架构之思-分析那些深入骨髓的设计原则
Posted 编程一生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构之思-分析那些深入骨髓的设计原则相关的知识,希望对你有一定的参考价值。
引子
遵从SOLID五大设计原则、遵从三大编程范式……很多的设计原则对于像我这样工作十几年的人来说,已经刻到了骨髓里。
在平时工作中,不自觉的进行了熟练的运用:看到公司里有个基础数据这样的服务,明知道很难很难也要决心治理掉:“这种服务不应该存在!任何一个软件模块都应该只对一个用户或系统利益相关者负责(单一职责原则)。我们的代码是要长长久久运行N个世纪的,不应该将领域不清的部分堆到一处!”
有一次跟刚工作几年的小伙子讨论的时候,就是《面对编码分歧怎样展开讨论》里逻辑分析那一段,我突然意识到自己正面临着危险:很多原则是在很多年前思考并开始运用了,那时候的批判性思维还很弱,时代也在飞速的发展,是不是很多金科玉律当时并没有想明白、或者理解有偏差、或者应该被更新了。我是否正在逐渐走向经验主义?
想到这里,我决心从头来梳理分析自己深入骨髓的设计原则。

SOLID原则
先简单回忆一下SOLID原则的内容:
SRP:单一职责原则,任何一个软件模块应该只对某一类行为者负责。
OCP:开闭原则,设计良好的软件应该易于扩展(对扩展开放),同时抗拒修改(对修改关闭)。
LSP:里氏替换原则,尽量使用抽象(如父类),避免使用具体(如子类),以便于方便的进行替换。
ISP:接口隔离原则,客户端不应该依赖于它不需要的接口。这里啰嗦两句,Bob大叔在自己的巅峰之作《架构整洁之道》中详细介绍了SOLID原则,后来设计原则逐渐演变为六大,多出来的一个是LOD迪米特法则,又称最少知识原则,我一直找不到六大设计原则的出处,知道的朋友还烦请告知。我个人观点,接口隔离原则与迪米特法则异曲同工,所以没有必要放进来。
DIP:依赖反转原则,多使用抽象接口,尽量避免使用多变的实现类。
《面对编码分歧怎样展开讨论》里逻辑分析那一段,我本身之所以认为自己是对的,原因是同事的设计违反了LSP里氏替换原则和DIP依赖反转原则,同时还间接的违反了OCP开闭原则。
落笔在这个地方踌躇了很久。我该怎么证明自己这样是对的还是错的呢?这个问题最后还是想起了Bob大叔的观点,才和自己达成和解。
Bob大叔说:
科学和数学在证明方法上有着根本性的不同,科学理论和科学定律通常是无法被证明的,比如我们没法证明万有引力的正确性,但我们可以用科学实验来演示这些定律的正确性。而且不管做多少次正确的实验,也无法排除在今后的某次实验可能会推翻万有引力定律的可能性。
这就是科学理论和定律的特点:它们可以被伪证,但是没有办法被证明。如果某个结论经过一定努力没有办法证明是伪证,我们则认为它在当下是足够正确的。
从这里吸取的营养是:我应该从本身这么做是否正确出发。《面对编码分歧怎样展开讨论》里逻辑分析那一段,实际上同事已经认同了他要解决的问题有别的方法去解决,而我的建议有更好的扩展性和可维护性。
扩展性和可维护性又在软件领域有多重要的作用呢?软件之所以叫软件,软本身就有灵活的意思,如果以后都不太会变化,这段逻辑刻在硬件上不是更高效嘛。为了达到软件的本来目的,软件系统必须足够软,应该很容易被修改。

三大编程范式
先来简单回忆一下三大编程范式:
结构化编程
结构化编程对程序控制权的直接转移进行了限制和规范。
对结构化编程的结构举个例子,大家就明白了:顺序结构、分支结构和循环结构。现在大多数编程语言都禁止使用goto这样的无限制跳转语句,因为它将会损害程序的整体结构。
工作十几年,自己从未写过goto语句。但是见过一些源码有goto语句的,那时候才见识了goto的厉害:用它可以跳转到任何代码位置,不受限制。它破坏了程序的封装,修改一个类的内部结构变的很危险,增加了耦合性。
不过我们不必担心自己没有遵循结构化编程的范式,只要是按照编程语言推荐的语法都是遵循这一范式的。
面向对象编程
面向对象编程对程序控制权的间接转移进行了限制和规范。
面向过程和面向对象最大的不同在于,面向对象有更好的可读性和重用性。
记得头几年评价别人代码写的不怎么样会这样说:这个同学用面向对象的语言写出了面向过程的程序。
函数式编程
函数式编程对程序中的赋值进行了限制和规范。
面向对象编程是对数据进行抽象,函数式编程是对行为的抽象。我们来理解一下什么是对行为的抽象。
下面代码可以被编译通过:
new ArrayList<Integer>().stream().forEach(x-> System.out.println(x=x+1));
下面代码不可以被编译通过:
int i =0;
new ArrayList<Integer>().stream().forEach(x-> System.out.println(i+=x));
提示说i应该是final或者effectively(实际上) final。
为什么函数式编程要求用到的变量i为不可变的?但是没有要求x是不可变呢?
区别是x是函数的参数也就是输入,i是函数外变量。而函数式编程是对行为抽象,就是说对输入进行了一系列的处理行为,得到一个输出;不能对其他数据进行操作,对其他数据操作是面向编程做的事情。
举个生活中的例子:
记得高中的时候特别喜欢陆游那首<卜算子.咏梅>
驿外断桥边,寂寞开无主。
已是黄昏独自愁,更着风和雨。
无意苦争春,一任群芳妒。
零落成泥碾作尘,只有香如故。
这首古文描述了对梅花的加工行为。这个行为抽象为函数是这个样子的:
function 梅花变香泥(一枝梅) {
第一步:孤立它
第二步:让它经历黑暗
第三步:让它经历风雨
第四步:让其他花儿妒忌它
第五步:让它凋落到泥里化为尘土只保留香气
}
这里“梅花变香泥”行为被抽象,对调用者来说只要调用了这个函数,就是调用了那5步骤的行为。这里仅能对一枝梅处理,一枝红杏出墙来到这里,她只能对这枝梅产生改变,她可以嫉妒这枝梅冬天开放。“梅花已谢杏花新”,让梅花零落成泥后让杏花开放,这就不是这个函数该做的事了。
面向对象编程可以做这件事情,它是对数据的抽象:
暖气潜催次第春,梅花已谢杏花新。
暖气对象 暖气;
春对象 春;
梅花对象 梅花;
杏花对象 杏花;
public 春对象 描述春天() {
梅花.状态=谢了;
杏花.状态=开了;
春.空气状态=暖气;
春.梅花状态=谢了;
春.杏花状态=开了;
return 春;
}
我有对结构化编程没有什么疑问,毕竟50年前有人就用数学方法证明了顺序结构、分支结构和循环结构的正确性。
但是作为一直以java语言作为主要开发语言的我,java是面向对象的这句话一直在脑子里和引入函数式做斗争。
函数式编程确实有很多优势:因为函数式编程的引入变量都是不可变的,虚拟机实现时可以去掉很多多余的锁,并发处理更快;代码简洁;内聚性更好……
我仔细想了一下,对诸如java这种面向对象的编程语言来说,函数式编程和面向接口编程一样,是局部实现的技巧,整体结构还是面向对象的。
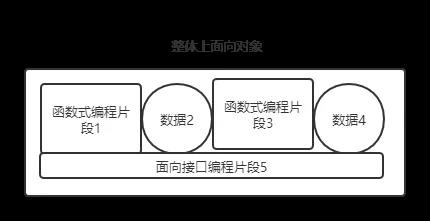
后记
在上篇《架构师之路-redis集群解析》最后我说到如果在看超过10,我就写篇架构师三大难的文章,只可惜周六发文一向阅读量不高,虽然“在看率”较平时已经提高很多了,目前还没达到。但是“在看率”上来了,可以感受到大家的支持,让我充满力量。女孩子嘛,比较感性,决定本周加更这篇,表达一下自己的感恩~~
推荐阅读
超硬核!!每个华为架构师不愿意透露的10个设计原则。注意迟点会下架
目录
做软件开发多年,CRUD仿佛已经形成一种惯性,深入骨髓,按照常规的结构拆分:表现层、业务逻辑层、数据持久层,一个功能只需要个把小时代码就撸完了。
再结合CTRL+C和CTRL+V 绝世秘籍,一个个功能点便如同雨后春笋般被快速克隆实现。
是不是有种雄霸天下的感觉,管他什么业务场景,大爷我一梭到底,天下无敌!!!

可现实真的是这样?
答案不言而喻!!!
初入软件行业,很多人都会经历这个阶段。时间久了,很多人便产生困惑,能力并没有随着工作年限得到同比提升,焦虑失眠,如何改变现状?
悟性高的人,很快能从一堆乱麻中找到线索,并不断的提升自己的能力。
什么能力?
当然是软件架构能力,一名优秀的软件架构师,要具备复杂的业务系统的吞吐设计能力、抽象能力、扩展能力、稳定性。
如何培养这样能力?

我将常用的软件架构原则,做了汇总,目录如下:
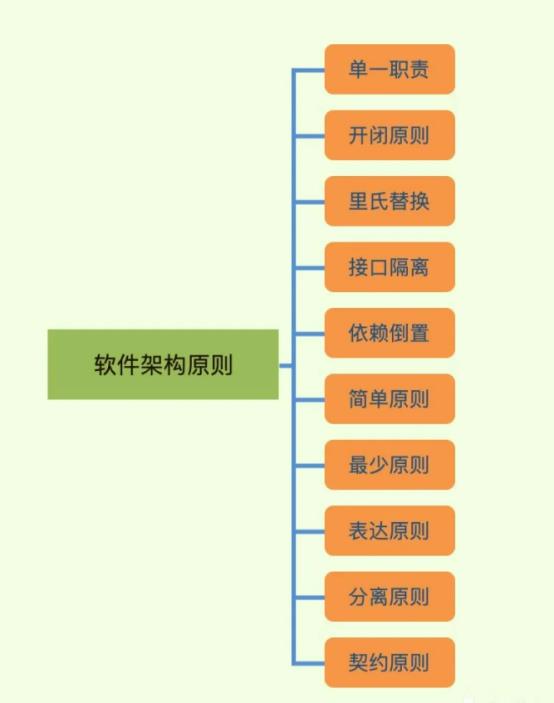
当然这些原则有些是相互辅助,有些是相互矛盾的。实际项目开发中,要根据具体业务场景,灵活应对。千万不能教条主义,生搬硬套。
单一职责
我们在编码的时候,为了省事,总是喜欢在一个类中添加各种各样的功能。未来业务迭代时,再不断的修改这个类,导致后续的维护成本很高,耦合性大。牵一发而动全身。为了解决这个问题,我们在架构设计时通常会考虑单一职责
定义:
单一职责(SRP:Single Responsibility Principle),面向对象五个基本原则(SOLID)之一。每个功能只有一个职责,这样发生变化的原因也会只有一个。通过缩小职责范围,尽量减少错误的发生。
单一职责原则和一个类只干一件事之间,最大的差别就是,将变化纳入了考量。
代码要求:
一个接口、类、方法只负责一项职责,简单清晰。
优点:
降低了类的复杂度,提高类的可读性、可维护性。进而提升系统的可维护性,降低变更引起的风险。
示例:
有一个用户服务接口UserService,提供了用户注册、登录、查询个人信息的方法,主要还是围绕用户相关的服务,看似合理。
public interface UserService
{
// 注册接口
Object register(Object param);
// 登录接口
Object login(Object param);
// 查询用户信息
Object queryUserInfoById(Long uid);
}
过了几天,业务方提了一个需求,用户可以参加项目。简单的做法是在UserService类中增加一个 joinProject()方法 又过了几天,业务方又提了一个需求,统计一个用户参加过多少个项目,我们是不是又在UserService类中增加一个 countProject()方法。
这样导致的后果是, UserService类 的职责越来越重,类会不断膨胀,内部的实现会越来越复杂。既要负责用户相关还有负责项目相关,后续任何一块业务变动,都会导致这个类的修改。
两类不同的需求,都改到同一个类。正确做法是,把不同的需求引起的变动拆分开,单独构建一个 ProjectService类 ,专门负责项目相关的功能。
public interface ProjectService
{
// 加入一个项目
void addProject (Object param);
// 统计一个用户参加过多少个项目
void countProject(Object param);
}
这样带来的好处是,用户相关的需求只要改动 UserService。 如果是项目管理的需求,只需要改动 ProjectService。 二者各自变动的理由就少了很多。
开闭原则
开闭原则(OCP:Open-Closed Principle), 主要指一个类、方法、模块 等 对扩展开放,对修改关闭。简单来讲,一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码来实现变化。
个人感觉,开闭原则在所有的原则中最重要,像我们耳熟能详的23种设计模式,大部分都是遵循开闭原则,来解决代码的扩展性问题。
实现思路:
采用抽象构建框架主体,用实现扩展细节。不同的业务采用不用的子类,尽量避免修改已有代码。
优点:
-
可复用性好。在软件完成以后,仍然可以对软件进行扩展,加入新的功能,非常灵活。因此,这个软件系统就可以通过不断地增加新的组件,来满足不断变化的需求。
-
可维护性好。它的底层抽象相对固定,不用担心软件系统中原有组件的稳定性,这就使变化中的软件系统有一定的稳定性和延续性。
示例:
比如有这样一个业务场景,我们的电商支付平台,需要接入一些支付渠道,项目刚启动时由于时间紧张,我们只接入微信支付,那么我们的代码这样写:
class WeixinPay
{
public Object pay(Object requestParam)
{
// 请求微信完成支付
// 省略。。。。
return new Object();
}
}
随着业务扩展,后期开始逐步接入一些其他的支付渠道,比如支付宝、云闪付、红包支付、零钱包支付、积分支付等,要如何迭代?
class PayGateway
{
public Object pay(Object requestParam) {
if(微信支付){
// 请求微信完成支付
// 省略。。。。
}esle if(支付宝){
// 请求支付宝完成支付
// 省略。。。。
}esle if(云闪付){
// 请求云闪付完成支付
// 省略。。。。
}
// 其他,不同渠道的个性化参数的抽取,转换,适配
// 可能有些渠道一次支付需要多次接口请求,获取一些前置准备参数
// 省略。。。。
return new Object();
}
}
所有的业务逻辑都集中到一个方法中,每一个支付渠道本身的业务逻辑又相当复杂,随着更多支付渠道的接入,pay方法中的代码逻辑会越来越重,维护性只会越来越差。每一次改动都要回归测试所有的支付渠道,劳民伤财。那么有没有什么好的设计原则,来解决这个问题。我们可以尝试按开闭原则重新编排代码。
首先定义一个支付渠道的抽象接口类,把所有的支付渠道的骨架抽象出来。设计一系列的插入点,并对若干插入点流程关联。
关于插入点,用过OpenResty的同学都知道,通过set_by_lua、rewrite_by_lua、body_filter_by_lua 等不同阶段来处理请求在对应阶段的逻辑,有效的避免各种衍生问题。
abstract class AbstractPayChannel
{
public Object pay(Object requestParam)
{
// 抽象方法
}
}
逐个实现不同支付渠道的子类,如: AliayPayChannel、WeixinPayChannel, 每个渠道都是独立的,后期如果做渠道升级维护,只需修改对应的子类即可,降低修改代码的影响面。
class AliayPayChannel extends AbstractPayChannel
{
public Object pay(Object requestParam)
{
// 根据请求参数,如果选择支付宝支付,处理后续流程
// 支付宝处理
}
}
class WeixinPayChannel extends AbstractPayChannel{
public Object pay(Object requestParam) {
// 根据请求参数,如果选择微信支付,处理后续流程
// 微信处理
}
}
总调度入口,遍历所有的支付渠道,根据 requestParam 里的参数,判断当前渠道是否处理本次请求。
当然,也有可能采用组合支付的方式,比如,红包支付+微信支付,可以通过上下文参数,传递一些中间态的数据。下文参数,传递一些中间态的数据。
class PayGateway
{
List<AbstractPayChannel> payChannelList;
public Object pay(Object requestParam) {
for(AbstractPayChannel channel:payChannelList){
channel.pay(requestParam);
}
}
}
里氏替换
里氏替换原则(LSP:Liskov Substitution Principle): 所有引用基类的地方必须能透明地使用其子类的对象。
简单来讲,子类可以扩展父类的功能,但不能改变父类原有的功能(如:不能改变父类的入参,返回),跟面向对象编程的多态性类似。
多态是面向对象编程语言的一种语法,是一种代码实现的思路。而里氏替换是一种设计原则,是用来指导继承关系中子类如何设计,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
实现思路:
- 子类可以实现父类的抽象方法。
- 子类中可以增加自己特有的方法。
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
- 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
接口隔离
接口隔离原则(ISP:Interface Segregation Principle) 要求程序员尽量将臃肿庞大的接口拆分成更小的和更具体的接口,让接口中只包含调用方感兴趣的方法,而不应该强迫调用方依赖它不需要的接口。
实现思路:
- 接口尽量小,但是要有限度。一个接口只服务于一个子模块或业务逻辑。
- 为依赖接口的类定制服务。只提供调用者需要的方法,屏蔽不需要的方法。
- 结合业务,因地制宜。每个项目或产品都有特定的环境因素,环境不同,接口拆分的标准就不同,需要我们有较强的业务 sense。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
示例:
用户中心封装了一套UserService接口,给上层调用(业务端以及管理后台)提供用户基础服务。
public interface UserService
{
// 注册接口
Object register(Object param);
// 登录接口
Object login(Object param);
// 查询用户信息
Object queryUserInfoById(Long uid);
}
但随着业务衍化,我们需要提供一个删除用户功能,常规的做法是直接在 UserService接口 中增加一个 deleteById方法 ,比较简单。
但这样会带来一个安全隐患,如果该方法被普通权限的业务方误调用,容易导致误删用户,引发灾难。
如何避免这个问题,我们可以采用接口隔离的原则
定义一个全新的接口服务,并提供 deleteById方法 , BopsUserService接口 只提供给Bops管理后台系统使用。
public interface BopsUserService
{
// 删除用户
Object deleteById(Long uid);
}
总结一下,在设计微服务接口时,如果其中一些方法只限于部分调用者使用,我们可以将其拆分出来,独立封装,而不是强迫所有的调用方都能看到它。
依赖倒置
软件设计中的细节具有多变性,但是抽象相对稳定,为了利用好这个特性,我们引入了依赖倒置原则。 依赖倒置原则(DIP:Dependence Inversion Principle): 高层模块不应直接依赖低层模块,二者应依赖于抽象;抽象不应该依赖实现细节;而实现细节应该依赖于抽象。
依赖倒置原则的主要思想是要面向接口编程,不要面向具体实现编程。
示例:
定义一个消息发送接口MessageSender,具体的实例Bean注入到Handler,触发完成消息的发送。
interface MessageSender
{
void send(Message message);
}
class Handler {
@Resource
private MessageSender sender;
void execute() {
sender.send(message);
}
}
假如消息的发送采用Kafka消息中间件,我们需要定义一个 KafkaMessageSender 实现类来实现具体的发送逻辑。
class KafkaMessageSender implements MessageSender
{
private KafkaProducer producer;
public void send(final Message message) {
producer.send(new KafkaRecord<>("topic", message));
}
}
这样实现的好处,将高层模块与低层实现解耦开来。假如,后期公司升级消息中间件框架,采用Pulsar,我们只需要定义一个PulsarMessageSender类即可,借助Spring容器的@Resource会自动将其Bean实例依赖注入。
优点:
- 降低类间的耦合性。
- 提高系统的稳定性。
- 降低并行开发引起的风险。
- 提高代码的可读性和可维护性。
最后,要玩溜依赖倒置原则,必须要熟悉 控制反转 和 依赖注入 ,如果你是java后端,这两个词语你一定不陌生,Spring框架核心设计就是依赖这两个原则。
简单原则
复杂系统的终极架构思路就是化繁为简,此简单非彼简单,简单意味着灵活性的无限扩展,接下来我们来了解下这个简单原则。
简单原则(KISS:Keep It Simple and Stupid)。 翻译过来,保持简单,保持愚蠢。
我们深入剖析下这个 “简单”:
1、简单不等于简单设计或简单编程。软件开发中,为了赶时间进度,很多技术方案简化甚至没有技术方案,认为后面再找时间重构,编码时,风格随意,追求本次项目快速落地,导致欠下一大堆技术债。长此以往,项目维护成本越来越高。
保持简单并不是只能做简单设计或简单编程,而是做设计或编程时要努力以最终产出简单为目标,过程可能非常复杂也没关系。
2、简单不等于数量少。这两者没有必然联系,代码行少或者引入不熟悉的开源框架,看似简单,但可能引入更复杂的问题。
如何写出“简单”的代码?
- 不要长期进行打补丁式的编码。
- 不要炫耀编程技巧。
- 不要简单编程。
- 不要过早优化。
- 要定期做 Code Review。
- 要选择合适的编码规范。
- 要适时重构。
- 要有目标地逐渐优化。
最少原则
最少原则也称迪米特法则(LoD:Law of Demeter)。迪米特法则定义只与你的直接朋友交谈,不跟“陌生人”说话。
如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
核心思路:
-
一个类只应该与它直接相关的类通信
-
每一个类应该知道自己需要的最少知识
示例:
现在的软件采用分层架构,比如常见的 Web --> Service --> Dao 三层结构。 如果中间的Service层没有什么业务逻辑,但是按照迪米特法则保持层之间的密切联系,也要定义一个类,纯粹用于Web层和Dao层之间的调用转发。
这样传递效率势必低下,而且存在大量代码冗余。面对此问题,我们需灵活应对,早期可以允许Web层直接调用Dao。后面随着业务复杂度的提高,我们可以慢慢将Controller中的重业务逻辑收拢沉淀到Service层中。随着架构的衍化,清晰的分层开始慢慢沉淀下来。
写在最后,迪米特法则关心局部简化,这样很容易忽视整体的简化。
表达原则
代码的可维护性也是考验工程师能力的一个重要标准。试问一个人写的代码,每次code review时都是一堆问题,你会觉得他靠谱吗?
这时候我们就需要引入一个表达原则。
表达原则(Program Intently and Expressively,简称 PIE) ,起源于敏捷编程,是指编程时应该有清晰的编程意图,并通过代码明确地表达出来。
表达原则的核心思想:代码即文档,通过代码清晰地表达我们的真实意图。
那么如何提高代码的可读性?
1、优化代码表现形式
无论是变量名、类名还是方法名,要命名合理,要能清晰准确的表达含义。再配合一定的中文注释,基本不用看设计文档就能快速的熟悉项目代码,理解原作者的意图。
2、改进控制流和逻辑
控制嵌套代码的深度,比如if else的深度最好不要超多三层。外层最好提前做否定式判断,提前终止操作或返回。这样的代码逻辑清晰。下面示例便是正确的处理:
public List<User> getStudents(int uid)
{
List<User> result = new ArrayList<>();
User user = getUserByUid(uid);
if (null == user) {
System.out.println("获取员工信息失败");
return result;
}
Manager manager = user.getManager();
if (null == manager) {
System.out.println("获取领导信息失败");
return result;
}
List<User> users = manager.getUsers();
if (null == users || users.size() == 0) {
System.out.println("获取员工列表失败");
return result;
}
for (User user1 : users) {
if (user1.getAge() > 35 && "MALE".equals(user1.getSex())) {
result.add(user1);
}
}
return result;
}
分离原则
天下大事,分久必合合久必分。面对复杂的问题,考虑人脑的处理能力有限,有效的解决方案,就是大事化小,小事化了,将复杂问题拆分为若干个小问题,通过解决小问题进而解决大问题。
分离的核心思路:
1、架构视角
结合业务场景对整个系统内若干组件进行边界划分,如,层与层(MVC)、模块与模块、服务与服务等。像现在流行的DDD领域驱动设计指导的微服务就是一种很好的拆解方式,通过水平分离的策略达到服务与服务之间的分离。
架构设计视角下的关注点分离更重视组件之间的分离,并通过一定的通信策略来保证架构内各个组件间的相互引用。
2、编码视角
编码视角主要侧重于某个具体类或方法间的边界划分。比如Stream流的filter、map、limit,数据集在不同阶段按照不同的逻辑处理,并将输出内容作为下一个方法的输入,当所有的流程处理完后,最后汇总结果。
一些不错分层案例:
1、MVC模型
2、网络 OSI 七层模型
一个好的架构一定具有不错的分层,各层之间通过定义好的规范通讯 ,一旦系统中的某一部分发生了改变,并不会影响其他部分(前提,系统容错做的足够好)。
契约原则
天下事无规矩不成方圆,软件架构也是一样道理。动辄千日的大项目,如何分工协作,保证大家的工作能有条不紊的向前推进,靠的就是契约原则。
契约式原则(DbC:Design by Contract)。 软件设计时应该为软件组件定义一种精确和可验证的接口规范,这种规范要包括使用的预置条件、后置条件和不变条件,用来扩展普通抽象数据类型的定义。
契约原则关注重点:
- API 必须要保证输入是接收者期望的输入参数。
- API 必须要保证输出结果的正确性。
- API 必须要保持处理过程中的一致性。如果一个API被二次修改后,整个集群的服务器都要重新部署,保证服务能力状态的一致。
如何做好 API 接口设计?
1、接口职责分离。设计 API 的时候,应该尽量让每一个 API 只做一个职责的事情,保证API的简单和稳定性。避免相互干扰。
2、 API 命名。通过命名基本能猜出接口的功能,另外尽量使用小写英文。
3、接口具有幂等性。当一个操作执行多次所产生的影响与一次执行的影响相同。
4、安全策略。如果API是外部使用,要考虑黑客攻击、接口滥用,比如采用限流策略。
5、版本管理。API发布后不可能一成不变,很可能因为升级导致新、旧版本的兼容性问题,解决办法就是对API 进行版本控制和管理。

最后提醒大家软件架构原则的核心精髓,尽可能把变的部分和不变的部分分开,让不变的部分稳定下来。我们知道,模型是相对稳定的,实现细节则是容易变动的部分。所以,构建出一个稳定的模型层,对任何一个系统而言,都是至关重要的。
关注苏州程序大白,持续更新技术分享。谢谢大家支持
以上是关于架构之思-分析那些深入骨髓的设计原则的主要内容,如果未能解决你的问题,请参考以下文章