介绍一个非常好用的Python模块-pprint模块,相信你一定会爱上它的
Posted 小小程序员ol
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了介绍一个非常好用的Python模块-pprint模块,相信你一定会爱上它的相关的知识,希望对你有一定的参考价值。
一. pprint美观打印数据结构
pprint模块包含一个“美观打印机”,用于生成数据结构的一个美观的视图。格式化工具会生成数据结构的一些表示,不仅能够由解释器正确地解析,还便于人阅读。输出会尽可能放在一行上,分解为多行时会缩进。
1.打印
from pprint import pprint
data = [
(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\',
\'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'t\'\'u\', \'v\', \'x\', \'y\', \'z\']),
]
print(\'PRINT:\')
print(data)
print()
print(\'PPRINT:\')
pprint(data)
pprint()格式化一个对象,并把它作为参数传入一个数据流(或者是默认的sys.stdout)。
PRINT:
[(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}), (2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\', \'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}), (3, [\'m\', \'n\']), (4, [\'o\', \'p\', \'q\']), (5, [\'r\', \'s\', \'tu\', \'v\', \'x\', \'y\', \'z\'])]
PPRINT:
[(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2,
{\'e\': \'E\',
\'f\': \'F\',
\'g\': \'G\',
\'h\': \'H\',
\'i\': \'I\',
\'j\': \'J\',
\'k\': \'K\',
\'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'tu\', \'v\', \'x\', \'y\', \'z\'])]
2 .格式化
要格式化一个数据结构而不是把它直接写入一个流(即用于日志),可以使用pformat()来构建一个字符串表示。
import logging
from pprint import pformat
data = [
(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\',
\'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'t\'\'u\', \'v\', \'x\', \'y\', \'z\']),
]
logging.basicConfig(
level=logging.DEBUG,
format=\'%(levelname)-8s %(message)s\',
)
logging.debug(\'Logging pformatted data\')
formatted = pformat(data)
for line in formatted.splitlines():
logging.debug(line.rstrip())
然后可以单独打印这个格式化的字符串或者记入日志。
DEBUG Logging pformatted data
DEBUG [(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
DEBUG (2,
DEBUG {\'e\': \'E\',
DEBUG \'f\': \'F\',
DEBUG \'g\': \'G\',
DEBUG \'h\': \'H\',
DEBUG \'i\': \'I\',
DEBUG \'j\': \'J\',
DEBUG \'k\': \'K\',
DEBUG \'l\': \'L\'}),
DEBUG (3, [\'m\', \'n\']),
DEBUG (4, [\'o\', \'p\', \'q\']),
DEBUG (5, [\'r\', \'s\', \'tu\', \'v\', \'x\', \'y\', \'z\'])]
3. 任意类
如果一个定制类定义了一个__repr__()方法,那么pprint()使用的PrettyPrinter类还可以处理这样的定制类。
from pprint import pprint
class node:
def __init__(self, name, contents=[]):
self.name = name
self.contents = contents[:]
def __repr__(self):
return (
\'node(\' + repr(self.name) + \', \' +
repr(self.contents) + \')\'
)
trees = [
node(\'node-1\'),
node(\'node-2\', [node(\'node-2-1\')]),
node(\'node-3\', [node(\'node-3-1\')]),
]
pprint(trees)
利用由PrettyPrinter组合的嵌套对象的表示来返回完整的字符串表示。
[node(\'node-1\', []),
node(\'node-2\', [node(\'node-2-1\', [])]),
node(\'node-3\', [node(\'node-3-1\', [])])]
4. 递归
递归数据结构由指向原数据源的引用表示,形式为<Recursion on typename with id=number>
\'\'\'
学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
\'\'\'
from pprint import pprint
local_data = [\'a\', \'b\', 1, 2]
local_data.append(local_data)
print(\'id(local_data) =>\', id(local_data))
pprint(local_data)
在这个例子中,列表local_data增加到其自身,这会创建一个递归引用。
id(local_data) => 2763816527488
[\'a\', \'b\', 1, 2, <Recursion on list with id=2763816527488>]
5. 限制嵌套输出
对于非常深的数据结构,可能不要求输出中包含所有细节。数据有可能没有适当地格式化,也可能格式化文本过大而无法管理,或者有些数据可能是多余的。
from pprint import pprint
data = [
(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\',
\'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'t\'\'u\', \'v\', \'x\', \'y\', \'z\']),
]
pprint(data, depth=1)
pprint(data, depth=2)
使用depth参数可以控制美观打印机递归处理嵌套数据结构的深度。输出中未包含的层次用省略号表示。
[(...), (...), (...), (...), (...)]
[(1, {...}), (2, {...}), (3, [...]), (4, [...]), (5, [...])]
6.控制输出宽度
格式化文本的默认输出宽度为80列。要调整这个宽度,可以在pprint()中使用参数width。
from pprint import pprint
data = [
(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\',
\'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'t\'\'u\', \'v\', \'x\', \'y\', \'z\']),
]
for width in [80, 5]:
print(\'WIDTH =\', width)
pprint(data, width=width)
print()
当宽度太小而不能满足格式化数据结构时,倘若截断或转行会导致非法语法,那么便不会截断或转行。
WIDTH = 80
[(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2,
{\'e\': \'E\',
\'f\': \'F\',
\'g\': \'G\',
\'h\': \'H\',
\'i\': \'I\',
\'j\': \'J\',
\'k\': \'K\',
\'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'tu\', \'v\', \'x\', \'y\', \'z\'])]
WIDTH = 5
[(1,
{\'a\': \'A\',
\'b\': \'B\',
\'c\': \'C\',
\'d\': \'D\'}),
(2,
{\'e\': \'E\',
\'f\': \'F\',
\'g\': \'G\',
\'h\': \'H\',
\'i\': \'I\',
\'j\': \'J\',
\'k\': \'K\',
\'l\': \'L\'}),
(3,
[\'m\',
\'n\']),
(4,
[\'o\',
\'p\',
\'q\']),
(5,
[\'r\',
\'s\',
\'tu\',
\'v\',
\'x\',
\'y\',
\'z\'])]
compact标志告诉pprint()尝试在每一行上放置更多数据,而不是把复杂数据结构分解为多行。
from pprint import pprint
data = [
(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2, {\'e\': \'E\', \'f\': \'F\', \'g\': \'G\', \'h\': \'H\',
\'i\': \'I\', \'j\': \'J\', \'k\': \'K\', \'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'t\'\'u\', \'v\', \'x\', \'y\', \'z\']),
]
for width in [80, 5]:
print(\'WIDTH =\', width)
pprint(data, width=width)
print()
这个例子展示了一个数据结构再一行上放不下时,它会分解(数据列表中的第二项也是如此)。如果多个元素可以放置在一行上(如第三个和第四个成员),那么便会把它们放在同一行上。
WIDTH = 80
[(1, {\'a\': \'A\', \'b\': \'B\', \'c\': \'C\', \'d\': \'D\'}),
(2,
{\'e\': \'E\',
\'f\': \'F\',
\'g\': \'G\',
\'h\': \'H\',
\'i\': \'I\',
\'j\': \'J\',
\'k\': \'K\',
\'l\': \'L\'}),
(3, [\'m\', \'n\']),
(4, [\'o\', \'p\', \'q\']),
(5, [\'r\', \'s\', \'tu\', \'v\', \'x\', \'y\', \'z\'])]
WIDTH = 5
[(1,
{\'a\': \'A\',
\'b\': \'B\',
\'c\': \'C\',
\'d\': \'D\'}),
(2,
{\'e\': \'E\',
\'f\': \'F\',
\'g\': \'G\',
\'h\': \'H\',
\'i\': \'I\',
\'j\': \'J\',
\'k\': \'K\',
\'l\': \'L\'}),
(3,
[\'m\',
\'n\']),
(4,
[\'o\',
\'p\',
\'q\']),
(5,
[\'r\',
\'s\',
\'tu\',
\'v\',
\'x\',
\'y\',
\'z\'])]
结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!
Python pprint | 超级好用的Python库,漂亮的打印,让json数据提取体验更好
文章目录
一、简介
在实践 P y t h o n Python Python 爬虫的时候,大家肯定碰到过返回的结果是json字符串格式的数据。
关于 json 数据的详解可以学习如下文章:
对于这种数据可以利用 json 模块将 json 字符串直接转化为字典格式的数据,字典为 key:value 型,之后再对应提取我们想要的字段。
但是存在一个问题:
往往网页获取到的 json 数据转化为字典后,嵌套太多,看起来一团糟的感觉,很难一下观察到哪个 key 对应那个value。
本文主要介绍一个超级好用的 Python 库: p p r i n t pprint pprint,它可以格式化打印字典数据,让对应关系更加清晰直观,算是一个实用的爬虫技巧。快学起来!
二、实践案例
下面我们以根据地理名称爬取高德地图地理位置信息为例,展现 p p r i n t pprint pprint 的妙用:
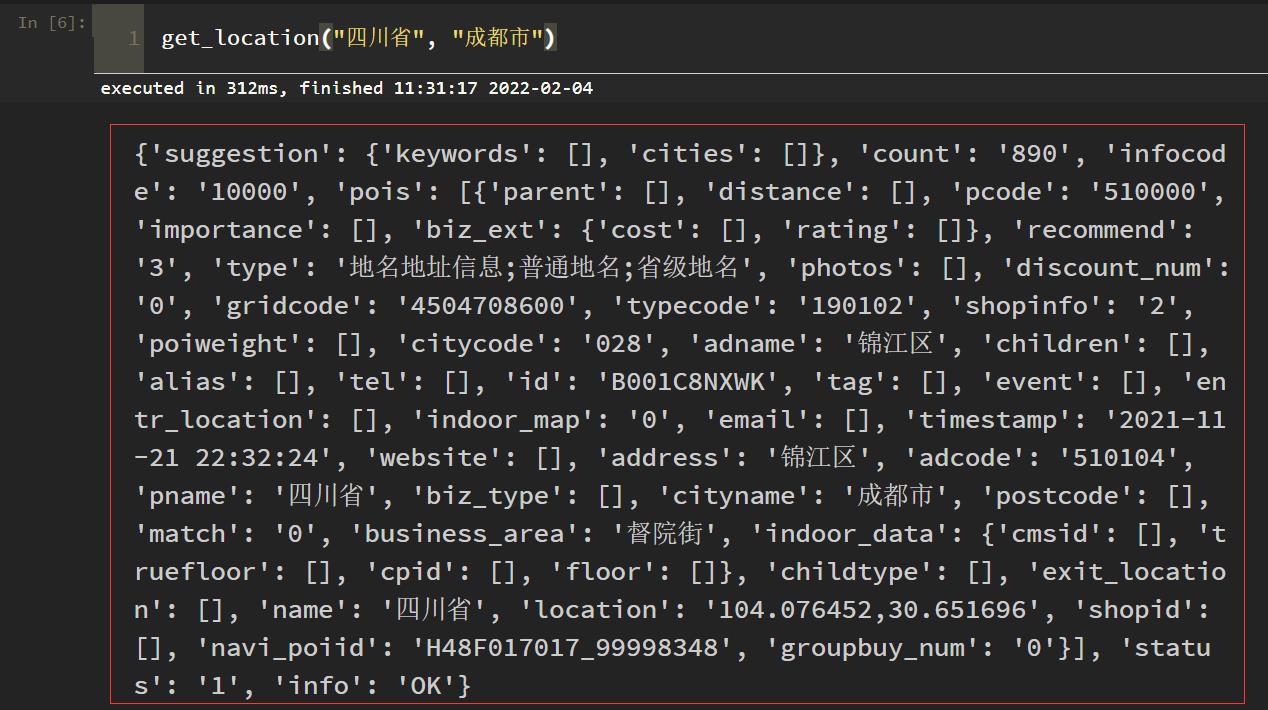
我们利用 json.loads(data.text) 方法,直接将 json 字符串,转换为了字典格式的数据。一看数据,一大堆东西,我们该怎么解析想要的字段?
pprint模块的妙用:我们期望有一种方法能够快速帮助我们理清字典嵌套和key:value对应的关系。
pprint是 Python 第三方库,在使用之前,需要先 pip 安装上。
pip install pprint -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
安装后,可以直接导入使用。
from pprint import pprint
接着,对于上述案例,现在我们使用 pprint() 函数,打印一下,看看会有什么好的效果呢?如下所示:
从图中可以看到,这个字典嵌套和 key:value 对应关系,一目了然,清晰美观,这样之后的解析提取数据就很容易了!源码如下:
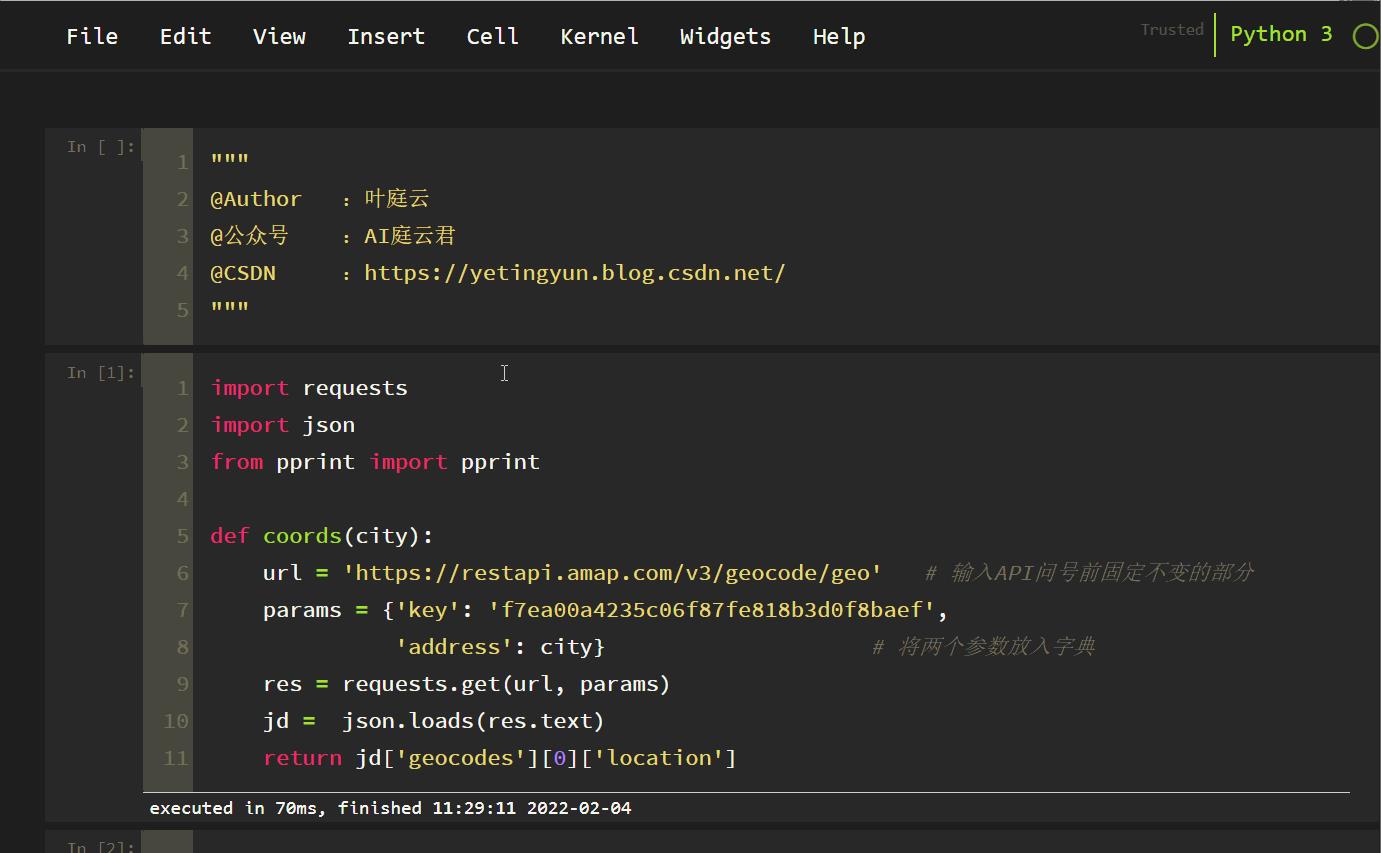
import requests
import json
from pprint import pprint
def coords(city):
url = 'https://restapi.amap.com/v3/geocode/geo' # 输入API问号前固定不变的部分
params = 'key': '注意:换成你的高德地图的API应用的key',
'address': city # 将两个参数放入字典
res = requests.get(url, params)
jd = json.loads(res.text)
return jd['geocodes'][0]['location']
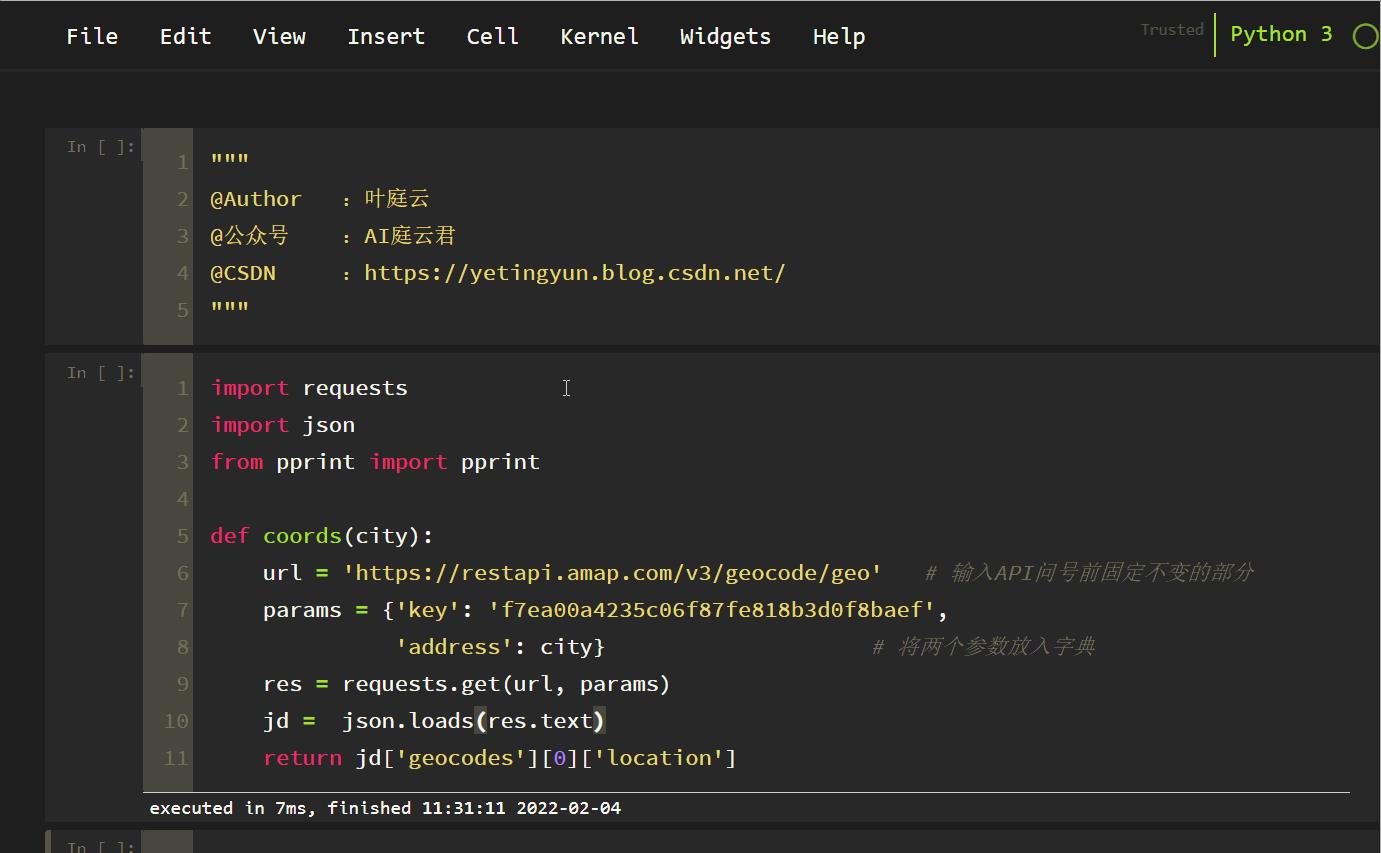
def get_location(keyword, city):
# 获得经纬度
keynum = "注意:换成你的高德地图的API应用的key"
user_agent = 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
headers = 'User-Agent': user_agent
url = 'http://restapi.amap.com/v3/place/text?key=' + keynum + '&keywords=' + keyword + '&types=&city=' + city + '&children=1&offset=1&page=1&extensions=all'
data = requests.get(url, headers=headers)
data.encoding = 'utf-8'
data = json.loads(data.text)
pprint(data)
result = data['pois'][0]['location'].split(',')
return result[0], result[1]
print(":".join(["CSDN叶庭云", "https://yetingyun.blog.csdn.net/"]))
get_location("四川省", "成都市")
下面再用一个简单的案例,带大家感受一下。
dic = "status":"1","info":"OK","infocode":"10000",
"count":"1",
"geocodes":["formatted_address":"上海市","country":"中国","province":"上海市","citycode":"021","city":"上海市","district":[],"township":[],"neighborhood":"name":[],"type":[],"building":"name":[],"type":[],"adcode":"310000","street":[],"number":[],"location":"121.473701,31.230416","level":"省"]
有这样一个嵌套字典,是关于上海市的地理位置信息的,如果想要获标签 location 对应的经纬度数据,我们应该这样做:
pprint(dic)
结果如下:
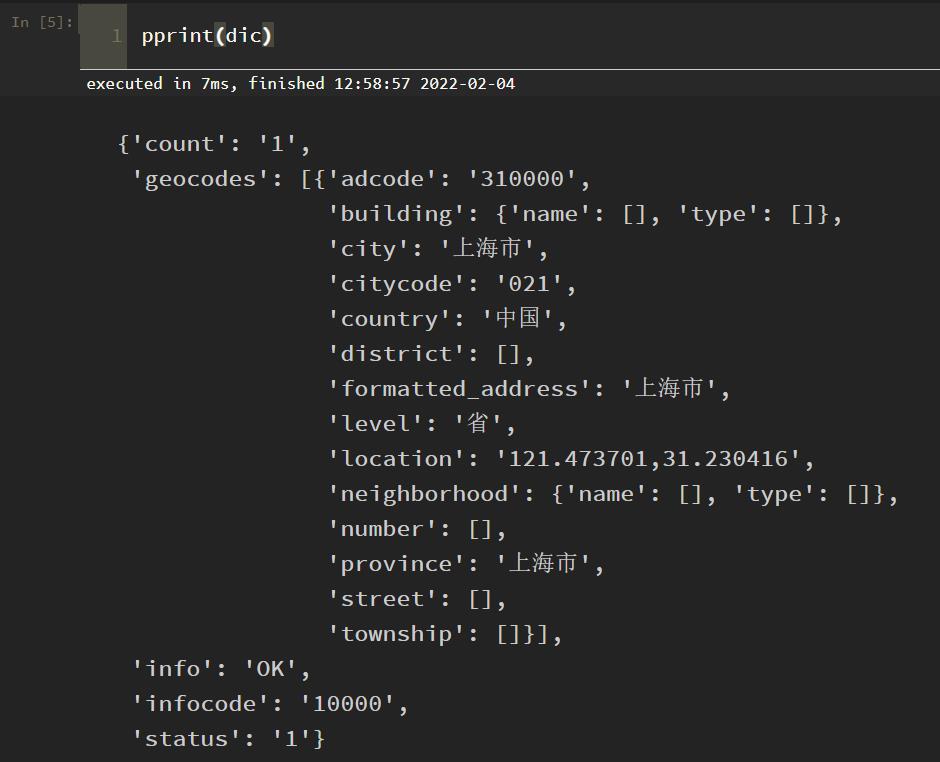
对于上面这个数据,大家应该看一眼就知道怎么提取经纬度数据,代码如下所示:
data = dic["geocodes"][0]["location"]
longitude, latitude = data.split(",")
print(data)
print("经度:", longitude)
print("纬度:", latitude)
结果如下:
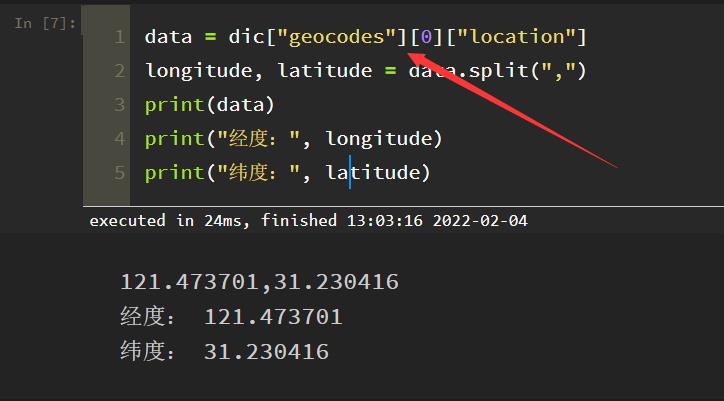
网页源代码返回的 json 数据,基本都是类似的,只要你搞清楚了它的结构关系,后面 for 循环遍历提取对应的数据就好。
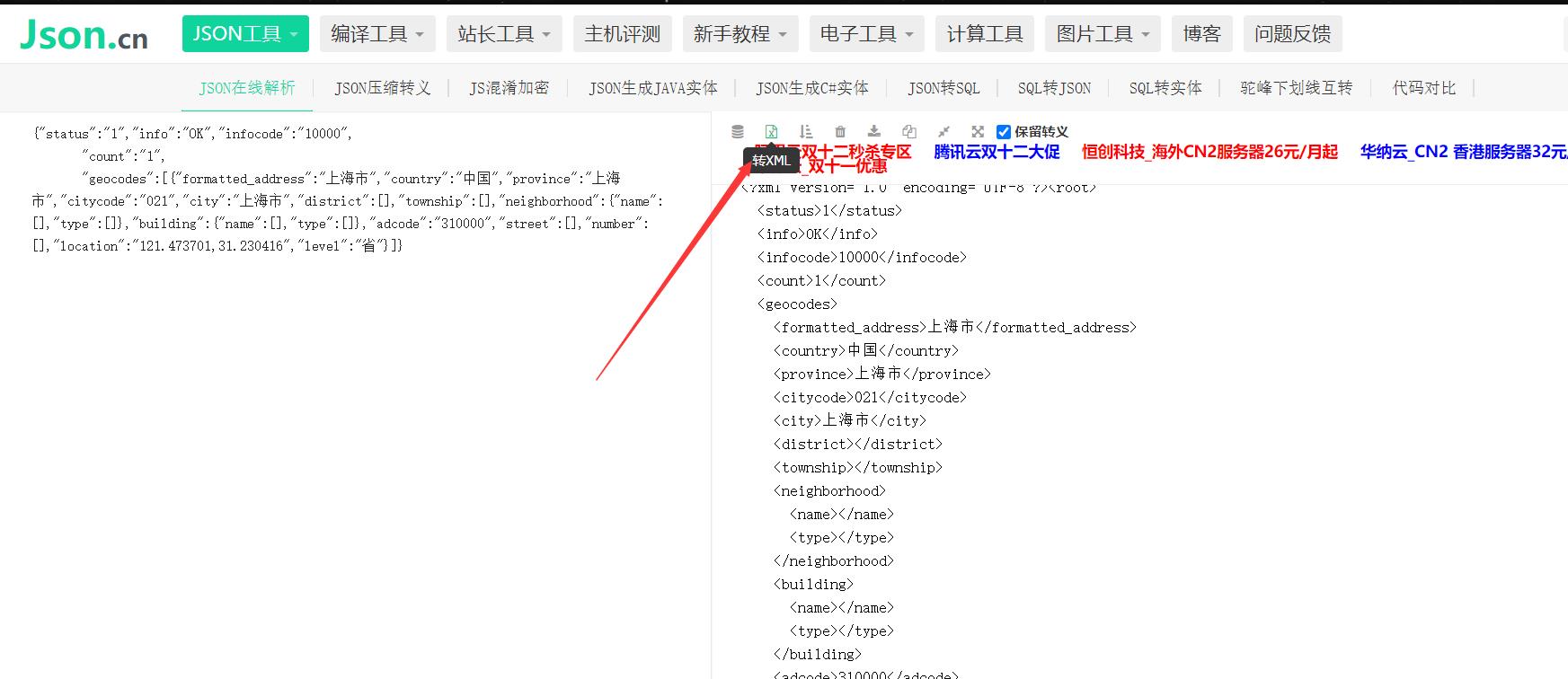
也有大佬做了 JSON 数据在线解析和格式化、以及转 XML 的在线网页,如下所示:
三、总结

以上是关于介绍一个非常好用的Python模块-pprint模块,相信你一定会爱上它的的主要内容,如果未能解决你的问题,请参考以下文章