机器学习——概率生成模型
Posted 深度学习科研平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——概率生成模型相关的知识,希望对你有一定的参考价值。
假设有两类数据,每一类都有若干个样本;概率生成模型认为每一类数据都服从某一种分布,如高斯分布;从两类训练数据中得到两个高斯分布的密度函数,具体的是获得均值和方差两个参数;测试样本输入到其中一个高斯分布函数,得到的概率值若大于0.5,则说明该样本属于该类,否则属于另一类。
算法的核心在于获取分布函数的两个参数。具体的做法是:利用训练数据,构造似然函数,使得该似然函数最大的参数即为所求。事实上,一类数据的所有训练样本的均值和协方差即为所求。
得到其中一类的分布函数后,就可以对测试样本进行测试分类:

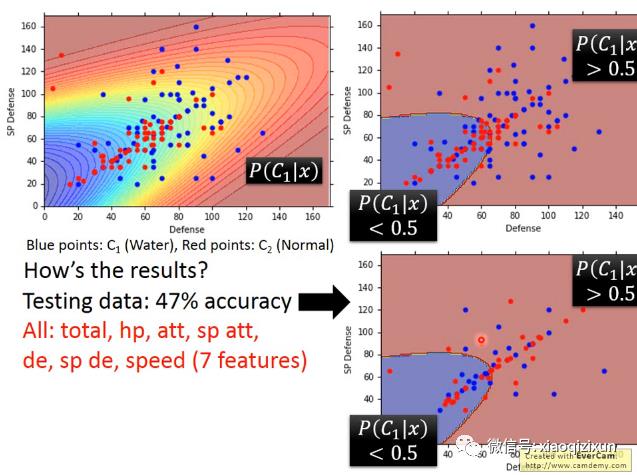
下图反映的是取样本的两个特征进行可视化的分类结果,可以看到只有47%的准确率。一个原因是选择的特征没有足够的区分性,另外一个原因是模型自身有问题
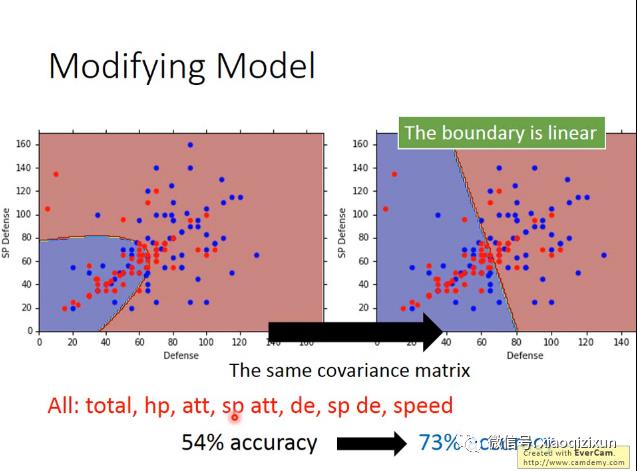
改进模型,使两类数据共用同一个协方差,均值不变。这里的协方差由两个类的协方差加权求和构成。

从下图可以看到,分类准确率提高到73%,决策边界也变成了直线
总结:
1、概率生成模型的三个步骤:

2、分布函数不唯一,可以是高斯分布,也可能是伯努利分布,根据数据特点人工决定

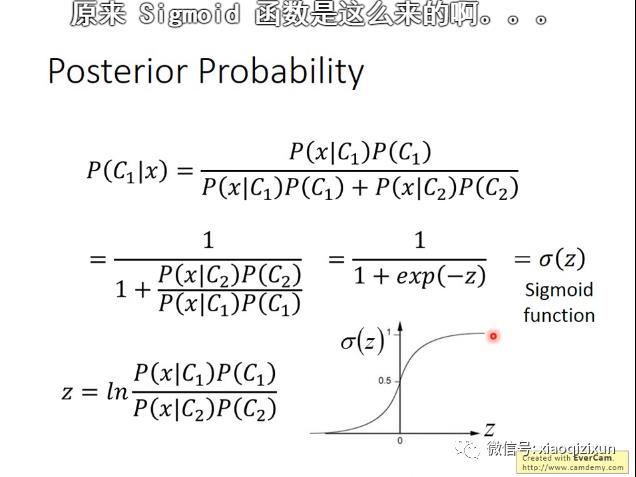
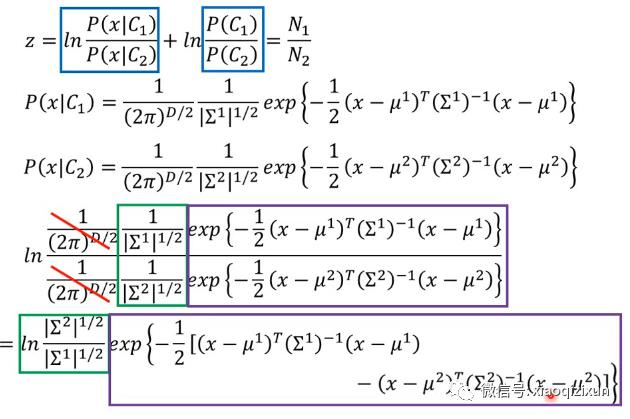
3、概率生成模型的决策函数可以转换成sigmoid函数:



4、判别模型和生成模型:前者直接计算求解w和b,后者通过求解分布函数的参数间接获得w和b,区别在哪里?
一般认为判别模型的分类效果比生成模型略胜一筹,但当训练数据较少时生成模型表现更好,而且生成模型对噪声点更鲁棒。从计算机复杂度来看,你认为呢?

以上是关于机器学习——概率生成模型的主要内容,如果未能解决你的问题,请参考以下文章