能够Awk何必Spark
Posted 早起的码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了能够Awk何必Spark相关的知识,希望对你有一定的参考价值。
大数据近些年算是比较火,好多程序员可能为了学习技术,一个简单数据量很少的数据处理也要写个spark程序去集群上跑一跑。这样反而打包,发布,跑任务,拉结果工作效率极低。这就属于杀鸡用牛刀。
试想一下,一个几十M的日志文本文件,几千几万行记录,真的有必要传到集群上一顿折腾吗?不妨让我们用最简单的工具来轻松快速的处理需求,这样不香吗?
可能有的程序员要说了,我本地处理也需要写代码编译,执行,其实效率也不高,那我今天给你介绍一款linux工具--AWK.可能你听过,但你大概率没有深入应用。记得10年前我们的数据分析系统就是用shell和awk完成的数据统计工作。当然那时候数据量也不大,linux单机服务器可以处理的过来。
一 Awk的基本用法
awk [-F‘,’] [-v a=b] ‘BEGIN{}{}END{}’ a.txt
awk -f run.awk a.txt
二 Awk命令的几个内置变量
NR,表示awk开始执行程序后所读取的数据行数.
FNR,与NR功用类似,不同的是awk每打开一个新文件,FNR便从0重新累计
NF,字段总数
RS, 记录结束分隔符,默认分隔符为
ORS,记录输出分隔符,默认为
OFS,列字段输出分隔
FS, 字段分隔符相当于-F
RT, 指定的那个分隔符
FILENAME,读取文件名
三 Awk内置函数
split(string, array, field separator) 切分
substr(s,p,n) 截取
length(val)求长度
gsub(r,s,t):函数则使得在所有正则表达式被匹配的时候都发生替换。
tolower(String ) 转化小写
int(x ) 返回 x的截断至整数的值,求整
…较新版本,自定义函数
function 函数名(参数表){
函数体 }
四 Awk数据分析
1.分组求和
样例数据:data.txt
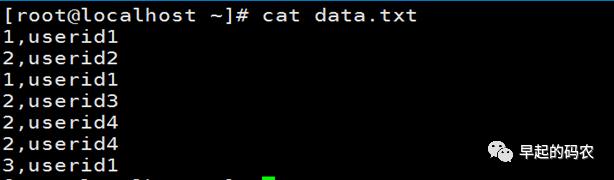
awk -F',' '{if ($1 in rs){rs[$1] += 1 } else{rs[$1]=1}}END{for (x in rs)
{print x,rs[x]}}'data.txt

2.分组排重1
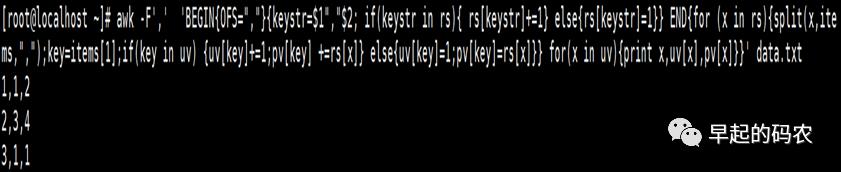
awk -F',' 'BEGIN{OFS=","}{keystr=$1","$2; if(keystrin rs){ rs[keystr]+=1}
else{rs[keystr]=1}}END{for (x in rs){split(x,items,",");key=items[1];
if(key in uv){uv[key]+=1;pv[key] +=rs[x]}else{uv[key]=1;pv[key]=rs[x]}}
for(x in uv){print x,uv[x],pv[x]}}' data.txt
3.分组排重2
awk -F',' '{keystr=$1" "$2;if(keystr in rs){ rs[keystr]+=1}
else{rs[keystr]=1}}END{for (x in rs) {print x,rs[x]}}'data.txt
|awk 'BEGIN{OFS=","}{if($1 in uv) {uv[$1]+=1;pv[$1] +=$3} else{uv[$1]=1;pv[$1]=$3}}END{for(xin uv){print x,uv[x],pv[x]}}'
、
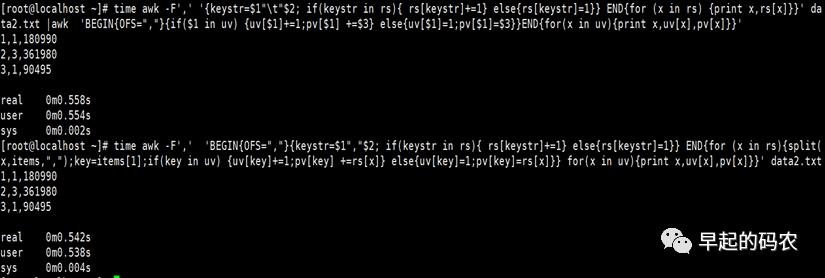
效率比较
生成文件data2.txt
633465行大小6.1M 0.5秒内完成,两种排重方法效率相当
4.数据关联
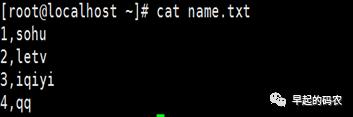
样例数据:name.txt
5.数据求和
求出现数字之和
awk -v RS='[0-9]+' '{s+=RT}END{print s}'data.txt
6.排序
五 其他linux工具
此外Linux还有好多很实用的数据处理小工具,可以自己研究
join
comm
diff
sed
sort
grep
cut
以上是关于能够Awk何必Spark的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段