一文读懂深克隆与浅克隆的关系
Posted Tom弹架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂深克隆与浅克隆的关系相关的知识,希望对你有一定的参考价值。
本文节选自《设计模式就该这样学》
1 分析JDK浅克隆API带来的问题
在Java提供的API中,不需要手动创建抽象原型接口,因为Java已经内置了Cloneable抽象原型接口,自定义的类型只需实现该接口并重写Object.clone()方法即可完成本类的复制。
通过查看JDK的源码可以发现,其实Cloneable是一个空接口。Java之所以提供Cloneable接口,只是为了在运行时通知Java虚拟机可以安全地在该类上使用clone()方法。而如果该类没有实现 Cloneable接口,则调用clone()方法会抛出 CloneNotSupportedException异常。
一般情况下,如果使用clone()方法,则需满足以下条件。
(1)对任何对象o,都有o.clone() != o。换言之,克隆对象与原型对象不是同一个对象。
(2)对任何对象o,都有o.clone().getClass() == o.getClass()。换言之,复制对象与原对象的类型一样。
(3)如果对象o的equals()方法定义恰当,则o.clone().equals(o)应当成立。
我们在设计自定义类的clone()方法时,应当遵守这3个条件。一般来说,这3个条件中的前2个是必需的,第3个是可选的。
下面使用Java提供的API应用来实现原型模式,代码如下。
class Client {
public static void main(String[] args) {
//创建原型对象
ConcretePrototype type = new ConcretePrototype("original");
System.out.println(type);
//复制原型对象
ConcretePrototype cloneType = type.clone();
cloneType.desc = "clone";
System.out.println(cloneType);
}
static class ConcretePrototype implements Cloneable {
private String desc;
public ConcretePrototype(String desc) {
this.desc = desc;
}
@Override
protected ConcretePrototype clone() {
ConcretePrototype cloneType = null;
try {
cloneType = (ConcretePrototype) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return cloneType;
}
@Override
public String toString() {
return "ConcretePrototype{" +
"desc=\'" + desc + \'\\\'\' +
\'}\';
}
}
}
super.clone()方法直接从堆内存中以二进制流的方式进行复制,重新分配一个内存块,因此其效率很高。由于super.clone()方法基于内存复制,因此不会调用对象的构造函数,也就是不需要经历初始化过程。
在日常开发中,使用super.clone()方法并不能满足所有需求。如果类中存在引用对象属性,则原型对象与克隆对象的该属性会指向同一对象的引用。
@Data
public class ConcretePrototype implements Cloneable {
private int age;
private String name;
private List<String> hobbies;
@Override
public ConcretePrototype clone() {
try {
return (ConcretePrototype)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
@Override
public String toString() {
return "ConcretePrototype{" +
"age=" + age +
", name=\'" + name + \'\\\'\' +
", hobbies=" + hobbies +
\'}\';
}
}
修改客户端测试代码。
public static void main(String[] args) {
//创建原型对象
ConcretePrototype prototype = new ConcretePrototype();
prototype.setAge(18);
prototype.setName("Tom");
List<String> hobbies = new ArrayList<String>();
hobbies.add("书法");
hobbies.add("美术");
prototype.setHobbies(hobbies);
System.out.println(prototype);
//复制原型对象
ConcretePrototype cloneType = prototype.clone();
cloneType.getHobbies().add("技术控");
System.out.println("原型对象:" + prototype);
System.out.println("克隆对象:" + cloneType);
}
我们给复制的对象新增一个属性hobbies(爱好)之后,发现原型对象也发生了变化,这显然不符合预期。因为我们希望复制出来的对象应该和原型对象是两个独立的对象,不再有联系。从测试结果来看,应该是hobbies共用了一个内存地址,意味着复制的不是值,而是引用的地址。这样的话,如果我们修改任意一个对象中的属性值,protoType 和cloneType的hobbies值都会改变。这就是我们常说的浅克隆。只是完整复制了值类型数据,没有赋值引用对象。换言之,所有的引用对象仍然指向原来的对象,显然不是我们想要的结果。那如何解决这个问题呢?
Java自带的clone()方法进行的就是浅克隆。而如果我们想进行深克隆,可以直接在super.clone()后,手动给复制对象的相关属性分配另一块内存,不过如果当原型对象维护很多引用属性的时候,手动分配会比较烦琐。因此,在Java中,如果想完成原型对象的深克隆,则通常使用序列化(Serializable)的方式。
2 使用序列化实现深克隆
在上节的基础上继续改造,增加一个deepClone()方法。
/**
* Created by Tom.
*/
@Data
public class ConcretePrototype implements Cloneable,Serializable {
private int age;
private String name;
private List<String> hobbies;
@Override
public ConcretePrototype clone() {
try {
return (ConcretePrototype)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
return null;
}
}
public ConcretePrototype deepClone(){
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (ConcretePrototype)ois.readObject();
}catch (Exception e){
e.printStackTrace();
return null;
}
}
@Override
public String toString() {
return "ConcretePrototype{" +
"age=" + age +
", name=\'" + name + \'\\\'\' +
", hobbies=" + hobbies +
\'}\';
}
}
客户端调用代码如下。
public static void main(String[] args) {
//创建原型对象
ConcretePrototype prototype = new ConcretePrototype();
prototype.setAge(18);
prototype.setName("Tom");
List<String> hobbies = new ArrayList<String>();
hobbies.add("书法");
hobbies.add("美术");
prototype.setHobbies(hobbies);
//复制原型对象
ConcretePrototype cloneType = prototype.deepCloneHobbies();
cloneType.getHobbies().add("技术控");
System.out.println("原型对象:" + prototype);
System.out.println("克隆对象:" + cloneType);
System.out.println(prototype == cloneType);
System.out.println("原型对象的爱好:" + prototype.getHobbies());
System.out.println("克隆对象的爱好:" + cloneType.getHobbies());
System.out.println(prototype.getHobbies() == cloneType.getHobbies());
}
运行程序,得到如下图所示的结果,与期望的结果一致。
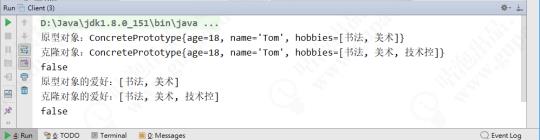
从运行结果来看,我们的确完成了深克隆。

本文为“Tom弹架构”原创,转载请注明出处。技术在于分享,我分享我快乐!
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。关注微信公众号『 Tom弹架构 』可获取更多技术干货!
java中深克隆与浅克隆的区别
java中深克隆和浅克隆又什么区别,对于对象的克隆,无论是深克隆还是浅克隆,克隆前和克隆后的内存地址,内容为什么不相等?
能够给你做出解释,我很荣幸!!献丑了:A、你说的很对,无论是深克隆还是浅克隆都是克隆,既然是克隆就必然会产生一个全新的对象,这个全新的对象和原对象的保持一致性的深浅取决于克隆的深度。但需要始终明确的一点是克隆的对象与源对象没有任何关系,它在堆中是一个独立的实体,占据独立的内存地址,与原对象没有任何引用与指向关系。这个新生的对象是在源对象被克隆时由JVM运行时环境在调用类加载器时通过反射创建出来的。
B、深克隆与浅克隆的区别:深克隆的过程是通过序列化来完成的,而序列化的过程可以将对象及所牵涉的所有引用链中的对象一起通过字节流的方式转移到特定的存储单元中(这个存储单元可以是内存也可以是硬盘,对于克隆通常是序列化至内存),再通过反序列化的过程读出这些序列化的字节流重构出对象,这样就完成了一个新对象的产生。而浅克隆不用序列化,这种克隆方式仅仅只是将指定的当前对象复制出来一个,这种复制过程不包括原对象引用的各个对象
C、克隆出的对象与原对象具有相同的属性及方法,但克隆的对象与原对象是属于两个不同的独立对象,因此二者占据内存中不同的空间地址。这就好比两个人长的极为相像但他们毕竟还是属于两个人,可以住在不同的场所。 参考技术A 深克隆与浅克隆
大家知道,对象是互相引用的,即对象中可能包含了另一个对象的引用,举例如:有一个Order对象,Order对象中又包含了LineItems对象,然后LineItems对象又包含了Item对象。
好了,现在我有一个Order对象order1,它包含了一个LineItems对象items,这表示的是有一个订单order1,订单的内容是items。
好的,现在有另一个客户想要一份订单,内容跟order1完全一样,那么在系统的逻辑层我们怎么做呢?很简单,order2=order1.clone(). 我们知道clone方法是在内存中生成一个新的对象,而不是只得到原对象的引用。这时候,有人说话了:“哦,明白了我们对order2的成员变量进行修改,是不会影响order1的。” 很可惜,这句话只对了一半。
假设order类有一个成员变量name,当然改变order2.name不会影响order1.name,因为他们在不同的内存区域。但是如果改变 order1.items呢?很遗憾,简单地使用order1.clone,是会影响到order2.items的。原因很简单,就是因为clone方法默认的是浅克隆,即不会克隆对象引用的对象,而只是简单地复制这个引用。所以在上例中,items对象在内存中只有一个,order1和order2都指向它,任何一个对象对它的修改都会影响另一个对象。
那相对浅克隆,深克隆自然就是会克隆对象引用的对象了。也就是说,在上例中,改变order1.items并不会影响order2.items了。因为内存中有两个一样的items。
如果实现深克隆?
一个方法自然是重写clone方法,添加如order.items=(LineItems)items.clone()的语句,也就是人为地添加对引用对象的复制。这个方法的缺点是如果引用对象有很多,或者说引用套引用很多重,那么太麻烦了。业界常用的方法是使用串行化然后反串行化的方法来实现深克隆。由于串行化后,对象写到流中,所有引用的对象都包含进来了,所以反串行化后,对等于生成了一个完全克隆的对象。绝!
这个方法的要求是对象(包括被引用对象)必须事先了Serializable接口,否则就要用transient关键字将其排除在复制过程中。本回答被提问者采纳
以上是关于一文读懂深克隆与浅克隆的关系的主要内容,如果未能解决你的问题,请参考以下文章