的线程16进制的id定位到这个线程的运行情况,其中jstack后面的7268是第(1)步定位到的进程号,grep后面的是(2)、(3)步定位到的线程号。
从输出结果可以看到这个线程处于运行状态,在执行com.spareyaya.jvm.service.EndlessLoopService.service这个方法,代码行号是19行,这样就可以去到代码的19行,找到其所在的代码块,看看是不是处于循环中,这样就定位到了问题。
死锁并没有第一种场景那么明显,web应用肯定是多线程的程序,它服务于多个请求,程序发生死锁后,死锁的线程处于等待状态(WAITING或TIMED_WAITING),等待状态的线程不占用cpu,消耗的内存也很有限,而表现上可能是请求没法进行,最后超时了。在死锁情况不多的时候,这种情况不容易被发现。
可以使用jstack工具来查看
(1)jps查看java进程
[root@localhost ~]# jps -l
8737 sun.tools.jps.Jps
8682 jvm-0.0.1-SNAPSHOT.jar
(2)jstack查看死锁问题
由于web应用往往会有很多工作线程,特别是在高并发的情况下线程数更多,于是这个命令的输出内容会十分多。jstack最大的好处就是会把产生死锁的信息(包含是什么线程产生的)输出到最后,所以我们只需要看最后的内容就行了
Java stack information for the threads listed above:
===================================================
"Thread-4":
at com.spareyaya.jvm.service.DeadLockService.service2(DeadLockService.java:35)
- waiting to lock <0x00000000f5035ae0> (a java.lang.Object)
- locked <0x00000000f5035af0> (a java.lang.Object)
at com.spareyaya.jvm.controller.JVMController.lambda$deadLock$1(JVMController.java:41)
at com.spareyaya.jvm.controller.JVMController$$Lambda$457/1776922136.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"Thread-3":
at com.spareyaya.jvm.service.DeadLockService.service1(DeadLockService.java:27)
- waiting to lock <0x00000000f5035af0> (a java.lang.Object)
- locked <0x00000000f5035ae0> (a java.lang.Object)
at com.spareyaya.jvm.controller.JVMController.lambda$deadLock$0(JVMController.java:37)
at com.spareyaya.jvm.controller.JVMController$$Lambda$456/474286897.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
发现了一个死锁,原因也一目了然。
内存泄漏我们都知道,java和c++的最大区别是前者会自动收回不再使用的内存,后者需要程序员手动释放。在c++中,如果我们忘记释放内存就会发生内存泄漏。但是,不要以为jvm帮我们回收了内存就不会出现内存泄漏。
程序发生内存泄漏后,进程的可用内存会慢慢变少,最后的结果就是抛出OOM错误。发生OOM错误后可能会想到是内存不够大,于是把-Xmx参数调大,然后重启应用。这么做的结果就是,过了一段时间后,OOM依然会出现。最后无法再调大最大堆内存了,结果就是只能每隔一段时间重启一下应用。
内存泄漏的另一个可能的表现是请求的响应时间变长了。这是因为频繁发生的GC会暂停其它所有线程(Stop The World)造成的。
为了模拟这个场景,使用了以下的程序
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main
public static void main(String[] args)
Main main = new Main();
while (true)
try
Thread.sleep(1);
catch (InterruptedException e)
e.printStackTrace();
main.run();
private void run()
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++)
executorService.execute(() ->
// do something...
);
运行参数是-Xms20m -Xmx20m -XX:+PrintGC,把可用内存调小一点,并且在发生gc时输出信息,运行结果如下
...
[GC (Allocation Failure) 12776K->10840K(18432K), 0.0309510 secs]
[GC (Allocation Failure) 13400K->11520K(18432K), 0.0333385 secs]
[GC (Allocation Failure) 14080K->12168K(18432K), 0.0332409 secs]
[GC (Allocation Failure) 14728K->12832K(18432K), 0.0370435 secs]
[Full GC (Ergonomics) 12832K->12363K(18432K), 0.1942141 secs]
[Full GC (Ergonomics) 14923K->12951K(18432K), 0.1607221 secs]
[Full GC (Ergonomics) 15511K->13542K(18432K), 0.1956311 secs]
...
[Full GC (Ergonomics) 16382K->16381K(18432K), 0.1734902 secs]
[Full GC (Ergonomics) 16383K->16383K(18432K), 0.1922607 secs]
[Full GC (Ergonomics) 16383K->16383K(18432K), 0.1824278 secs]
[Full GC (Allocation Failure) 16383K->16383K(18432K), 0.1710382 secs]
[Full GC (Ergonomics) 16383K->16382K(18432K), 0.1829138 secs]
[Full GC (Ergonomics) Exception in thread "main" 16383K->16382K(18432K), 0.1406222 secs]
[Full GC (Allocation Failure) 16382K->16382K(18432K), 0.1392928 secs]
[Full GC (Ergonomics) 16383K->16382K(18432K), 0.1546243 secs]
[Full GC (Ergonomics) 16383K->16382K(18432K), 0.1755271 secs]
[Full GC (Ergonomics) 16383K->16382K(18432K), 0.1699080 secs]
[Full GC (Allocation Failure) 16382K->16382K(18432K), 0.1697982 secs]
[Full GC (Ergonomics) 16383K->16382K(18432K), 0.1851136 secs]
[Full GC (Allocation Failure) 16382K->16382K(18432K), 0.1655088 secs]
java.lang.OutOfMemoryError: Java heap space
可以看到虽然一直在gc,占用的内存却越来越多,说明程序有的对象无法被回收。但是上面的程序对象都是定义在方法内的,属于局部变量,局部变量在方法运行结果后,所引用的对象在gc时应该被回收啊,但是这里明显没有。
为了找出到底是哪些对象没能被回收,我们加上运行参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.bin,意思是发生OOM时把堆内存信息dump出来。运行程序直至异常,于是得到heap.dump文件,然后我们借助eclipse的MAT插件来分析,如果没有安装需要先安装。
然后File->Open Heap Dump... ,然后选择刚才dump出来的文件,选择Leak Suspects
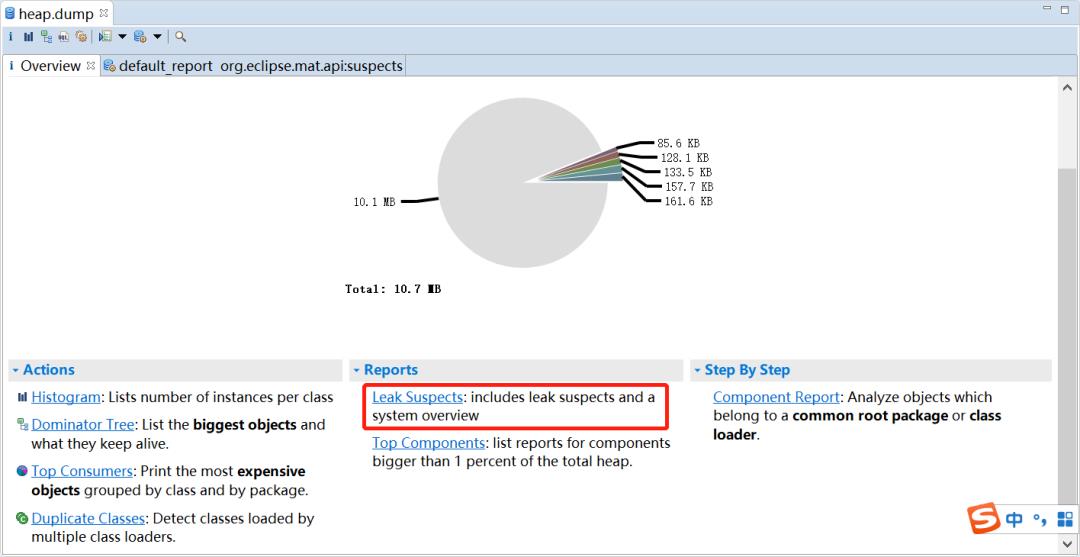
MAT会列出所有可能发生内存泄漏的对象
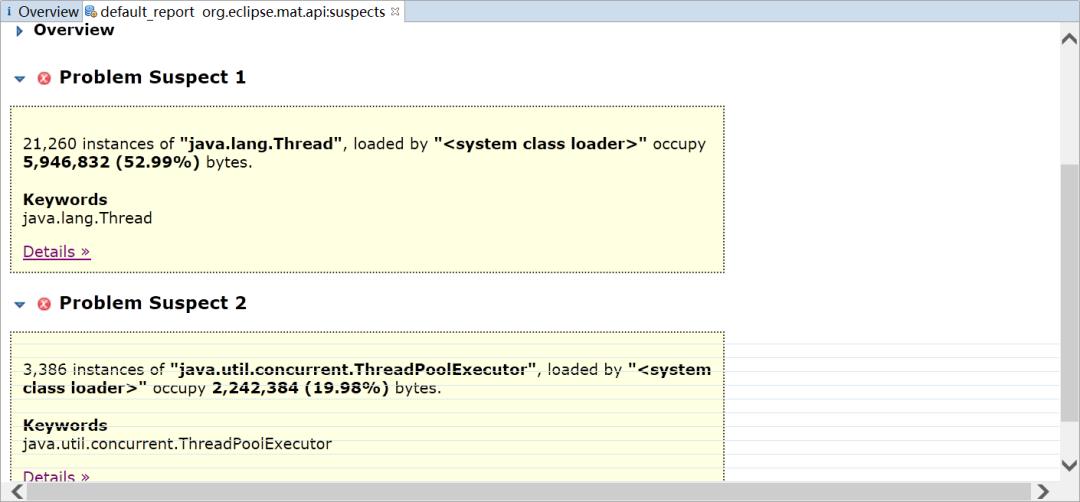
可以看到居然有21260个Thread对象,3386个ThreadPoolExecutor对象,如果你去看一下java.util.concurrent.ThreadPoolExecutor的源码,可以发现线程池为了复用线程,会不断地等待新的任务,线程也不会回收,需要调用其shutdown方法才能让线程池执行完任务后停止。
其实线程池定义成局部变量,好的做法是设置成单例。
上面只是其中一种处理方法
在线上的应用,内存往往会设置得很大,这样发生OOM再把内存快照dump出来的文件就会很大,可能大到在本地的电脑中已经无法分析了(因为内存不足够打开这个dump文件)。这里介绍另一种处理办法:
(1)用jps定位到进程号
C:\\Users\\spareyaya\\IdeaProjects\\maven-project\\target\\classes\\org\\example\\net>jps -l
24836 org.example.net.Main
62520 org.jetbrains.jps.cmdline.Launcher
129980 sun.tools.jps.Jps
136028 org.jetbrains.jps.cmdline.Launcher
因为已经知道了是哪个应用发生了OOM,这样可以直接用jps找到进程号135988
(2)用jstat分析gc活动情况
jstat是一个统计java进程内存使用情况和gc活动的工具,参数可以有很多,可以通过jstat -help查看所有参数以及含义
C:\\Users\\spareyaya\\IdeaProjects\\maven-project\\target\\classes\\org\\example\\net>jstat -gcutil -t -h8 24836 1000
Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
29.1 32.81 0.00 23.48 85.92 92.84 84.13 14 0.339 0 0.000 0.339
30.1 32.81 0.00 78.12 85.92 92.84 84.13 14 0.339 0 0.000 0.339
31.1 0.00 0.00 22.70 91.74 92.72 83.71 15 0.389 1 0.233 0.622
上面是命令意思是输出gc的情况,输出时间,每8行输出一个行头信息,统计的进程号是24836,每1000毫秒输出一次信息。
输出信息是Timestamp是距离jvm启动的时间,S0、S1、E是新生代的两个Survivor和Eden,O是老年代区,M是Metaspace,CCS使用压缩比例,YGC和YGCT分别是新生代gc的次数和时间,FGC和FGCT分别是老年代gc的次数和时间,GCT是gc的总时间。虽然发生了gc,但是老年代内存占用率根本没下降,说明有的对象没法被回收(当然也不排除这些对象真的是有用)。
(3)用jmap工具dump出内存快照
jmap可以把指定java进程的内存快照dump出来,效果和第一种处理办法一样,不同的是它不用等OOM就可以做到,而且dump出来的快照也会小很多。
jmap -dump:live,format=b,file=heap.bin 24836
这时会得到heap.bin的内存快照文件,然后就可以用eclipse来分析了。
总结以上三种严格地说还算不上jvm的调优,只是用了jvm工具把代码中存在的问题找了出来。我们进行jvm的主要目的是尽量减少停顿时间,提高系统的吞吐量。但是如果我们没有对系统进行分析就盲目去设置其中的参数,可能会得到更坏的结果,jvm发展到今天,各种默认的参数可能是实验室的人经过多次的测试来做平衡的,适用大多数的应用场景。如果你认为你的jvm确实有调优的必要,也务必要取样分析,最后还得慢慢多次调节,才有可能得到更优的效果。
好了,今天就到这儿吧,我们下期见~~
如果觉得分享的不错,欢迎大家分享、转发、在看!
转自: cnblogs.com/spareyaya/p/13174003.html
其他学习资料尚硅谷 Java 学科全套教程(总 207.77GB) 2021 最新版 Java 微服务学习线路图 + 视频 阿里技术大佬整理的《Spring 学习笔记.pdf》 2021 版 java 高并发常见面试题汇总.pdf Idea 快捷键大全.pdf
点击上方卡片关注我
一次JVM GC引发的Spark调优大全(建议收藏)
一般在我们开发spark程序的时候,从代码开发到上线以及后期的维护中,在整个过程中都需要涉及到调优的问题,即一开始需要考虑如何把代码写的更简洁高效调优(即代码优化),待开发测试完成后,提交任务时综合考量该任务所需的资源(这里涉及到资源调优),上线后是否会出现数据倾斜问题(即倾斜调优),以及是否出现频繁GC问题(这里涉及到GC调优)。
那么本篇通过反推的模式,即通过GC调优进行延伸扩展,比如出现GC问题是不是可能出现了倾斜?如果没有出现倾斜,是不是我们给的资源不足?如果资源充足的话,那么是不是我们代码写的有问题呢(比如频繁创建对象等操作)?按照这样一个思路展开来总结spark的调优。
JVM的堆、栈、方法区
如上图所示,JVM主要由类加载器系统、运行时数据区、执行引擎和本地接口等组成。
其中运行时数据区又由方法区、堆、Java栈、PC寄存器、本地方法栈组成。
当JVM加载一个class文件后,class中的参数、类型等信息会存储到方法区中,程序运行时所创建的对象存储在堆中(堆中不放基本类型和对象引用,只存放对象本身)。当每个新线程启动时,会有自己的程序计数器(Program Counter Register)和栈,当线程调用方法时,程序计数器表明下一条执行的指令,同时线程栈会存储线程的方法调用状态(包括局部变量、被调用的参数、中间结果等)。本地方法调用存储在独立的本地方法栈中,或其他独立的内存区域中。
栈区由栈桢组成,每个栈桢就是每个调用的方法的栈,当方法调用结束后,JVM会弹栈,即抛弃此方法的栈桢。
JVM内存划分
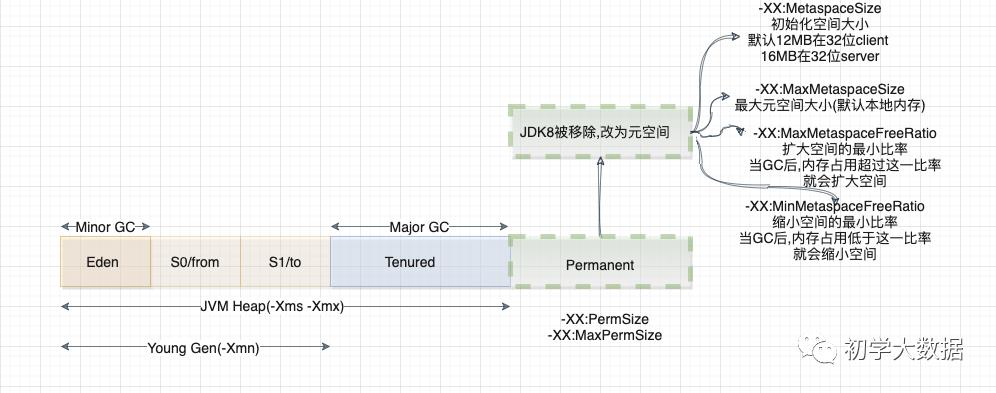
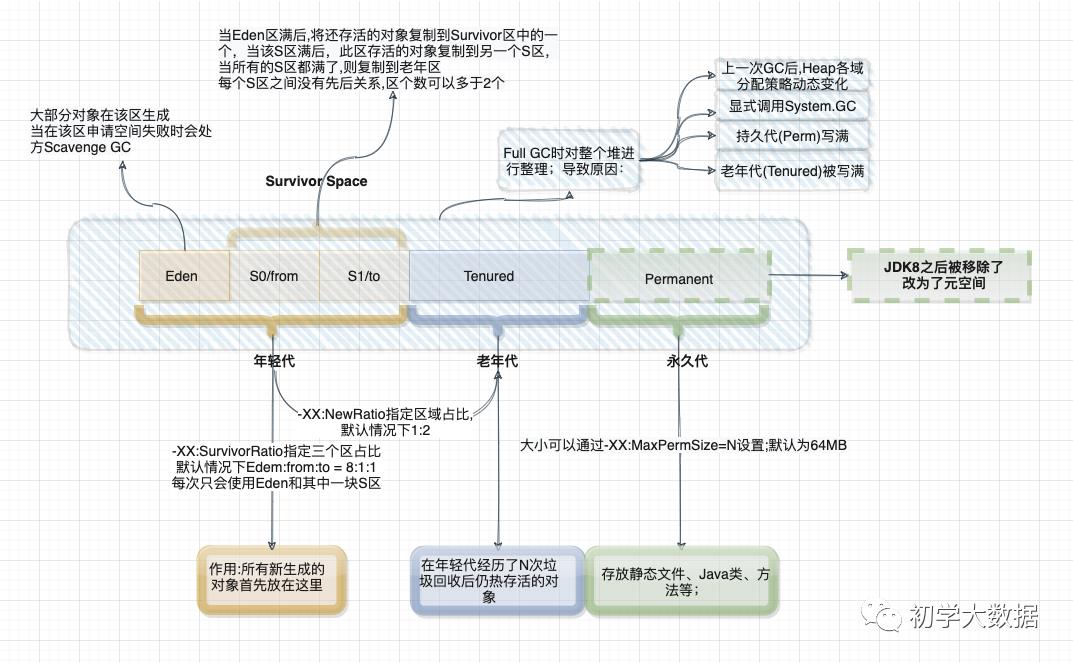 上图中的划分是基于JDK7和JDK8,其中有一些变动(主要是永久代的移除)。
上图中的划分是基于JDK7和JDK8,其中有一些变动(主要是永久代的移除)。
JVM内存从大体上划分为三部分:年轻代、老年代、永久代(元空间)
年轻代:所有新生成的对象都会先放到年轻代,年轻代又分为三个区:Eden区、两个Survivor,三者之间的比例为8:1:1。
Eden区:大部分对象会在该区生成,当在Eden区申请空间失败后,会触发Scavenge GC,对Eden区进行GC,清除非存活对象,并把还存活的对象复制到其中一个Survivor区中。这里可能会有一个问题,由于默认情况下Eden:Survivor1:Survivor2的内存占比是8:1:1,如果存活下来的对象是1.5,一个Survivor区域放不下,那么这个时候就会利用JVM的担保机制,将多余的对象直接放入老年代,会出现老年代囤积一大堆短生命周期的,导致老年代频繁溢满,频繁进行Full GC去回收老年代中的对象
Survivor区:当Eden区满后,会把还存活的对象复制到其中一个S区中,且两个S区之间没有先后顺序关系,同时根据程序需要Survivor区是可以配置多个的,这样可以增加对象在年轻代存在的时间,减少被放到老年代的可能。JVM每次只会使用Eden和其中一块Survivor区域来为对象服务,所以无论什么时候总会有一块Survivor区域是空闲的,也就是说年轻代实际可用的内存空间为9/10的年轻代空间。
老年代:在年轻代中经历了N次GC之后仍然存活的对象,就会被放到老年代中。该区域通常存放一些生命周期较长的对象。默认情况下,年轻代和老年代的比值为1:2,即老年代占用堆空间大小的2/3,当然这个值可以通过-XX:NewRation来调整
持久代:主要存放静态文件、Java类、方法等。在Java 8中该区域已经被移除了,开始使用本地化的内存来存放类的元数据,也称之元空间
JVM GC
 JVM主要管理两种类型的内存:堆和非堆,简单来说,堆就是Java代码可及的内存,是留给开发人员用的,非堆就是JVM留给自己用的。
JVM主要管理两种类型的内存:堆和非堆,简单来说,堆就是Java代码可及的内存,是留给开发人员用的,非堆就是JVM留给自己用的。
-
当Eden满了之后,一个小型的GC就会被触发(Minor GC),Eden和Survivor1中幸存仍被使用的对象被复制到Survivor2。 -
Survivor1和Survivor2区域进行交换,当一个对象生存的时间足够长或者Survivor2满了之后,就会被转移到Old代 -
当Old空间快满的时候,这个时候会进行Full GC
一般以下几种情况可能会导致Full GC:
-
当Old空间被写满时 -
System.GC()被显式调用 -
上一次GC之后,Heap的各个区域分配策略动态变化
以上简单说明一下jvm相关知识点,其实spark GC的目的就是要确保老年代只保存长生命周期RDD,同时年轻代的空间又能够保存短生命周期的对象,这样就能避免启动Full GC
Spark对JVM的使用
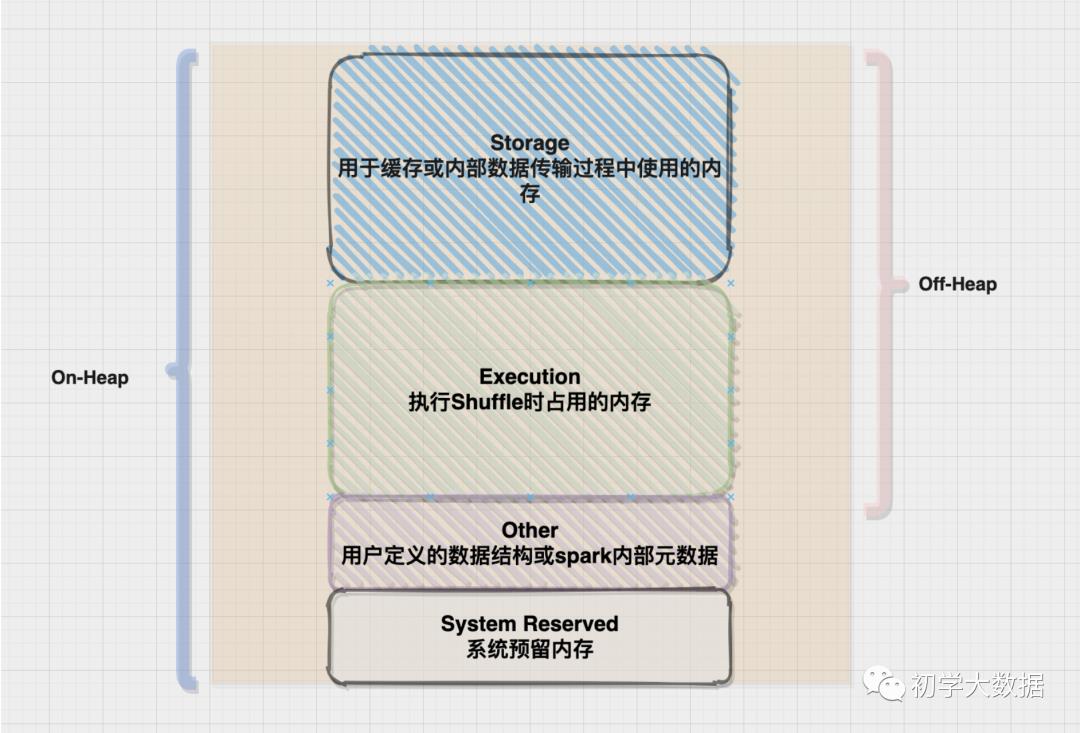 基于上篇Tungsten on spark 文章的整理,Executor对内存的使用主要有以下几个部分:
基于上篇Tungsten on spark 文章的整理,Executor对内存的使用主要有以下几个部分:
-
RDD存储。当对RDD调用persist或Cache方法时,RDD的partitons会被存储到内存里,那么这块内存也就是Storage内存。 -
Shuffle操作。当发生Shuffle时,需要缓冲区来存储Shuffle的输出和聚合的中间结果,该块内存称之为Execution内存。 -
用户代码。用户编写的代码能够使用的内存空间,也就是其他内存(用户内存)
在统一内存模式下,整个堆空间分为Spark Memory和User Memory,其中Spark Memory包括Storage Memory和Execution Memory,而且两者之间可以互相借用空间。
通过spark.memory.fraction参数来控制Spark Memory在整个堆空间所占的比例
通过spark.memory.storageFraction来设置Storage Memory占Spark Memory的比例,如果Spark作业中有较多的RDD持久化操作,该参数值可以适当调高,保证持久化的数据能够容纳在内存中,避免内存不够缓存所有的数据,只能写入磁盘中,降低性能。如果Spark作业中Shuffle类操作比较多,持久化类操作比较少,那么可以适当降低该参数值。
这里给出一个实际的例子来说明一下spark是如何分配内存的
/usr/local/spark-current/bin/spark-submit
--master yarn
--deploy-mode client
--executor-memory 1G
--queue root.default
--class my.Application
--conf spark.ui.port=4052
--conf spark.port.maxRetries=100
--num-executors 2
--jars mongo-spark-connector_2.11-2.3.1.jar
App.jar 20201118000000
# 这里配置两个Executor,每个Executor内存给1G
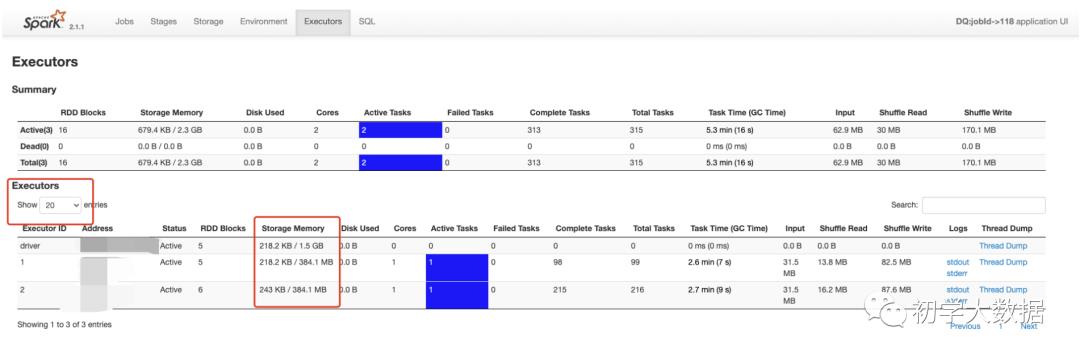 如图所示,spark申请到了两个Executor,每个Executor得到的Storage Memory内存分别为384.1MB(注意:这里Storage Memory其实就是Storage+Execution的总和内存),这里有一个疑惑,我们分配的是每个Executor内存为1G,为什么只得到384MB呢?这里给出具体的计算公式:
如图所示,spark申请到了两个Executor,每个Executor得到的Storage Memory内存分别为384.1MB(注意:这里Storage Memory其实就是Storage+Execution的总和内存),这里有一个疑惑,我们分配的是每个Executor内存为1G,为什么只得到384MB呢?这里给出具体的计算公式:
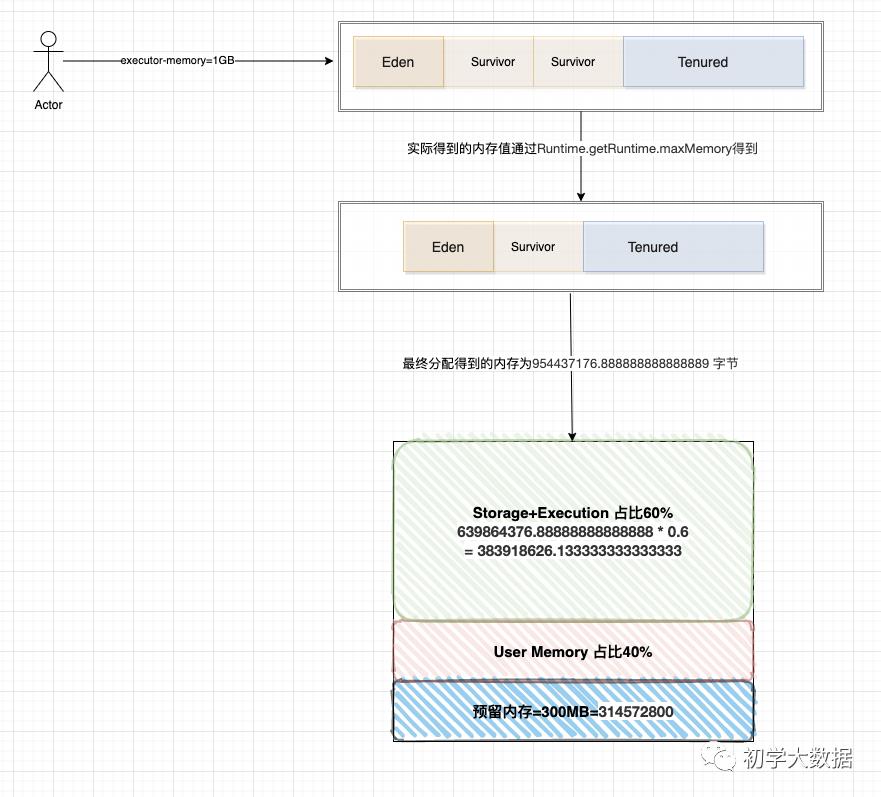
-
我们申请为1G内存,但是真正拿到内存会比这个少,这里涉及到一个Runtime.getRuntime.maxMemory 值的计算(在上篇文章中关于UnifiedMemoryManager源码分析中提到过),Runtime.getRuntime.maxMemory对应的值才是程序能够使用的最大内存,上面也提到了堆划分了Eden,Survivor,Tenured区域,所以该值计算公式为:
ExecutorMemory = Eden + 2 * Survivor + Tenured = 1GB = 1073741824 字节
systemMemory = Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured = 954437176.888888888888889 字节
//org.apache.spark.memory.UnifiedMemoryManager(这里讨论的还是动态内存模型)
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
//这里即获取最大的内存值
(usableMemory * memoryFraction).toLong
} -
基于Spark的动态内存模型设计,其中有300MB的预留内存,因此剩余可用内存为总申请得到的内存-预留内存
reservedMemory = 300MB = 314572800字节
usableMemory = systemMemory - reservedMemory = 954437176.888888888888889 - 314572800 = 639864376.888888888888889字节
-
Spark Web UI界面上虽然显示的是Storage Memory,但其实是Execution+Storage内存,即该部分占用60%比例
Storage + Execution = usableMemory * 0.6 = 639864376.888888888888889 * 0.6 = 383918626.133333333333333 字节
-
通过第三步骤即可看出实际的内存分配情况了,注意:web ui界面得到的结果计算是除于1000转换得到的值。
GC调优步骤
-
统计一下GC启动的频率和GC使用的总时间,即在spark-submit提交的时候设置参数即可
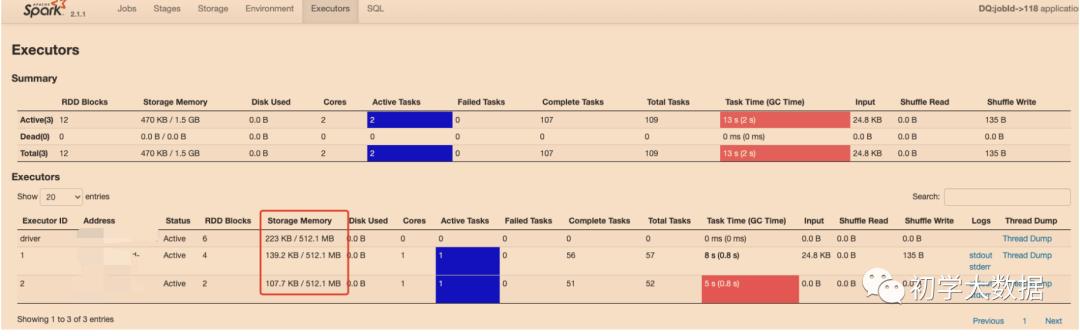 如图所示,这里提高了spark.memory.fraction参数值,则每个Exectuor实际可用的内存也随之增加了.
如图所示,这里提高了spark.memory.fraction参数值,则每个Exectuor实际可用的内存也随之增加了./usr/local/spark-current/bin/spark-submit
--master yarn
--deploy-mode client
--executor-memory 1G
--driver-memory 1G
--queue root.default
--class my.Application
--conf spark.ui.port=4052
--conf spark.port.maxRetries=100
--num-executors 2
--jars mongo-spark-connector_2.11-2.3.1.jar
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
--conf spark.memory.fraction=0.8
App.jar
 如图所示,出现了多次Full GC,首先考虑的是可能配置的Executor内存较低,这个时候需要增加Executor Memory来调节。
如图所示,出现了多次Full GC,首先考虑的是可能配置的Executor内存较低,这个时候需要增加Executor Memory来调节。
-
检查GC日志中是否有过于频繁的GC。如果一个任务结束前,Full GC执行多次,说明老年代空间被占满了,那么有可能是没有分配足够的内存。
1.调整executor的内存,配置参数executor-memory
2.调整老年代所占比例:配置-XX:NewRatio的比例值
3.降低spark.memory.storageFraction减少用于缓存的空间 -
如果有太多Minor GC,但是Full GC不多,可以给Eden分配更多的内存.
1.比如Eden代的内存需求量为E,可以设置Young代的内存为-Xmn=4/3*E,设置该值也会导致Survivor区域扩张
2.调整Eden在年轻代所占的比例,配置-XX:SurvivorRatio的比例值 -
调整垃圾回收器,通常使用G1GC,即配置-XX:+UseG1GC。当Executor的堆空间比较大时,可以提升G1 region size(-XX:G1HeapRegionSize)
/usr/local/spark-current/bin/spark-submit
--master yarn
--deploy-mode client
--executor-memory 1G
--driver-memory 1G
--queue root.default
--class my.Application
--conf spark.ui.port=4052
--conf spark.port.maxRetries=100
--num-executors 2
--jars mongo-spark-connector_2.11-2.3.1.jar
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC -XX:G1HeapRegionSize=16M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
--conf spark.memory.fraction=0.8
App.jar -
优化代码,尽量多使用array和string,并使用kyro序列,让每个Partition都成为字节数组
-
结合实际的需求,调整缓存和shuffle计算所占的内存比例,即当代码中出现shuffle类操作比较多,而不需要太多缓存的话,则可以适当降低Storage Memory所占比例;当缓存操作比较多,而Shuffle类操作比较少的话,可以适当调低Execution Memory所占比例。主要是通过spark.storage.storageFraction来控制
-
开启堆外内存,设置堆外内存大小,这里为了避免OOM
spark.memory.offHeap.size=4G
spark.memory.offHeap.enabled=true
注意:这里需要说明一下spark.executor.memoryOverhead 和spark.memory.offHeap.size之间的区别
spark.executor.memoryOverhead是属于JVM堆外内存,用于JVM自身的开销、内部的字符串还有一些本地开销,spark不会对这块内存进行管理。默认大小为ExecutorMemory的10%,在spark2.4.5之前,该参数的值应该包含spark.memory.offHeap.size的值。比如spark.memory.offHeap.size配置500M,spark.executor.memoryOverhead默认为384M,那么memoryOverhead的值应该为884M。
//spark2.4.5之前的
// Executor memory in MB.
protected val executorMemory = sparkConf.get(EXECUTOR_MEMORY).toInt
// Additional memory overhead.
protected val memoryOverhead: Int = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN)).toInt
protected val pysparkWorkerMemory: Int = if (sparkConf.get(IS_PYTHON_APP)) {
sparkConf.get(PYSPARK_EXECUTOR_MEMORY).map(_.toInt).getOrElse(0)
} else {
0
}
// Resource capability requested for each executors
private[yarn] val resource = Resource.newInstance(
executorMemory + memoryOverhead + pysparkWorkerMemory,
executorCores)
//由于memoryOverHead的参数值理解起来比较困难,而且不易于用户对每个特定的内存区域进行自定义配置,所以在Spark3.0之后进行了拆分
//spark3.0之后的资源申请更改为
private[yarn] val resource: Resource = {
val resource = Resource.newInstance(
executorMemory + executorOffHeapMemory + memoryOverhead + pysparkWorkerMemory, executorCores)
ResourceRequestHelper.setResourceRequests(executorResourceRequests, resource)
logDebug(s"Created resource capability: $resource")
resource
}
spark.memory.offHeap.size这个参数指定的内存(广义上是指所有堆外的),这部分内存的申请和释放是直接进行的,不由JVM管理,所以这块是没有GC的。
倾斜调优
倾斜部分的调优可以阅读下面两篇文章,相对来说已经比较全了
开发调优
相信有很多读者应该非常熟悉以下这几种使用姿势了,这里就不再重复详细说明了
-
避免创建重复的RDD
-
尽可能复用同一个RDD
-
对多次使用的RDD进行持久化
-
尽量避免使用Shuffle算子
-
使用map-side预聚合的shuffle操作
-
使用高性能的算子
6.1: 使用reduceByKey/aggregateByKey替代groupByKey
6.2: 使用mapPartitions替代普通map
6.3: 使用foreachPartitions替代foreach
6.4: 使用filter之后进行coalesce操作
6.5: 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
-
广播大变量
val list1 = ...
val list1Broadcast = sc.broadcast(list1)
rdd1.map(list1Broadcast...) -
使用kryo优化序列化性能
// 创建SparkConf对象
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 设置序列化器为KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) -
优化数据结构,尽量使用字符串代替对象,使用原始类型(如int,Long)代替字符串,使用数组代替集合类型
资源参数调优
众所周知,引起GC主要是内存资源问题,一般情况下是不需要对GC进行调优的。当出现GC问题时,那么就需要思考是哪个环节造成内存紧张。首先想到的应该是配置的内存不足,直接加资源,这里整理了一些配置参数,仅供读者参考。
| 应用行为 | 属性名 | 默认值 | 属性描述 | 生效版本 |
|---|---|---|---|---|
| driver行为 | spark.driver.cores | 1 | driver程序运行需要的cpu内核数 | 1.3.0 |
| driver行为 | spark.driver.maxResultSize | 1G | 每个Spark action(如collect)所有分区的序列化结果的总大小限制。设置的值应该不小于1m,0代表没有限制。如果总大小超过这个限制,程序将会终止。大的限制值可能导致driver出现内存溢出错误(依赖于spark.driver.memory和JVM中对象的内存消耗) |
1.2.0 |
| driver行为 | spark.driver.memory | 1G | driver进程使用的内存数 | 1.1.1 |
| driver行为 | spark.driver.memoryOverhead | driverMemory * 0.10,with minimum of 384 | driver端分配的堆外内存 | 2.3.0 |
| driver行为 | spark.driver.extraClassPath | None | 附加到driver的classpath的额外的classpath实体 | 1.0.0 |
| driver行为 | spark.driver.defaultJavaOptions | None | 默认传递给driver的JVM选项字符串。注意这个配置不能直接在代码中使用SparkConf来设置,因为这个时候driver JVM已经启动了,可以在命令行通过--driver-java-options参数来设置 | 3.0.0 |
| driver行为 | spark.driver.extraJavaOptions | None | 传递给driver的JVM选项字符串。例如GC设置或者其它日志设置。注意,在这个选项中设置Spark属性或者堆大小是不合法的。Spark属性需要用--driver-class-path设置 |
1.0.0 |
| driver行为 | spark.driver.extraLibraryPath | None | 指定启动driver的JVM时用到的库路径 | 1.0.0 |
| driver行为 | spark.driver.userClassPathFirst | false | 当在driver中加载类时,是否用户添加的jar比Spark自己的jar优先级高。这个属性可以降低Spark依赖和用户依赖的冲突,现在还是一个实验性的特征 | 1.3.0 |
| executor行为 | spark.executor.memory | 1G | 每个executor进程使用的内存数 | 0.7.0 |
| executor行为 | spark.executor.memoryOverhead | executorMemory * 0.10, with minimum of 384 | Executor JVM堆外内存设置,用于解决JVM开销,内部字符串,其他本机开销等问题 | 2.3.0 |
| executor行为 | spark.executor.extraClassPath | None | 附加到executors的classpath的额外的classpath实体。这个设置存在的主要目的是Spark与旧版本的向后兼容问题。用户一般不用设置这个选项 | 1.0.0 |
| executor行为 | spark.executor.defaultJavaOptions | None | 默认的JVM选项,以附加到spark.executor.extraJavaOptions | 3.0.0 |
| executor行为 | spark.executor.extraJavaOptions | None | 传递给executors的JVM选项字符串。例如GC设置或者其它日志设置。注意,在这个选项中设置Spark属性或者堆大小是不合法的。Spark属性需要用SparkConf对象或者spark-submit脚本用到的spark-defaults.conf文件设置。堆内存可以通过spark.executor.memory设置 |
1.0.0 |
| executor行为 | spark.executor.extraLibraryPath | None | 指定启动executor的JVM时用到的库路径 | 1.0.0 |
| executor行为 | spark.executor.userClassPathFirst | false | (实验性)与spark.driver.userClassPathFirst相同的功能,但应用于执行程序实例. | 1.3.0 |
| executor行为 | spark.executor.cores | 1 | 每个executor使用的核数 | 1.0.0 |
| executor行为 | spark.default.parallelism | 本地模式:机器核数;Mesos:8;其他:max(executor的core,2) |
默认并行度 | 0.5.0 |
| shuffle行为 | spark.reducer.maxSizeInFlight | 48m | 从每个reduce中获取的最大容量,该参数值如果过低时,会导致Shuffle过程中产生的数据溢出到磁盘 | 1.4.0 |
| shuffle行为 | spark.reducer.maxReqsInFlight | Int.MaxValue | 此配置限制了获取块的远程请求的数量 | 2.0.0 |
| shuffle行为 | spark.reducer.maxBlocksInFlightPerAddress | Int.MaxValue | 该配置限制了reduce任务从其他机器获取远程块的数量 | 2.2.1 |
| shuffle行为 | spark.shuffle.compress | true | 是否压缩map操作的输出文件 | 0.6.0 |
| shuffle行为 | spark.shuffle.file.buffer | 32k | 每个shuffle文件输出缓存的大小 | 1.4.0 |
| shuffle行为 | spark.shuffle.io.maxRetries | 3 | (Netty only)自动重试次数 | 1.2.0 |
| shuffle行为 | spark.shuffle.io.numConnectionsPerPeer | 1 | (Netty only)机器之间的连接复用 | 1.2.1 |
| shuffle行为 | spark.shuffle.io.preferDirectBufs | true | (Netty only)直接堆外内存,用于减少随机和高速缓存块传输期间的GC | 1.2.0 |
| shuffle行为 | spark.shuffle.io.retryWait | 5s | (Netty only)重试提取之间要等待多长时间;默认情况下重试导致的最大延迟为15s | 1.2.1 |
| shuffle行为 | spark.shuffle.service.enabled | false | 启用外部shuffle服务 | 1.2.0 |
| shuffle行为 | spark.shuffle.service.index.cache.size | 100m | 缓存条目限制为指定的内存占用,以字节为单位 | 2.3.0 |
| shuffle行为 | spark.shuffle.sort.bypassMergeThreshold | 200 | 如果shuffle map task的数量小于这个阀值200,且不是聚合类的shuffle算子(比如reduceByKey),则不会进行排序 | 1.1.1 |
| shuffle行为 | spark.shuffle.spill.compress | true | 在shuffle时,是否将spilling的数据压缩。压缩算法通过spark.io.compression.codec指定 |
0.9.0 |
| shuffle行为 | spark.shuffle.accurateBlockThreshold | 100 * 1024 * 1024 | 高于该阈值时,HighlyCompressedMapStatus中的混洗块的大小将被准确记录。通过避免在获取随机块时低估随机块的大小,有助于防止OOM | 2.2.1 |
| shuffle行为 | spark.shuffle.registration.timeout | 5000 | 注册到外部shuffle服务的超时时间 | 2.3.0 |
| shuffle行为 | spark.shuffle.registration.maxAttempts | 3 | 注册到外部shuffle服务的重试次数 | 2.3.0 |
| 压缩序列化 | spark.broadcast.compress | true | 是否压缩广播变量 | 0.6.0 |
| 压缩序列化 | spark.checkpoint.compress | false | 是否开启RDD压缩checkpoint | 2.2.0 |
| 压缩序列化 | spark.io.compression.codec | lz4 | RDD压缩方式org.apache.spark.io.LZ4CompressionCodec, org.apache.spark.io.LZFCompressionCodec, org.apache.spark.io.SnappyCompressionCodec, and org.apache.spark.io.ZStdCompressionCodec. |
0.8.0 |
| 压缩序列化 | spark.io.compression.lz4.blockSize | 32k | LZ4压缩中使用的块大小 | 1.4.0 |
| 压缩序列化 | spark.io.compression.snappy.blockSize | 32k | Snappy压缩中使用的块大小 | 1.4.0 |
| 压缩序列化 | spark.kryo.classesToRegister | None | 如果你用Kryo序列化,给定的用逗号分隔的自定义类名列表表示要注册的类 | 1.2.0 |
| 压缩序列化 | spark.kryo.registrator | None | 如果你用Kryo序列化,设置这个类去注册你的自定义类。如果你需要用自定义的方式注册你的类,那么这个属性是有用的。否则spark.kryo.classesToRegister会更简单。它应该设置一个继承自KryoRegistrator的类 |
0.5.0 |
| 压缩序列化 | spark.kryo.registrationRequired | false | 是否需要注册为Kyro可用 | 1.1.0 |
| 压缩序列化 | spark.kryoserializer.buffer.max | 64m | Kryo序列化缓存允许的最大值 | 1.4.0 |
| 压缩序列化 | spark.kryoserializer.buffer | 64k | Kyro序列化缓存的大小 | 1.4.0 |
| 压缩序列化 | spark.rdd.compress | False | 是否压缩序列化的RDD分区 | 0.6.0 |
| 压缩序列化 | spark.serializer | org.apache.spark.serializer. JavaSerializer |
序列化对象使用的类 | 0.5.0 |
| 压缩序列化 | spark.serializer.objectStreamReset | 100 | 当用org.apache.spark.serializer.JavaSerializer序列化时,序列化器通过缓存对象防止写多余的数据,然而这会造成这些对象的垃圾回收停止。通过请求’reset’,你从序列化器中flush这些信息并允许收集老的数据。为了关闭这个周期性的reset,你可以将值设为-1。默认情况下,每一百个对象reset一次 |
1.0.0 |
| 动态分配 | spark.dynamicAllocation.enabled | false | 是否开启动态分配 | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.executorIdleTimeout | 60s | 当某个executor空间超过该值时,则会remove掉该executor | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.cachedExecutorIdleTimeout | infinity | 当executor内有缓存数据并且空闲了该值后,则remove掉该executor | 1.4.0 |
| 动态分配 | spark.dynamicAllocation.initialExecutors | spark.dynamicAllocation.minExecutors | 初始executor数量,默认和executor数量一样 | 1.3.0 |
| 动态分配 | spark.dynamicAllocation.maxExecutors | infinity | executor上限,默认无限制 | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.minExecutors | 0 | executor下限,默认是0个 | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.executorAllocationRatio | 1 | 默认情况下,动态分配将要求足够的执行者根据要处理的任务数量最大化并行性。虽然这可以最大程度地减少作业的等待时间,但是对于小型任务,此设置可能会由于执行程序分配开销而浪费大量资源,因为某些执行程序甚至可能无法执行任何工作。此设置允许设置一个比率,该比率将用于减少执行程序的数量。完全并行。默认为1.0以提供最大的并行度。0.5将执行者的目标数量除以2由dynamicAllocation计算的执行者的目标数量仍然可以被spark.dynamicAllocation.minExecutors和spark.dynamicAllocation.maxExecutors设置覆盖 | 2.4.0 |
| 动态分配 | spark.dynamicAllocation.schedulerBacklogTimeout | 1s | 如果启用了动态分配,并且有待解决的任务积压的时间超过了此期限,则将请求新的执行者。 | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | schedulerBacklogTimeout | 与spark.dynamicAllocation.schedulerBacklogTimeout相同,但仅用于后续执行程序请求 | 1.2.0 |
| 动态分配 | spark.dynamicAllocation.shuffleTracking.enabled | false | 实验功能。为执行程序启用随机文件跟踪,从而无需外部随机服务即可动态分配。此选项将尝试保持为活动作业存储随机数据的执行程序 | 3.0.0 |
| 动态分配 | spark.dynamicAllocation.shuffleTracking.timeout | infinity | 启用随机跟踪时,控制保存随机数据的执行程序的超时。默认值意味着Spark将依靠垃圾回收中的shuffle来释放执行程序。如果由于某种原因垃圾回收无法足够快地清理随机数据,则此选项可用于控制执行者何时超时,即使它们正在存储随机数据。 | 3.0.0 |
--end--
扫描下方二维码
添加好友,备注【 交流 】 可私聊交流,也可进资源丰富学习群
以上是关于JVM调优的几种场景(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章