Linux防火墙iptables之概念篇
Posted 青牛踏雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux防火墙iptables之概念篇相关的知识,希望对你有一定的参考价值。
- 为什么要学Linux防火墙?当你所在公司,出于安全原因,想上防火墙,而各大云厂商云防火墙和硬件防火墙费用及其昂贵,出于成本考虑,此时Linux的防火墙就是最好的解决方案,如果有较高且复杂的防护需求时,也可以考虑上开源的WAF,如OpenResty、OpenWAF等,这里就不过多叙述了,可以自行谷歌了解。
- Docker底层的网络转发是通过Linux内核模块netfilter/iptables完成工作的,以及流行编排工具Kubernetes的各个网络插件也是,如果对iptables的理解不够深入以及操作不熟练的话,那么在排查网络、路由问题的时候,必然会困难重重。所以学好netfilter/iptables,必将事半功倍。

netfilter/iptables是什么?
netfilter/iptables 是在Linux下工作的免费防火墙,完成拆包、过滤、封包、重定向、网络地址转换(NAT)等功能。相比各大厂商昂贵的硬件防火墙来比,它是当前最完善最稳定的防火墙解决方案。
Linux的iptables只是作为内核netfilter的代理,转储rule,真正完成安全防护功能的是位于内核空间中的netfilter模块。
iptables只是作为用户操作的一个记录、更新、删除rule的使用工具。
iptables中最核心的是 四表五链,所有rule动作都是基于 四表五链 操作内核模块netfilter完成工作的。
对于ubuntu的ufw,是基于iptables封装的一层及其友好的操作命令,会在第二篇 Linux防火墙iptables之Kubernetes篇 中,做延伸讲解。
为了更好的理解iptables原理与实践,引入Kubernetes作为演示案例,以图文形式循序渐进的来讲解iptables在Kubernetes中是怎样完成工作的。
此篇主要是通过图文形式讲解iptables的四表五链对应关系、工作过程以及相关名词,用于了解iptables的整体概念。
iptables 基础
我们都知道iptables是按照rule来工作的,rule其实就是操作人员预定义的条件,rule一般的定义为: "如果数据包符合条件,就对对应的数据进行操作"。rule存放在内核空间的信息包filter表中,这些规则包括了源地址、目标地址、源端口、目标端口、传输协议(如ICMP/UDP/TCP)与服务协议(HTTP/FTP/SSH)等。当数据包与rule匹配时,iptables会根据rule定义的条件来处理对应的数据包,比如accept/rejct/drop等操作,用于对防火墙rule的添加、修改、删除等。
如果仅仅通过上述就可以理解netfilter/iptables,那是基本不可能的,因为iptables的抽象层级还是非常高的,为了能很好的理解netfilter/iptables,我们简单的举个栗子来理解。
当客户端访问服务器的某个服务的时候,首先是客户端发送数据报文到网卡,而TCP/IP协议栈是属于内核的一部分,客户端的信息会通过内核的TCP协议传输给用户空间(用户态)的某服务进程,此时,客户端的数据报文到目标地址为服务所监听的套接字IP地址:端口上,服务响应客户端请求时,会发出响应数据报文的目标地址是客户端,也就是说目标地址转换成了源地址。上面已经提过,netfilter是防火墙的核心工作模块,工作在Linux内核中,想让防火墙达到防护的功能,就需要对内核中的netfilter配置对应的拦截rule,可以理解为检查站。所有进出的数据报文必须经过检查站,经过rule筛选后,放行符合rule的数据包,拦截拒绝rule的数据包,这里面就有了 input 和 output的概念 ,在iptables中的名词是链,也就是 四表五链中的五链之二,对于 四表五链,后面会详细的讲解。

上面的描述仅仅是逻辑的一种抽象表达,因为发起者也有可能不是客户端而是其他的服务器,当本机开启了ip_forward功能,就具备了路由转发功能,这个时候就会用到iptables 四表五链 中的 PREROUTING、FORWARD、POSTROUTING。
当开启了防火墙的时候,数据报文会经过以下的步骤完成,根据实际场景的改变,经过的链也会有所改变。
当数据报文不需要转发的时候,会进入input链到用户空间经过服务处理完成后,然后在由output链通过postrouting链返回目标地址。如果数据报文需要转发的时候,会直接在内核中通过forward链完成转发动作,经由output链直接将数据报文送向目标地址。

由上图可以看出来,四表五链中的五链完整的的工作过程。
-
由当前主机转发数据报文: prerouting –> forward –> postrouting
-
进入当前主机,到达用户空间的服务进程数据报文: prerouting –> input。
-
由当前主机中的用户空间服务进程处理的数据报文: output –> postrouting
什么是链?
通过上述已经了解到,iptables是对经过的数据报文匹配rule,然后执行对应的操作,当数据报文经过检查站的时候,必须匹配当前检查站的rule,而每个检查站中存在的不是一个rule,而是由多个rule组成,当所有rule被应用执行的时候,就形成了链。每个链经过的数据报文都会以顺序匹配对应rule,对符合条件的做对应的操作,如下图所示。

什么是表?
通过上述已经了解到了什么是链,而且也了解到每个链是对n+1的rule做匹配与数据报文处理,那么我们现在想要实现另外一个功能,比如rule1是修改数据报文,rule2是对IP端口做开放或限制,这个时候,我们就用到了iptables中的表功能。iptables的表其实就是把不同功能的rule做了分类管理,而这个功能就是我们上面提到的四表五链中的四表,所有的规则都是由以下的四表归类管理。
filter 负责过滤功能。
模块: iptables_filter
nat 网络地址转换。
模块:iptable_nat
mangle 对数据报文拆解、修改、重新封装的功能;
模块: iptable_mangle
raw 关闭nat表上启用的连接追踪机制;
模块: iptable_raw
链与表的关系
首先要知道,某些链并不是万能的,它可能不具备你需要的功能,所以这个时候,必须要了解每个链上的rule与每个表的对应关系。
如下图,来看看filter表支持哪些链?

上图的意思其实就是说 filler表 所具备的功能可以被应用的链被限定为input foward output。
综上所述,我们可以总结一下表链之间的关系:
Filter 可以被应用的链为 INPUT、FORWARD、OUTPUT。
Nat 可以被应用的链为OUTPUT、PREROUTING、POSTROUTING
Mangle 可以被用应用在所有链:INPUT、FORWARD、OUTPUT、PREROUTING、POSTROUTING。
Raw 可以被应用的链为OUTPUT、PREROUTING
如下图:

为了更好的理解,换个思路在理解一下对应关系,哪些链的rule可以被哪些表调用?
INPUT 可以调用的表:mangle、filter
OUTPUT 可以调用的表:raw、mangle、nat、filter
PREROUTING 可以调用的表:raw、mangle、nat
FORWARD 可以调用的表:mangle、filter。
POSTROUTING 可以调用的表:mangle、nat
如下图:

另外需要注意的是,数据报文经过链的时候,会顺序匹配所有rule,那么这里就会涉及到优先级的问题,哪些表的rule会先于链被执行?到底谁先被执行?
请看下图:

如上所述,PREROUTING链可以被调用的是这三张表,其优先级是 raw --> mangle --> nat。
但是我们知道iptables的表是四张,当他们同时被应用在一个链的时候,优先级如下图:

但是,如上述所言,某些链的rule不能被应用到某些表,所以,你要知道,当前能被四表调用的链只有OUTPUT链。
为了便于管理,可以在表中自定义链,把自己需要的rule放在这个自定义链中,但是要注意的是,这个链不能被表直接调用,而是在某个默认链将这个链引用,也就是在五链之一中的某个链中配置成动作才会生效。
iptables工作流程
下图是数据包通过iptables的流程:

上图描述的工作流程:
根据路由匹配发送给服务进程的数据包
- 数据包由客户端发送到网卡,然后由网卡传入内核态中的
prerouting链,在raw、mangle、nat表 由上到下的顺序对rule进行匹配,对数据包处理完成后,经过路由判断,确定发送目标地址为本机的服务进程,进入input链,在mangle、nat、filter表 由上到下的顺序对rule进行匹配,然后对数据包进行处理后,交由用户空间的服务进程对数据包进行处理。 - 当数据包在用户空间的服务进程处理完成后,由本机作为源地址根据路由判断将数据包经由
output链对raw、mangle、nat、filter由上到下的顺序对rule进行匹配,对数据包进行处理,送由postrouting链,在mangle、nat表由上到下的顺序对rule进行匹配,根据匹配rule对数据包进行最后的封装处理,离开内核空间,经由网卡,返回给客户端。
根据路由匹配发送给其他服务器的数据包
- 数据包由客户端发送到网卡,然后传入内核态中的
prerouting链,在raw、mangle、nat表 由上到下的顺序对rule进行匹配,对数据包处理完成后,经过路由判断,如果不是发送本机的服务进程的数据包,则由forward链,在mangle、filter链由上到下的顺序对rule进行匹配,对数据包进行处理。 - 当
forwanrd链对数据包处理完成后,送由postrouting链,在mangle、nat表由上到下的顺序rule匹配,对数据包进行最后封装处理,离开内核空间,经由网卡,发送给其他服务器。
当把上述图以及流程理解透彻了,这个时候,你对iptables的工作流程已经完全掌握了,在后续的实践操作中可以灵活的应用各种rule了。
什么是rule?
在上述中四表五链中提的rule的时候,都是简单的一带而过,现在我们来详细的说下什么是rule,rule其实就是根据既定条件匹配每个链经过的数据报文,当匹配到对应的rule以后,则由匹配的rule配置好的相关动作来处理对应的操作。
其实简单来讲,就如上诉所言iptables每条链都是一个检查站,每个通过检查站的数据报文都要在此处经过rule规则处理一遍,如果匹配,则对数据报文进行对应的操作。比如:此时rule配置中对80端口开放了通行规则,而没有对443开放,这个时候俩个带有标记的数据报文在进入检查站的时候,80会匹配对应的规则而被放行,进入到目标地址,经过数据的拆包、封装等处理之后返回给客户端。而443不在放行规则内,则会被丢弃。这里的80、443是rule当中的一种条件,而放行、拒绝则是rule匹配之后对应的动作,也就是说,条件+动作组成了相应的规则。
匹配条件
匹配条件分为基本匹配条件与扩展匹配条件。
-
基本匹配条件
源地址 Source IP
目标地址 Destination IP
-
扩展匹配条件:
除了基本匹配条件之外,还有名词为扩展匹配条件,这些属于netfilter中的一部分,只是以模块形式存在,如果想使用对应的扩展匹配条件,需要依赖对应的扩展模块。
源地址 Source IP:Port
目标地址 Destination IP:Port
处理动作
处理动作在iptables中名词为target,动作分为基本动作和扩展动作。
ACCEPT 允许数据包通过。
DROP 直接丢弃数据包,不返回任何回应信息,只对超时时间才有回应信息。
REJECT 拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
SNAT 对源地址做出转换,用于内网用户用同一个公网地址上网。
MASQUERADE 是SNAT的一种特殊形式,适用于动态的IP上。
DNAT 目标地址转换。
REDIRECT 在本机端口转发、映射。
LOG 只是记录对应的数据包传递过程的日志,不对数据报文做任何动作,用于审计与DEBUG。
- 本文对iptables中四表五链的对应关系、工作流程通过图文的形式做了详细讲解,也对相关名词做了简要的描述,读完的同学,对iptables的概念基本了解清楚了,下一篇 Linux防火墙iptables之Kubernetes篇 中,会引入
Kubernetes作为案例使大家对iptables有更为详细深入的理解。 - 本文提及到内核态到用户态进程之间切换涉及到的知识点,并没有深入讲解,后面会单独出一个对内核以图文方式由浅入深讲解的文章,敬请期待。
在基于DevOps思想对自动化运维改革的大道上,一直砥砺前行,从未停歇。
道阻且长,行则将至,行而不辍,未来可期。
欢迎搜索 k8stech 关注公众号 Kubernetes技术栈,定时更新关于运维开发、云原生、SRE等文章。
软件防火墙之iptables/netfilter概念篇(一)
简介
在讲防火墙的时候,不得不说的是iptables,本文尽量以通俗易懂的方式描述iptables的相关概念,请耐心的读完。
防火墙分类及说明
从逻辑上讲防火墙分为主机防火墙和网络防火墙两类。
- 主机防火墙: 针对单个主机进行防护;
- 网络防火墙:往往处于网络入口或边缘,针对于网络入口进行防护,服务于防火墙背后的本地局域网。
网络防火墙和主机防火墙并不冲突,可以理解为,网络防火墙是对一个集体的防范,主机防火墙则是对个人的防范。
从物理上讲,防火墙可以分为硬件防火墙和软件防火墙。
- 硬件防火墙:在硬件级别实现部分防火墙功能,另一部分功能基于软件实现,性能高,成本高。
软件防火墙:应用软件处理逻辑运行于通用硬件平台之上的防火墙,性能低,成本低。
接下来我们来聊老linux的iptables。什么是netfilter和iptables
简单点的来说:- netfilter指整个项目,不然官网就不会叫www.netfilter.org了。
- netfilter特指内核中的netfilter框架,iptables指用户空间的配置工具。
- netfilter在协议栈中添加了5个钩子,允许内核模块在这些钩子的地方注册回调函数,这样经过钩子的所有数据包都会被注册在相应钩子上的函数所处理,包括修改数据包内容、给数据包打标记或者丢掉数据包等。
- netfilter框架负责维护钩子上注册的处理函数或者模块,以及它们的优先级。
- iptables是用户空间的一个程序,通过netlink和内核的netfilter框架打交道,负责往钩子上配置回调函数。
netfilter框架负责在需要的时候动态加载其它的内核模块,比如ip_conntrack、nf_conntrack、NAT subsystem等。
小结:iptables工作在用户空间,是一个命令行工具,我们用这个工具来操作真正的框架,netfilter工作在内核模块。
netfilter钩子
在内核协议栈中,有5个跟netfilter有关的钩子,数据包经过每个钩子时,都会检查上面是否注册有函数,如果有的话,就会调用相应的函数处理数据包,他们的位置见下图:
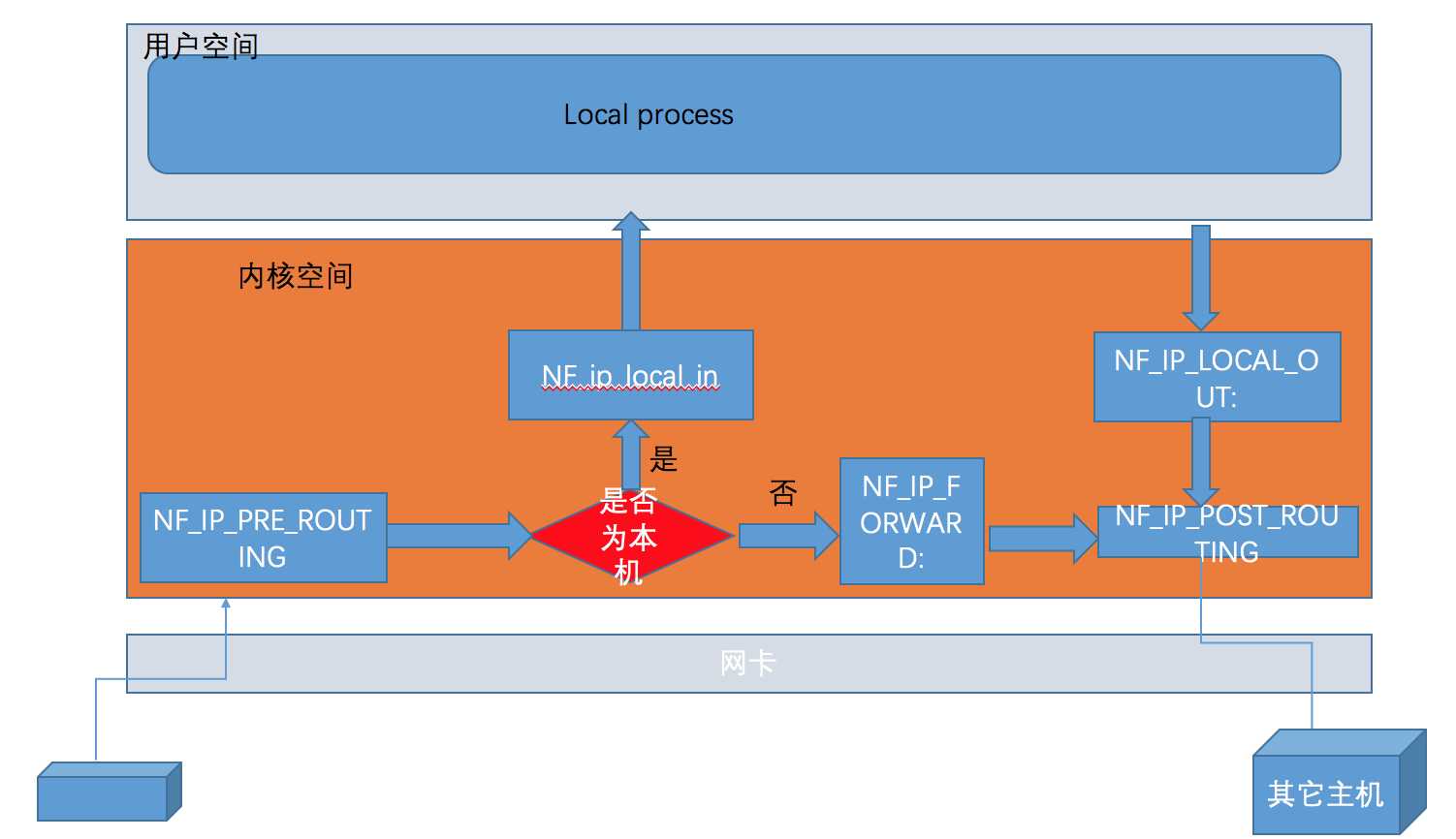
- NF_IP_PRE_ROUTING: 接收的数据包刚进来,还没有经过路由选择,即还不知道数据包是要发给本机还是其它机器。
- NF_IP_LOCAL_IN: 已经经过路由选择,并且该数据包的目的IP是本机,进入本地数据包处理流程。
- NF_IP_FORWARD: 已经经过路由选择,但该数据包的目的IP不是本机,而是其它机器,进入forward流程。
- NF_IP_LOCAL_OUT: 本地程序要发出去的数据包刚到IP层,还没进行路由选择。
- NF_IP_POST_ROUTING: 本地程序发出去的数据包,或者转发(forward)的数据包已经经过了路由选择,即将交由下层发送出去。
根据上图,我们能够想象出某些常用场景中,数据包的流向:
- 本机收到目的IP是本机的数据包: NF_IP_PRE_ROUTING -> NF_IP_LOCAL_IN
- 本机收到目的IP不是本机的数据包: NF_IP_PRE_ROUTING -> NF_IP_FORWARD -> NF_IP_POST_ROUTING
- 本机发出去的数据包: NF_IP_LOCAL_OUT -> NF_IP_POST_ROUTING
注意: netfilter所有的钩子都是在内核协议栈的ip层,由于ipv4和ipv6用的是不同的ip层代码,所以iptables配置的rules只会影响ipv4的数据包,而ipv6相关的配置需要使用ip6tables。iptables中的表
iptables用表来管理它的rule,根据rule的作用分成了好几张表,比如用来过滤数据包的filter表,用于处理地址转换的rule就会放到nat表中,如果我们自己在开发权限的时候,因为这个不需要跟用户挂钩,所以大家理解为根据不同的功能将权限给划分到不同的表里面,如果要配置某个权限就需要操作那张表是一个道理,其中rule就是应用在netfilter钩子上的函数,用来修改或者过滤数据包。目前iptables支持的表如表所示:
| 表名 | 用途 |
|---|---|
| filter | 这个表里面的规则主要用来过滤数据,用来控制让那些数据可以通过,那些数据不可以通过 |
| nat | 这个表里面的rule是用来处理网络地址转换的,控制要不要进行地址转换,以及怎样修改源地址和目标地址,从容影响数据包的路由 |
| mangle | 主要用来修改ip数据包头,比如修改ttl值,同时也用于给数据包添加一些标记,从而便于其它模块对数据进行处理 |
| raw | 在netfilter里面有一个叫做connection tracking的功能(后面会介绍到),主要用来追踪所有的连接,而raw表里的rule的功能是给数据包打标记,从而控制哪些数据包不被connection tracking所追踪。 |
| security | 里面的rule跟SELinux有关,主要是在数据包上设置一些SELinux的标记,便于跟SELinux相关的模块来处理该数据包。 |
chains
上面我们说根据不同的功能将rule放到了不同的表里面之后,这些rule会注册到哪些钩子上呢?于是iptables将表中的rule继续分类,让rule属于不同的链(chain),由chain来决定什么时候触发chain上的这些rule。
iptables里面有5个内置的chains,分别对应5个钩子:
- PREROUTING: 数据包经过NF_IP_PRE_ROUTING时会触发该chain上的rule.
- INPUT: 数据包经过NF_IP_LOCAL_IN时会触发该chain上的rule.
- FORWARD: 数据包经过NF_IP_FORWARD时会触发该chain上的rule.
- OUTPUT: 数据包经过NF_IP_LOCAL_OUT时会触发该chain上的rule.
- POSTROUTING: 数据包经过NF_IP_POST_ROUTING时会触发该chain上的rule.
每个表里面都可以包含多个chains,但并不是每个表都能包含所有的chains,因为某些表在某些chain上没有意义或者有些多余,比如说raw表,它只有在connection tracking之前才有意义,所以它里面包含connection tracking之后的chain就没有意义。(connection tracking的位置会在后面介绍到)
多个表里面可以包含同样的chain,比如在filter和raw表里面,都有OUTPUT chain,那应该先执行哪个表的OUTPUT chain呢?这就涉及到后面会介绍的优先级的问题。
提示:可以通过命令iptables -L -t nat|grep policy|grep Chain查看到nat表所支持的chain,其它的表也可以用类似的方式查看到,比如修改nat为raw即可看到raw表所支持的chain。
表链关系
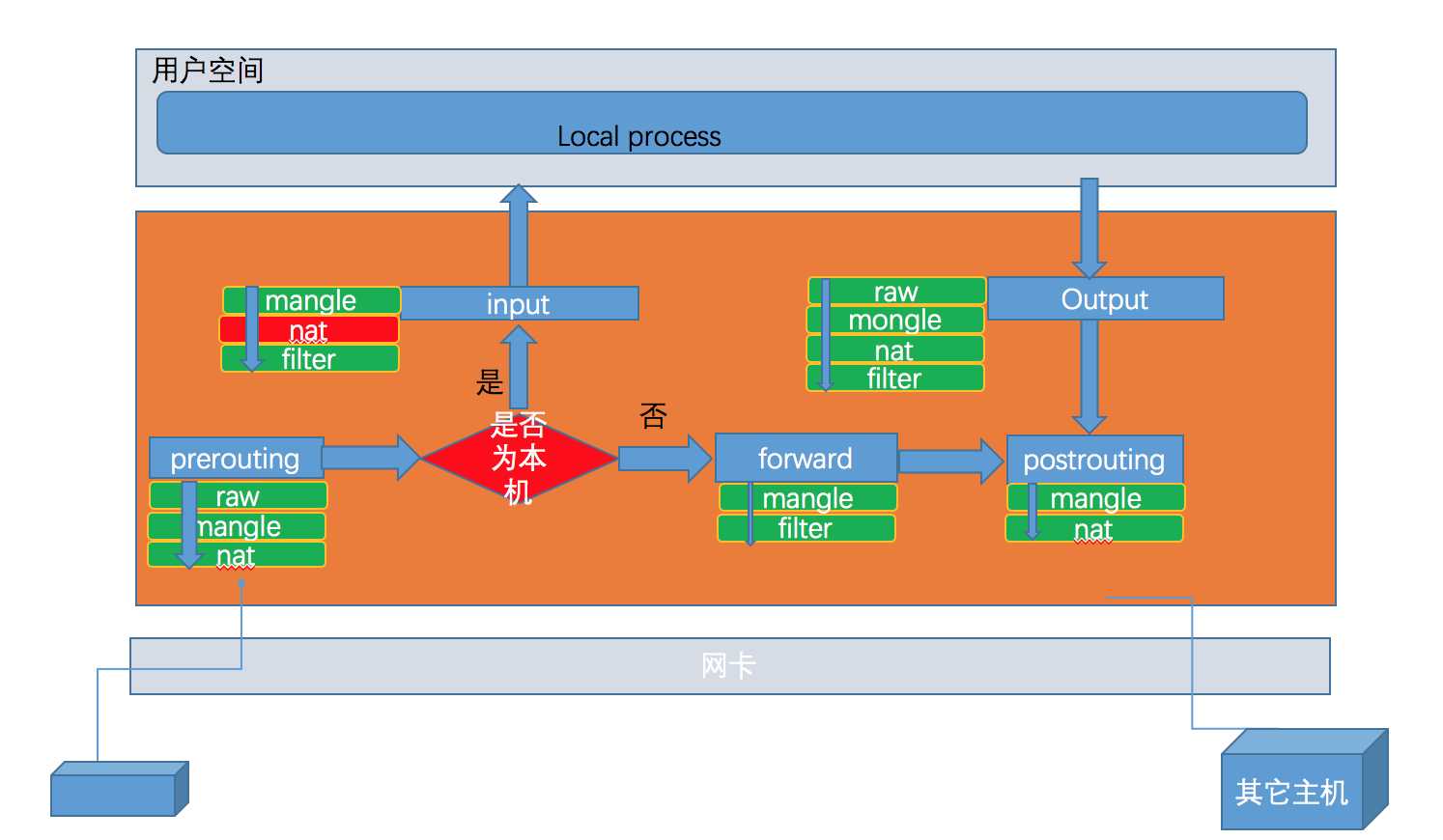
根据上文提到的每个表里面都会有不同的链,不是每个链里面都会有所有的表,我们做下归类:
| chain名 | 表名 |
|---|---|
| prerouting | raw,mangle,nat |
| input | mangle,filter |
| forword | mangle,filter |
| output | raw,nat,filter |
| postrouting | mangle,nat |
但是,我们在实际使用过程中,往往是通过表作为操作入口,对规则进行定义,所以我们将表与链的关系罗列出来。
| 表 | 链 |
|---|---|
| raw | prerouting,output |
| mangle | prerouting,input,forward,output,postrouting |
| nat | prerouting,output,postrouting |
| filter | input,forward,output |
其实我们还需要注意,数据包经过一个链的时候会把所有的规则都执行一遍,所以需要一个优先级问题。关于优先级的定义如下图所示:
通过上图,我们已经知道了表中的规则可以被那些链使用,下面我们做下归纳总结,因为后面我们操作都是通过操作表来操作规则的。
| 表 |链 |
| --- | --- |
| raw |prerouting,output |
|mangle |prerouting,input,forward,output,postrouting |
|nat |prerouting,output,postrouting |
|filter |input,forward,output |
iptables中的规则
rule就是特定表的特定chain上,每条rule包含如下两部分信息
Matching
Matching就是如何匹配一个数据包,匹配条件很多,比如协议类型、源/目的IP、源/目的端口、in/out接口、包头里面的数据以及连接状态等,这些条件可以任意组合从而实现复杂情况下的匹配。详情请参考Iptables matches
targets
tartets就是找到匹配的数据包之后怎么办,常见的有如下四种:
- drop:直接将数据包丢弃,不在进行后续的处理
- reject:拒绝数据包通过,必要时会给数据发送一个响应的信息,
- accept:允许数据包通过。
- snat: 源地址转换,解决内网用户用同一个公网地址上网问题
- masquerade:是snat的一种特殊形式,适用于动态的、临时会变的ip上
- dnat: 目标地址转换
- redirect: 在本机做端口映射
当然iptables包含的targets很多很多,但并不是每个表都支持所有的targets,
rule所支持的target由它所在的表和chain以及所开启的扩展功能来决定,具体每个表支持的targets请参考Iptables targets and jumps。
以上是关于Linux防火墙iptables之概念篇的主要内容,如果未能解决你的问题,请参考以下文章