1029-实体分析与部分实体构建
Posted 清风紫雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1029-实体分析与部分实体构建相关的知识,希望对你有一定的参考价值。
实体分析
实体
如何找出自己想求得的知识图谱的实体,在我看来一个实体所独有的是他的属性,其他实体也包含的就是实体。因而,我对诗词进行了实体-实体,实体-属性的分类。
如下图所示:
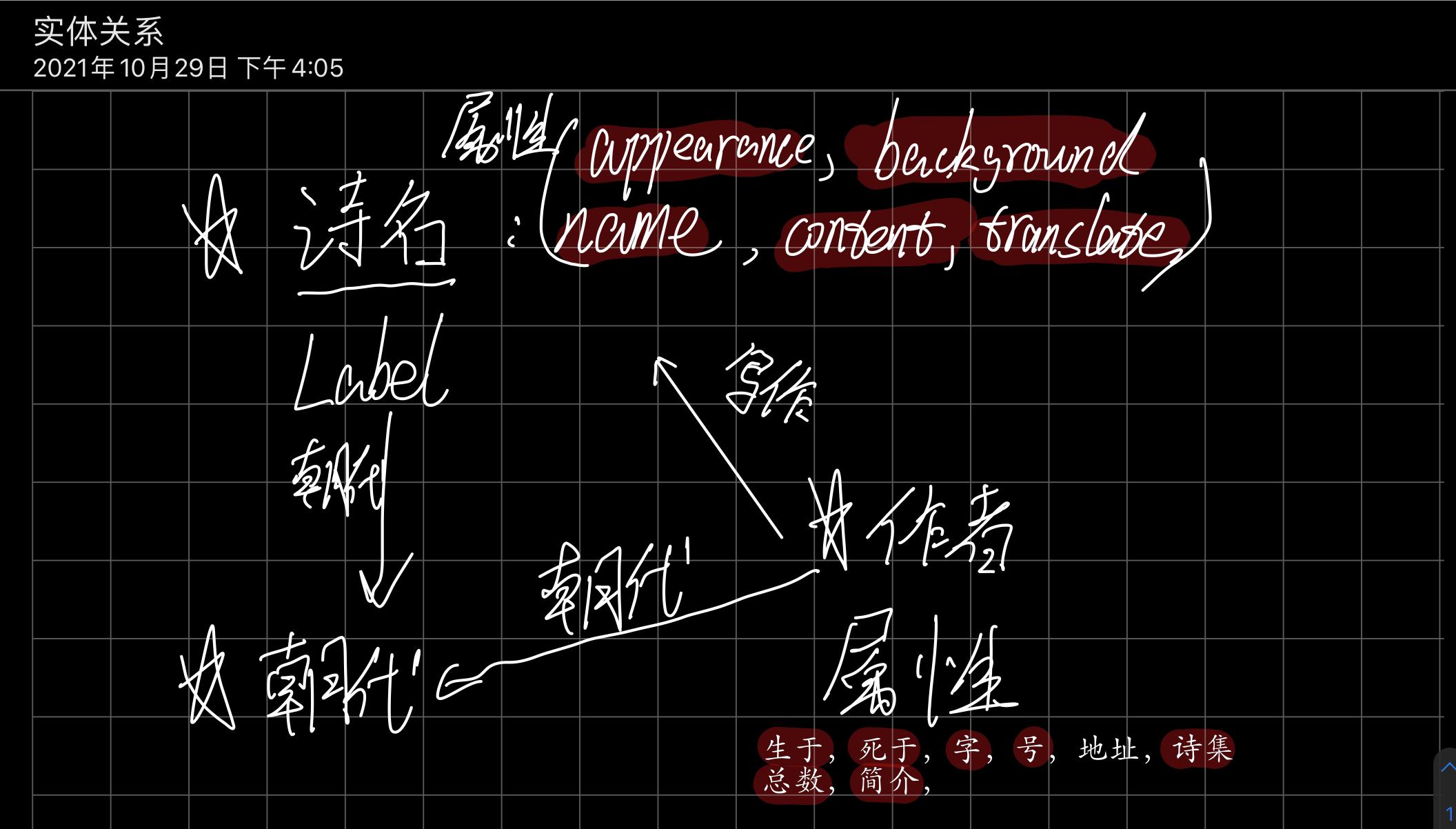
除了明显的实体之外,我还构思出一些潜在的实体,如下:诗名-类别(写山,抒情,思念等等),诗名-词牌名,诗词中的一句-飞花令中的关键字(月,人,花),诗人-诗人合成(唐宋八大家)

实体属性清洗
对诗人进行清洗,找出生于,去世于,字,号,诗词总量,诗人简介这类属性信息
诗人数据格式:

对数据进行清洗,代码如下
def update_author():
label2 = "author"
file = "author.xlsx"
data = pd.read_excel(file).fillna("无")
produce = list(data.produce)
# 获取诗人名字
name = list(data.author)
bg = []
ed = []
zi = []
hao = []
pome_self = []
# 获取诗人诗集数目
num = list(data.num)
for it in produce:
# 获取诗人个人简介
pome_self.append(it)
# 获取诗人出生,去世的年份
datas = re.findall(r"\\d+", it)
if len(datas) != 0 and len(datas) != 1:
bg.append(datas[0] + "年")
# print("生于"+datas[0])
flag = False
for j in range(1, len(datas)):
if len(datas[j]) >= len(datas[0]) and int(datas[j]) - int(datas[0]) > 15:
ed.append(datas[j] + "年")
# print("死于"+datas[j])
flag = True
break
if flag == False:
ed.append("无")
else:
bg.append("无")
ed.append("无")
# 获取诗人,字,号
ztext = re.findall(r".*字(.*?)[,|。]", it)
if len(ztext) != 0:
zi.append(ztext)
else:
zi.append("无")
# print(ztext)
htext = str(re.findall(r".*号(.*?)[,|。]", it)).replace(\'“\', \'\').replace(\'”\', \'\')
if len(htext) != 0:
hao.append(htext)
else:
hao.append("无")
for i in range(len(zi)):
attr={"name":name[i]}
newattr={"name":name[i],"生于":bg[i],"去世于":ed[i],"字":zi[i],"号":hao[i],"数目":num[i],"简介":pome_self[i]}
if updateNode(graph,label2,attr,newattr)==False:
print("没有该诗人"+name[i])
CreateNode(graph,label2,newattr)
neo4j数据导入
基础的neo4j数据导入函数:
# 创建节点
def CreateNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\\\'"+m_attrs[\'name\']+"\\\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
print(re_value)
if re_value is None:
m_mode = Node(m_label,**m_attrs)
n = graph.create(m_mode)
return n
return None
# 查询节点
def MatchNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\\\'"+m_attrs[\'name\']+"\\\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
return re_value
# 创建关系
def CreateRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph,m_label1,m_attrs1)
reValue2 = MatchNode(m_graph,m_label2,m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1,m_r_name,reValue2)
n = graph.create(m_r)
return n
#查找关系
def findRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1, m_r_name[\'name\'], reValue2)
return m_r
#修改节点属性
def updateNode(m_graph,m_label1,m_attrs1,new_attrs):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
if reValue1 is None:
return False
reValue1.update(new_attrs)
graph.push(reValue1)
创建诗名实体,诗人实体,朝代实体,构建对应的关系。此处导入的仅为唐朝诗集
诗人-创作-诗名,诗人-所属朝代-朝代,诗名-所属朝代-朝代
def get_data():
#title = [], desty = [], author = [], content = [], trans_content = [], appear = [], background = []
file = \'tang.xlsx\'
data = pd.read_excel(file).fillna("无")
title = list(data.title)
desty=list(data.desty)
author=list(data.author)
content=list(data.content)
trans_content=list(data.trans_content)
appear=list(data.appear)
background=list(data.background)
label1="pome"
label2="author"
label3="desty"
for i in range(len(title)):
if title[i]==" nan":
title[i]=""
if content[i]==" nan":
content[i]=""
if trans_content[i]==" nan":
trans_content[i]=""
if appear[i]==" nan":
appear[i]=""
if background[i]==" nan":
background[i]=""
attr1={"name":title[i],"content":content[i],"trans_content":trans_content[i],"appear":appear[i],"background":background[i]}
CreateNode(graph, label1, attr1)
attr2 = {"name": author[i]}
if MatchNode(graph,label2,attr2)==None:
CreateNode(graph, label2, attr2)
attr3 = {"name": desty[i]}
CreateNode(graph, label3, attr3)
m_r_name = "创作"
reValue = CreateRelationship(graph,label2,attr2,label1,attr1,m_r_name)
m_r_name2 = "朝代"
reValue2 = CreateRelationship(graph, label1, attr1, label3, attr3, m_r_name2)
print(reValue)
print(reValue2)
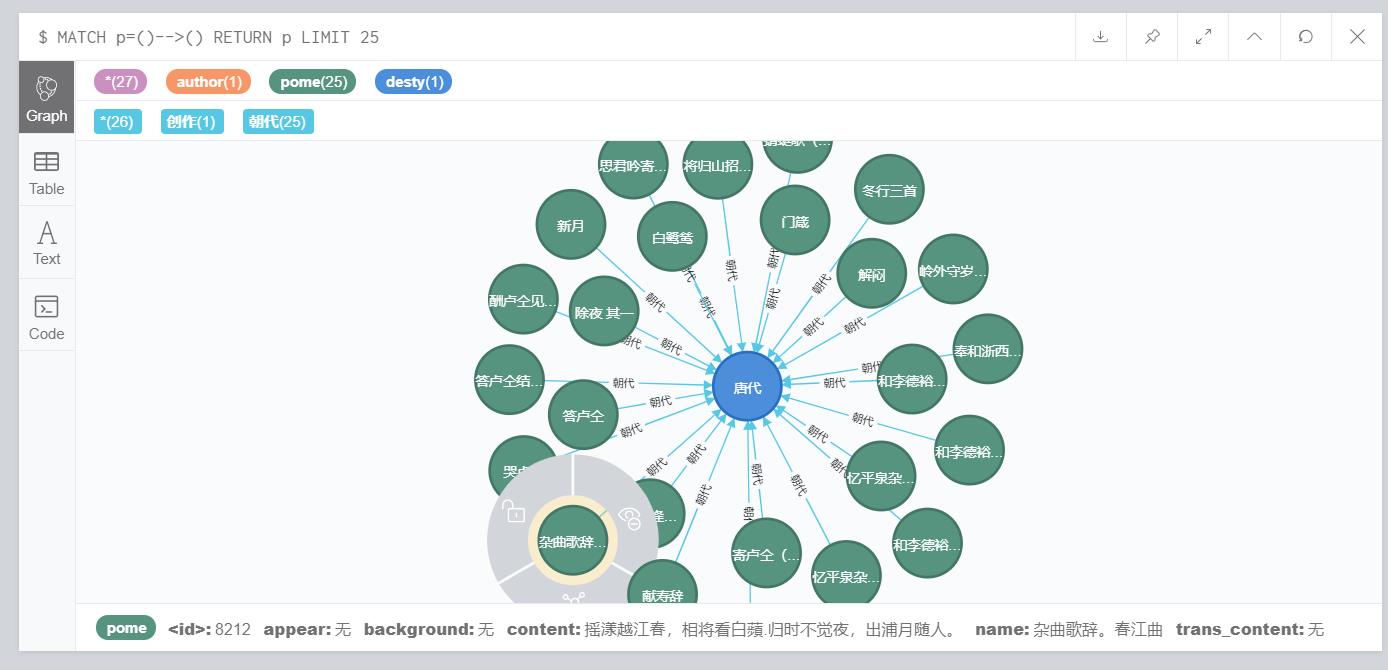
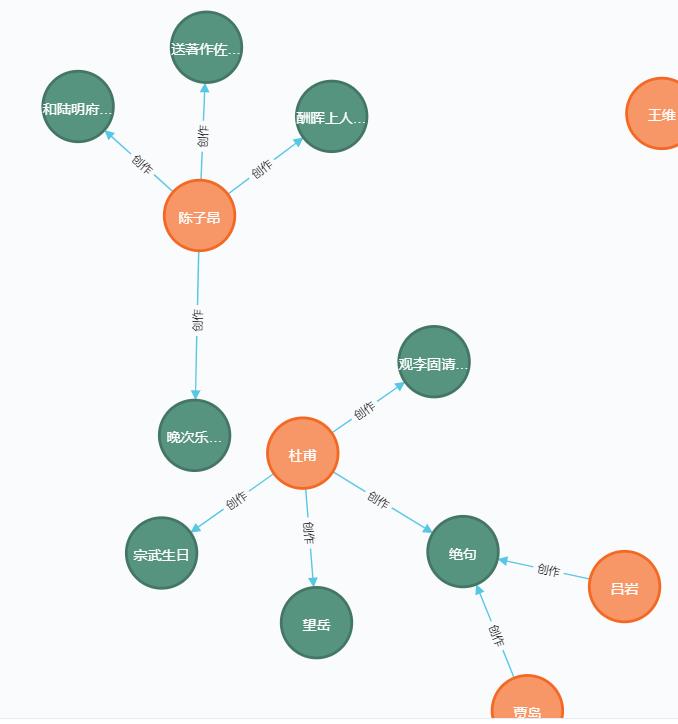
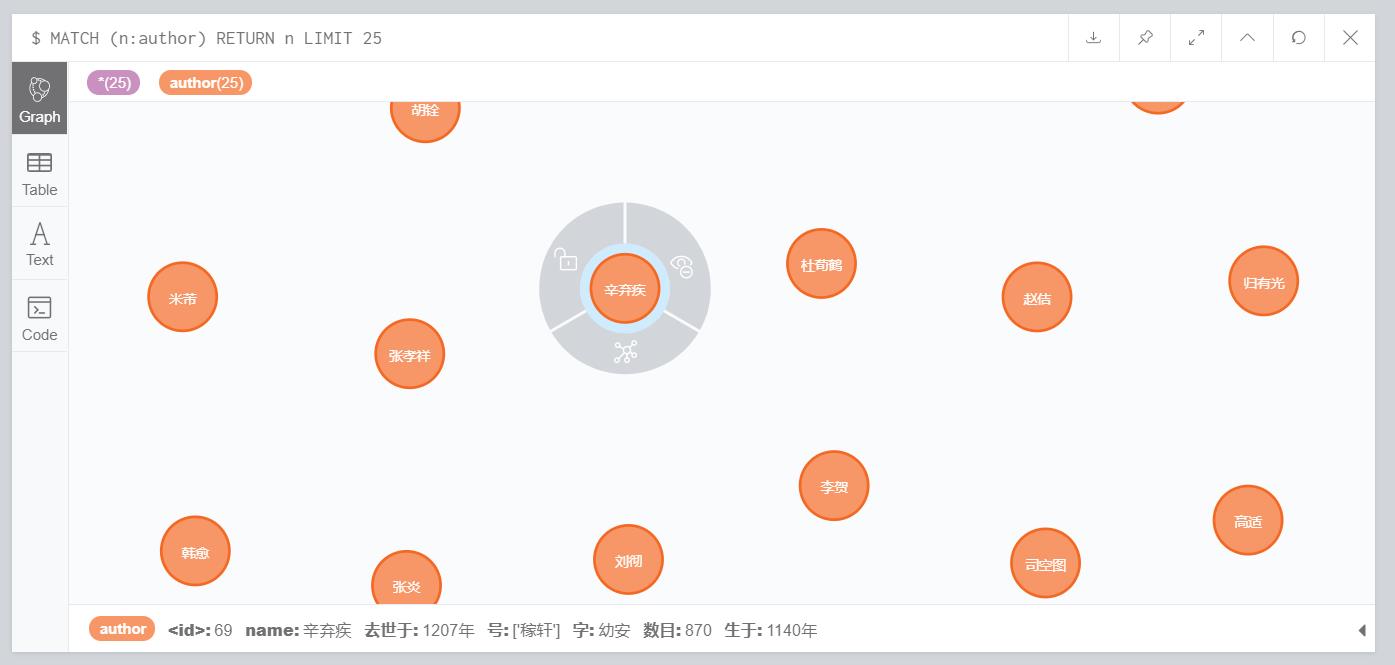
成果展示
构建之法第十一章读后感
本周进行了构建之法的第十一章软件设计与实现的学习;
第十一章主要讲了典型的开发流程,常见的分析和设计方法:ERD,DFD,UML,开发阶段的一些管理方法:每日构建,小强地狱,构建大师;
分析和设计方法包括以文字为主的文档,以图形为主构造的模型,用数学语言的描述,用类自然语言+代码构造的描述,原代码加注释也能描述;
图形模型和分析方法;1表达实体与实体之间的关系如思维导图,实体关系图,Use Case Diagram。2.表达数据的流动。3.表达控制流。4.统一的表达方式。
其他的设计方法包括形式化的方法,文学化编程。
开发阶段的日产管理包括以下问题:闭门造车,每日构建,构建大师,宽严皆误,小强地狱。
然后关于要做的四则运算应用程序,我们初步研究了一下要求和目的。我们需要做的是编一个代码使其可以完成加减乘除的真分数的运算,还要具有退格和清屏的功能,可以让用户输入,程序判断对错。以及在多运算符计算和倒计时中间选一个。我们目前尚未编出代码,做出GUI对我们有一定的难度。但我们会尽最大的努力完成这个项目。
以上是关于1029-实体分析与部分实体构建的主要内容,如果未能解决你的问题,请参考以下文章