被称之为永远的神!就这6个Python爬虫开源项目?
Posted python可乐编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了被称之为永远的神!就这6个Python爬虫开源项目?相关的知识,希望对你有一定的参考价值。
今天盘点 6 个爬虫开源项目,它们可以帮你爬天爬地爬空气,爬微博、爬B站、爬知乎、爬*站。
提前声明,切勿使用这些项目从事非法商业活动,仅用于用于科研学习
很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。 很多已经做案例的人,却不知道如何去学习更加高深的知识。 那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码! QQ群:701698587 欢迎加入,一起讨论 一起学习!

01
微博爬虫
这个开源项目程序可以持续爬取一个或多个新浪微博用户(如李文di、无疫烦)的数据,并将结果信息写入文件或数据库。写入信息几乎包括用户微博的所有数据,包括用户信息和微博信息两大类。
地址:https://github.com/dataabc/weiboSpider爬取结果可写入文件和数据库,具体的写入文件类型如下:
- txt文件
- csv文件
- json文件
- mysql数据库
- MongoDB数据库
- SQLite数据库
同时支持下载微博中的图片和视频,具体的可下载文件如下:
- 原创微博中的原始图片
- 转发微博中的原始图片
- 原创微博中的视频
- 转发微博中的视频
- 原创微博Live Photo中的视频
- 转发微博Live Photo中的视频
首先需要修改 config.json 文件,然后爬取,程序会自动生成一个 weibo 文件夹,我们以后爬取的所有微博都被存储在这里。
然后程序在该文件夹下生成一个名为"微博名字"的文件夹,明星的所有微博爬取结果都在这里。文件夹里包含一个csv文件、一个txt文件、一个json文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见设置数据库部分。
02
Python爬虫教程
Python爬虫教程系列、从 0 到 1 学习 Python 爬虫,包括浏览器抓包,手机 APP 抓包,如 fiddler、mitmproxy,各种爬虫涉及的模块的使用,如:requests、beautifulSoup、selenium、appium、scrapy 等,以及验证码识别,MySQL,MongoDB 数据库的 Python 使用,多线程多进程爬虫的使用,css 爬虫加密逆向破解,JS爬虫逆向,分布式爬虫,爬虫项目实战实例等。
地址:https://github.com/wistbean/learn_python3_spider
03
爬虫集合
这个开源项目收集了各种爬虫 ,包括 Blibli、博客园、百度百科、北邮人、百度云网盘、Boss、贝壳、豆瓣、CSDN、抖音、GitHub、京东、知乎、拉钩、链家、微信公众号、网易云等等,你能想到的国内外网站爬虫,都可以先来这里看看有没有开源的爬虫。
地址:https://github.com/facert/awesome-spider04
智能爬虫平台
这个开源平台以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台。你可以在该平台配置各种爬虫。
地址:https://gitee.com/ssssssss-team/spider-flow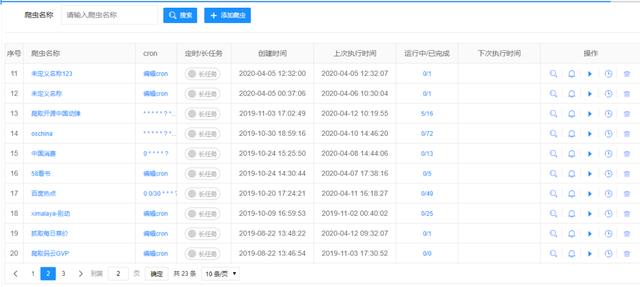
接下来以流程图的方式,开始配置一些变量和参数,点开始就能爬出你想要的数据。
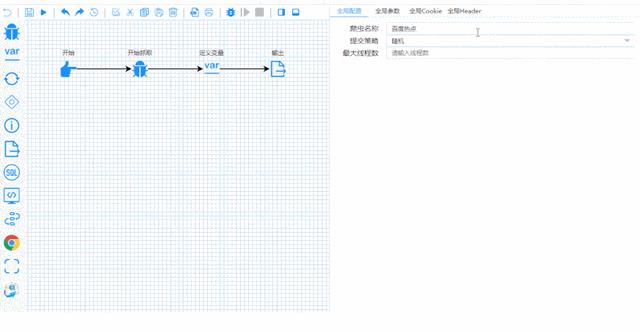
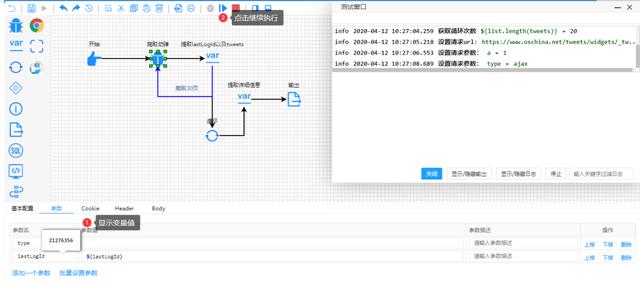
05
Java爬虫
Spiderman 是一个Java开源Web数据抽取工具,它能够收集指定的Web页面并从这些页面中提取有用的数据。
Spiderman主要是运用了像XPath,正则表达式等这些技术来实数据抽取。
地址:https://gitee.com/l-weiwei/spiderman
06
爬虫大全
这个开源项目包含多种网站、电商数据爬虫。包含:淘宝商品、微信公众号、大众点评、招聘网站、闲鱼、阿里任务、scrapy博客园、微博、百度贴吧、豆瓣电影、包图网、全景网、豆瓣音乐、某省药监局、搜狐新闻、机器学习文本采集、fofa资产采集、汽车之家、国家统计局、百度关键词收录数、蜘蛛泛目录、今日头条、豆瓣影评️️️。
地址:https://gitee.com/AJay13/ECommerceCrawlers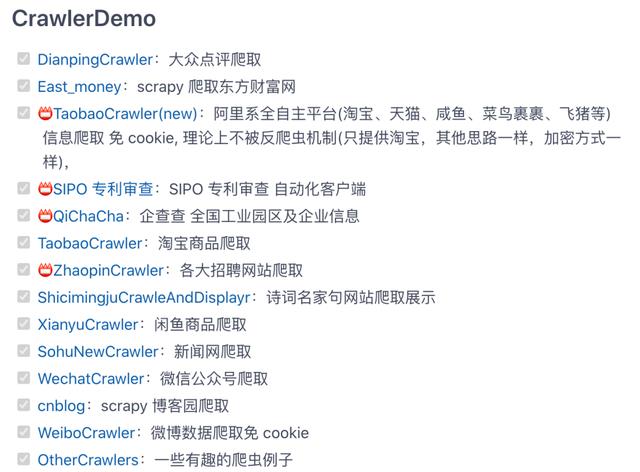
再见了Antirez我永远的神
其实antirez(Redis作者)退出Redis维护的消息一发布我就在很多咨询网站上面看到了,当时也没太多感慨。
今天比较有空想去看看霉霉Twitter的,然后看到了关注列表的antirez,我就又一次回顾了他的退役声明。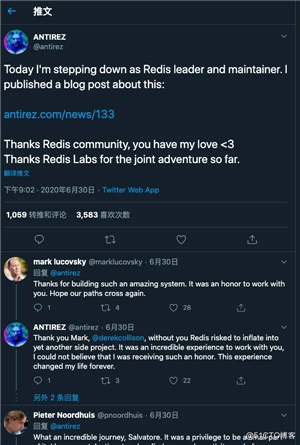
我想这个Redis之父肯定没想到,自己和小伙伴启动的项目,在10年后的今天,会对这个互联网时代产生这么大的影响吧,说Redis加速了互联网公司的发展也不为过。
其实很多开源项目都是作者一个无意间的初衷启动的,然后不经意间做到了各个领域的世界第一,比如Linux,Nginx等等,都是小小的体积蕴含着大大的能量。
我之前所在的团队是做电商活动的,可以说Redis就是我接触最多的中间件,所以我文章最开始也是以Redis作为系列的开篇,对它的感情也可以说比正常程序员都要独特,他的各种使用场景,高级用法我几乎接触了一个遍,在很长一段时间也成为我面试的杀手锏,我研读过Redis很多功能的源码,不得不说这个团队真的把性能的优化做到了极致,用最短的代码,做到了最大的性能优化。
如果不是技术的同学可能不是很明白,这么说吧,大家进任何网页第一眼能看到的东西,大部分都是跟缓存息息相关的,或者也是利用了缓存这样的概念,一旦缓存挂了,那所有的网站可能会天天都会发生微博宕机那样的事故,所有人都无法正常访问网站,大量的流量会瞬间击垮服务器。
在Redis中,数据结构这个词的意义不仅表示在某种数据结构上的操作,更包括了结构本身及这些操作的时间空间复杂度。
Redis 定位是一个内存数据库,正是由于内存的快速访问特性,才使得Redis能够有如此高的性能,才使得Redis能够轻松处理大量复杂的数据结构,Redis会尝试其它的存储方面的选择,但是永远不会改变它是一个内存数据库的角色。
Redis 有着诗一般优美的代码,经常有一些不太了解Redis 原则的人会建议Redis采用一些其它人的代码,以实现一些Redis 未实现的功能,但这对研发团队来说来说就像是非要给《红楼梦》接上后四十回一样。
Redis的深度用户都知道,缓存只是他最简单和基础的功能罢了,哨兵,集群,分布式锁,延时队列,位图,HyperLogLog,布隆过滤器,限流,GeoHash(附近的人)等等,眼花缭乱的类型和使用姿势多得不行。
这里面大部分的东西在antirez维护Redis的早期就诞生了,是不是对他的敬佩又多了一分。
antirez这样的大神能坚持这么多年,我想枯燥是必然的,但是如果你跟我一样关注他的Twitter你会发现,这个人是真的热爱这项事业。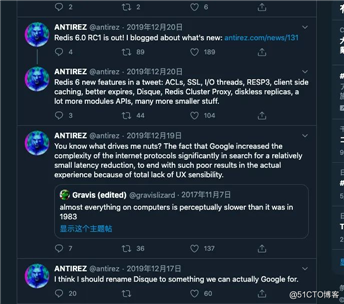
他几乎没有一条生活相关的推特,最多偶尔晒一下论坛和技术大牛的合照,或者偶尔。。。开开车,我发现我们程序员都喜欢开车哈哈哈,不知道为啥敲到这里的时候,我的嘴角微微的上扬了。
你说他枯燥吧他枯燥,不过他也很有趣,我问大家一个问题:大家知道Redis端口为啥是6379么?
Antirez出生在非英语系国家,英语能力长期以来是一个短板,他曾经专门为自己蹩脚的英语能力写过一篇博文《英语伤痛 15 年》,用自己的成长经历来鼓励那些非英语系的技术开发者们努力攻克英语难关。
我们都知道 Redis 的默认端口是 6379,这个端口号也不是随机选的,而是由手机键盘字母「MERZ」的位置决定的。
「MERZ」在 Antirez 的朋友圈语言中是「愚蠢」的代名词,它源于意大利广告女郎「Alessia Merz」在电视节目上说了一堆愚蠢的话。
他的博客地址:http://oldblog.antirez.com/post/redis-as-LRU-cache.html 包括上面的英语伤痛15年也是有的,他是意大利人嘛,所以英文的博客不是那么多,不过他最近更新的大部分都是英文的了。
是不是发现这个人还是有意思,因为不爽一个广告女郎,就把人家做成了端口名。
最后跟随谷歌以及程序羊的翻译跟我再一次回顾,Antirez的退役文吧,这个四十岁的老兵,这么多年孜孜不倦地写代码,为 Redis 的开源事业持续贡献自己的力量:
antirez在退役文中说到:他最激动人心的时刻就是十年前项目刚刚开始的时刻,Redis 的联合创始人和我启动了两个重要的意大利互联网 web 2.0 项目,为了持续扩容服务,我们创造了很多新概念,这些概念其实已经在技术领域流行很多年了,但是在当时我们并不了解也不曾验证过是否可行,不过没关系,我们喜欢解决问题,并从中发现很多乐趣,Redis 刚刚诞生的时候真的是非常有意思的(让人难忘的)。
但是如今 Redis 不一样了,它难以置信的在非常非常多的项目中扮演者至关重要的角色。经过了这么多年的打磨,我的工作性质也发生了变化。我不只是要让它变更加有用(更多新鲜的功能),还要让它尽可能的稳定(少出 bug)。
尤其最近这几年,我的工作内容变化太大了,我主要的精力都花在了 Redis 代码的维护上,主要就是看看其它的开发者告诉我关于 Redis 的代码该如何改进才能让它变的更快更好。其实我根本就不想做一个软件维护者(修 bug、优化代码的工作实在太无聊了)。
我写代码是为了更好的表达自我,这是艺术创作(乐趣),而不单单是为了把事情搞定(挣钱)。
我的目标更多的是为了追求美感,而最终能不能起到作用仅仅是附带的结果而已。我宁可大家认为我是一个糟糕的艺术家,也不希望只被看成一个优秀的程序员。
但是现在我被要求这要求那,就因为这个项目变得如此重要。我不能随意表达自己(艺术创作,大刀阔斧的改代码),而只能在现有的代码基础上维护(小打小闹)。
我并不是说这样不对,这只是现阶段的 Redis 必须要接受的方式。但是我个人有点受不了,最近几年我感到很憋屈(Linus 也会是这种感觉么?)。
所以呢,社区里面的同志们啊,我告诉你们我要退居幕后了。我未来只是作为 Redis 的顾问来给 Redis 实验室提供一些新奇的想法(维护 Redis 代码我就不干了)。
如此呢,我就可以把自己释放出来做点其它的事。至于做什么还没有想好,会不会继续写代码也不确定。我比较怀疑自己是否能够完全放弃写代码,只是因为写代码实在是太好玩了(此处有个调皮的表情)。
从今天开始,我要把 Redis 留给了 Redis 社区,让我的老战友 Yossi Gottlieb 和 Oran Agra 来继续维护它。
这两个人在过去这几年对我帮助非常大,在关于 Redis 愿景(未来)的理解上,他们并不会被我个人的主观想法所左右。因为我不太想参与 Redis 开发模型的治理工作(这是 Redis 维护工作中最重要的元工作,而我不是想继续搞维护了),所以后面跟其它 Redis 开发者交流「可持续的开发模型」一事就完全托付给他们两了,你们可以从这边文章 https://redislabs.com/blog/new-governance-for-redis/ 中直接了解这个事。
我相信我不只是把 Redis 留给了社区里的一堆专家级程序员,还应该包括社区中所有对 Redis 精神遗产感兴趣的朋友们。
十一年来,我希望让大家看到开发软件还有这样的一种特别的方式(我的方式),这种方式只有个别人可以理解。我希望在 Redis 未来的变化中,这种方式还是可以继续被适度采用。(是不是 antirez 独裁(不可持续)的方式和 他老战友的「可持续开发模型」冲突了,闹的很不愉快,不是很确定)。
Redis 是我职业生涯中压力最大的项目,可能也是最重要的项目。
最近这些年编程世界的变化我并不是特别喜欢(不知道说的是哪方面的变化),虽然这段旅程非常艰辛,能够有机会和很多特别的人一起工作交流也让我感觉非常知足。
谢谢你们的理解和帮助,这让我成长了很多,我需要特别感谢无私赞助我的公司和个人让我可以持续这么多年持续每天为开源世界共享代码,让我可以自由地做自己认为是正确的事。还有 Redis Labs、VMWare 和 Pivotal,非常感谢你们的帮助和宽容(是不是 antirez 摸鱼了)。
前面说到,除了继续 Redis 的顾问工作之外,我也不知道未来的路该怎么走。也许走一步看一步也挺好,不用干太多事。我还想发展一下个人的一些兴趣爱好,比如写写博客就挺好,以前我一直想写但是一直没有太多时间。
最近我还发了一些意大利语的技术视频,这很好玩,还收到了读者大量的反馈,我未来应该还会发更多的视频。你们大概也知道我的 Twitter 账号 @antirez 一直很活跃 ,如果你们还对我这样一个又老又怪的程序员感兴趣,那就去 Twitter 上围观我吧。
最后用antirez的一句话收尾吧:
我们以优化代码为乐,我们相信编码是一件辛苦的工作,唯一对得起这辛苦的就是去享受它,如果我们在编码中失去了乐趣,那最好的解决办法就是停下来,我们决不会选择让Redis不好玩的开发模式。
respect
我是敖丙,你知道的越多,你不知道的越多,我们下期见!
以上是关于被称之为永远的神!就这6个Python爬虫开源项目?的主要内容,如果未能解决你的问题,请参考以下文章