pytorch加载数据集
Posted 编程coding小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch加载数据集相关的知识,希望对你有一定的参考价值。
DataLoader 和 Dataset
构建模型的基本方法,我们了解了。
接下来,我们就要弄明白怎么对数据进行预处理,然后加载数据,我们以前手动加载数据的方式,在数据量小的时候,并没有太大问题,但是到了大数据量,我们需要使用 shuffle, 分割成mini-batch 等操作的时候,我们可以使用PyTorch的API快速地完成这些操作。

Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
DataLoader是一个比较重要的类,它为我们提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
现在,我们先展示直接使用 TensorDataset 来将数据包装成Dataset类
接下来,我们来继承 Dataset类 ,写一个将数据处理成DataLoader的类。
当我们集成了一个 Dataset类之后,我们需要重写 len 方法,该方法提供了dataset的大小; getitem 方法, 该方法支持从 0 到 len(self)的索引
class DealDataset(Dataset):
"""
下载数据、初始化数据,都可以在这里完成
"""
def __init__(self):
xy = np.loadtxt(\'../dataSet/diabetes.csv.gz\', delimiter=\',\', dtype=np.float32) # 使用numpy读取数据
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 实例化这个类,然后我们就得到了Dataset类型的数据,记下来就将这个类传给DataLoader,就可以了。
dealDataset = DealDataset()
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=32,
shuffle=True)
for epoch in range(2):
for i, data in enumerate(train_loader2):
# 将数据从 train_loader 中读出来,一次读取的样本数是32个
inputs, labels = data
# 将这些数据转换成Variable类型
inputs, labels = Variable(inputs), Variable(labels)
# 接下来就是跑模型的环节了,我们这里使用print来代替
print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())
————————————————
版权声明:本文为CSDN博主「嘿芝麻」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zw__chen/article/details/82806900
本文来自博客园,作者:编程coding小白,转载请注明原文链接:https://www.cnblogs.com/zhenhua1203/p/15527414.html
PyTorch学习笔记 3.数据集和数据加载器
PyTorch学习笔记 3.数据集和数据加载器
一、说明
PyTorch提供了一些公共数据集,如FashionMNIST,可以在torch.utils.data.Dataset库里找到这些库。
准备环境 :
- python3
- pytorch
- pandas
- matplotlib
本文使用conda环境,安装pandas的命令:
conda install pandas
本文重点用到 DataSet和DataLoader。通俗地讲,DataSet是数据集,
DataLoader负责从DataSet里分批取数据。
二、使用PyTorch预置数据集
1. 预置数据集FashionMNIST介绍
以FashionMNIST为例。FashionMNIST是Zalando文章图片的数据集,包括6万个培训训练数据和1万个测试数据。每个示例是28*28的灰度图像,标签集是10个分类。
使用FashionMNIST时要设置参数:
- root
- train
- downloa=True , 表示从互联网下载数据
- transform:数据处理功能
2. 加载数据集
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
运行结果:
这里有个报警,大意是给的NumPy数组不能写。暂且忽略。
3. 对数据集处理和可视化
手工建立10个分类:
labels_map =
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
然后显示图形(灰度图):
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
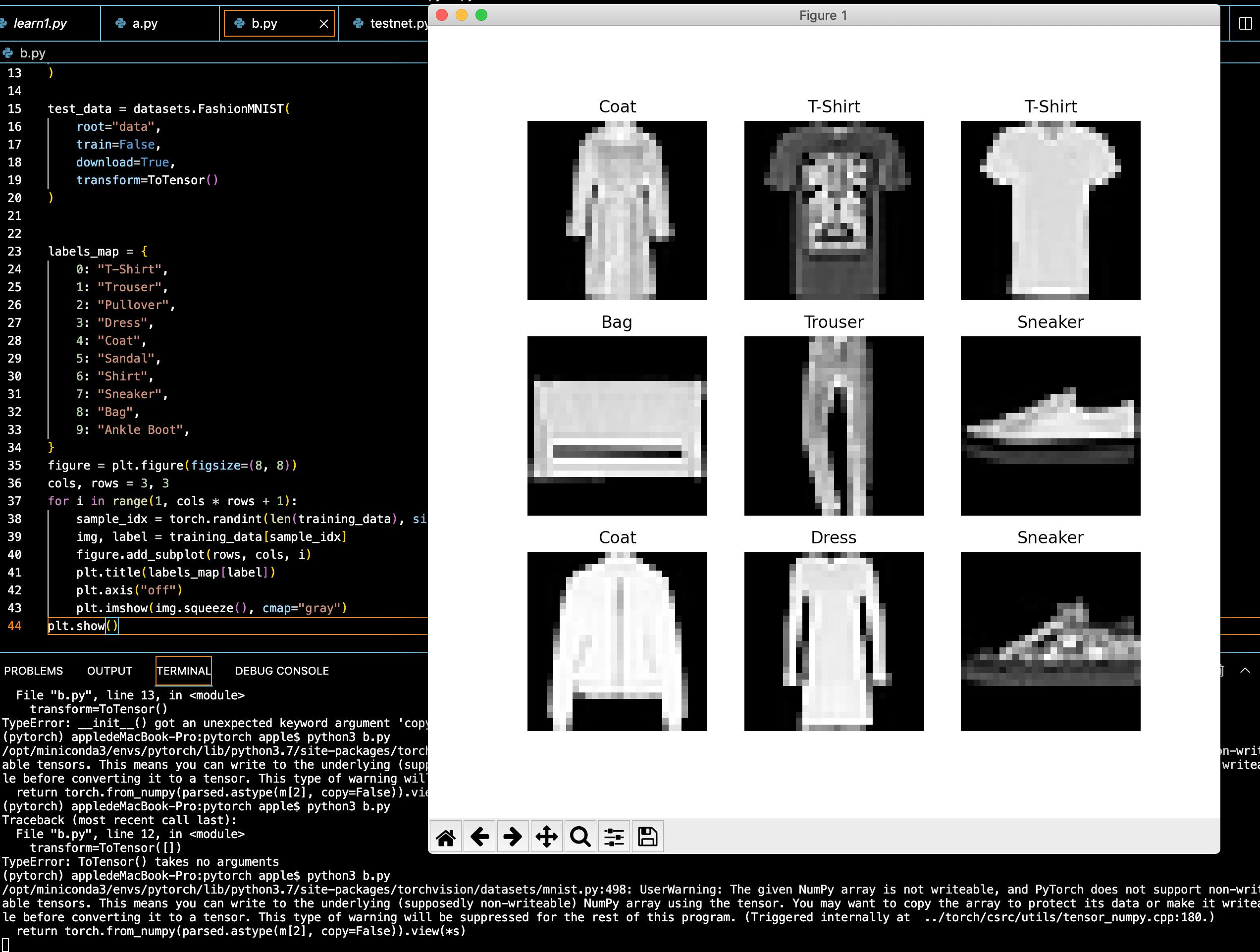
完整代码:
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
labels_map =
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
三、自定义数据集
1. 要实现的方法
自定义数据集需要实现三个方法:
__init____len____getitem__
2. 定义
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
3. __init__
类的初始化执行函数,这里读入标签、传入图片文件夹、传入两种转换的目录。
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
4. __len
__len__返回数据集中样本数量。
def __len__(self):
return len(self.img_labels)
5. __getitem__
在给定索引上加载并返回数据集中的示例。基于该索引,它识别图像文件位置、转为张量、从csv检索标签,调用适用的转换功能。
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
6. 准备数据、训练
这个步骤是检索数据集,一次标记一个示例。在训练时,数据集会分块处理,DataLoader从dataset里分匹取数据集。这里每次返回一批是64个样本,分别包含了训练的特征和标签。
这里指定了shuffle=True,在遍历完后,会将数据打乱。
由于我这里没有自己真实的数据集,所以数据仍使用上面定义的Fashion_MNIST数据集。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
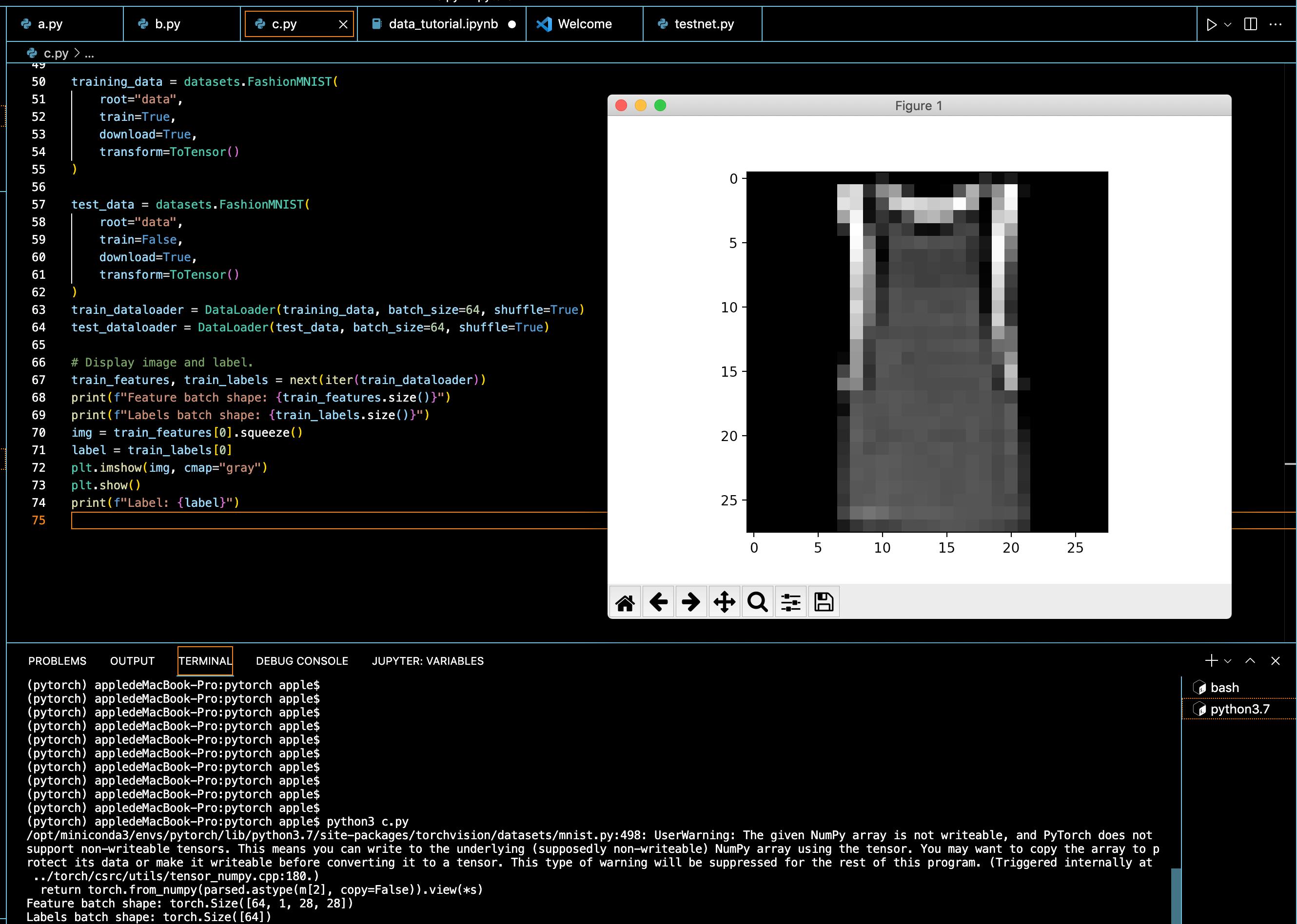
7. 通过数据加载器传入数据
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: train_features.size()")
print(f"Labels batch shape: train_labels.size()")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: label")
运行情况:
以上是关于pytorch加载数据集的主要内容,如果未能解决你的问题,请参考以下文章