一文读懂Android进程及TCP动态心跳保活
Posted xiaxveliang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂Android进程及TCP动态心跳保活相关的知识,希望对你有一定的参考价值。
一直以来,APP进程保活都是 各软件提供商 和 个人开发者 头疼的问题。毕竟一切的商业模式都建立在用户对APP的使用上,因此保证APP进程的唤醒,提升用户的使用时间,便是软件提供商和个人开发者的永恒追求。
面对国内GCM(Google Cloud Messaging)推送服务不可用,也未出现一个统一市场PUSH平台的现状。早期的第三方软件一般通过维持一个终端与远端服务器之间的TCP长连接,达到PUSH拉活和消息及时送达的目的。
而为了维持这个TCP长连接不断开,前提条件就是保证自己APP的后台服务进程,不会被杀死(因为只有活着的终端进程才能定期与远端服务器通信,保证长连接不断连)。
因此在android发布的早期,各种技术论坛和GitHub出现了五花八门、各显神通的App进程保活方案;如今随着Android系统的逐渐完善,各种进程保活方案不断受到限制,想要做到Android进程保活已经不太容易。
一般来说,Android进程保活主要有以下两方面工作:
- 进程保活:保持
进程不被系统杀死或进程被杀后可以重新拉起。
早期Android,对于后台运行的Service服务进程限制较小,第三方软件保证自己APP后台服务进程长时间运行相对容易,但仍然是有被系统杀死的可能。
这个阶段随着APP的不断增多,许多第三方APP开始利用系统漏洞(早期的Android系统尚不完善,可利用的漏洞较多),在APP进入后台或系统准备休眠时,通过各种所谓的黑科技(实际为流氓手段)保证自己的APP进程不被杀死,甚至阻止系统休眠。
伴随随着这类软件的不断增多,最终造成的结果是,用户侧手机卡顿、待机时间短、耗电量增加。 - TCP保活:保证
终端与远端服务器之间的TCP长连接不断连。
在App进程保活的基础上,一般通过使用Android系统RCT时钟 Alarm每5~10分钟唤醒一次系统,并发送一条只有几个字节的TCP保活消息,来维持终端与远端服务器之间的TCP长连接不断开。
一、Android早期进程保活
这里简单回顾一下,Android早期App进程保活的各种方案。
- 通过Service的onStartCommand方法中返回
START_STICKY:
当Service的onStartCommand方法返回START_STICKY时,若当前Service因内存不足被系统清理掉,待内存再次空闲时,系统将会尝试重新创建此Service,一旦创建成功后将回调onStartCommand方法,但其中的Intent将是NULL。 - 1像素透明Activity进程保活:
监测到Android系统息屏时,启动一个1像素的前台透明Activity,欺骗系统,使其认为该应用为一个前台应用而不会被清理(据说淘宝早期就使用过这种方案)。 - 开启前台服务:
利用系统漏洞,创建一个不包含系统通知栏或透明系统通知栏的前台服务,提升App进程的系统优先级,使其不被系统清理。 - Fork Native守护进程:
Android 5.0 以前,App内部 fork 出来的native进程不受系统管控。系统在杀死 App进程时,只会杀死对应的Java进程。
因此诞生了一大批流氓软件,通过fork native进程,在 App 的 Java 进程被杀死的时候,通过 ActivityManager 重新拉起被杀死的进程,从而达到“进程永生”的目的(这个方案据说最初由360提出,后来大家纷纷效仿)。 - 通过其他活跃App拉起:
进程保活的后期,又出现一种进程保活的方案。
多个App组成一个联盟,只要有一个App被用户使用,其他所有联盟内的App进程都会被拉起,以此来保证消息的及时到达。
例如:集成个推、极光推送的App,可以通过前台活跃的App拉起不活跃的App进程,提升所有集成个推、极光推送的第三方App推送消息的到达率。
注:
当前随着Android系统的不断完善,以上方案大多不再有效。
二、Android各版本后台进程限制
Android系统源码的开放,加之早期的系统尚不完善,众多应用软件提供商通过对AOSP各版本源码的深入解读,提出了各种所谓黑科技的保活方案,保证自己的应用程序进程不被系统清理。这段时期可谓是魑魅横行、群魔乱舞;Android手机用户则是苦不堪言,Android手机卡顿、待机时间短等问题也为人所诟病。
随着Android系统的不断完善,Google和国内终端手机厂商也对Android系统做了很多的改进,如今已经基本封死了第三方应用各种所谓黑科技流氓保活方案。
- Android后台进程限制;
- 国内手机厂商后台进程限制;
2.1 Android后台进程限制
如今Google每年发布的AOSP(Android Open Source Project)新版本中,每个版本均不断增加后台服务进程限制的相关条款,一方面是为了限制第三方App后台服务进程的运行,节省用户手机资源与电量消耗;另一方面,增加后台服务进程限制也是在保护用户的隐私。
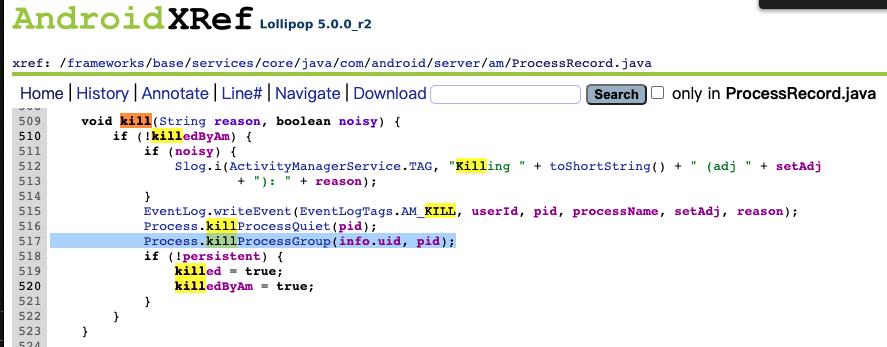
Android 5.0 开始,Android系统开始以uid为标识,查杀APP进程组,通过杀死整个进程组来杀死App进程,因此通过fork native 进程守护App进程这种方式从此不再有效。
Android 6.0开始,引入了Doze模式用户拔下设备的电源插头,并在屏幕关闭后的一段时间后,设备会进入Doze模式。
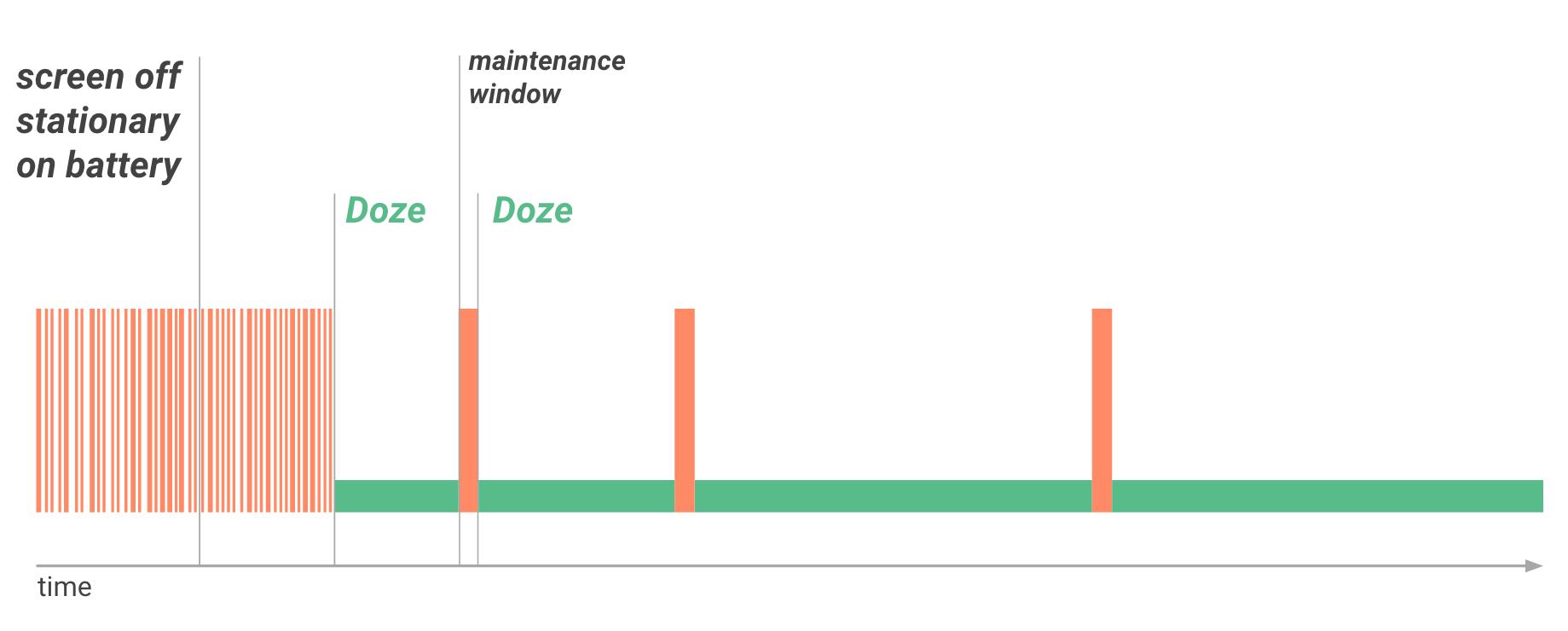
- 在Doze模式下,系统会尝试通过限制应用访问网络和 占用CPU资源的措施来节省电量,阻止应用访问网络,并延迟作业与Alarm闹钟。
- 系统会定期退出Doze模式一小段时间,让应用完成其延迟的活动。在此维护期内,系统会运行所有待处理的同步操作、Alarm闹钟,并允许应用访问网络。
- 随着时间的推移,系统进入维护期的次数越来越少,这有助于在设备未连接至充电器的情况下长期处于Doze模式状态降低耗电量。
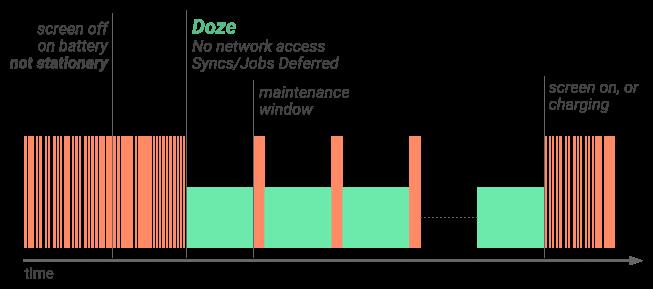
Android 7.0开始,加强了Doze模式,进入Doze模式不再要求设备静止状态。
只要屏幕关闭了一段时间,且设备未插入电源,设备就会进入Doze模。
Android 8.0开始,加强了应用后台执行限制:
- 不能再通过
startService创建后台服务,否则将抛出异常;但可通过Context.startForegroundService()方法启动一个带通知栏提醒的前台服务; - 应用处于后台时,会对后台应用检索用户当前位置信息的频率进行限制。应用每小时仅接收几次位置信息更新。
- 广播限制:第三方应用将无法通过在
AndroidManifest注册静态广播来接收大部分的系统隐式广播,以减少App对手机的唤醒,从而节省手机的电量;动态注册不受影响。
Android 9.0开始,进一步加强了应用后台执行限制:
- 后台应用不再可以访问麦克风和摄像头,传感器(加速度传感器、陀螺仪);
- 创建前台服务需要申请普通权限:
FOREGROUND_SERVICE。
Android 10开始,再进一步加强了应用后台执行限制:
- 应用在后台运行时,访问手机位置需要动态申请
ACCESS_BACKGROUND_LOCATION权限,用户则可以选择拒绝; - 应用在后台运行时,对后台应用启动Activity进行限制(运行前台服务的应用仍然会被应用看做“后台”应用)。
Android 11开始,再进一步完善了应用后台访问位置限制:
- 在Android11设备上,对于targetSdkVersion=30(Android 11)的应用,需先申请前台位置权限,后申请后台位置权限。
- 在Android11设备上,对于targetSdkVersion=30(Android 11)的应用,同时申请前台、后台位置权限时,系统会忽略该请求,无任何响应(需首先获取前台位置权限,再次申请后台位置权限)。
- 在Android11设备上,对于targetSdkVersion<=29(Android 10)的应用,同时申请前台、后台位置权限时,对话框不再提示始终允许字样,而是提供了位置权限的设置入口,需要用户在设置页面选择始终允许才能获得后台位置权限。
2.2 手机厂商后台进程限制
Google新发布的各版本主要还是限制第三方App后台进程服务的运行,而国内各终端厂商则在AOSP的基础上增加了Alarm的限制。
国内手机厂商(华米OV等)在手机系统休眠后,第三方App注册的Alarm定时唤醒闹钟几乎全部无效!!!
“Google的后台进程限制” 与 “国内手机厂商Alarm限制”相叠加的双重影响是:
彻底封死了 “第三方手机软件” 利用 “Alarm闹钟” 定时唤醒手机系统,维持 “终端” 与 “远端服务器” 之间的TCP长连接。达到 远端服务器 可随时拉起 终端App,提升APP用户端使用时长(提升APP的DAU)这一方案。
- 国内手机厂商 Alarm 限制;
- 国内手机厂商 后台进程 限制;
2.2.1 手机厂商 Alarm 限制
国内终端手机厂商,不同厂商对应的Alarm限制方案也不相同,但目前已知的大概有以下两个方向:
- Alarm 对齐机制:
当手机系统黑屏休眠时,部分国内的手机品牌,会忽略 “第三方APP” 设置的 “Alarm唤醒周期”,强制将所有注册Alarm闹钟的APP,做Alarm唤醒周期对齐。
例如:假设有三款App,其设定的Alarm唤醒周期分别为1分钟、3分钟、5分钟。手机会直接忽略以上三款App的Alarm唤醒周期设定,强制将Alarm唤醒对齐为每5分钟唤醒一次。
系统休眠时,将所有App的唤醒时间做对齐,来减少手机的唤醒次数,节省用户的待机电量消耗。 - Alarm 无效:
当手机系统黑屏休眠时,部分国内的手机品牌,忽略 “第三方APP” 注册的全部Alarm,导致第三方应用注册的Alarm无效。
2.2.2 手机厂商 后台进程 限制
除了以上Alarm限制外,对于后台运行进程,不同终端厂商也进行了不同的限制。例如,部分终端厂商增加了后台进程耗电监测机制。
- 后台进程耗电监测机制:
当手机系统黑屏休眠时,部分国内的手机品牌,会启动一个耗电监测进程,若发现某个后台进程持续耗电,将直接杀死耗电进程。
三、手机厂商进程白名单
前边说道第三方App进程若在后台运行,会受到国内厂商Alarm限制、后台耗电监测等限制。但也有例外情况,比如:微信。
这里可以将其归结为以下两个白名单:
Alarm 对齐白名单:
微信这个体量的App 会被直接添加到,国内手机厂商的Alarm 对齐白名单中。白名单中的进程,系统休眠时的Alarm唤醒将不再受到限制。系统守护进程白名单:
若能达到微信的体量,国内手机厂商甚至可能会将其添加到系统守护进程白名单。该白名单中的进程,若某些原因后台进程被杀,系统守护进程会在一定时间内迅速拉起该进程,从而保证进程的活跃。
四、Push推送 建议方案
前边回顾了这几年在进程保活这个问题上,各软件提供商与Android系统研发制造商之间互相博弈过程。
如今在“Google的后台进程限制” 与 “国内手机厂商Alarm限制”双重限制下,第三方软件希望做到App进程常驻后台已经不太可能。
但每一个第三方App,基本都存在消息Push的需求。对于消息PUSH需求,第三方APP可使用的方案是什么?
- 接入终端手机厂商 Push通道;
- 进程添加到厂商进程保活白名单;
4.1 接入厂商 Push通道
在当前环境下的建议实现方案:接入终端手机厂商Push通道。
接入各终端厂商的Push通道,是最简单的实现方案。
厂商的Push通道常驻内存,所有第三方App接入厂商Push后 即能保证消息及时准确的到达,又可以减少终端用户手机的常驻进程,延长用户手机的待机时长,可以说是对双方都有利。
- 接入厂商PUSH 终端侧实现方案;
- 接入厂商Push的 到达率上的注意点。
4.1.1 接入厂商PUSH 终端方案
接入厂商PUSH 终端方案,终端侧可通过创建与维护一个单独的推送 Module 模块,其中集成 华为、小米、VIVO、OPPO、中兴 5家厂商的Push SDK;其他终端厂商的Push到达,可通过接入 个推 或 极光推送来实现。
华米OV等头部手机厂商:
通过接入华米OV等头部厂商PUSH通道,保证市场上大多数手机用户的PUSH到达率;- 其他非头部手机厂商:
通过极光或个推等第三方市场占有率较高的PUSH实现方案,来覆盖除 华米OV 等头部手机厂商外的其他终端手机,保证市场上少部分手机用户的PUSH到达率;
采用这个方案,研发人员需要开发和维护6个Push SDK组成的Module模块。因此,接入厂商PUSH,优点和缺点可归结如下。
- 优点:可以很好的保证 PUSH到达率;
- 缺点:开发与维护成本增加。
国内头部手机终端厂商较多,研发的同学在一个App中需要同时维护 华为、小米、VIVO、OPPO、中兴、魅族 等一系列厂商的PUSH SDK,研发维护成本急剧增加。
4.1.2 接入厂商Push的注意点
- 接入厂商Push的注意点;
- 将来终端手机厂商 PUSH渠道 可能收费。
接入厂商Push的注意点
接入厂商PUSH,在PUSH到达上仍有不同的限制条件,这一点也需要相关研发人员仔细研究各终端厂商PUSH的接入文档。
例如OPPO,存在一个PUSH配额问题:
OPPO PUSH配额是 OPPO推送消息的数量限制规则。每天的Push量 超过这个PUSH配额,OPPO将不再下发Push。
OPPO PUSH配额官方描述:
https://open.oppomobile.com/wiki/doc#id=10200
OPPO PUSH配额官方描述如下:

将来终端手机厂商 PUSH渠道 可能收费。
目前终端手机厂商的PUSH渠道均是免费为开发者使用的,但随着全市场的PUSH通道均为各终端厂商把控后,第三方APP的消息PUSH也许存在收费的可能。个人认为厂商PUSH渠道 收费 在不久的将来可能性还是很大的。
4.2 添加到厂商进程保活白名单
终端手机厂商追求的还是利益,因此只要给钱或有钱赚,没什么不可谈的。
与国内各终端厂商谈合作 添加到对应的进程白名单中。
这个方案,需要与各终端厂商合作 达成利益上的同盟或找到利益契合点,从而使终端厂商为您的App开放进程保活白名单。
若 您的公司与各终端厂商达成了利益同盟,恭喜您可以考虑采用维持一个终端与远端服务器的TCP长连接,实现消息及时到达终端,提升用户端App使用时长的PUSH方案了。
五、TCP 动态心跳方案
前边提到,若APP用户体量足够大 或 与各终端厂商达成了利益同盟,可以考虑维持一个终端与远端服务器的TCP长连接,实现消息及时到达终端,提升用户端App使用时长。
- TCP心跳 相关标准;
- 维持 TCP心跳 不断连;
- TCP动态心跳 方案。
5.1 TCP心跳 相关标准
在Android下,通过自建 TCP长连接 来进行Push消息推送,TCP长连接若存活,消息Push才能及时送达。
而说到TCP心跳,那什么是TCP心跳,TCP消息的结构又是什么?
rfc5626 4.4.1 Keep-Alive with CRLF标准中,关于SIP消息的TCP心跳给出了标准。
- Keep-Alive with CRLF;
- CRLF 详细说明;
- ping pong 心跳消息。
5.1.1 Keep-Alive with CRLF
rfc5626 4.4.1 Keep-Alive with CRLF中,SIP消息TCP心跳标准可以如下描述:
- 终端侧需每隔一段时间(心跳间隔时间)需发送一个“ping”(double CRLF)消息,到远端服务器侧;
- 终端发送“ping”消息后,若在10s之内未收到远端服务端的“pong”(CRLF)消息,则终端认为与服务端的连接失败。

5.1.2 CRLF 详细说明
根据rfc5626 4.4.1 Keep-Alive with CRLF标准:
- 终端上行的ping消息为 CRLFCRLF;
- 远端服务器下行的pong消息为 CRLF;
pong消息为CRLF ,含义是 回车+换行 符;
ping消息为double CRLF,也就是CRLFCRLF 含义是 回车换行回车换行 符。
CRLF 在ASCII表中与 16进制数据 的对应关系,如下图所示:

ASCII的对应表中查看:
- ping心跳消息
CRLFCRLF,对应的16进制数据为0d0a0d0a; - pong心跳消息
CRLF,对应的16进制数据为0d0a;
| 心跳 | 含义 | 缩写 | 十六进制 |
|---|---|---|---|
| ping | 终端上行心跳数据 | CRLFCRLF | 0d0a0d0a |
| pong | 远端服务器下行心跳数据 | CRLF | 0d0a |
5.1.3 ping pong 心跳消息
这一节关于 ping pong心跳消息,从其消息发送接收流程、WireShark现网数据抓包、消息结构举例 三方面进行介绍。
- ping pong 心跳流程;
- ping pong 心跳WireShark抓包;
- ping pong 心跳消息举例。
ping pong 心跳流程:
ping pong 心跳消息的发送/接收流程,如下图所示:
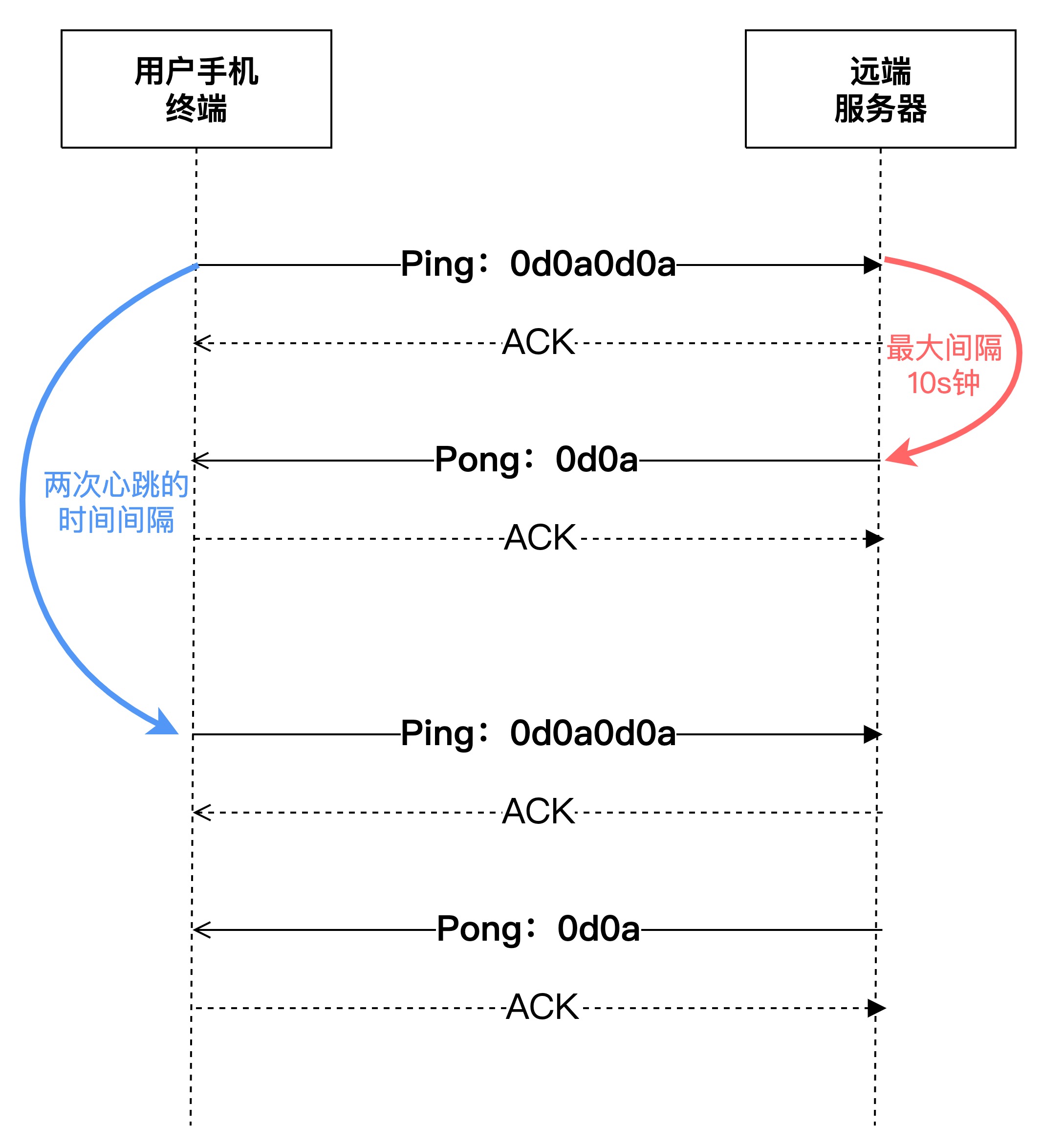
- 终端侧需每隔一段时间(心跳间隔时间)需发送一个“ping”(double CRLF 0xd0xa0xd0xa)消息,到远端服务器侧;
- 终端发送“ping”消息后,若在10s之内未收到远端服务端的“pong”(CRLF 0xd0xa)消息,则终端认为与服务端的连接失败。
ping pong 心跳WireShark抓包:
ping pong 心跳WireShark抓包如下图所示:

ping pong 心跳消息举例:
ping pong 心跳消息的举例如下所示:
// 终端侧发送: TCP Ping:0d 0a 0d 0a
Frame 2427: 60 bytes on wire (480 bits), 60 bytes captured (480 bits)
Linux cooked capture v1
Internet Protocol Version 4, Src: 10.xxx.xxx.xxx, Dst: 183.xxx.xxx.xxx
Transmission Control Protocol, Src Port: 46649, Dst Port: 5460, Seq: 21, Ack: 11, Len: 4
Source Port: 46649
Destination Port: 5460
[Stream index: 3]
[TCP Segment Len: 4]
Sequence Number: 21 (relative sequence number)
Sequence Number (raw): 149531750
[Next Sequence Number: 25 (relative sequence number)]
Acknowledgment Number: 11 (relative ack number)
Acknowledgment number (raw): 3481893389
0101 .... = Header Length: 20 bytes (5)
Flags: 0x018 (PSH, ACK)
Window: 65535
[Calculated window size: 65535]
[Window size scaling factor: -1 (unknown)]
Checksum: 0x727d [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[SEQ/ACK analysis]
[Timestamps]
TCP payload (4 bytes)
Data (4 bytes)
Data: 0d0a0d0a
[Length: 4]
// 终端侧接收:TCP ACK
Frame 2432: 56 bytes on wire (448 bits), 56 bytes captured (448 bits)
Linux cooked capture v1
Internet Protocol Version 4, Src: 183.xxx.xxx.xxx, Dst: 10.xxx.xxx.xxx
Transmission Control Protocol, Src Port: 5460, Dst Port: 46649, Seq: 11, Ack: 25, Len: 0
Source Port: 5460
Destination Port: 46649
[Stream index: 3]
[TCP Segment Len: 0]
Sequence Number: 11 (relative sequence number)
Sequence Number (raw): 3481893389
[Next Sequence Number: 11 (relative sequence number)]
Acknowledgment Number: 25 (relative ack number)
Acknowledgment number (raw): 149531754
0101 .... = Header Length: 20 bytes (5)
Flags: 0x010 (ACK)
Window: 21476
[Calculated window size: 21476]
[Window size scaling factor: -1 (unknown)]
Checksum: 0x7279 [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[SEQ/ACK analysis]
[Timestamps]
// 终端侧接收:TCP Pong:0d 0a
Frame 2433: 58 bytes on wire (464 bits), 58 bytes captured (464 bits)
Linux cooked capture v1
Internet Protocol Version 4, Src: 183.xxx.xxx.xxx, Dst: 10.xxx.xxx.xxx
Transmission Control Protocol, Src Port: 5460, Dst Port: 46649, Seq: 11, Ack: 25, Len: 2
Source Port: 5460
Destination Port: 46649
[Stream index: 3]
[TCP Segment Len: 2]
Sequence Number: 11 (relative sequence number)
Sequence Number (raw): 3481893389
[Next Sequence Number: 13 (relative sequence number)]
Acknowledgment Number: 25 (relative ack number)
Acknowledgment number (raw): 149531754
0101 .... = Header Length: 20 bytes (5)
Flags: 0x018 (PSH, ACK)
Window: 21476
[Calculated window size: 21476]
[Window size scaling factor: -1 (unknown)]
Checksum: 0x727b [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[SEQ/ACK analysis]
[Timestamps]
TCP payload (2 bytes)
Data (2 bytes)
Data: 0d0a
[Length: 2]
// 终端侧发送:TCP ACK
Frame 2434: 56 bytes on wire (448 bits), 56 bytes captured (448 bits)
Linux cooked capture v1
Internet Protocol Version 4, Src: 10.xxx.xxx.xxx, Dst: 183.xxx.xxx.xxx
Transmission Control Protocol, Src Port: 46649, Dst Port: 5460, Seq: 25, Ack: 13, Len: 0
Source Port: 46649
Destination Port: 5460
[Stream index: 3]
[TCP Segment Len: 0]
Sequence Number: 25 (relative sequence number)
Sequence Number (raw): 149531754
[Next Sequence Number: 25 (relative sequence number)]
Acknowledgment Number: 13 (relative ack number)
Acknowledgment number (raw): 3481893391
0101 .... = Header Length: 20 bytes (5)
Flags: 0x010 (ACK)
Window: 65535
[Calculated window size: 65535]
[Window size scaling factor: -1 (unknown)]
Checksum: 0x7279 [unverified]
[Checksum Status: Unverified]
Urgent Pointer: 0
[SEQ/ACK analysis]
[Timestamps]
5.2 维持 TCP心跳 不断连
TCP长连接的存活且有效,终端才能维持与远端服务器的TCP心跳,保证消息及时准确的到达。
因此影响TCP长连接稳定状态的因素,值得研发人员重点关注:
- 运营商 NAT超时;
- 终端 网络状态变化。
5.2.1 运营商 NAT超时
NAT(Network Address Translation) 是运营商的一个地址转换网关。生活中最常见的NAT设备,是我们家中使用的路由器。
国内运行商网络下,因为 IP v4 的 IP 数量有限,运营商分配给手机终端的 IP 是运营商内网的 IP,手机要连接 Internet,需要通过运营商的网关做一个网络地址转换(Network Address Translation,NAT)。

简单的说运营商的网关需要维护一个外网 IP、端口到内网 IP、端口的对应关系,以确保内网的手机可以跟 Internet 的服务器通讯。
| 内网地址 | 外网地址 |
|---|---|
| 192.168.0.3:8888 | 120.132.92.21:9202 |
| 192.168.0.2:5566 | 120.132.92.21:9200 |
如上表所示:
- NAT设备会根据NAT表对 发送 和 接收 的数据做修改, 比如将
192.168.0.3:8888发出去的数据封包改成120.132.92.21:9202,外部就认为他们是在和120.132.92.21:9202通信。 - NAT设备会将
120.132.92.21:9202收到的封包数据 IP和端口改成192.168.0.3:8888再发给内网的主机,这样内部和外部就能互相通信了。 - 但如果
192.168.0.3:8888 == 120.132.92.21:9202这一映射因为某些原因被NAT设备淘汰了,那么外部设备就无法与192.168.0.3:8888通信了。
为了节省资源,大部分国内移动网络运营商 在链路一段时间没有数据通讯时,会淘汰 NAT 表中的对应项,造成通信双方链路的中断。
因此,为了应对运营商NAT超时,终端需每隔一段时间向 远端服务器 发送一个 TCP保活消息,也就是TCP保活心跳。
以上也就是为什么终端与远端服务器,需要维持TCP心跳的原因。
5.2.2 终端 网络状态变化
终端网络状态变化,也会使TCP长连接断连,比如:终端移动网络与WIFI网络切换、网络断开与重新连 等
因此,终端 APP 需监听相应网络状态变化事件:若发现终端网络状态发生变化,需重新建立TCP长连接。
5.3 TCP 动态心跳方案
- 跟随手机状态变化 调整心跳状态;
- TCP 动态心跳周期的计算;
- 冗余心跳。
5.3.1 动态调整 心跳状态
这里我们可以将手机不同状态划进行划分,比如:
应用处于前台时为活跃态,刚刚进入后台或息屏时为次活跃态,应用进入后台一段时间后为后台状态,手机断网或关机后为IDEL状态。
可根据用户手机不同状态变化,动态调整应用的TCP心跳周期。
- 若应用处于前台活跃态:固定心跳。
当应用处于前台活跃状态时,为了保证消息及时准确的达到,使用固定心跳,保证用户体验。 - 应用刚进入后台(或息屏)的次活跃态:使用几次固定心跳。
应用进入后台(或息屏)时,先用几次固定跳维持长链接,保证用户刚刚息屏或应用刚刚进入后台,消息的及时与准确到达,然后进入后台自适应心跳计算。 - 应用进入后台(或息屏)一段时间后:使用动态心跳。
应用进入后台(或息屏)一段时间后,采用动态心跳,减少因心跳引起的空中信道资源消耗,以及因心跳引起的终端唤醒与电量消耗。 - 用户切换网络或重新联网:重新建立TCP长连接。
用户断网后,直接进入IDEL状态,此时需检测用户网络状态变化,若用户联网后,则重建TCP长连接;
用户切换网络状态(WIFI、移动网络互相切换),也需要重新建立TCP连接; - 应用重新进入前台活跃态:固定心跳。
应用重新进入前台活跃状态,重新采用固定心跳,保证用户消息及时准确到达。
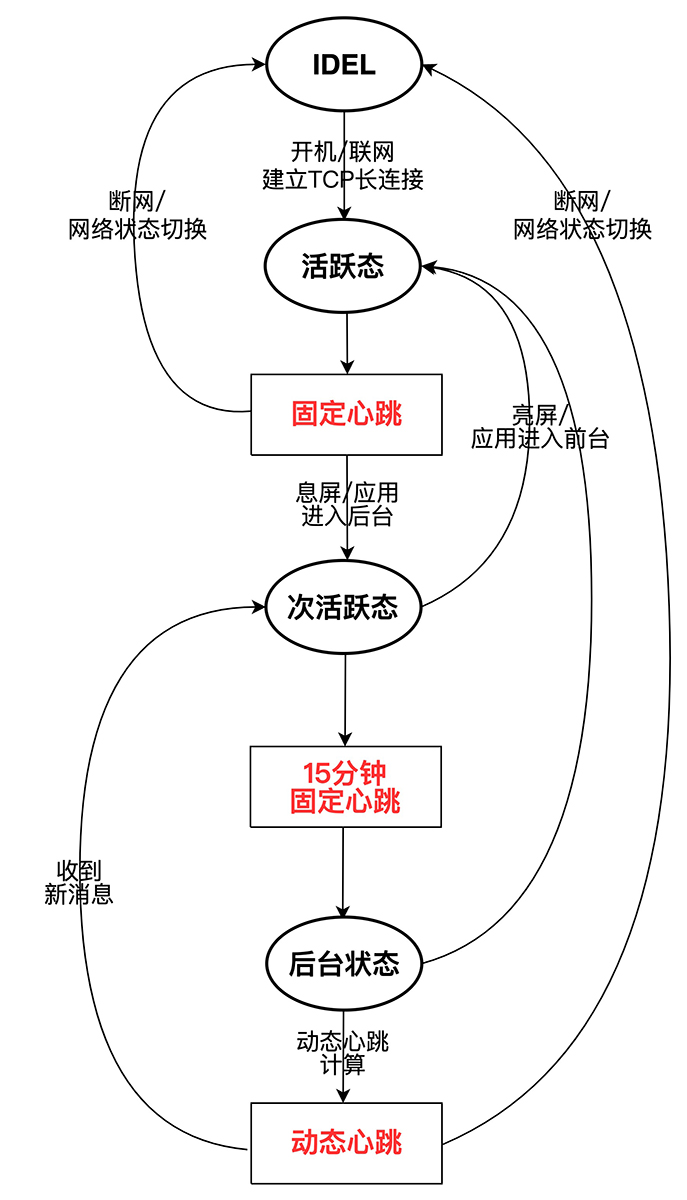
注:应用进入后台(或者息屏)时,先用几次最小心跳维持长链接,然后采用动态心跳。这样做的目的是 尽量选择用户不活跃的时间段,来减少因动态心跳可能产生的 消息送达不及时,从而对用户体验产生影响。
5.3.2 动态计算 心跳周期
动态计算心跳前,假设预定义定义几个数据常量:
- MinHeart 最小心跳间隔时间;
- MaxHeart 最大心跳间隔时间;
- HeartStep 心跳增加时间步长;
预定义几个数据变量:
- successHeart 动态探测 稳定后的心跳间隔时间;
- curHeart 当前成功心跳 初始为MinHeart;
注:
MinHeart、MaxHeart、HeartStep为预先定义的固定数据常量。
successHeart、curHeart为我们要探测的数据变量。

如上图所示:
- 应用进入后台(或者息屏)时,先用最小心跳间隔 MinHeart 维持心跳长链接;
- 若连续三次MinHeart心跳均成功,则认为下一次相同时间间隔的心跳大概率也会成功;此时下次心跳,可以尝试增加一次心跳步进HeartStep;
- 增加TCP心跳步进后,再次进行三次心跳探测,若连续三次均成功,则继续增加HeartStep步进,向上探测;
- 若出现失败,则同一个curHeart累计出现3次失败时,则认为这个时间为NAT超时时间;
同一个 curHeart 需要累计3次失败,才认定为失败,是为了排除用户处于弱网环境的情况下,比如地铁快速行进中。 - 同一个 curHeart 累计3次失败时,则认为找到了NAT超时时间。
下次心跳使用 successHeart = curHeart- HeartStep 作为心跳时间周期。 - 使用 successHeart 作为心跳周期,若连续成功,则一直使用 successHeart 作为心跳周期;
- 使用 successHeart 作为心跳周期,若连续出现3次失败,则认为探测数据失败,或者用户更换了网络环境,需重新探测。
5.3.2 冗余心跳
在用户对手机的的一些主动操作时,需增加冗余心跳,确保及时收到消息。
- 当用户点亮屏幕(或熄灭屏幕)时,立刻做一次心跳;
- 当应用切换到前台(或切换到后台)时,立刻做一次心跳;
- 当用户切换网络状态时,重新建立TCP长连接;
六、参考:
1像素Activity进程保活:
https://blog.csdn.net/zhenufo/article/details/79317068
Optimize for Doze and App Standby:
https://developer.android.google.cn/training/monitoring-device-state/doze-standby
Android 7.0 行为变更:
https://developer.android.google.cn/about/versions/nougat/android-7.0?hl=zh-cn
Android 8.0 行为变更:
https://developer.android.google.cn/about/versions/oreo/android-8.0-changes?hl=zh-cn
Android 9.0 行为变更:
https://developer.android.google.cn/about/versions/pie/android-9.0-changes-28?hl=zh-cn
Android10 行为变更:
https://developer.android.google.cn/about/versions/10/privacy?hl=zh-cn
Android11 行为变更:
https://developer.android.google.cn/about/versions/11/behavior-changes-all?hl=zh-cn
IPV6部署之后 是否还会大量使用NAT?
https://www.zhihu.com/question/27316663
Using Native IPv6 via Comcast in San Francisco:
https://blog.kylemanna.com/ipv6/using-native-ipv6-via-comcast-in-san-francisco/
rfc5626 SIP TCP心跳:
https://datatracker.ietf.org/doc/html/rfc5626#section-4.4.1
TCP Keep-Alive 和 应用层探活:
https://www.jianshu.com/p/00aec37b6be8
WebSocket细节 长连接保活及其原理:
https://baijiahao.baidu.com/s?id=1661934194124740212&wfr=spider&for=pc
2020年Android最新保活实现原理揭秘:
https://cloud.tencent.com/developer/news/585273
Andoird TCP通讯:
https://www.cnblogs.com/duwenqidu/p/12361811.html
关于TCP长连接、NAT超时、心跳包
https://www.cnblogs.com/sjjg/p/5830009.html
Android微信智能心跳方案:
https://mp.weixin.qq.com/s/ghnmC8709DvnhieQhkLJpA
=== THE END ===

不为人知的网络编程:彻底搞懂TCP协议层的KeepAlive保活机制
文中引用了参考资料中的部分内容,本文参考资料详见文末“参考资料”一节,感谢资料分享者。
1、引言
对于IM开发者而言,网络保活这件事再熟悉不过了,比如这是我最近一篇有关网络保活话题文章《一文读懂即时通讯应用中的网络心跳包机制:作用、原理、实现思路等》,以及我分享的大量代码实战编码中也都必须要考虑这个问题的实现,比如最近的这篇《跟着源码学IM(五):正确理解IM长连接、心跳及重连机制,并动手实现》。
对于IM这种应用而言,应用层的网络保活的最直接办法就是心跳机制,比如主流的IM里有微信、QQ、钉钉、易信等等,可能代码实现细节有所差异,但理论上无一例外都是这样实现。(PS:没错,当初微信跟运营商间的“信令危机”就是跟这个有关)
所谓的网络心跳,通常是客户端每隔一小段时间向服务器发送一个数据包(即心跳包),通知服务器自己仍然在线(心跳包中同时可能传输一些必要的数据)。发送心跳包,从通信层面来说就是为了保持长连接,至于这个包的内容,是没有什么特别规定的,但在移动端IM中为了省流量,一般都是很小的包(比如某些第3方的IM云为了说明心跳不费流量,号称1字节的心跳包)。
但经常有人会问到,既然TCP协议本身有KeepAlive保活这个东西(见:《TCP/IP详解 卷1 - 第23章·TCP的保活定时器》),为什么还要自已在应用层去实现网络保活/心跳机制呢?
没错,通常面视即时通讯/IM方面的程序员时,这几乎是必提问题!
要解答这个问题,我通常建议看看《为什么说基于TCP的移动端IM仍然需要心跳保活?》这篇。但限于篇幅,该篇并没有深入探讨TCP协议本身的KeepAlive机制,所以这次借本文想把TCP协议的KeepAlive保活机制给详细的整理出来,以便大家能深入其中一窥究竟。
学习交流:
- 即时通讯/推送技术开发交流5群:215477170 [推荐]
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
- 开源IM框架源码:https://github.com/JackJiang2...
(本文已同步发布于:http://www.52im.net/thread-35...
2、系列文章
本文是系列文章中的第12篇,本系列文章的大纲如下:
《不为人知的网络编程(一):浅析TCP协议中的疑难杂症(上篇)》
《不为人知的网络编程(二):浅析TCP协议中的疑难杂症(下篇)》
《不为人知的网络编程(三):关闭TCP连接时为什么会TIME_WAIT、CLOSE_WAIT》
《不为人知的网络编程(四):深入研究分析TCP的异常关闭》
《不为人知的网络编程(五):UDP的连接性和负载均衡》
《不为人知的网络编程(六):深入地理解UDP协议并用好它》
《不为人知的网络编程(七):如何让不可靠的UDP变的可靠?》
《不为人知的网络编程(八):从数据传输层深度解密HTTP》
《不为人知的网络编程(九):理论联系实际,全方位深入理解DNS》
《不为人知的网络编程(十):深入操作系统,从内核理解网络包的接收过程(Linux篇)》
《不为人知的网络编程(十一):从底层入手,深度分析TCP连接耗时的秘密》
《不为人知的网络编程(十二):彻底搞懂TCP协议层的KeepAlive保活机制》(* 本文)
3、TCP KeepAlive的初衷
采用TCP连接的C/S模式应用中,当连接的双方在连接空闲状态时,如果任意一方意外崩溃、当机、网线断开或路由器故障,另一方无法得知TCP连接已经失效。
那么,连接的另一方并不知道对端的情况,它会一直维护这个连接。而作为“服务端”来说,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,且有可能导致在一个无效的数据链路层面发送业务数据,结果就是发送失败。
所以各端要做到快速感知失败,减少无效链接操作,这就有了TCP的KeepAlive保活探测机制。
PS:这样宽泛的说TCP的KeepAlive机制的必要性,貌似还不是很有说服力,下节将带着具体的例子深入分析。
4、从NAT角度更具体地理解TCP KeepAlive的必要性
讲到TCP的KeepAlive的必要性,多数文章都是像上节这样比较笼统的进行说明,但对于爱刨根问底的开发者来说,这还远远不够。
本节将以路由器的NAT机制这个角度来具体分析TCP协议的造物主们设计KeepAlive机制的必要性。
4.1 从NAT原理讲起
狭义上,NAT分为SNAT(原地址转换)和DNAT(目标地址转换),关于DNAT,有兴趣的同学可以自行查阅,这里只讨论SNAT。
我们都知道,路由器的最基本功能是对第三层(网络层)上的IP报文进行转发。实际上,路由器还有很关键的一个功能,这便是NAT。特别是对于ISP对普通用户链路上的路由器,NAT功能尤为重要。
为什么要使用NAT?
原因很简单:IPv4地址非常稀缺。上网需求庞大,这使得ISP不可能为每一个入网用户都提供一个独立的公网IP,因此通常情况下,ISP会把用户接入局域网,使得多个用户共享同一个公网IP,而每一个用户各分得一个局域网内网IP。而连接公网和局域网的这台路由器,称之为网关(gateway),NAT的过程就发生在这台网关路由器上。
PS:《P2P技术详解(一):NAT详解——详细原理、P2P简介》这篇文章有助于更深入的理解NAT原理。
4.2 三层地址转换
局域网内的主机向公网发出的网络层IP报文,将经由网关被转发至公网,而在该转发过程中发生了地址转换。网关将该IP报文中的 源IP地址 从”该主机的内网IP”修改为”网关的公网IP”。
比如:局域网主机获得的内网IP为192.168.1.100,网关的公网IP为210.177.63.2,局域网主机向公网目标主机发出的IP报文中,源IP字段数据为192.168.1.100,在经过网关时,该字段数据将被修改为210.177.63.2。
为什么要这么做,相信大家已经猜到了:公网上的目标主机在收到这个IP报文后,需要知道这个IP报文的来源地址,并向该来源地址发送响应报文,但如果不经过NAT,目标主机拿到的来源地址是192.168.1.100,这显然是一个公网上不可访问到的私有地址,目标主机无法将响应报文发送到正确的来源主机上。开启了NAT之后,IP报文的来源地址被网关修改为210.177.63.2,这是一个公网地址,目标主机将向这个地址(即网关路由器的公网地址)发送响应报文。
但是请注意:如果这个IP报文的数据段不含传输层协议报文,而是一个pure的网络层packet,来自目标主机的响应报文是不能被网关准确转发到多台局域网主机中的其中一台的。
PS:ICMP报文除外,其报头中有Identifier字段用于标识不同的主机或进程,网关在处理Identifier时类似于下面提到的运输层端口。
4.3 传输层端口转换表
在三层地址转换中,我们可以保证局域网内主机向公网发出的IP报文能顺利到达目的主机,但是从目的主机返回的IP报文却不能准确送至指定局域网主机(我们不能让网关把IP报文广播至全部局域网主机,因为这样必然会带来安全和性能问题)。
为了解决这个问题,网关路由器需要借助传输层端口,通常情况下是TCP或UDP端口,由此来生成一张端口转换表。
让我们通过一个实例来说明端口转换表如何运作:
假设局域网主机A192.168.1.100需要与公网上的目标主机B210.199.38.2:80进行一次TCP通信。其中A所在局域网的网关C的公网IP地址为210.177.63.2。
步骤如下:
1)局域网主机A192.168.1.100发出TCP连接请求,A上的TCP端口为系统分配的53600。该TCP握手包中,包含源地址和端口192.168.1.100:53600,目的地址和端口210.199.38.2:80。
2)网关C将该包的原地址和端口修改为210.177.63.2:63000,其中63000是网关分配的临时端口。
3)网关C在端口转换表中增加一条记录:
4)网关C将修改后的TCP包发送至目的主机B。
5)目的主机B收到后,发送响应TCP包。该响应TCP包含有以下信息:源地址和端口210.199.38.2:80,目的地址和端口210.177.63.2:63000。
6)网关C收到这个来自B的响应包后,随即在端口转换表中查找记录。该记录须符合以下条件:目的主机IP==210.199.38.2,目的主机端口==80,网关端口==63000。
7)网关C搜索到这条记录,记录显示内网主机IP为192.168.1.100,内网主机端口为53600。
8)网关C将该包的目的地址和端口修改为192.168.1.100:53600。
9)网关C随即将该修改后的TCP包转发至192.168.1.100:53600,即局域网主机A。此时运输层数据的一次交换已完成。
4.4 问题来了
在网关C上,由于端口数量有限(0~65535),端口转换表的维护占用系统资源,因此不能无休止地向端口转换表中增加记录。对于过期的记录,网关需要将其删除。
如何判断哪些是过期记录?
网关认为:一段时间内无活动的连接是过期的,应定时检测转换表中的非活动连接,并将之丢弃。而这个丢弃的过程,网关不会以任何的方式通告该连接的任何一端。
通过下图可以更直观的理解这个过程:
▲ 上图引用自《TCP保活(TCP keepalive)》
那么问题就来了:如果一个客户端应用程序由于业务需要,需要与服务端维持长连接(例如基于TCP的IM聊天应用),而如果在特别长的时间内这个连接没有任何的数据交换,网关会认为这个连接过期并将这个连接从端口转换表中丢弃。该连接被丢弃时,客户端和服务端对此是完全无感知的。在连接被丢弃后,客户端将收不到服务端的数据推送,客户端发送的数据包也不能到达服务端。
一个具体的例子来感受一下这个问题的严重性:
某财务应用,在客户端需要填写大量的表单数据,在客户端与服务器端建立TCP连接后,客户端终端使用者将花费几分钟甚至几十分钟填写表单相关信息,终端使用者终于填好表单所需信息后,点击“提交”按钮。
结果,这个时候由于中间设备早已经将这个TCP连接从连接表中删除了,其将直接丢弃这个报文或者给客户端发送RST报文,应用故障产生,这将导致客户端终端使用者所有的工作将需要重新来过,给使用者带来极大的不便和损失。
4.5 解决方法
针对上述问题,TCP协议这一层的解决方法就是利用KeepAlive机制维持长连接,让网关认为我们的TCP连接是活动的,从而避免网关“干掉”我们的长连接。
通过NAT这个具体的例子,相信你已经能更具体地理解TCP协议中KeepAlive保活机制的必要性了。
5、TCP Keepalive工作原理
5.1 技术原理
当一个 TCP 连接建立之后,启用 TCP Keepalive 的一端便会启动一个计时器,当这个计时器数值到达 0 之后(也就是经过tcp_keep-alive_time时间后,这个参数之后会讲到),一个 TCP 探测包便会被发出。这个 TCP 探测包是一个纯 ACK 包(RFC1122#TCP Keep-Alives规范建议:不应该包含任何数据,但也可以包含1个无意义的字节,比如0x0),其 Seq号 与上一个包是重复的,所以其实探测保活报文不在窗口控制范围内。
如果一个给定的连接在两小时内(默认时长)没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于下表中的4个状态之一。
详细解释一下就是:
1)客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
2)客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
3)客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
4)客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探测的响应。
直观来说,TCP KeepAlive的交互过程大致如下图所示:
▲ 上图引用自《TCP保活(TCP keepalive)》
5.2 具体使用举例
以linux内核为例,应用程序若想使用TCP Keepalive,需要设置SO_KEEPALIVE套接字选项才能生效。
对应的,有三个重要的参数:
1)tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为7200s(2h);
2)tcp_keepalive_probes 在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包次数,默认值为9(次);
3)tcp_keepalive_intvl,在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包的发送频率,默认值为75s。
上面谈的是linux内核参数的配置,实际上其他编程语言有相应的设置方法。
例如,Java的Netty服务器框架中也提供了相关接口:
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
// 心跳监测
.childOption(ChannelOption.SO_KEEPALIVE, true)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throwsException {
ch.pipeline().addLast(
new EchoServerHandler());
}
});
// Start the server.
ChannelFuture f = b.bind(port).sync();
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
PS:Java程序只能做到设置SO_KEEPALIVE选项,至于TCP_KEEPCNT,TCP_KEEPIDLE,TCP_KEEPINTVL等参数配置,应用层面是没法设置的。
6、TCP KeepAlive可能导致的问题
Keepalive 技术只是TCP协议中的一个可选项。因为不当的配置可能会引起一些问题,所以默认是关闭的。
具体来说,可能导致下列问题:
1)在短暂的故障期间,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接;
2)需要消耗额外的宽带和流量(对于现在这个时代来说,这貌似已经不是问题了);
3)在以流量计费的互联网环境中增加了费用开销。
7、TCP KeepAlive在移动网络时代的局限性
不可否认,TCP协议作为TCP/IP协议族中最重要部分,对互联的发展确实功不可没(见:《技术往事:改变世界的TCP/IP协议(珍贵多图、手机慎点)》)。
但如今移动网络时代,无线通信越来越普及,作为上个世纪中期发明的TCP协议来说,客观的讲,在某些场景下确实有先天不足(见:《5G时代已经到来,TCP/IP老矣,尚能饭否?》)。
那么,又回到了本文开头的问题——“既然TCP协议本身有KeepAlive,为什么还要自已在应用层实现网络保活/心跳机制?”。
以移动端IM应用为例:
1)一方面,运营商ISP的网络资源更为稀缺,TCP协议默认2小时的KeepAlive基本不可能实现IM长连接“保活”(为了提升无线网络资源的利用率,运营商长则几分钟,短则数十秒就有可能回收空闲的网络连接)。
2)另一面,无线网络本身存在弱网问题,即使TCP连接是“好的”,但实际上处于“假死”状态,也无法起到长连接该有的作用。
所以说,IM应用层自已做网络保活(心跳机制)是不可避免的。
有关这方面的更多资料,有兴趣,可以深入阅读下面这几篇:
《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》
《移动端IM开发者必读(一):通俗易懂,理解移动网络的“弱”和“慢”》
《移动端IM开发者必读(二):史上最全移动弱网络优化方法总结》
《IM开发者的零基础通信技术入门(十三):为什么手机信号差?一文即懂!》
《IM开发者的零基础通信技术入门(十四):高铁上无线上网有多难?一文即懂!》
8、知识拓展:TCP Keepalive和HTTP Keep-Alive有什么区别?
很多人会把TCP Keepalive 和 HTTP Keep-Alive 这两个概念搞混淆。
这里简单介绍下HTTP Keep-Alive 。
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从 HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加上Connection、Keep-Alive字段。
如下图所示:
HTTP 1.0 和 1.1 在 TCP连接使用方面的差异如下图所示:
通俗地总结一下:
1)HTTP的Keep-Alive是为了让TCP连接活得更久一点,在发起多个http请求时能复用同一个连接,提高通信效率;
2)TCP的KeepAlive机制意图在于探测连接的对端是否存活,是一种检测TCP连接状况的保鲜机制。
9、参考资料
[1] TCP保活(TCP keepalive)
[2] TCP协议的KeepAlive机制与HeartBeat心跳包
[3] HTTP keep-alive和TCP keepalive的区别,你了解吗?
[4] TCP KeepAlive 与 HTTP Keep-Alive 区别
[5] tcp连接探测Keepalive和心跳包
[6] TCP keepalive的探究 (1) : NAT和保活机制
[7] 理解TCP长连接(Keepalive)
[8] 为何基于TCP协议的移动端IM仍然需要心跳保活机制?
[9] 移动端IM开发者必读(二):史上最全移动弱网络优化方法总结
[10] IM开发者的零基础通信技术入门(十三):为什么手机信号差?一文即懂!
附录:更多网络编程精华文章
[1] 网络编程(基础)资料:
《网络编程懒人入门(一):快速理解网络通信协议(上篇)》
《网络编程懒人入门(二):快速理解网络通信协议(下篇)》
《网络编程懒人入门(三):快速理解TCP协议一篇就够》
《网络编程懒人入门(四):快速理解TCP和UDP的差异》
《网络编程懒人入门(五):快速理解为什么说UDP有时比TCP更有优势》
《网络编程懒人入门(六):史上最通俗的集线器、交换机、路由器功能原理入门》
《网络编程懒人入门(七):深入浅出,全面理解HTTP协议》
《网络编程懒人入门(八):手把手教你写基于TCP的Socket长连接》
《网络编程懒人入门(九):通俗讲解,有了IP地址,为何还要用MAC地址?》
《网络编程懒人入门(十):一泡尿的时间,快速读懂QUIC协议》
《网络编程懒人入门(十一):一文读懂什么是IPv6》
《网络编程懒人入门(十二):快速读懂Http/3协议,一篇就够!》
《脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手》
《脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?》
《脑残式网络编程入门(三):HTTP协议必知必会的一些知识》
《脑残式网络编程入门(四):快速理解HTTP/2的服务器推送(Server Push)》
《脑残式网络编程入门(五):每天都在用的Ping命令,它到底是什么?》
《脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?》
《脑残式网络编程入门(七):面视必备,史上最通俗计算机网络分层详解》
《脑残式网络编程入门(八):你真的了解127.0.0.1和0.0.0.0的区别?》
《脑残式网络编程入门(九):面试必考,史上最通俗大小端字节序详解》
《网络编程入门从未如此简单(一):假如你来设计网络,会怎么做?》
《网络编程入门从未如此简单(二):假如你来设计TCP协议,会怎么做?》
[2] 网络编程(高阶)资料:
《高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少》
《高性能网络编程(二):上一个10年,著名的C10K并发连接问题》
《高性能网络编程(三):下一个10年,是时候考虑C10M并发问题了》
《高性能网络编程(四):从C10K到C10M高性能网络应用的理论探索》
《高性能网络编程(五):一文读懂高性能网络编程中的I/O模型》
《高性能网络编程(六):一文读懂高性能网络编程中的线程模型》
《高性能网络编程(七):到底什么是高并发?一文即懂!》
《不为人知的网络编程(一):浅析TCP协议中的疑难杂症(上篇)》
《不为人知的网络编程(二):浅析TCP协议中的疑难杂症(下篇)》
《不为人知的网络编程(三):关闭TCP连接时为什么会TIME_WAIT、CLOSE_WAIT》
《不为人知的网络编程(四):深入研究分析TCP的异常关闭》
《不为人知的网络编程(五):UDP的连接性和负载均衡》
《不为人知的网络编程(六):深入地理解UDP协议并用好它》
《不为人知的网络编程(七):如何让不可靠的UDP变的可靠?》
《不为人知的网络编程(八):从数据传输层深度解密HTTP》
《不为人知的网络编程(九):理论联系实际,全方位深入理解DNS》
《不为人知的网络编程(十):深入操作系统,从内核理解网络包的接收过程(Linux篇)》
《不为人知的网络编程(十一):从底层入手,深度分析TCP连接耗时的秘密》
《不为人知的网络编程(十二):彻底搞懂TCP协议层的KeepAlive保活机制》
《IM开发者的零基础通信技术入门(十一):为什么WiFi信号差?一文即懂!》
《IM开发者的零基础通信技术入门(十二):上网卡顿?网络掉线?一文即懂!》
《IM开发者的零基础通信技术入门(十三):为什么手机信号差?一文即懂!》
《IM开发者的零基础通信技术入门(十四):高铁上无线上网有多难?一文即懂!》
《IM开发者的零基础通信技术入门(十五):理解定位技术,一篇就够》
本文已同步发布于“即时通讯技术圈”公众号。
▲ 本文在公众号上的链接是:点此进入。同步发布链接是:http://www.52im.net/thread-35...
以上是关于一文读懂Android进程及TCP动态心跳保活的主要内容,如果未能解决你的问题,请参考以下文章