Go语言核心36讲(Go语言进阶技术七)--学习笔记
Posted MingsonZheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go语言核心36讲(Go语言进阶技术七)--学习笔记相关的知识,希望对你有一定的参考价值。
13 | 结构体及其方法的使用法门
我们都知道,结构体类型表示的是实实在在的数据结构。一个结构体类型可以包含若干个字段,每个字段通常都需要有确切的名字和类型。
前导内容:结构体类型基础知识
当然了,结构体类型也可以不包含任何字段,这样并不是没有意义的,因为我们还可以为类型关联上一些方法,这里你可以把方法看做是函数的特殊版本。
函数是独立的程序实体。我们可以声明有名字的函数,也可以声明没名字的函数,还可以把它们当做普通的值传来传去。我们能把具有相同签名的函数抽象成独立的函数类型,以作为一组输入、输出(或者说一类逻辑组件)的代表。
方法却不同,它需要有名字,不能被当作值来看待,最重要的是,它必须隶属于某一个类型。方法所属的类型会通过其声明中的接收者(receiver)声明体现出来。
接收者声明就是在关键字func和方法名称之间的圆括号包裹起来的内容,其中必须包含确切的名称和类型字面量。
接收者的类型其实就是当前方法所属的类型,而接收者的名称,则用于在当前方法中引用它所属的类型的当前值。
我们举个例子来看一下。
// AnimalCategory 代表动物分类学中的基本分类法。
type AnimalCategory struct {
kingdom string // 界。
phylum string // 门。
class string // 纲。
order string // 目。
family string // 科。
genus string // 属。
species string // 种。
}
func (ac AnimalCategory) String() string {
return fmt.Sprintf("%s%s%s%s%s%s%s",
ac.kingdom, ac.phylum, ac.class, ac.order,
ac.family, ac.genus, ac.species)
}
结构体类型AnimalCategory代表了动物的基本分类法,其中有 7 个string类型的字段,分别表示各个等级的分类。
下边有个名叫String的方法,从它的接收者声明可以看出它隶属于AnimalCategory类型。
通过该方法的接收者名称ac,我们可以在其中引用到当前值的任何一个字段,或者调用到当前值的任何一个方法(也包括String方法自己)。
这个String方法的功能是提供当前值的字符串表示形式,其中的各个等级分类会按照从大到小的顺序排列。使用时,我们可以这样表示:
category := AnimalCategory{species: "cat"}
fmt.Printf("The animal category: %s\\n", category)
这里,我用字面量初始化了一个AnimalCategory类型的值,并把它赋给了变量category。为了不喧宾夺主,我只为其中的species字段指定了字符串值"cat",该字段代表最末级分类“种”。
在 Go 语言中,我们可以通过为一个类型编写名为String的方法,来自定义该类型的字符串表示形式。这个String方法不需要任何参数声明,但需要有一个string类型的结果声明。
正因为如此,我在调用fmt.Printf函数时,使用占位符%s和category值本身就可以打印出后者的字符串表示形式,而无需显式地调用它的String方法。
fmt.Printf函数会自己去寻找它。此时的打印内容会是The animal category: cat。显而易见,category的String方法成功地引用了当前值的所有字段。
方法隶属的类型其实并不局限于结构体类型,但必须是某个自定义的数据类型,并且不能是任何接口类型。
一个数据类型关联的所有方法,共同组成了该类型的方法集合。同一个方法集合中的方法不能出现重名。并且,如果它们所属的是一个结构体类型,那么它们的名称与该类型中任何字段的名称也不能重复。
我们可以把结构体类型中的一个字段看作是它的一个属性或者一项数据,再把隶属于它的一个方法看作是附加在其中数据之上的一个能力或者一项操作。将属性及其能力(或者说数据及其操作)封装在一起,是面向对象编程(object-oriented programming)的一个主要原则。Go 语言摄取了面向对象编程中的很多优秀特性,同时也推荐这种封装的做法。从这方面看,Go 语言其实是支持面向对象编程的,但它选择摒弃了一些在实际运用过程中容易引起程序开发者困惑的特性和规则。
现在,让我们再把目光放到结构体类型的字段声明上。我们来看下面的代码:
type Animal struct {
scientificName string // 学名。
AnimalCategory // 动物基本分类。
}
我声明了一个结构体类型,名叫Animal。它有两个字段。一个是string类型的字段scientificName,代表了动物的学名。而另一个字段声明中只有AnimalCategory,它正是我在前面编写的那个结构体类型的名字。这是什么意思呢?
那么,我们今天的问题是:Animal类型中的字段声明AnimalCategory代表了什么?
更宽泛地讲,如果结构体类型的某个字段声明中只有一个类型名,那么该字段代表了什么?
这个问题的典型回答是:字段声明AnimalCategory代表了Animal类型的一个嵌入字段。Go 语言规范规定,如果一个字段的声明中只有字段的类型名而没有字段的名称,那么它就是一个嵌入字段,也可以被称为匿名字段。我们可以通过此类型变量的名称后跟“.”,再后跟嵌入字段类型的方式引用到该字段。也就是说,嵌入字段的类型既是类型也是名称。
问题解析
说到引用结构体的嵌入字段,Animal类型有个方法叫Category,它是这么写的:
func (a Animal) Category() string {
return a.AnimalCategory.String()
}
Category方法的接收者类型是Animal,接收者名称是a。在该方法中,我通过表达式a.AnimalCategory选择到了a的这个嵌入字段,然后又选择了该字段的String方法并调用了它。
顺便提一下,在某个代表变量的标识符的右边加“.”,再加上字段名或方法名的表达式被称为选择表达式,它用来表示选择了该变量的某个字段或者方法。
这是 Go 语言规范中的说法,与“引用结构体的某某字段”或“调用结构体的某某方法”的说法是相通的。我在以后会混用这两种说法。
实际上,把一个结构体类型嵌入到另一个结构体类型中的意义不止如此。嵌入字段的方法集合会被无条件地合并进被嵌入类型的方法集合中。例如下面这种:
animal := Animal{
scientificName: "American Shorthair",
AnimalCategory: category,
}
fmt.Printf("The animal: %s\\n", animal)
我声明了一个Animal类型的变量animal并对它进行初始化。我把字符串值"American Shorthair"赋给它的字段scientificName,并把前面声明过的变量category赋给它的嵌入字段AnimalCategory。
我在后面使用fmt.Printf函数和%s占位符试图打印animal的字符串表示形式,相当于调用animal的String方法。虽然我们还没有为Animal类型编写String方法,但这样做是没问题的。因为在这里,嵌入字段AnimalCategory的String方法会被当做animal的方法调用。
那如果我也为Animal类型编写一个String方法呢?这里会调用哪一个呢?
答案是,animal的String方法会被调用。这时,我们说,嵌入字段AnimalCategory的String方法被“屏蔽”了。注意,只要名称相同,无论这两个方法的签名是否一致,被嵌入类型的方法都会“屏蔽”掉嵌入字段的同名方法。
类似的,由于我们同样可以像访问被嵌入类型的字段那样,直接访问嵌入字段的字段,所以如果这两个结构体类型里存在同名的字段,那么嵌入字段中的那个字段一定会被“屏蔽”。这与我们在前面讲过的,可重名变量之间可能存在的“屏蔽”现象很相似。
正因为嵌入字段的字段和方法都可以“嫁接”到被嵌入类型上,所以即使在两个同名的成员一个是字段,另一个是方法的情况下,这种“屏蔽”现象依然会存在。
不过,即使被屏蔽了,我们仍然可以通过链式的选择表达式,选择到嵌入字段的字段或方法,就像我在Category方法中所做的那样。这种“屏蔽”其实还带来了一些好处。我们看看下面这个Animal类型的String方法的实现:
func (a Animal) String() string {
return fmt.Sprintf("%s (category: %s)",
a.scientificName, a.AnimalCategory)
}
在这里,我们把对嵌入字段的String方法的调用结果融入到了Animal类型的同名方法的结果中。这种将同名方法的结果逐层“包装”的手法是很常见和有用的,也算是一种惯用法了。
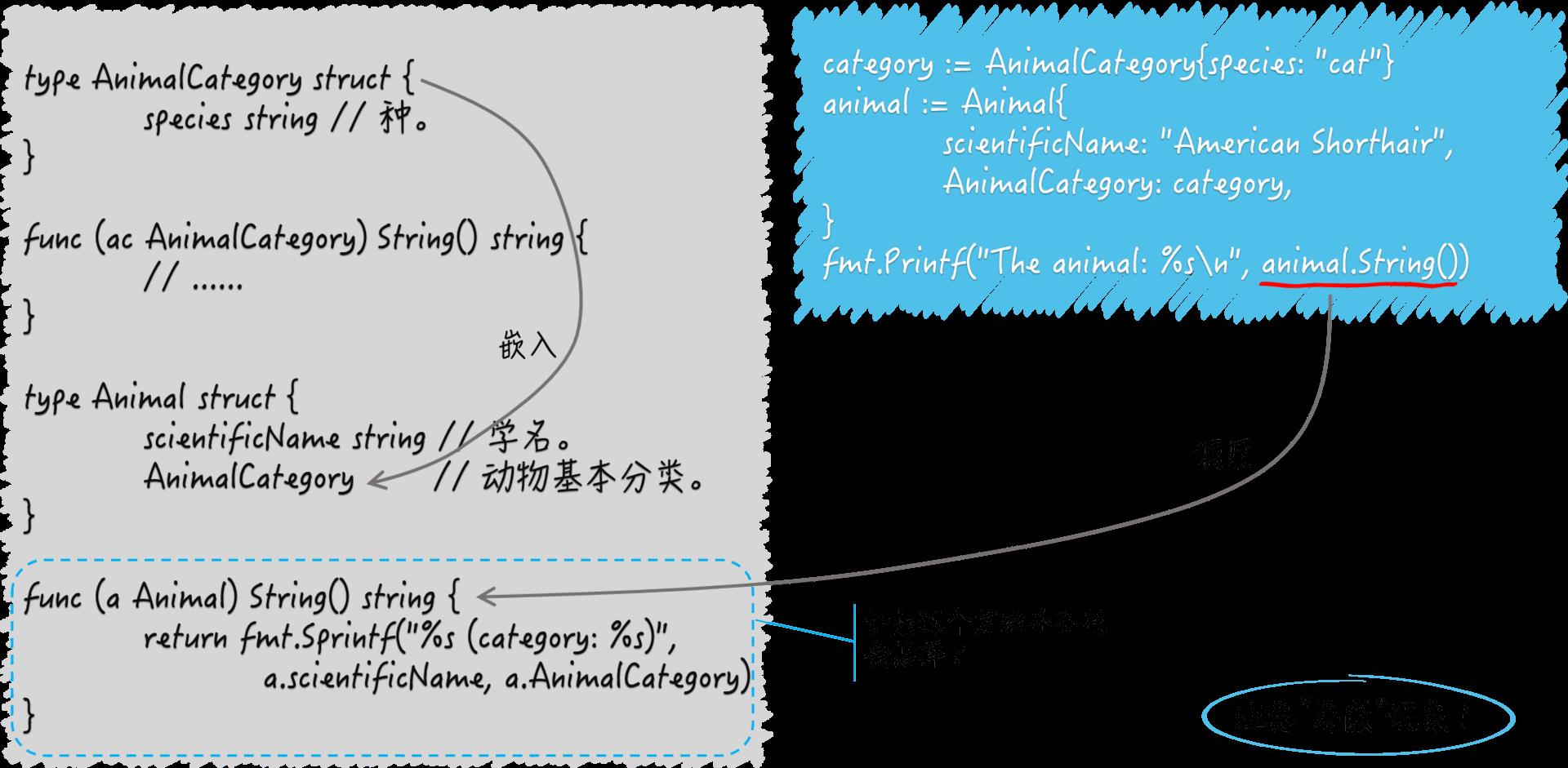
(结构体类型中的嵌入字段)
最后,我还要提一下多层嵌入的问题。也就是说,嵌入字段本身也有嵌入字段的情况。请看我声明的Cat类型:
type Cat struct {
name string
Animal
}
func (cat Cat) String() string {
return fmt.Sprintf("%s (category: %s, name: %q)",
cat.scientificName, cat.Animal.AnimalCategory, cat.name)
}
结构体类型Cat中有一个嵌入字段Animal,而Animal类型还有一个嵌入字段AnimalCategory。
在这种情况下,“屏蔽”现象会以嵌入的层级为依据,嵌入层级越深的字段或方法越可能被“屏蔽”。
例如,当我们调用Cat类型值的String方法时,如果该类型确有String方法,那么嵌入字段Animal和AnimalCategory的String方法都会被“屏蔽”。
如果该类型没有String方法,那么嵌入字段Animal的String方法会被调用,而它的嵌入字段AnimalCategory的String方法仍然会被屏蔽。
只有当Cat类型和Animal类型都没有String方法的时候,AnimalCategory的String方法菜会被调用。最后的最后,如果处于同一个层级的多个嵌入字段拥有同名的字段或方法,那么从被嵌入类型的值那里,选择此名称的时候就会引发一个编译错误,因为编译器无法确定被选择的成员到底是哪一个。
以上关于嵌入字段的所有示例都在 demo29.go 中,希望能对你有所帮助。
package main
import "fmt"
// 示例1。
// AnimalCategory 代表动物分类学中的基本分类法。
type AnimalCategory struct {
kingdom string // 界。
phylum string // 门。
class string // 纲。
order string // 目。
family string // 科。
genus string // 属。
species string // 种。
}
func (ac AnimalCategory) String() string {
return fmt.Sprintf("%s%s%s%s%s%s%s",
ac.kingdom, ac.phylum, ac.class, ac.order,
ac.family, ac.genus, ac.species)
}
// 示例2。
type Animal struct {
scientificName string // 学名。
AnimalCategory // 动物基本分类。
}
// 该方法会"屏蔽"掉嵌入字段中的同名方法。
func (a Animal) String() string {
return fmt.Sprintf("%s (category: %s)",
a.scientificName, a.AnimalCategory)
}
// 示例3。
type Cat struct {
name string
Animal
}
// 该方法会"屏蔽"掉嵌入字段中的同名方法。
func (cat Cat) String() string {
return fmt.Sprintf("%s (category: %s, name: %q)",
cat.scientificName, cat.Animal.AnimalCategory, cat.name)
}
func main() {
// 示例1。
category := AnimalCategory{species: "cat", genus: "dog"}
fmt.Printf("The animal category: %s\\n", category)
// 示例2。
animal := Animal{
scientificName: "American Shorthair",
AnimalCategory: category,
}
fmt.Printf("The animal: %s\\n", animal)
// 示例3。
cat := Cat{
name: "little pig",
Animal: animal,
}
fmt.Printf("The cat: %s\\n", cat)
}
知识扩展
问题 1:Go 语言是用嵌入字段实现了继承吗?
这里强调一下,Go 语言中根本没有继承的概念,它所做的是通过嵌入字段的方式实现了类型之间的组合。这样做的具体原因和理念请见 Go 语言官网的 FAQ 中的Why is there no type inheritance? https://golang.org/doc/faq#inheritance。
简单来说,面向对象编程中的继承,其实是通过牺牲一定的代码简洁性来换取可扩展性,而且这种可扩展性是通过侵入的方式来实现的。
类型之间的组合采用的是非声明的方式,我们不需要显式地声明某个类型实现了某个接口,或者一个类型继承了另一个类型。
同时,类型组合也是非侵入式的,它不会破坏类型的封装或加重类型之间的耦合。
我们要做的只是把类型当做字段嵌入进来,然后坐享其成地使用嵌入字段所拥有的一切。如果嵌入字段有哪里不合心意,我们还可以用“包装”或“屏蔽”的方式去调整和优化。
另外,类型间的组合也是灵活的,我们总是可以通过嵌入字段的方式把一个类型的属性和能力“嫁接”给另一个类型。
这时候,被嵌入类型也就自然而然地实现了嵌入字段所实现的接口。再者,组合要比继承更加简洁和清晰,Go 语言可以轻而易举地通过嵌入多个字段来实现功能强大的类型,却不会有多重继承那样复杂的层次结构和可观的管理成本。
接口类型之间也可以组合。在 Go 语言中,接口类型之间的组合甚至更加常见,我们常常以此来扩展接口定义的行为或者标记接口的特征。与此有关的内容我在下一篇文章中再讲。
在我面试过的众多 Go 工程师中,有很多人都在说“Go 语言用嵌入字段实现了继承”,而且深信不疑。
要么是他们还在用其他编程语言的视角和理念来看待 Go 语言,要么就是受到了某些所谓的“Go 语言教程”的误导。每当这时,我都忍不住当场纠正他们,并建议他们去看看官网上的解答。
问题 2:值方法和指针方法都是什么意思,有什么区别?
我们都知道,方法的接收者类型必须是某个自定义的数据类型,而且不能是接口类型或接口的指针类型。所谓的值方法,就是接收者类型是非指针的自定义数据类型的方法。
比如,我们在前面为AnimalCategory、Animal以及Cat类型声明的那些方法都是值方法。就拿Cat来说,它的String方法的接收者类型就是Cat,一个非指针类型。那什么叫指针类型呢?请看这个方法:
func (cat *Cat) SetName(name string) {
cat.name = name
}
方法SetName的接收者类型是Cat。Cat左边再加个代表的就是Cat类型的指针类型。
这时,Cat可以被叫做*Cat的基本类型。你可以认为这种指针类型的值表示的是指向某个基本类型值的指针。
我们可以通过把取值操作符*放在这样一个指针值的左边来组成一个取值表达式,以获取该指针值指向的基本类型值,也可以通过把取址操作符&放在一个可寻址的基本类型值的左边来组成一个取址表达式,以获取该基本类型值的指针值。
所谓的指针方法,就是接收者类型是上述指针类型的方法。
那么值方法和指针方法之间有什么不同点呢?它们的不同如下所示。
1、值方法的接收者是该方法所属的那个类型值的一个副本。我们在该方法内对该副本的修改一般都不会体现在原值上,除非这个类型本身是某个引用类型(比如切片或字典)的别名类型。
而指针方法的接收者,是该方法所属的那个基本类型值的指针值的一个副本。我们在这样的方法内对该副本指向的值进行修改,却一定会体现在原值上。
2、一个自定义数据类型的方法集合中仅会包含它的所有值方法,而该类型的指针类型的方法集合却囊括了前者的所有方法,包括所有值方法和所有指针方法。
严格来讲,我们在这样的基本类型的值上只能调用到它的值方法。但是,Go 语言会适时地为我们进行自动地转译,使得我们在这样的值上也能调用到它的指针方法。
比如,在Cat类型的变量cat之上,之所以我们可以通过cat.SetName("monster")修改猫的名字,是因为 Go 语言把它自动转译为了(&cat).SetName("monster"),即:先取cat的指针值,然后在该指针值上调用SetName方法。
3、在后边你会了解到,一个类型的方法集合中有哪些方法与它能实现哪些接口类型是息息相关的。如果一个基本类型和它的指针类型的方法集合是不同的,那么它们具体实现的接口类型的数量就也会有差异,除非这两个数量都是零。
比如,一个指针类型实现了某某接口类型,但它的基本类型却不一定能够作为该接口的实现类型。
能够体现值方法和指针方法之间差异的小例子我放在 demo30.go 文件里了,你可以参照一下。
package main
import "fmt"
type Cat struct {
name string // 名字。
scientificName string // 学名。
category string // 动物学基本分类。
}
func New(name, scientificName, category string) Cat {
return Cat{
name: name,
scientificName: scientificName,
category: category,
}
}
func (cat *Cat) SetName(name string) {
cat.name = name
}
func (cat Cat) SetNameOfCopy(name string) {
cat.name = name
}
func (cat Cat) Name() string {
return cat.name
}
func (cat Cat) ScientificName() string {
return cat.scientificName
}
func (cat Cat) Category() string {
return cat.category
}
func (cat Cat) String() string {
return fmt.Sprintf("%s (category: %s, name: %q)",
cat.scientificName, cat.category, cat.name)
}
func main() {
cat := New("little pig", "American Shorthair", "cat")
cat.SetName("monster") // (&cat).SetName("monster")
fmt.Printf("The cat: %s\\n", cat)
cat.SetNameOfCopy("little pig")
fmt.Printf("The cat: %s\\n", cat)
type Pet interface {
SetName(name string)
Name() string
Category() string
ScientificName() string
}
_, ok := interface{}(cat).(Pet)
fmt.Printf("Cat implements interface Pet: %v\\n", ok)
_, ok = interface{}(&cat).(Pet)
fmt.Printf("*Cat implements interface Pet: %v\\n", ok)
}
总结
结构体类型的嵌入字段比较容易让 Go 语言新手们迷惑,所以我在本篇文章着重解释了它的编写方法、基本的特性和规则以及更深层次的含义。在理解了结构体类型及其方法的组成方式和构造套路之后,这些知识应该是你重点掌握的。
嵌入字段是其声明中只有类型而没有名称的字段,它可以以一种很自然的方式为被嵌入的类型带来新的属性和能力。在一般情况下,我们用简单的选择表达式就可以直接引用到它们的字段和方法。
不过,我们需要小心可能产生“屏蔽”现象的地方,尤其是当存在多个嵌入字段或者多层嵌入的时候。“屏蔽”现象可能会让你的实际引用与你的预期不符。
另外,你一定要梳理清楚值方法和指针方法的不同之处,包括这两种方法各自能做什么、不能做什么以及会影响到其所属类型的哪些方面。这涉及值的修改、方法集合和接口实现。
最后,再次强调,嵌入字段是实现类型间组合的一种方式,这与继承没有半点儿关系。Go 语言虽然支持面向对象编程,但是根本就没有“继承”这个概念。
思考题
- 我们可以在结构体类型中嵌入某个类型的指针类型吗?如果可以,有哪些注意事项?
- 字面量struct{}代表了什么?又有什么用处?

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
Go语言核心36讲(Go语言进阶技术十六)--学习笔记
22 | panic函数、recover函数以及defer语句(下)
我在前一篇文章提到过这样一个说法,panic 之中可以包含一个值,用于简要解释引发此 panic 的原因。
如果一个 panic 是我们在无意间引发的,那么其中的值只能由 Go 语言运行时系统给定。但是,当我们使用panic函数有意地引发一个 panic 的时候,却可以自行指定其包含的值。我们今天的第一个问题就是针对后一种情况提出的。
知识扩展
问题 1:怎样让 panic 包含一个值,以及应该让它包含什么样的值?
这其实很简单,在调用panic函数时,把某个值作为参数传给该函数就可以了。由于panic函数的唯一一个参数是空接口(也就是interface{})类型的,所以从语法上讲,它可以接受任何类型的值。
但是,我们最好传入error类型的错误值,或者其他的可以被有效序列化的值。这里的“有效序列化”指的是,可以更易读地去表示形式转换。
还记得吗?对于fmt包下的各种打印函数来说,error类型值的Error方法与其他类型值的String方法是等价的,它们的唯一结果都是string类型的。
我们在通过占位符%s打印这些值的时候,它们的字符串表示形式分别都是这两种方法产出的。
一旦程序异常了,我们就一定要把异常的相关信息记录下来,这通常都是记到程序日志里。
我们在为程序排查错误的时候,首先要做的就是查看和解读程序日志;而最常用也是最方便的日志记录方式,就是记下相关值的字符串表示形式。
所以,如果你觉得某个值有可能会被记到日志里,那么就应该为它关联String方法。如果这个值是error类型的,那么让它的Error方法返回你为它定制的字符串表示形式就可以了。
对于此,你可能会想到fmt.Sprintf,以及fmt.Fprintf这类可以格式化并输出参数的函数。
是的,它们本身就可以被用来输出值的某种表示形式。不过,它们在功能上,肯定远不如我们自己定义的Error方法或者String方法。因此,为不同的数据类型分别编写这两种方法总是首选。
可是,这与传给panic函数的参数值又有什么关系呢?其实道理是相同的。至少在程序崩溃的时候,panic 包含的那个值字符串表示形式会被打印出来。
另外,我们还可以施加某种保护措施,避免程序的崩溃。这个时候,panic 包含的值会被取出,而在取出之后,它一般都会被打印出来或者记录到日志里。
既然说到了应对 panic 的保护措施,我们再来看下面一个问题。
问题 2:怎样施加应对 panic 的保护措施,从而避免程序崩溃?
Go 语言的内建函数recover专用于恢复 panic,或者说平息运行时恐慌。recover函数无需任何参数,并且会返回一个空接口类型的值。
如果用法正确,这个值实际上就是即将恢复的 panic 包含的值。并且,如果这个 panic 是因我们调用panic函数而引发的,那么该值同时也会是我们此次调用panic函数时,传入的参数值副本。请注意,这里强调用法的正确。我们先来看看什么是不正确的用法。
package main
import (
"fmt"
"errors"
)
func main() {
fmt.Println("Enter function main.")
// 引发panic。
panic(errors.New("something wrong"))
p := recover()
fmt.Printf("panic: %s\\n", p)
fmt.Println("Exit function main.")
}
在上面这个main函数中,我先通过调用panic函数引发了一个 panic,紧接着想通过调用recover函数恢复这个 panic。可结果呢?你一试便知,程序依然会崩溃,这个recover函数调用并不会起到任何作用,甚至都没有机会执行。
还记得吗?我提到过 panic 一旦发生,控制权就会讯速地沿着调用栈的反方向传播。所以,在panic函数调用之后的代码,根本就没有执行的机会。
那如果我把调用recover函数的代码提前呢?也就是说,先调用recover函数,再调用panic函数会怎么样呢?
这显然也是不行的,因为,如果在我们调用recover函数时未发生 panic,那么该函数就不会做任何事情,并且只会返回一个nil。
换句话说,这样做毫无意义。那么,到底什么才是正确的recover函数用法呢?这就不得不提到defer语句了。
顾名思义,defer语句就是被用来延迟执行代码的。延迟到什么时候呢?这要延迟到该语句所在的函数即将执行结束的那一刻,无论结束执行的原因是什么。
这与go语句有些类似,一个defer语句总是由一个defer关键字和一个调用表达式组成。
这里存在一些限制,有一些调用表达式是不能出现在这里的,包括:针对 Go 语言内建函数的调用表达式,以及针对unsafe包中的函数的调用表达式。
顺便说一下,对于go语句中的调用表达式,限制也是一样的。另外,在这里被调用的函数可以是有名称的,也可以是匿名的。我们可以把这里的函数叫做defer函数或者延迟函数。注意,被延迟执行的是defer函数,而不是defer语句。
我刚才说了,无论函数结束执行的原因是什么,其中的defer函数调用都会在它即将结束执行的那一刻执行。即使导致它执行结束的原因是一个 panic 也会是这样。正因为如此,我们需要联用defer语句和recover函数调用,才能够恢复一个已经发生的 panic。
我们来看一下经过修正的代码。
package main
import (
"fmt"
"errors"
)
func main() {
fmt.Println("Enter function main.")
defer func(){
fmt.Println("Enter defer function.")
if p := recover(); p != nil {
fmt.Printf("panic: %s\\n", p)
}
fmt.Println("Exit defer function.")
}()
// 引发panic。
panic(errors.New("something wrong"))
fmt.Println("Exit function main.")
}
在这个main函数中,我先编写了一条defer语句,并在defer函数中调用了recover函数。仅当调用的结果值不为nil时,也就是说只有 panic 确实已发生时,我才会打印一行以“panic:”为前缀的内容。
紧接着,我调用了panic函数,并传入了一个error类型值。这里一定要注意,我们要尽量把defer语句写在函数体的开始处,因为在引发 panic 的语句之后的所有语句,都不会有任何执行机会。
也只有这样,defer函数中的recover函数调用才会拦截,并恢复defer语句所属的函数,及其调用的代码中发生的所有 panic。
至此,我向你展示了两个很典型的recover函数的错误用法,以及一个基本的正确用法。
我希望你能够记住错误用法背后的缘由,同时也希望你能真正地理解联用defer语句和recover函数调用的真谛。
在命令源码文件 demo50.go 中,我把上述三种用法合并在了一段代码中。你可以运行该文件,并体会各种用法所产生的不同效果。
package main
import (
"errors"
"fmt"
)
func main() {
fmt.Println("Enter function main.")
defer func() {
fmt.Println("Enter defer function.")
// recover函数的正确用法。
if p := recover(); p != nil {
fmt.Printf("panic: %s\\n", p)
}
fmt.Println("Exit defer function.")
}()
// recover函数的错误用法。
fmt.Printf("no panic: %v\\n", recover())
// 引发panic。
panic(errors.New("something wrong"))
// recover函数的错误用法。
p := recover()
fmt.Printf("panic: %s\\n", p)
fmt.Println("Exit function main.")
}
下面我再来多说一点关于defer语句的事情。
问题 3:如果一个函数中有多条defer语句,那么那几个defer函数调用的执行顺序是怎样的?
如果只用一句话回答的话,那就是:在同一个函数中,defer函数调用的执行顺序与它们分别所属的defer语句的出现顺序(更严谨地说,是执行顺序)完全相反。
当一个函数即将结束执行时,其中的写在最下边的defer函数调用会最先执行,其次是写在它上边、与它的距离最近的那个defer函数调用,以此类推,最上边的defer函数调用会最后一个执行。
如果函数中有一条for语句,并且这条for语句中包含了一条defer语句,那么,显然这条defer语句的执行次数,就取决于for语句的迭代次数。
并且,同一条defer语句每被执行一次,其中的defer函数调用就会产生一次,而且,这些函数调用同样不会被立即执行。
那么问题来了,这条for语句中产生的多个defer函数调用,会以怎样的顺序执行呢?
为了彻底搞清楚,我们需要弄明白defer语句执行时发生的事情。
其实也并不复杂,在defer语句每次执行的时候,Go 语言会把它携带的defer函数及其参数值另行存储到一个链表中。
这个链表与该defer语句所属的函数是对应的,并且,它是先进后出(FILO)的,相当于一个栈。
在需要执行某个函数中的defer函数调用的时候,Go 语言会先拿到对应的链表,然后从该链表中一个一个地取出defer函数及其参数值,并逐个执行调用。
这正是我说“defer函数调用与其所属的defer语句的执行顺序完全相反”的原因了。
下面该你出场了,我在 demo51.go 文件中编写了一个与本问题有关的示例,其中的核心代码很简单,只有几行而已。
package main
import "fmt"
func main() {
defer fmt.Println("first defer")
for i := 0; i < 3; i++ {
defer fmt.Printf("defer in for [%d]\\n", i)
}
defer fmt.Println("last defer")
}
总结
我们这两期的内容主要讲了两个函数和一条语句。recover函数专用于恢复 panic,并且调用即恢复。
它在被调用时会返回一个空接口类型的结果值。如果在调用它时并没有 panic 发生,那么这个结果值就会是nil。
而如果被恢复的 panic 是我们通过调用panic函数引发的,那么它返回的结果值就会是我们传给panic函数参数值的副本。
对recover函数的调用只有在defer语句中才能真正起作用。defer语句是被用来延迟执行代码的。
更确切地说,它会让其携带的defer函数的调用延迟执行,并且会延迟到该defer语句所属的函数即将结束执行的那一刻。
在同一个函数中,延迟执行的defer函数调用,会与它们分别所属的defer语句的执行顺序完全相反。还要注意,同一条defer语句每被执行一次,就会产生一个延迟执行的defer函数调用。
这种情况在defer语句与for语句联用时经常出现。这时更要关注for语句中,同一条defer语句产生的多个defer函数调用的实际执行顺序。
以上这些,就是关于 Go 语言中特殊的程序异常,及其处理方式的核心知识。这里边可以衍生出很多面试题目。
思考题
我们可以在defer函数中恢复 panic,那么可以在其中引发 panic 吗?
笔记源码
https://github.com/MingsonZheng/go-core-demo

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
欢迎转载、使用、重新发布,但务必保留文章署名 郑子铭 (包含链接: http://www.cnblogs.com/MingsonZheng/ ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。
以上是关于Go语言核心36讲(Go语言进阶技术七)--学习笔记的主要内容,如果未能解决你的问题,请参考以下文章