nodejs:使用puppeteer在服务器中构建一个获取电影电视剧剧集的接口
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nodejs:使用puppeteer在服务器中构建一个获取电影电视剧剧集的接口相关的知识,希望对你有一定的参考价值。
首先我们看下数据来源:
来源于这个网站:https://z1.m1907.cn/
可以说这个网站上能找到很多你想看的很多电影或电视剧,最重要的是很多电影电视剧在别的网站是收费的,但是在这里看是免费的,之前也经常在这个网站中看。
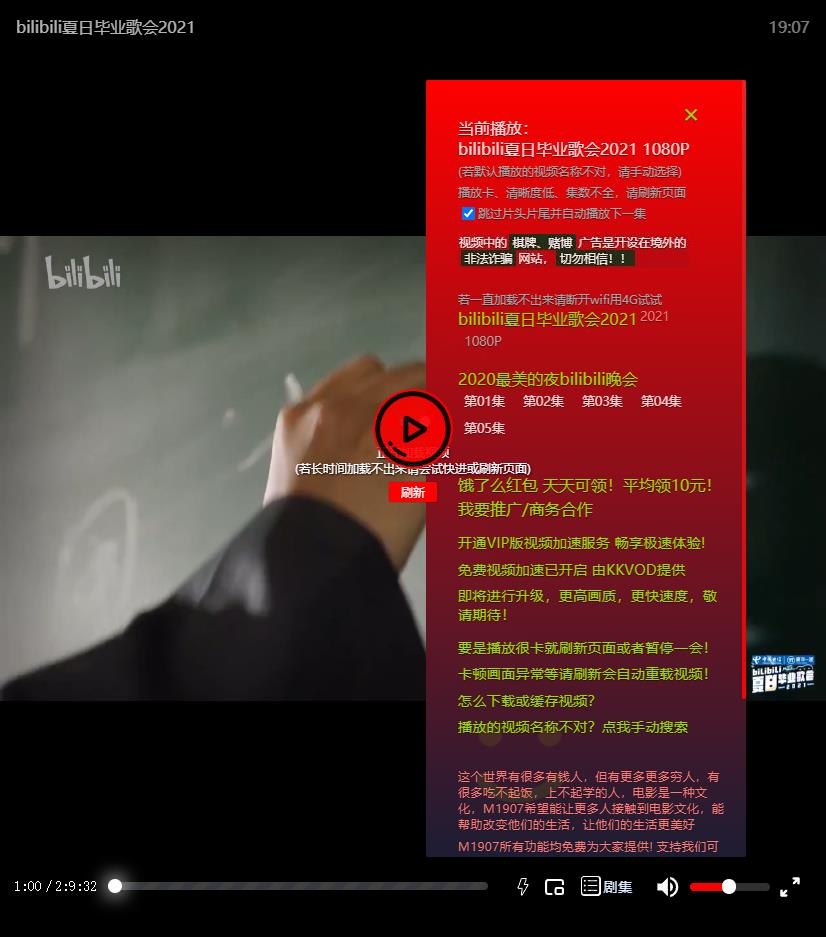
不过这个网站有些缺点:在微信中被屏蔽了网址。在夸克浏览器上如果播放到某集,夸克播放器就会覆盖掉原生播放器,导致切换下一集时不好切换过去,因此,希望能开发一个自己的网站,获取该网站的数据来呈现。
一般来说,我们只需要拿到这些数据的url接口就行了。但是看了这个网站的network请求,发现这个接口的某个参数是可变的,而且还是必须要的。
这个url就算获取视频列表的接口,但是中间的z参数是必填的,而且每过一段时间就需要更换参数。
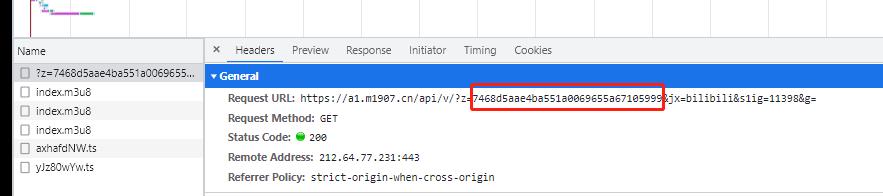
这个参数它不来源于上一个接口的某个结果,它是通过js进行了md5之后生成的。这就难办了。怎么去获取这个值呢?
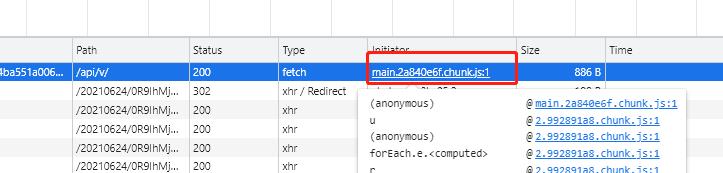
我们点击这里,然后点击这个小图标
断点发现,生成z参数的就是这个p变量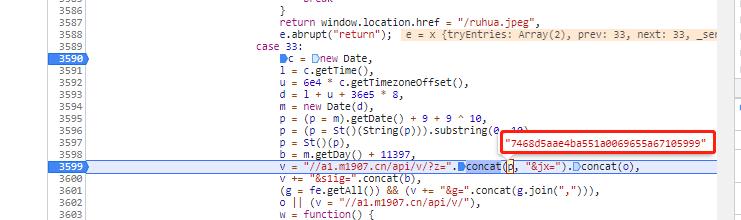 。
。
然后,因为内部代码已被压缩,所以不好理清楚里面的逻辑了,所以就采用了fiddler抓包工具,将这个js文件进行代理到本地js中。篡改js文件做一些外加功能。
我使用fiddler代理篡改了这段代码,就是将这个z参数显示在dom中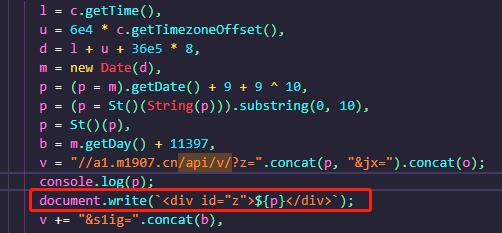 。
。
因此,dom中就有了这么一个dom元素,那么这有什么用呢?这样我就能在自己的服务器中拿到这个值?
是的,我使用的是nodejs。前段时间在网上找到了一个有意思npm包,用来在服务器中模拟浏览器操作,自然在服务器中就能获取到浏览器中渲染的dom了。那就是标题里说的puppeteer。
因为之前用fiddler代理将这个只放在了dom中,因此我们也就可以使用puppeteer模块从dom中拿到这个值,曲线救国。
请看实现(使用koajs服务端,ctx.response.body即可输出这个z参数)
const puppeteer = require(\'puppeteer\'); /** * 获取https://z1.m1907.cn/的动态z 需求开fiddler */ module.exports = async(ctx) => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(\'https://z1.m1907.cn/?jx=bilibili\'); //注入脚本 const dimensions = await page.evaluate(async() => { let z = \'\' if (document.querySelector(\'#z\')) { z = document.querySelector(\'#z\').innerText; } return { z, } }); await browser.close(); ctx.response.body = dimensions; return dimensions;//这个return是给下一个接口调用的 }
page.evaluate可以将浏览器的js代码注入到dimensions的隐藏浏览器中。就能通过document.querySelector(\'#z\').innerText拿到那个z参数,然后通过node返回了。
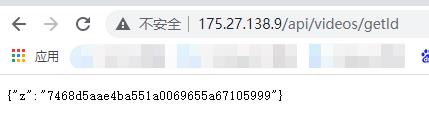 拿到了。这个数据一般能使用几个小时,几个小时后又需要重新获取新的值了,重新执行接口即可。
拿到了。这个数据一般能使用几个小时,几个小时后又需要重新获取新的值了,重新执行接口即可。
拿到这样要获取数据就容易多了。
看后续写法:
const { loadPage } = require(\'../../utils/utils\');
const getId = require(\'./getId\');
const setting = require(\'./setting\');
/**
* 主程序
*/
const videos = async(ctx) => {
const { title = \'bilibili\', z = null } = ctx.query
// console.log(setting.z)
z && (setting.z = z); //手动输入z参数
const content = await loadPage(`https://a1.m1907.cn/api/v/?z=${setting.z}&jx=${title}&s1ig=11402&g=`);
if (content.includes(\'获取json版api地址\')) {//获取数据错误 重新获取z参数
const obj = await getId(ctx);
console.log(obj)
setting.z = obj.z
await videos(ctx)
return;
}
ctx.response.body = content;
}
module.exports = videos;
loadPage是封装的请求页面的方法,getId是之前用于返回z参数的方法,setting是用于储存获取到的z参数,失效了才重新获取。
这样就能返回数据了。
访问接口,拿到当前电视剧/电影的所有剧集的m3u8播放地址,这样在支持m3u8的播放器中就可以直接播放了。
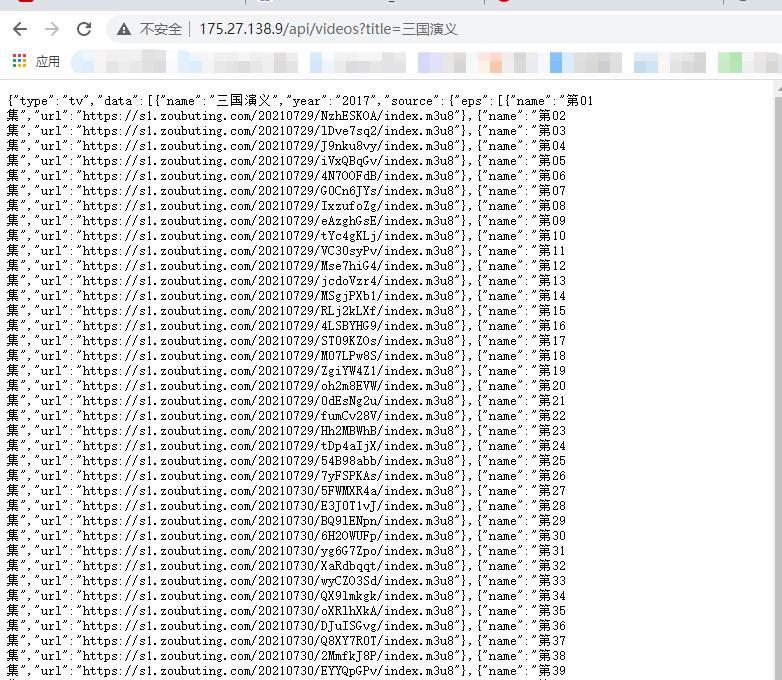
(完)
朋友,看到这里,用支付宝扫码领个红包吧!实体店付款可以优惠哦!

请认准【http://wuhairui.cnblogs.com/】
Nodejs中puppeteer抓取浏览器HAR数据
有这么一个需求,首先从csv文件中读取要解析的url数据,然后使用puppeteer和puppeteer-har来获取浏览器的HAR数据。在调试的过程中,发现在for循环中怎么操作都是异步的,最后找到了一个解决方案,也算在此记录。
har.js
const puppeteer = require(‘puppeteer‘);
const PuppeteerHar = require(‘puppeteer-har‘);
/*
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const har = new PuppeteerHar(page);
await har.start({ path: ‘results.har‘ });
await page.goto(‘http://example.com‘);
await har.stop();
await browser.close();
})();
*/
async function saveHarlog(url,filename){
//启动浏览器实例 [puppeteer.createBrowserFetcher([options])]
let browser = await puppeteer.launch({
// 若是手动下载的chromium需要指定chromium地址, 默认引用地址为 /项目目录/node_modules/puppeteer/.local-chromium/
//executablePath: ‘/Users/huqiyang/Documents/project/z/chromium/Chromium.app/Contents/MacOS/Chromium‘,
//设置超时时间
timeout: 15000,
//如果是访问https页面 此属性会忽略https错误
ignoreHTTPSErrors: true,
// 关闭headless模式, 不会打开浏览器
headless: false,
args:["--disk-cache-size=0","--disable-cache",‘--disable-infobars‘],
//是否为每个选项卡自动打开DevTools面板。 如果此选项为true,则headless选项将设置为false。
devtools:false
});
//创建一个新页面
let page = await browser.newPage();
//Puppeteer 初始化的屏幕大小默认为 800px x 600px。但是这个尺寸可以通过 Page.setViewport() 设置。
await page.setViewport({
width: 800,
height: 600
});
let har = new PuppeteerHar(page);
await har.start({ path: (filename +‘.har‘) });
await page.goto(url);
// Get the "viewport" of the page, as reported by the page.
let dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio
};
});
await har.stop();
await browser.close();
}
exports.saveHarlog = saveHarlog;
cvsresovler.js
const fs = require("fs");
const path = require("path");
const csv =require(‘csv‘);
const parse = require(‘csv-parse/lib/sync‘)
const iconv = require(‘iconv-lite‘);
/*
npm install iconv-lite
*/
function readUrlRecord(csvpath){
console.log(‘开始解析文件:‘ + csvpath) ;
//读取文件
const input = fs.readFileSync(csvpath,‘utf8‘) ;
/*
解析文件,生成JSON格式
{ ‘ ‘: ‘142‘,
AREA_NAME: ‘湖北‘,
SITE_LINK: ‘www.banggo.com‘,
BEARING_MODE: ‘移动接入‘,
SITE_NAME: ‘邦购‘,
MENU_TYPE: ‘二级‘ }
*/
const records = parse(input, {
columns: true,
skip_empty_lines: true,
delimiter: ‘,‘,
}) ;
return records ;
}
//readUrlRecord(‘../top300.csv‘) ;
exports.readUrlRecord = readUrlRecord;main.js
const fs = require("fs");
const path = require("path");
const moment = require("moment");
const schedule = require(‘node-schedule‘);
const cvsresovler=require("./module/cvsresovler");
const mhar=require("./module/har");
/*
cnpm install --save moment
cnpm install --save csv
cnpm install --save node-schedule
cnpm install --save puppeteer
cnpm install --save puppeteer-har
cnpm install --save iconv-lite
*/
function init(){
console.log(‘初始化调度器‘) ;
//每分钟的第30秒定时执行一次:
schedule.scheduleJob(‘0 21 * * * *‘,()=>{
let ftime = moment().format(‘YYYYMMDDHHmm‘);
console.log(‘当前调度时间为:‘ + ftime) ;
let dirPath = path.join(__dirname,‘harlogs‘,ftime) ;
console.log("创建目录:" + dirPath) ;
let isExist = false ;
if(fs.existsSync(dirPath)){
//创建文件夹
let stat = fs.lstatSync(dirPath);
if(stats.isDirectory()){
isExist = false ;
}
}
if(!isExist){
//创建文件夹
console.log("创建文件夹" + ftime) ;
fs.mkdirSync(dirPath);
}
//开始解析需要处理的URL
let dataArr = cvsresovler.readUrlRecord(path.join(__dirname,‘top300.csv‘)) ;
console.log("解析出URL共计" + dataArr.length + "条") ;
/*
开始抓取HAR数据【同步的方式执行】。
注意:如果这里直接通过for循环遍历dataArr并调用saveHarlog方法,那么这将是一个异步的过程。
*/
(async function iterator(i){
let data = dataArr[i]
let url = data[‘SITE_LINK‘] ;
console.log("开始处理:" + url ) ;
await mhar.saveHarlog(‘http://‘ + url,path.join(dirPath,url.replace(‘/‘,"-"))) ;
if(i + 1 < dataArr.length){
iterator(i+1) ;
}
})(0) ;
});
console.log(‘应用程序启动完成‘) ;
}
//执行
init();以上是关于nodejs:使用puppeteer在服务器中构建一个获取电影电视剧剧集的接口的主要内容,如果未能解决你的问题,请参考以下文章