用python帮别人写了个文字识别程序
Posted python可乐编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python帮别人写了个文字识别程序相关的知识,希望对你有一定的参考价值。
文章目录
- 前言
- 一.需求分析
- 二.代码实现
- 1.百度文字识别
- 2.查看文档获取access_token
- 3.图片代码
- 4.代码部分解读
- 三.效果展示
很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。 很多已经做案例的人,却不知道如何去学习更加高深的知识。 那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码! QQ群:861355058 欢迎加入,一起讨论 一起学习!
前言
就在前几天一个大一学妹打破了我繁忙的生活,我纳闷了,直接问她啥事啊(老直男了)
原来是找我帮个忙,作为好学长那肯定得助人为乐啊…
话不多说,进入正题
一.需求分析
根据学妹的描述来看,就只是想要一个能识别图片文字的程序,那就不管啥排版了,直接依次识别算了,主要是忙…那我直接用百度的ocr就行了,半小时搞定它!
二.代码实现
1.百度文字识别
文字识别官方入口
https://ai.baidu.com/tech/ocr/general

点击立即使用,我们就白嫖吧,反正一个月也用不到1000次
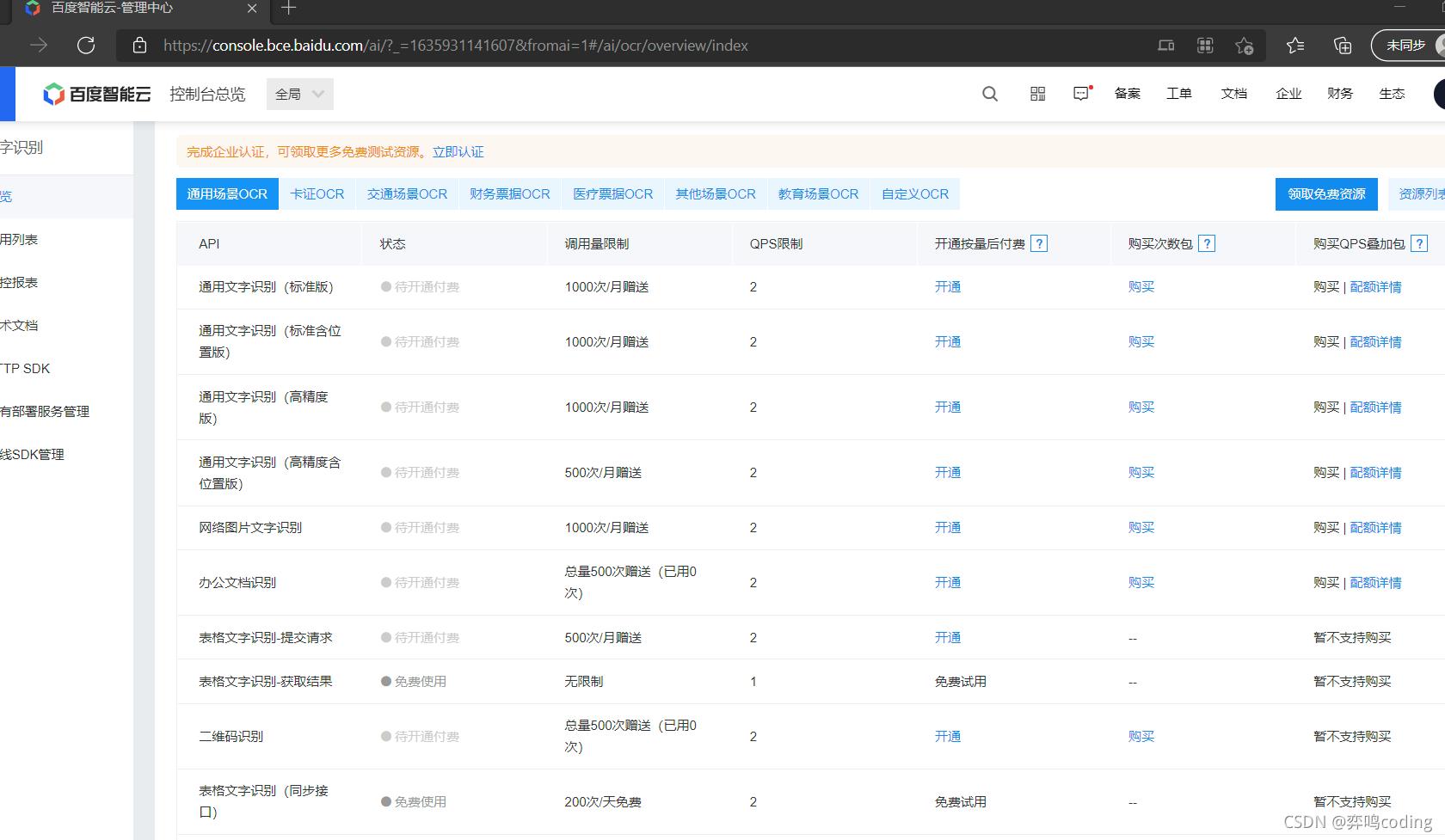
创建应用,输入应用名称,这个随意哈,然后选一个文字识别-免费的,有钱的话当我没说。
下图创建成功。
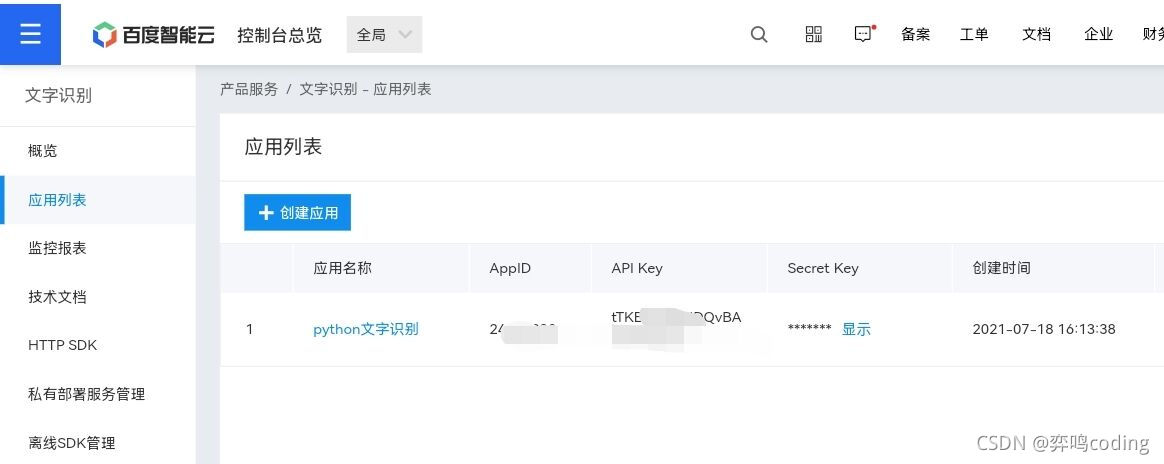
一会API Key和Secret Key是要使用的。
2.查看文档获取access_token
接下来就要去看看文档了,看是怎么使用的
https://ai.baidu.com/ai-doc/OCR/1k3h7y3db
不会看文档的小伙伴,我直接就讲我需要的东西了,其余的大家自己学着看吧。
从文档来看,我们首先要获取一个东西——access_token
官网代码
# encoding:utf-8 import requests # client_id 为官网获取的AK, client_secret 为官网获取的SK host = \'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】\' response = requests.get(host) if response: print(response.json()) 我的代码 import requests def access_token(): url = \'https://aip.baidubce.com/oauth/2.0/token\' token_ = { \'grant_type\': \'client_credentials\', # API Key \'client_id\': \'官网获取的AK\', # ecret Key \'client_secret\': \'官网获取的SK\' } res = requests.post(url, data=token_) res = res.json() print(res) access_token = res[\'access_token\'] print(access_token) return access_token if __name__ == \'__main__\': access_token()
官网说推荐使用post,那我们就用post,但是官方代码是用的get这种方法,其实结果都一样,都能得到需要的数据。只不过官方的代码还需要一步提取出access_token。
access_token = response.json()[\'access_token\']

然后就能得到access_token了。

如果在这个过程中遇到错误,文档也有,而且会比我讲的详细,所以遇到问题的话可以先看文档,实在不行可以问我。
获取access_token的函数
def access_token(): url = \'https://aip.baidubce.com/oauth/2.0/token\' token_ = { \'grant_type\': \'client_credentials\', # API Key \'client_id\': \'自己获取\', # ecret Key \'client_secret\': \'自己获取\' } res = requests.post(url, data=token_) res = res.json() print(res) access_token = res[\'access_token\'] print(access_token) return access_token
当我们需要用时直接调用就行了。

根据文档的说明,我们就开始写读取图片的代码了
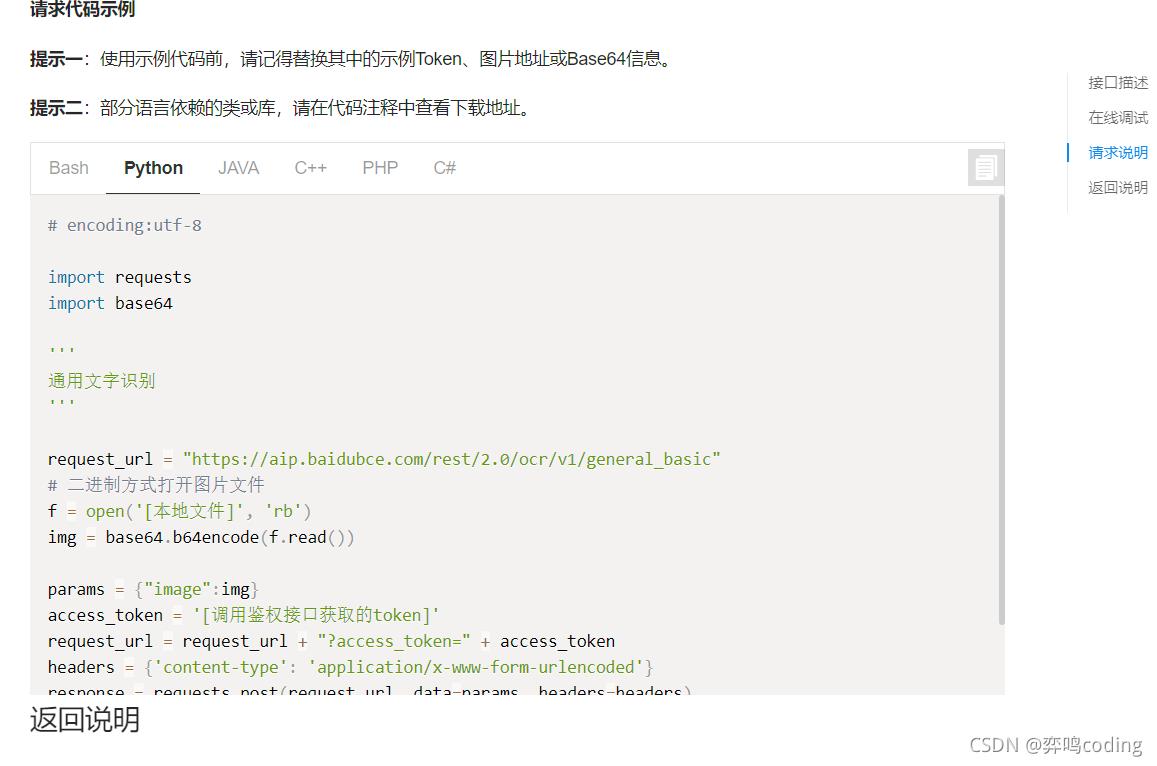
3.图片代码
def raed_pic(): url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate" request_url = url + "?access_token=" + access_token() f = open(\'6.jpg\', \'rb\') img = base64.b64encode(f.read()) # 参数看文档 params = {"image": img, "language_type": "CHN_ENG", "recognize_granularity": "small", } headers = {\'content-type\': \'application/x-www-form-urlencoded\'} response = requests.post(request_url, data=params, headers=headers) # print(response) # res = response.json() # print(res) # 判断是否响应成功 if response: # 保存读出文字的文件,自动创建 file_name = "yiming6.txt" # 这个没说的了,就是写入操作 with open(file_name, \'w\', encoding=\'utf-8\') as f: for j in res: f.write(j["words"] + "\\n")
4.代码部分解读
从json分析来看我们只要提取当中的words_result里面的words

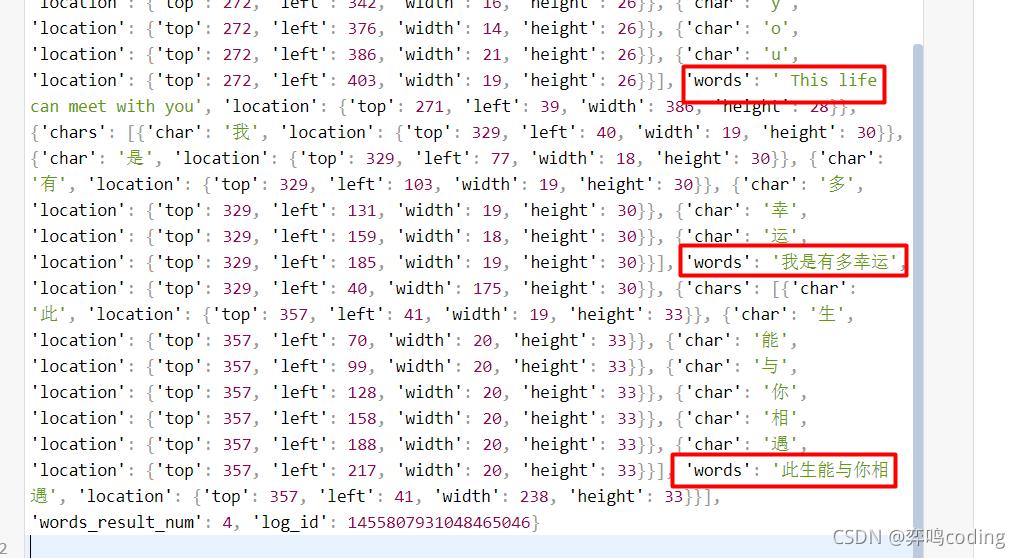
三.效果展示
效果如下:
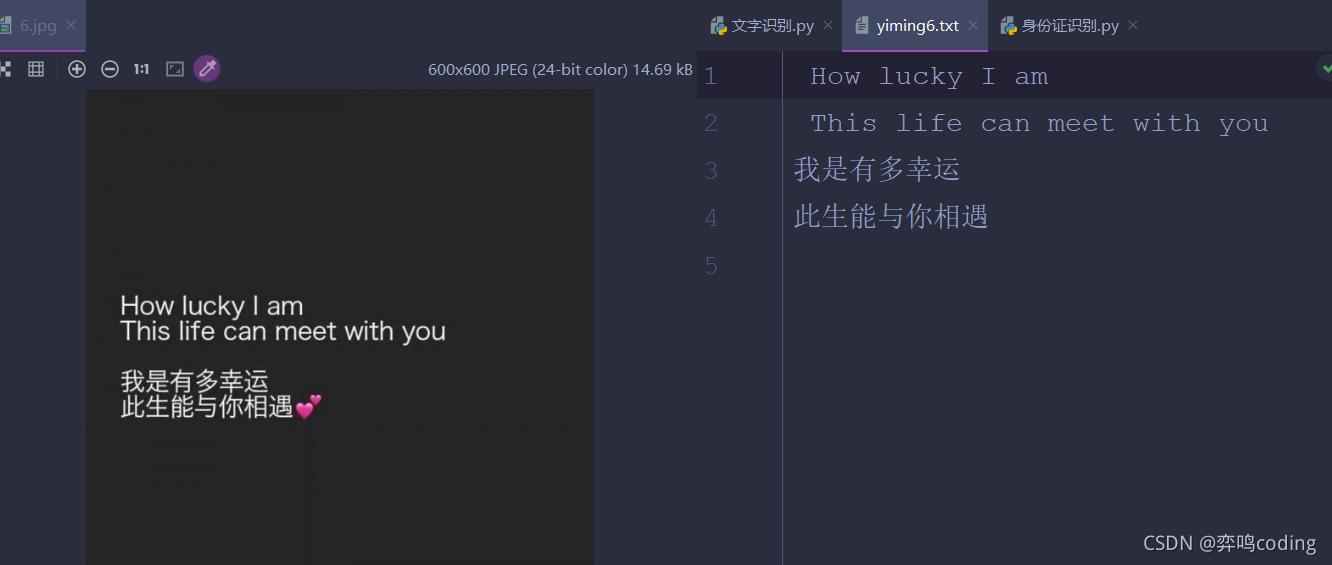
nice!当然可以写个循环然后直接遍历一个文件夹里面的所有图片,就可以得到每张图的文字了,再读取里面的文字放在同一个txt文件里面,有闲工夫的小伙伴可以试一试,我就不写了。最后也成功得到学妹的奶茶,就不上图片了,嘻嘻嘻~
用Python写了一个图像文字识别OCR工具

导读:人生苦短,快学Python!今天我们直接写一个图像文字识别OCR工具!
作者:虾米小馄饨
来源:快学Python(ID:kxpython)
最近在技术交流群里聊到一个关于图像文字识别的需求,在工作、生活中常常会用到,比如票据、漫画、扫描件、照片的文本提取。
博主基于 PyQt + labelme + PaddleOCR 写了一个桌面端的OCR工具,用于快速实现图片中文本区域自动检测+文本自动识别。
识别效果如下图所示:
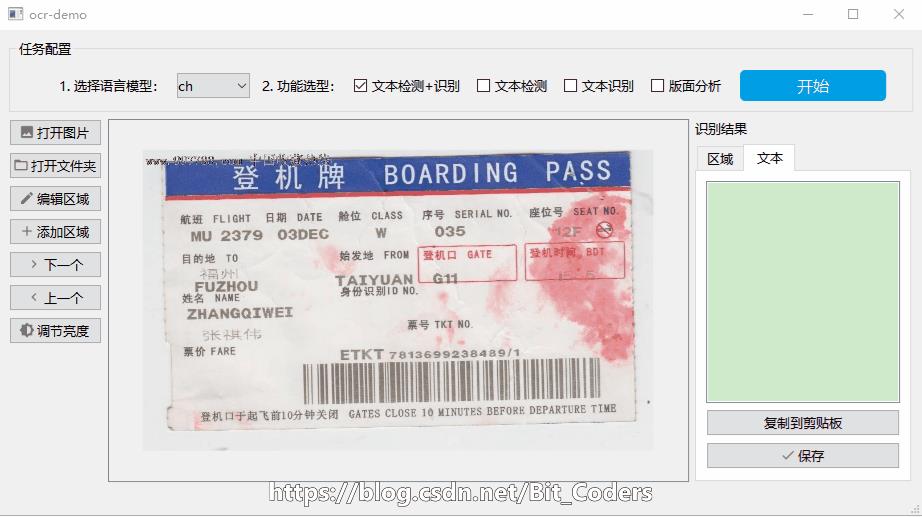
▲OCR工具识别效果
所有框选区域为OCR算法自动检测,右侧列表有每个框对应的文字内容;点击右侧“识别结果”中的文本记录,然后点击“复制到剪贴板”即可复制该文本内容。
功能列表
文本区域检测+文字识别
文本区域可视化
文字内容列表
图像、文件夹加载
图像滚轮缩放查看
绘制区域、编辑区域
复制所选文本识别结果
01 OCR部分
图像文字检测+文字识别算法,主要借助 paddleocr 实现。
创建或者选择一个虚拟环境,安装需要用到的第三方库。
conda create -n ocr
conda activate ocr1. 安装框架
如果你没有NVIDIA GPU,或GPU不支持CUDA,可以安装CPU版本:
# CPU版本
pip install paddlepaddle==2.1.0 -i https://mirror.baidu.com/pypi/simple如果你的GPU安装过CUDA9或CUDA10,cuDNN 7.6+,可以选择下面这个GPU版本:
# GPU版本
python3 -m pip install paddlepaddle-gpu==2.1.0 -i https://mirror.baidu.com/pypi/simple2. 安装 PaddleOCR
安装paddleocr:
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本版面分析,需要安装 Layout-Parser:
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl3. 测试安装是否成功
安装完成后,测试一张图片--image_dir ./imgs/11.jpg,采用中英文检测+方向分类器+识别全流程:
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false输出一个list:

4. 在Python中调用
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)输出结果是一个list,每个item包含了文本框,文字和识别置信度:
[[[24.0, 36.0], [304.0, 34.0], [304.0, 72.0], [24.0, 74.0]], ['纯臻营养护发素', 0.964739]] [[[24.0, 80.0], [172.0, 80.0], [172.0, 104.0], [24.0, 104.0]], ['产品信息/参数', 0.98069626]] [[[24.0, 109.0], [333.0, 109.0], [333.0, 136.0], [24.0, 136.0]], ['(45元/每公斤,100公斤起订)', 0.9676722]] ......02 界面部分
界面部分基于pyqt5实现,其中pyqt GUI程序开发入门和环境配置,详见一篇博客(具体见文末)。
主要步骤:
1. 界面布局设计
在QtDesigner中拖拽控件,完成程序界面布局,并保存*.ui文件。
2. 利用 pyuic 自动生成界面代码
在 pycharm 的项目文件结构中找到*.ui文件,右键——External Tools——pyuic,会在ui文件同级目录下自动生成界面 ui 的 Python 代码。

3. 编写界面业务类
业务类 MainWindow 实现程序逻辑和算法功能,与前面第2步生成的ui实现解耦,避免每次修改ui文件会影响业务代码。ui界面上的控件可以通过self._ui.xxxObjectName 访问。
class MainWindow(QMainWindow):
FIT_WINDOW, FIT_WIDTH, MANUAL_ZOOM = 0, 1, 2
def __init__(self):
super().__init__() # 调用父类构造函数,创建QWidget窗体
self._ui = Ui_MainWindow() # 创建ui对象
self._ui.setupUi(self) # 构造ui
self.setWindowTitle(__appname__)
# 加载默认配置
config = get_config()
self._config = config
# 单选按钮组
self.checkBtnGroup = QButtonGroup(self)
self.checkBtnGroup.addButton(self._ui.checkBox_ocr)
self.checkBtnGroup.addButton(self._ui.checkBox_det)
self.checkBtnGroup.addButton(self._ui.checkBox_recog)
self.checkBtnGroup.addButton(self._ui.checkBox_layoutparser)
self.checkBtnGroup.setExclusive(True)4. 实现界面业务逻辑
对主界面上的按钮、列表、绘图控件进行信号槽连接。自定义的槽函数不用专门声明,如果是自定义的信号,需要在类__init__()前加上 yourSignal= pyqtSignal(args)。
这里以按钮响应函数、列表响应函数为例。按钮点击的信号是 clicked,listWidget列表切换选择的信号是 itemSelectionChanged 。
# 按钮响应函数
self._ui.btnOpenImg.clicked.connect(self.openFile)
self._ui.btnOpenDir.clicked.connect(self.openDirDialog)
self._ui.btnNext.clicked.connect(self.openNextImg)
self._ui.btnPrev.clicked.connect(self.openPrevImg)
self._ui.btnStartProcess.clicked.connect(self.startProcess)
self._ui.btnCopyAll.clicked.connect(self.copyToClipboard)
self._ui.btnSaveAll.clicked.connect(self.saveToFile)
self._ui.listWidgetResults.itemSelectionChanged.connect(self.onItemResultClicked)5. 运行看看效果
运行 python main.py 即可启动GUI程序。
打开图片→选择语言模型ch(中文)→选择文本检测+识别→点击开始,检测完的文本区域会自动画框,并在右侧识别结果——文本Tab页的列表中显示。
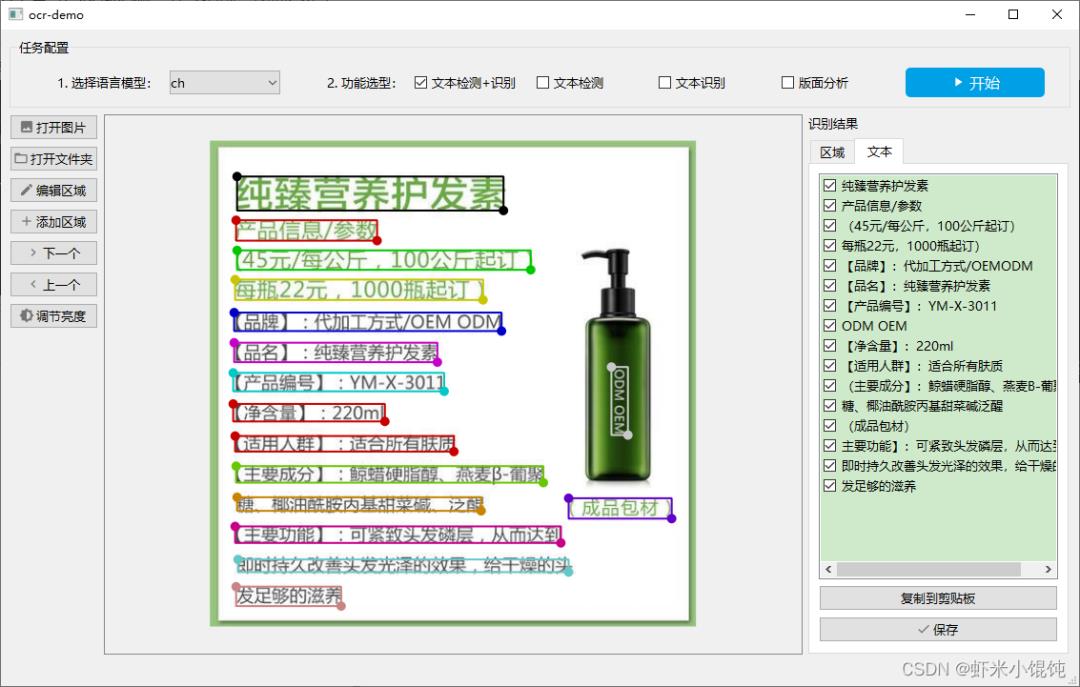
所有检测出文本的区域列表,在识别结果——区域Tab页:

软件代码
由于时间有限,软件细节功能还需进一步完善。代码已开源到 gitee 上,欢迎感兴趣的朋友提pull request,共同修改完善。
代码开源地址:
https://gitee.com/signal926/ocr-gui-demo
参考链接
画框、区域列表:
https://github.com/wkentaro/labelme
icons:
https://github.com/google/material-design-icons
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.3/doc/doc_ch/quickstart.md
https://blog.csdn.net/Bit_Coders/article/details/119304488

延伸阅读👇

延伸阅读《深度实践OCR》
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
以上是关于用python帮别人写了个文字识别程序的主要内容,如果未能解决你的问题,请参考以下文章