神经网络性能提升两倍,英特尔®深度学习加速技术和oneAPI推动大型强子对撞机研究
Posted FPGA创新中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络性能提升两倍,英特尔®深度学习加速技术和oneAPI推动大型强子对撞机研究相关的知识,希望对你有一定的参考价值。


为了帮助满足全球最大的粒子加速器CERN的LHC(大型强子对撞机)的未来需求,CERN,SURFsara和英特尔的研究人员一直在研究提供全新高水平仿真的方法。
Reinders 写到,CERN 研究人员“业已证明在不影响准确度的情况下,通过降低精度,成功将推理速度提升了近两倍。”此项工作是英特尔通过 CERN openlab 与 CERN 长期合作的一部分。
CERN 研究人员发现,在名为“生成式对抗网络 (GAN)”的特定神经网络 (NN) 中,约一半的计算可以从 FP32 切换至 INT8 数值精度,英特尔® 深度学习加速技术可以在不影响准确度的情况下直接支持这种切换。最终,GAN 性能提升了两倍,且准确度丝毫不受影响。虽然这项工作由直接支持 INT8 的英特尔® 至强® 可扩展处理器完成,但 Reinders 还在文章中提出了下一个逻辑跳跃:
“INT 8 的广泛支持得益于英特尔至强可扩展处理器,英特尔® Xe GPU 也支持 INT 8。FPGA 支持 INT8 和其他较低的精度格式。”
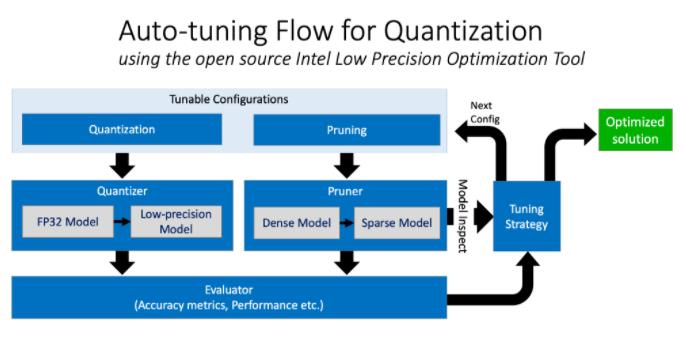
通过完全控制精度权衡来实现量化,从而为推理带来了显着的性能提升
此外,Reinders 还表示:
“执行并大幅改进此项工作的秘密武器是,oneAPI 支持轻松访问英特尔深度学习加速和其他加速技术,无需将应用锁定到单个厂商或设备中。”

值得一提的是,oneAPI 如何让此类工作更具价值。所用工具的关键部分,包括 TensorFlow 和 Python 中隐藏的加速,都利用了支持 oneAPI 的库。这意味着,它们是公开的,可随时用于异构系统,不只针对于一家厂商或一种产品(比如 GPU)。
oneAPI 是跨行业、开放式、基于标准的统一编程模型,可在所有加速器架构中提供统一的开发体验。英特尔帮助创建了 oneAPI,并为其提供各种开源编译器、库和其他工具的支持。编程后通过 oneAPI 使用 INT8,这样文章所述的 CERN 执行的此类工作可以使用英特尔 Xe GPU、FPGA 或其他支持 INT8 或其他数值格式(可以量化)的设备来完成。
实际性能受使用情况、配置和其他因素的差异影响。更多信息请见 www.Intel.com/PerformanceIndex。
英特尔不对第三方数据承担任何控制或审计的责任。请您审查该内容,咨询其他来源,并确认提及数据是否准确。
性能结果基于配置信息中显示的日期进行测试,且可能并未反映所有公开可用的安全更新。配置详情请见备用页。没有任何产品或组件是绝对安全的。
具体成本和结果可能不同。
英特尔技术可能需要启用硬件、软件或激活服务。
© 英特尔公司版权所有。英特尔、英特尔标识和其他英特尔标志是英特尔公司或其子公司在美国和/或其他国家(地区)的商标。文中涉及的其它名称及商标属于各自所有者资产。
内容来自英特尔FPGA。


点分享

点收藏
点点赞
点在看
以上是关于神经网络性能提升两倍,英特尔®深度学习加速技术和oneAPI推动大型强子对撞机研究的主要内容,如果未能解决你的问题,请参考以下文章
打破深度学习局限,强化学习深度森林或是企业AI决策技术的“良药”
基于英特尔® 至强 E5 系列处理器的单节点 Caffe 评分和训练