并发编程从零开始(十五)-CompletableFuture
Posted 会编程的老六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程从零开始(十五)-CompletableFuture相关的知识,希望对你有一定的参考价值。
并发编程从零开始(十五)-CompletableFuture
14 CompletableFuture 用法
从JDK 8开始,在Concurrent包中提供了一个强大的异步编程工具CompletableFuture。在JDK8之前,异步编程可以通过线程池和Future来实现,但功能还不够强大。

CompletableFuture实现了Future接口,所以它也具有Future的特性:调用get()方法会阻塞在那,直到结果返回。
另外1个线程调用complete方法完成该Future,则所有阻塞在get()方法的线程都将获得返回结果。
14.1 runAsync与supplyAsync
上面的例子是一个空的任务,下面尝试提交一个真的任务,然后等待结果返回。
例1:runAsync(Runnable)

CompletableFuture.runAsync(...)传入的是一个Runnable接口。
例2: supplyAsync(Supplier)
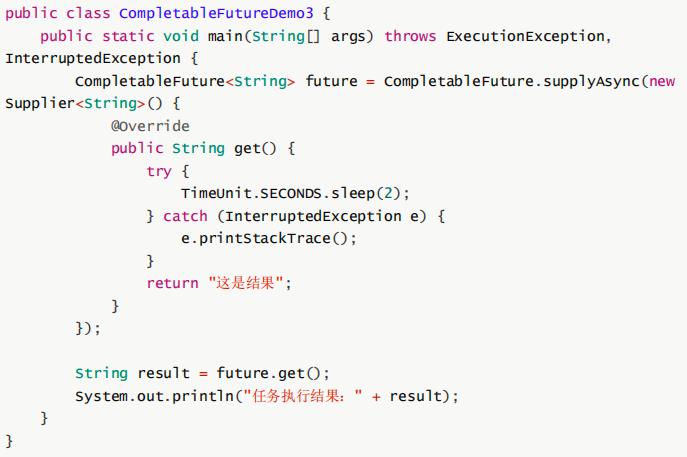
例2和例1的区别在于,例2的任务有返回值。没有返回值的任务,提交的是Runnable,返回的是CompletableFuture
通过上面两个例子可以看出,在基本的用法上,CompletableFuture和Future很相似,都可以提交两类任务:一类是无返回值的,另一类是有返回值的。
14.2 thenRun、thenAccept和thenApply
对于 Future,在提交任务之后,只能调用 get()等结果返回;但对于 CompletableFuture,可以在结果上面再加一个callback,当得到结果之后,再接着执行callback。
例1:thenRun(Runnable)

该案例最后不能获取到结果,只会得到一个null。
例2:thenAccept(Consumer)


上述代码在thenAccept中可以获取任务的执行结果,接着进行处理。
例3:thenApply(Function)

三个例子都是在任务执行完成之后,接着执行回调,只是回调的形式不同:
-
thenRun后面跟的是一个无参数、无返回值的方法,即Runnable,所以最终的返回值是CompletableFuture
类型。 -
thenAccept后面跟的是一个有参数、无返回值的方法,称为Consumer,返回值也是CompletableFuture
类型。顾名思义,只进不出,所以称为Consumer;前面的Supplier,是无参数,有返回值,只出不进,和Consumer刚好相反。 -
thenApply 后面跟的是一个有参数、有返回值的方法,称为Function。返回值是CompletableFuture
类型。
而参数接收的是前一个任务,即 supplyAsync(...)这个任务的返回值。因此这里只能用supplyAsync,不能用runAsync。因为runAsync没有返回值,不能为下一个链式方法传入参数。
14.3 thenCompose与thenCombine
例1:thenCompose
在上面的例子中,thenApply接收的是一个Function,但是这个Function的返回值是一个通常的基本数据类型或一个对象,而不是另外一CompletableFuture。如果 Function 的返回值也是一个CompletableFuture,就会出现嵌套的CompletableFuture。考虑下面的例子:

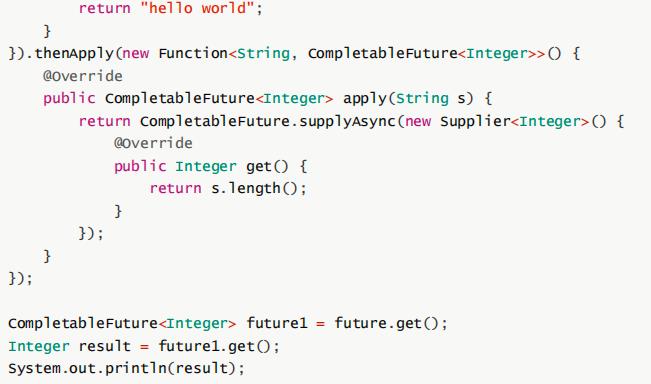
如果希望返回值是一个非嵌套的CompletableFuture,可以使用thenCompose:
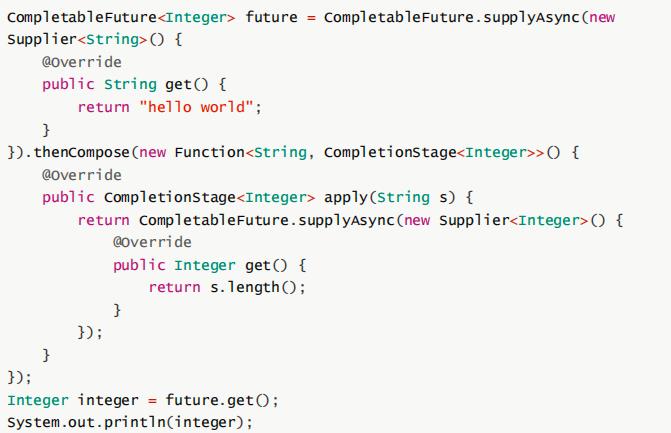
下面是thenCompose方法的接口定义:

CompletableFuture中的实现:
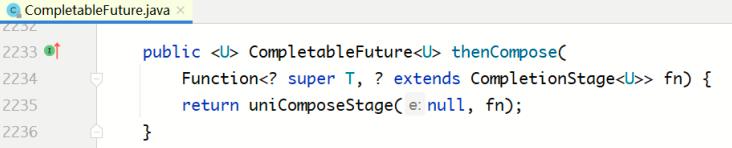
从该方法的定义可以看出,它传入的参数是一个Function类型,并且Function的返回值必须是CompletionStage的子类,也就是CompletableFuture类型。
例2:thenCombine
thenCombine方法的接口定义如下,从传入的参数可以看出,它不同于thenCompose。

第1个参数是一个CompletableFuture类型,第2个参数是一个方法,并且是一个BiFunction,也就是该方法有2个输入参数,1个返回值。
从该接口的定义可以大致推测,它是要在2个 CompletableFuture 完成之后,把2个CompletableFuture的返回值传进去,再额外做一些事情。实例如下:
14.4 任意个CompletableFuture的组合
上面的thenCompose和thenCombine只能组合2个CompletableFuture,而接下来的allOf 和anyOf 可以组合任意多个CompletableFuture。方法接口定义如下所示。


首先,这两个方法都是静态方法,参数是变长的CompletableFuture的集合。其次,allOf和anyOf的区别,前者是“与”,后者是“或”。
allOf的返回值是CompletableFuture
anyOf 的含义是只要有任意一个 CompletableFuture 结束,就可以做接下来的事情,而无须像AllOf那样,等待所有的CompletableFuture结束。
但由于每个CompletableFuture的返回值类型都可能不同,任意一个,意味着无法判断是什么类型,所以anyOf的返回值是CompletableFuture
并发编程从零开始-同步工具类
并发编程从零开始(十)-同步工具类
6 同步工具类
6.1 Semaphore
Semaphore也就是信号量,提供了资源数量的并发访问控制,其使用代码很简单,如下所示:


有参方法tryAcquire(long timeout, TimeUnit unit)的作用是在指定的时间内尝试地获取1个许可,如果获取不到就返回false。
可以使用Semphore实现一个简易的抢座:
public class Main {
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(2);
for (int i = 0; i < 5; i++) {
Thread.sleep(500);
new MySemphore(semaphore).start();
}
}
}
public class MySemphore extends Thread{
private Semaphore semaphore;
public MySemphore(Semaphore semaphore){
this.semaphore = semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+": working");
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName()+": releasing");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
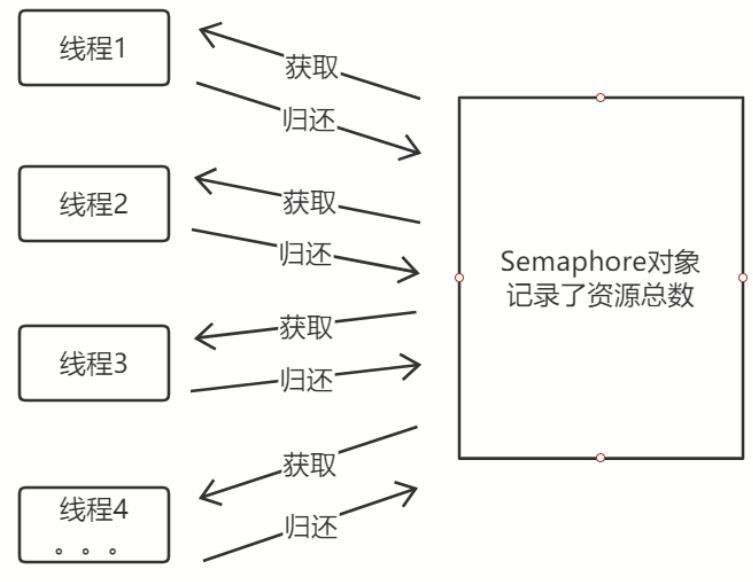
如下图所示,假设有n个线程来获取Semaphore里面的10份资源(n > 10),n个线程中只有10个线程能获取到,其他线程都会阻塞。直到有线程释放了资源,其他线程才能获取到。
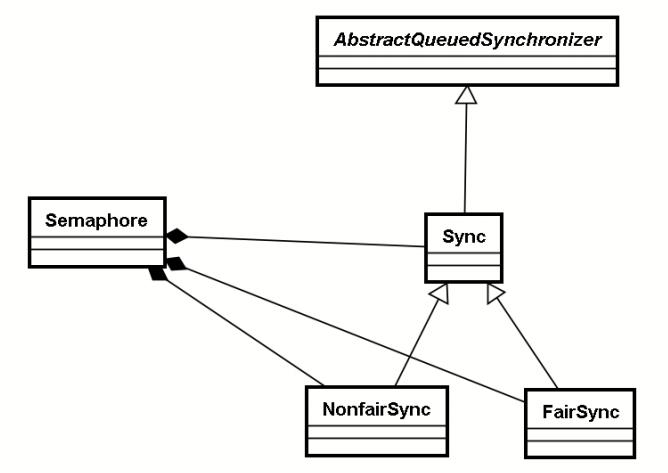
当初始的资源个数为1的时候,Semaphore退化为排他锁。正因为如此,Semaphone的实现原理和锁十分类似,是基于AQS,有公平和非公平之分。Semaphore相关类的继承体系如下图所示:
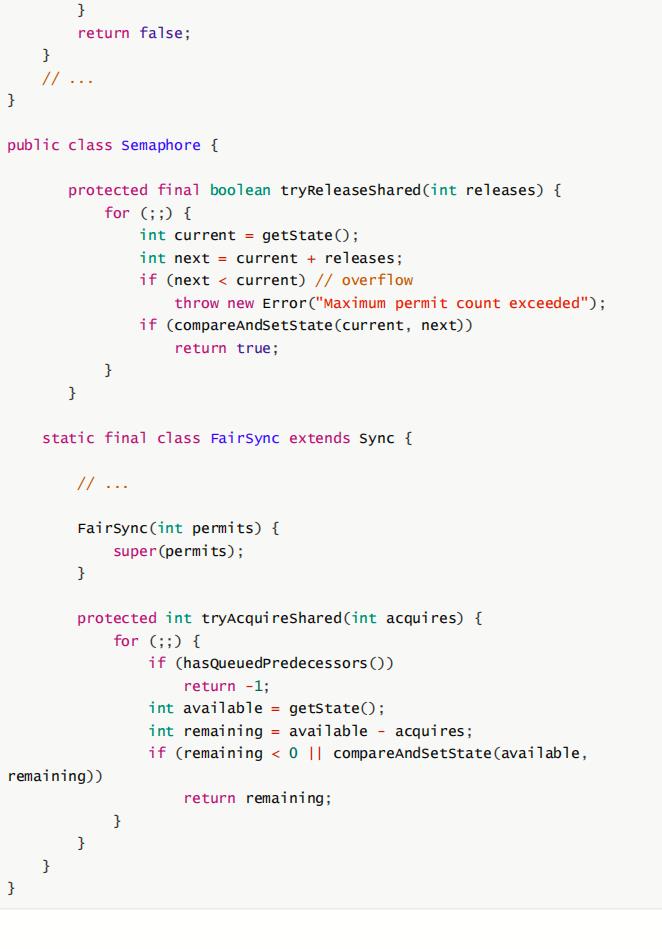
由于Semaphore和锁的实现原理基本相同。资源总数即state的初始值,在acquire里对state变量进行CAS减操作,减到0之后,线程阻塞;在release里对state变量进行CAS加操作。



6.2 CountDownLatch
6.2.1 CountDownLatch使用场景
假设一个主线程要等待5个 Worker 线程执行完才能退出,可以使用CountDownLatch来实现:
线程:
public class MyThread extends Thread{
private final CountDownLatch countDownLatch;
private final Random random = new Random();
public MyThread(String name ,CountDownLatch countDownLatch){
super(name);
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 运行结束");
countDownLatch.countDown();
}
}
Main类:
public class Main {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
new MyThread("THREAD"+i,countDownLatch).start();
}
//当前线程等待
countDownLatch.await();
System.out.println("程序运行结束");
}
}
下图为CountDownLatch相关类的继承层次,CountDownLatch原理和Semaphore原理类似,同样是基于AQS,不过没有公平和非公平之分。
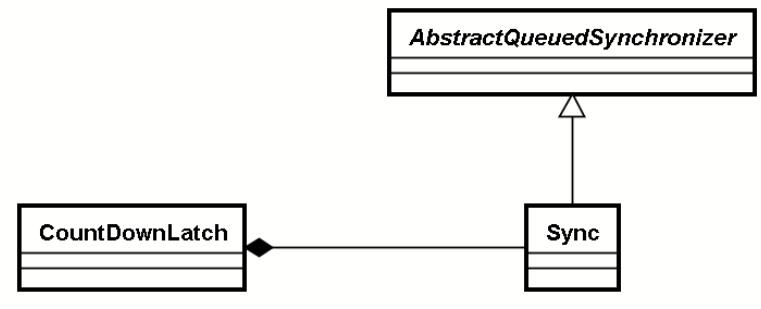
6.2.2 await()实现分析
await()调用的是AQS 的模板方法,CountDownLatch.Sync重新实现了tryAccuqireShared方法。

从tryAcquireShared(...)方法的实现来看,只要state != 0,调用await()方法的线程便会被放入AQS的阻塞队列,进入阻塞状态。
6.2.3 countDown()实现分析


countDown()调用的AQS的模板方法releaseShared(),里面的tryReleaseShared(...)由CountDownLatch.Sync实现。从上面的代码可以看出,通过CAS减少state的值,只有state=0,tryReleaseShared(...)才会返回true,然后执行doReleaseShared(...),一次性唤醒队列中所有阻塞的线程。
总结:由于是基于AQS阻塞队列来实现的,所以可以让多个线程都阻塞在state=0条件上,通过countDown()一直减state,减到0后一次性唤醒所有线程。如下图所示,假设初始总数为M,N个线程await(),M个线程countDown(),减到0之后,N个线程被唤醒。
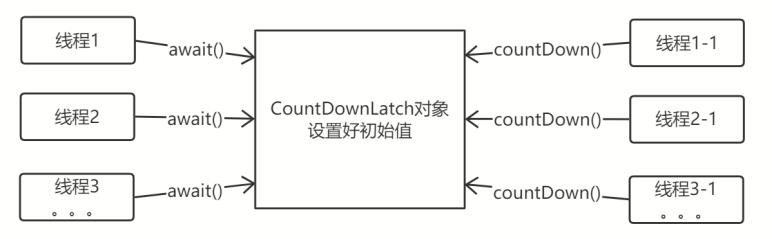
6.3 CyclicBarrier-循环屏障
6.3.1 CyclicBarrier 使用场景
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做 的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一 个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier使用方式比较简单:
//创建CyclicBarrier
CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
CyclicBarrier cyclicBarrier = new CyclicBarrier(3, new Runnable() {
@Override
public void run() {
// 当所有线程被唤醒时,执行Runnable。
System.out.println("do something");
}
});
//线程进入到屏障进行阻塞
cyclicBarrier.await();
实现阶段运行:
Main:
public class Main {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(3, new Runnable() {
@Override
public void run() {
System.out.println("finish");
}
});
for (int i = 0; i < 3; i++) {
new MyThread(cyclicBarrier).start();
}
}
}
MyThread:
public class MyThread extends Thread{
private final CyclicBarrier cyclicBarrier;
private final Random random = new Random();
public MyThread(CyclicBarrier cyclicBarrier){
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
try {
Thread.sleep(random.nextInt(2000));
System.out.println(Thread.currentThread().getName()+" A begin");
cyclicBarrier.await();
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName()+" B begin");
cyclicBarrier.await();
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName()+" C begin");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
在整个过程中,有2个同步点。只有所有的线程全部到达了同步点之后,最后一个进入的线程将唤醒所有被阻塞的线程。
6.3.2 CyclicBarrier实现原理
CyclicBarrier基于ReentrantLock+Condition实现

//该内部类用于表明当前循环屏障的状态,当broken为true时表示障碍器发生了异常
private static class Generation {
boolean broken = false;
}
//CyclicBarrier内部的显示锁
private final ReentrantLock lock = new ReentrantLock();
//通过上面的显式锁得到的Condition变量,障碍器能够阻塞和唤醒多个线程完全得益于这个Condition
private final Condition trip = lock.newCondition();
//临界值,当障碍器阻塞的线程数等于parties时即count=0,障碍器将会通过trip唤醒目前所有阻塞的线程
private final int parties;
//条件线程,当屏障被打破时,在障碍器通过trip唤醒所有正被阻塞的的线程之前,执行该线程,这个线程可以充当一个主线程,那些被阻塞的线程可以充当子线程,即可以实现当所有子线程都达到屏障时调用主线程的作用
private final Runnable barrierCommand;
//内部类Generation变量表示当前循环屏障CyclicBarrier的状态
private Generation generation = new Generation();
//计数器,用于计算还剩多少个线程还没有达到屏障处,初始值应该等于临界值parties
private int count;
构造方法:

await()方法实现过程:
//timed:表示是否设置了等待时间
//nanos等待的时间(纳秒)
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
//使用CyclicBarrier定义的显示锁,加锁避免并发问题
lock.lock();
try {
//当前循环屏障的状态
final Generation g = generation;
//如果为true,表示障碍器之前发生了异常,抛出异常BrokenBarrierException
if (g.broken)
throw new BrokenBarrierException();
//当前线程是否被中断
if (Thread.interrupted()) {
breakBarrier();//该方法会重置计数值count为parties,并且唤醒所有被阻塞的线程,并改变状态Generation
throw new InterruptedException();
}
//屏障计数器减一
int index = --count;
//如果index等于0 ,达到屏障的线程的数量等于最开始设置的数量parties
if (index == 0) { // tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
//如果条件线程不为空,则执行条件线程
if (command != null)
command.run();
ranAction = true;
//唤醒所有被阻塞的线程,并且重置计数器count,生成新的状态generation
nextGeneration();
return 0;
} finally {
if (!ranAction)//如果ranAction为true,表示上面的代码没有顺利执行结束,表示障碍器发生了异常,调用breakBarrier重置计数器,并设置generation.broken=true表示当前的状态
breakBarrier();
}
}
// 当计数器为零调用了Condition的唤醒方法、或者broken为true、或者线程中断、或者等待超时时跳出异常
for (;;) {
try {
//阻塞当前线程,如果timed为false表示没有设置等待的时间
if (!timed)
//不限时阻塞线程,只有当调用唤醒方法后才会继续执行
trip.await();
else if (nanos > 0L)
//等待nanos毫秒
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
//调用await方法如果发生异常,并且此时CyclicBarrier还没有调用nextGeneration()方法重置计数器和generation
if (g == generation && ! g.broken) {
breakBarrier();//该方法会唤醒所有阻塞的线程,并且重置计数器,而且设置generation.broken = true表示障碍器发生了异常。
throw ie;
} else {
//中断当前线程
Thread.currentThread().interrupt();
}
}
//g.broken为true,表示障碍器发生了异常,抛出异常
if (g.broken)
throw new BrokenBarrierException();
//index=0的唤醒操作顺利执行完了,所以通过nextGeneration()方法更新了generation,而由于generation是线程中的共享变量,所以当前线程此时 g!=generation
if (g != generation)
return index;
//如果timed为true表示设置了线程阻塞的时间,然后时间nanos却小于等于0,
if (timed && nanos <= 0L) {
breakBarrier();//此时重置计数器,并且设置generation.broken=true表示障碍器发生异常
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
//唤醒所有线程,重置计数器count,重新生成generation
private void nextGeneration() {
trip.signalAll();
count = parties;
generation = new Generation();
}
//设置generation.broken=true表示障碍器发生的异常,重置计数器count,唤醒所有阻塞的线程
private void breakBarrier() {
generation.broken = true;
count = parties;
trip.signalAll();
}
关于上面的方法,有几点说明:
-
CyclicBarrier是可以被重用的。以应聘场景为例,来了10个线程,这10个线程互相等待,到齐后一起被唤醒,各自执行接下来的逻辑;然后,这10个线程继续互相等待,到齐后再一起被唤醒。每一轮被称为一个Generation,就是一次同步点。
-
CyclicBarrier 会响应中断。10 个线程没有到齐,如果有线程收到了中断信号,所有阻塞的线程也会被唤醒,就是上面的breakBarrier()方法。然后count被重置为初始值(parties),重新开始。
-
breakBarrier()只会被第10个线程执行1次(在唤醒其他9个线程之前),而不是10个线程每个都执行1次。
6.4 Exchanger
6.4.1 使用场景
Exchanger用于线程之间交换数据,其使用代码很简单,是一个exchange(...)方法,使用示例如下:
public class Main {
private static final Random random = new Random();
public static void main(String[] args) {
// 建一个多线程共用的exchange对象
// 把exchange对象传给3个线程对象。每个线程在自己的run方法中调用exchange,把自己的数据作为参数
// 传递进去,返回值是另外一个线程调用exchange传进去的参数
Exchanger<String> exchanger = new Exchanger<>();
new Thread("线程1") {
@Override
public void run() {
while (true) {
try {
// 如果没有其他线程调用exchange,线程阻塞,直到有其他线程调 用exchange为止。
String otherData = exchanger.exchange("交换数据1");
System.out.println(Thread.currentThread().getName() + "得到<==" + otherData);
Thread.sleep(random.nextInt(2000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
new Thread("线程2") {
@Override
public void run() {
while (true) {
try {
String otherData = exchanger.exchange("交换数据2");
System.out.println(Thread.currentThread().getName() + "得到<==" + otherData);
Thread.sleep(random.nextInt(2000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
new Thread("线程3") {
@Override
public void run() {
while (true) {
try {
String otherData = exchanger.exchange("交换数据3");
System.out.println(Thread.currentThread().getName() + "得到<==" + otherData);
Thread.sleep(random.nextInt(2000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
}
}
在上面的例子中,3个线程并发地调用exchange(...),会两两交互数据,如1/2、1/3和2/3。
6.4.2 实现原理
Exchanger的核心机制和Lock一样,也是CAS+park/unpark。
park/unpark推荐阅读:https://www.cnblogs.com/set-cookie/p/9582547.html
首先,在Exchanger内部,有两个内部类:Participant和Node,代码如下:

每个线程在调用exchange(...)方法交换数据的时候,会先创建一个Node对象。
这个Node对象就是对该线程的包装,里面包含了3个重要字段:第一个是该线程要交互的数据,第二个是对方线程交换来的数据,最后一个是该线程自身。
一个Node只能支持2个线程之间交换数据,要实现多个线程并行地交换数据,需要多个Node,因此在Exchanger里面定义了Node数组:
private volatile Node[] arena;
6.4.3 exchange( V x )实现分析
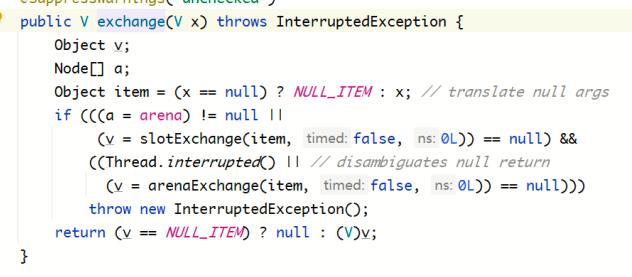
一对一交换数据使用slotExchange,其余情况使用arenaExchange。
上面方法中,如果arena不是null,表示启用了arena方式交换数据。如果arena不是null,并且线程被中断,则抛异常。
如果arena不是null,但是arenaExchange的返回值为null,则抛异常。对方线程交换来的null值是封装为NULL_ITEM对象的,而不是null。
如果slotExchange的返回值是null,并且线程被中断,则抛异常。
如果slotExchange的返回值是null,并且areaExchange的返回值是null,则抛异常。
slotExchange的实现:



arenaExchange的实现:




6.5 Phaser-移相器
6.5.1 用Phaser代替CyclicBarrier 和 CountDownLatch
从JDK7开始,新增了一个同步工具类Phaser,其功能比CyclicBarrier和CountDownLatch更加强大。
CyclicBarrier解决了CountDownLatch不能重用的问题,但是仍有以下不足:
1)不能动态调整计数器值,假如线程数不足以打破barrier,就只能reset或者多加些线程,在实际运用中显然不现实
2)每次await仅消耗1个计数器值,不够灵活
Phaser就是用来解决这些问题的。Phaser将多个线程协作执行的任务划分为多个阶段,每个阶段都可以有任意个参与者,线程可以随时注册并参与到某个阶段。
代替CountDownLatch:
public class PhaserInsteadOfCountDownLatch {
public static void main(String[] args) {
Phaser phaser = new Phaser(5);
for (int i = 0; i < 5; i++) {
new Thread("thread-"+(i+1)){
private final Random random = new Random();
@Override
public void run() {
System.out.println(getName()+" start");
try {
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName()+" end");
phaser.arrive();
}
}.start();
}
System.out.println("threads start finish");
phaser.awaitAdvance(phaser.getPhase());
System.out.println("threads end finish");
}
}
代替CyclicBarrier:
Main:
public class PhaserInsteadOfCyclicBarrier {
public static void main(String[] args) {
Phaser phaser = new Phaser(5);
for (int i = 0; i < 5; i++) {
new MyThread(phaser).start();
}
phaser.awaitAdvance(0);
}
}
MyThread:
public class MyThread extends Thread{
private final Phaser phaser;
private final Random random = new Random();
public MyThread(Phaser phaser){
this.phaser = phaser;
}
@Override
public void run() {
try {
System.out.println("start a");
Thread.sleep(500);
System.out.println("end a");
phaser.arriveAndAwaitAdvance();
System.out.println("start b");
Thread.sleep(500);
System.out.println("end b");
phaser.arriveAndAwaitAdvance();
System.out.println("start c");
Thread.sleep(500);
System.out.println("end c");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
arriveAndAwaitAdance()就是 arrive()与 awaitAdvance(int)的组合,表示“我自己已到达这个同步点,同时要等待所有人都到达这个同步点,然后再一起前行”。
6.5.2 Phaser新特性
-
动态调整线程个数
CyclicBarrier 所要同步的线程个数是在构造方法中指定的,之后不能更改,而 Phaser 可以在运行期间动态地调整要同步的线程个数。Phaser 提供了下面这些方法来增加、减少所要同步的线程个数。
-
层次Phaser
多个Phaser可以组成如下图所示的树状结构,可以通过在构造方法中传入父Phaser来实现。
public Phaser(Phaser parent, int parties){ //.... }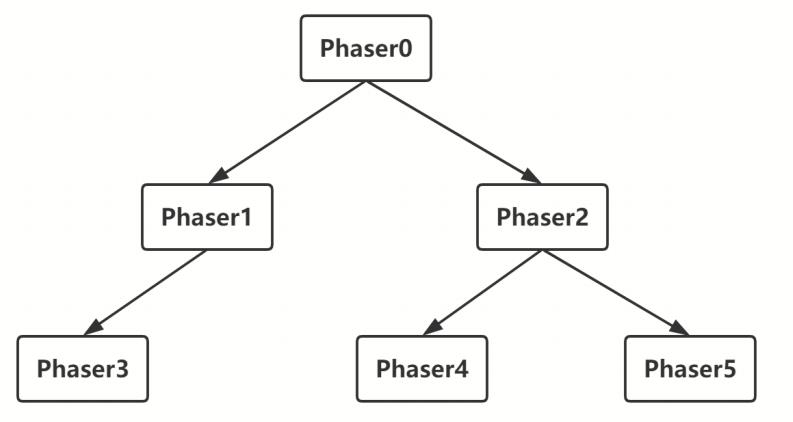
通过parent节点来存储树状结构:
private final Phaser parent;
可以发现,在Phaser的内部结构中,每个Phaser记录了自己的父节点,但并没有记录自己的子节点列表。所以,每个 Phaser 知道自己的父节点是谁,但父节点并不知道自己有多少个子节点,对父节点的操作,是通过子节点来实现的。
树状的Phaser怎么使用呢?考虑如下代码,会组成下图的树状Phaser。
Phaser root = new Phaser(2);
Phaser c1 = new Phaser(root,3);
Phaser c2 = new Phaser(root,2);
Phaser c3 = new Phaser(c1,0);
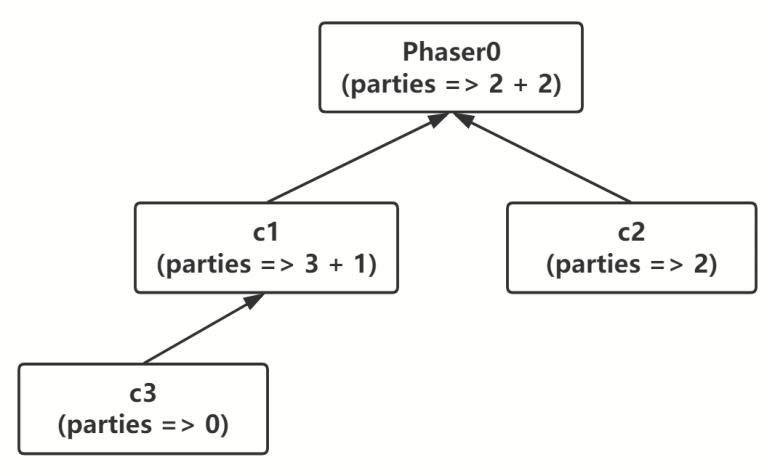
本来root有两个参与者,然后为其加入了两个子Phaser(c1,c2),每个子Phaser会算作1个参与者,root的参与者就变成2+2=4个。c1本来有3个参与者,为其加入了一个子Phaser c3,参与者数量变成3+1=4个。c3的参与者初始为0,后续可以通过调用register()方法加入。
对于树状Phaser上的每个节点来说,可以当作一个独立的Phaser来看待,其运作机制和一个单独的Phaser是一样的。
父Phaser并不用感知子Phaser的存在,当子Phaser中注册的参与者数量大于0时,会把自己向父节点注册;当子Phaser中注册的参与者数量等于0时,会自动向父节点解除注册。父Phaser把子Phaser当作一个正常参与的线程就即可。
6.5.3 state变量解析
大致了解了Phaser的用法和新特性之后,下面仔细剖析其实现原理。Phaser没有基于AQS来实现,但具备AQS的核心特性:state变量、CAS操作、阻塞队列。先从state变量说起。
private volatile long state;
这个64位的state变量被拆成4部分:
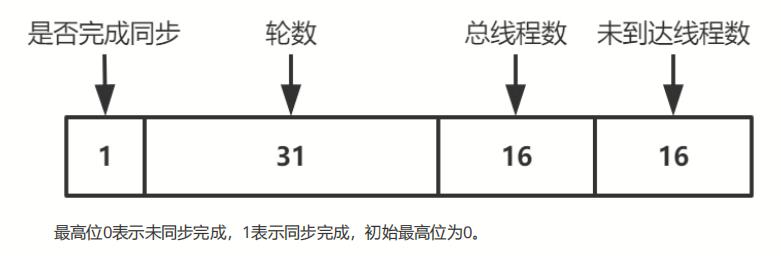
Phaser提供了一系列的成员方法来从state中获取上图中的几个数字。下面再看一下state变量在构造方法中是如何被赋值的:

其中,已经定义了:
private static final int EMPTY = 1;
private static final int PHASE_SHIFT = 32;
private static final int PARTIES_SHIFT = 16;
当parties=0时,state被赋予一个EMPTY常量,常量为1;
当parties != 0时,把phase值左移32位;把parties左移16位;然后parties也作为最低的16位,3个值做或操作,赋值给state。
6.5.4 阻塞与唤醒(Treiber Stack)
基于上述的state变量,对其执行CAS操作,并进行相应的阻塞与唤醒。如下图所示,右边的主线程会调用awaitAdvance()进行阻塞;左边的arrive()会对state进行CAS的累减操作,当未到达的线程数减到0时,唤醒右边阻塞的主线程。
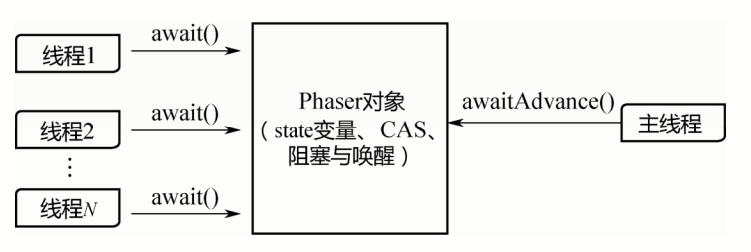
在这里,阻塞使用的是一个称为Treiber Stack的数据结构,而不是AQS的双向链表。Treiber Stack是一个无锁的栈,它是一个单向链表,出栈、入栈都在链表头部,所以只需要一个head指针,而不需要tail指针,如下的实现:
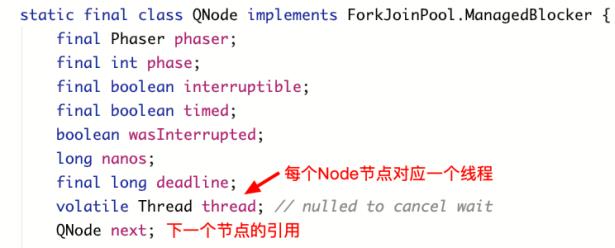

为了减少并发冲突,这里定义了2个链表,也就是2个Treiber Stack。当phase为奇数轮的时候,阻塞线程放在oddQ里面;当phase为偶数轮的时候,阻塞线程放在evenQ里面。代码如下所示:
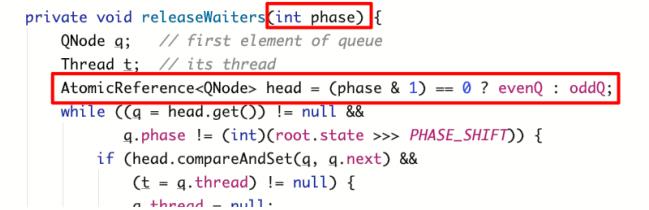
6.5.5 arrive() 方法分析
下面看arrive()方法是如何对state变量进行操作,又是如何唤醒线程的。
其中,定义了变量:
private static final int ONE_ARRIVAL = 1;
private static final int ONE_PARTY = 1 << PARTIES_SHIFT;
private static final int ONE_DEREGISTER = ONE_ARRIVAL\\ONE_PARTY;
private static final int PARTIES_SHIFT = 16;
arrive()和 arriveAndDeregister()内部调用的都是 doArrive(boolean)方法。
区别在于前者只是把“未达到线程数”减1;后者则把“未到达线程数”和“下一轮的总线程数”都减1。下面看一下doArrive(boolean)方法的实现。


关于上面的方法,有以下几点说明:
- 定义了2个常量如下。当 deregister=false 时,只最低的16位需要减 1,adj=ONE_ARRIVAL;当deregister=true时,低32位中的2个16位都需要减1,adj=ONE_ARRIVAL|ONE_PARTY。
- 把未到达线程数减1。减了之后,如果还未到0,什么都不做,直接返回。如果到0,会做2件事情:第1,重置state,把state的未到达线程个数重置到总的注册的线程数中,同时phase加 1;第2,唤醒队列中的线程。
下面看一下唤醒方法:

遍历整个栈,只要栈当中节点的phase不等于当前Phaser的phase,说明该节点不是当前轮的,而是前一轮的,应该被释放并唤醒。
6.5.6 awaitAdvance()方法分析

下面的while循环中有4个分支:
初始的时候,node==null,进入第1个分支进行自旋,自旋次数满足之后,会新建一个QNode节点;
之后执行第3、第4个分支,分别把该节点入栈并阻塞。


这里调用了ForkJoinPool.managedBlock(ManagedBlocker blocker)方法,目的是把node对应的线程阻塞。ManagerdBlocker是ForkJoinPool里面的一个接口,定义如下:

QNode实现了该接口,实现原理还是park(),如下所示。之所以没有直接使用park()/unpark()来实现阻塞、唤醒,而是封装了ManagedBlocker这一层,主要是出于使用上的方便考虑。一方面是park()可能被中断唤醒,另一方面是带超时时间的park(),把这二者都封装在一起。

理解了arrive()和awaitAdvance(),arriveAndAwaitAdvance()就是二者的一个组合版本。
以上是关于并发编程从零开始(十五)-CompletableFuture的主要内容,如果未能解决你的问题,请参考以下文章