[所思所想]观《长津湖》有感
Posted 千千寰宇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[所思所想]观《长津湖》有感相关的知识,希望对你有一定的参考价值。
1 组织能力
抗美援朝战争 := 组织能力之战
商场如战场,若商业中的【组织能力】能够有ZG这么强,早晚会是所从事行业的领头羊。可参考的有:huawei
尽管仅有最不利的资源(后勤资源、武器资源、气候资源、时间等),但能物尽其用、人尽其才,每个个体(战士)和小集体(作战单位)主观能动地、充分发挥每份有限资源(人、食物、武器/子弹/炮弹、时间等),并发挥其最大的能量(杀敌),最终达成目标(赢得最终胜利)。这种组织动员能力,实属历史罕见。
2 道义的力量
正道是古人云: 师出必有名。为何必须有名?名即理由、即为什么,以提高自身行为的正当性、正义性,最终提高集体的【士气(信心、恒心、勇气)】。
抗美援朝战争 := 道义的人民之战 VS 帝国侵略主义之战
3 和平可贵,英雄的人民和人民的英雄需我辈铭记 / 一代人有一代人的使命
中国人民迷茫过、摸索并浴血抗争了、奋斗了100余年才获得安定的国家环境,那种对安全、和平的渴望和决心,美军是无法理解和战胜的。










那一代人不打,下几代人就不得不打。所以,铭记那一代人对后续几代人的巨大牺牲。



4 勿忘历史:中国百年近代史(1840-1949)
人民英雄纪念碑碑文
三年以来,在人民解放战争和人民革命中牺牲的人民英雄们永垂不朽!
三十年以来,在人民解放战争和人民革命中牺牲的人民英雄们永垂不朽!
由此上溯到一千八百四十年,从那时起,为了反对内外敌人,争取民族独立和人民自由幸福,在历次斗争中牺牲的人民英雄们永垂不朽!







本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:若本文对您有帮助,可点击右下角【推荐】一下。您的鼓励、【赞赏】(左侧赞赏支付码)是博主技术写作的重要动力!
由AnnotatedElementUtils延伸的一些所思所想
这篇博客的两个主题:
- spring的AnnotatedElementUtils
- 个人源码阅读方法论分享
为什么要分享AnnotatedElementUtils这个类呢,这个类看起来就是一个工具类,听起来很像apache的StringUtils,CollectionUtils。
原因是,它包含着spring对java注解的另类理解,和运用。
java的是怎样支撑注解的?
Class<TestAnnotation> clazz = TestAnnotation.class;
// 获取类注解
MyClassAnnotation myClassAnnotation = clazz.getAnnotation(MyClassAnnotation.class);
// 获得构造方法注解
Constructor<TestAnnotation> cons = clazz.getConstructor(new Class[] {});
MyConstructorAnnotation Constructor = cons.getAnnotation(MyConstructorAnnotation.class);
// 获得方法注解
Method method = clazz.getMethod("setId", new Class[] { String.class });
MyMethodAnnotation myMethodAnnotation = method.getAnnotation(MyMethodAnnotation.class);
// 获得字段注解
Field field = clazz.getDeclaredField("id");
MyFieldAnnotation myFieldAnnotation = field.getAnnotation(MyFieldAnnotation.class);
以及@Inherited,它可以将父类的注解,带到继承体系上的子类中去。
这套注解体系有什么问题?
面向对象语言之所以被冠以“面向对象”这样的名字,是因为它具有多态的能力。有了多态的能力,我们才有了面向接口编程的能力,有了这个能力,依赖反转才有立足点;所有的设计模式才有立足点(工厂模式,装饰器模式,策略模式...)。厦门SEO可以说多态是java这样的强类型,面向对象语言的灵魂。
那么多态这种能力是怎么来的?
父类与接口。弱类型的语言其实天然就支持多态,但强类型的语言则不是。而java在语言层面支持了"父类与接口",关键词排名体现在java程序可以自动的向上转型,并且可以安全的向下转型。向上,向下转型这两件事,就实现了所谓的“多态”语义。
我们再向问题的本质进一步,看看java是怎么实现上下转型的?
当把class文件加载进内存(方法区)时,方法在真正运行之前就有一个确定的调用版本,且该版本在运行期不可变的一类,将会被解析,符号引用将被替换为实在的内存地址,成为该方法的入口地址。静态方法,私有方法,构造器,父类方法符合这个要求。这类方法也被称为非虚方法。
public class Test {
public void test() {
// 实例和方法都是确定的(Human的静态方法run)
Human.run();
}
}
而虚方法和静态分派则是:
// 实例不确定,方法也不确定。
// 此处唯一能确定的是,方法的重载版本。可见这个方法的版本是无参数的,它确定了执行器在调用run时,
// 一定不会去调用一个带任何参数的版本的run方法。这就是静态分派。
public class Test {
public void test(Human human) {
human.run();
}
}
上面提到了重载,而静态分派就是用以确定重载版本的,下面我要说的是覆写。覆写会导致不同实例的覆写版本,方法体不一样,所以虚拟机只能在运行期通过对象的实际类型来决定调用哪个版本的覆写方法。这被称为动态分派。
public class Test {
public void test() {
System.out.println("i‘m Test");
}
}
public class SubTest extends Test {
public void test() {
System.out.println("i‘m SubTest");
}
}
public class TestTest {
public static void main(String[] args) {
Test t = new Test();
t.test();
t = new SubTest();
t.test();
}
}
发现没有,覆写是多态的原理!动态分派是覆写的原理!那么,动态分派也就是多态的原理,进而,动态分派也就是java是面向对象语言的根本原理,或者说根本原因!
而目前,java的注解,并不支持动态分派,就是说它并不支持覆写!这就是目前java这套注解体系的一个重要的问题,它使得注解不易使用。
举例:
- java的注解之间没有继承关系。注意@Inherited表达的不是注解间有继承关系,而是子类可以获得父类的注解。这导致注解的语义不能传递,类似于Man属于Human这样的逻辑它无法表达。
- Java的注解之间没有多态关系,你就是你,我就是我。这导致你可能要将某些相似的处理逻辑放到多个不同的annotation processor里。例:@Component和@Service都有注册bean的能力,则这个能力将在这两个注解的处理器中分别实现。
在深入探究Spring解决方案前,还有一个问题有待解决
在阐述AnnotatedElementUtils前,我要引出今天这次分享的第二个主题:源码阅读方法论。
我问过好多朋友,也在各社区搜索过,如何阅读开源代码这件事情。得到的答案往往是一些“放之四海而皆准”的指导性建议,始终没有得到一个切实可行的方法论,后来我自己总结,摸索了一套。
seo实验室首先问一个问题:当我们说“读源码”时,我们究竟是要做一件什么事情?
以前我对这个问题的回答是:读懂它的逻辑,或叫流程。这个答案背后的含义是,我在乎的是代码中的判断,分支。但是我经常在读源码时有很强的挫败感,因为我很努力的去读,却发现,我读懂了一个方法,而这个类有好几十个方法,我对这个类还是不理解,方法和方法间的关系还是不明朗,类的抽象还是很模糊。
也就是在这个阶段,我请教过很多朋友,以及论坛,甚至每当遇到新的程序员朋友时,我都会问对方这个问题——怎么阅读源码。
直到后来,我看到《人月神话》中有这样一句话:让我看你的流程图不让我看表,我会仍然搞不明白。给我看你的表,一般我就不用看你的流程图了,表能让人一目了然。
这里的表指的是数据,以及数据的结构,例如一个类的成员变量就是它的表;我们写业务的时候,mysql中的数据就是表。《人月神话》的这句话让我突然一惊,难道我一直以来在理解代码的时候,所关注的点是错的,我不应该关注逻辑,而应该关注表?
验证这个道理的最好办法,就是运用它,实验它!
在这里我可以告诉大家,它是对的!我的方法论就是建立在它之上的。
源码阅读方法论——原则
-
以类为最小理解单位(指的是聚合类)
当你要读源码时,将一个类看作一个整体去理解,这个类有些什么方法,其实并不是很重要,重要的是,这个类是个什么东西,或者说抽象是什么(这里仅指聚合类,聚合类指的是它的方法和表是为同一件事情而存在的。举个例子,apache的StringUtils是一个非聚合类,它的方法之间没有必然联系,是各自为正的;而spring的AnnotationTypeMapping则是一个聚合类,它的表和方法都围绕着某个注解而工作,这个类后面会重点介绍)。
-
以表为支点
理解一个类,就是去理解这个类的表(而不是它的业务方法)!理解表有多种途径:通过注释,通过表的设值函数,通过表的使用函数,通过其他文章等等。在理解表的这些途径中,表的设值函数通常来说是能提供最多信息的地方,所以类的构造函数和设值方法是我们首先应该关注的东西。
源码阅读方法论——技巧
-
打锚点,协助思维跳跃
在读源码的时候,经常遇到你要跨越很多次方法调用的情况,人脑的栈是比较小的,所以我通过打锚点的方式,来协助大脑记忆调用栈。
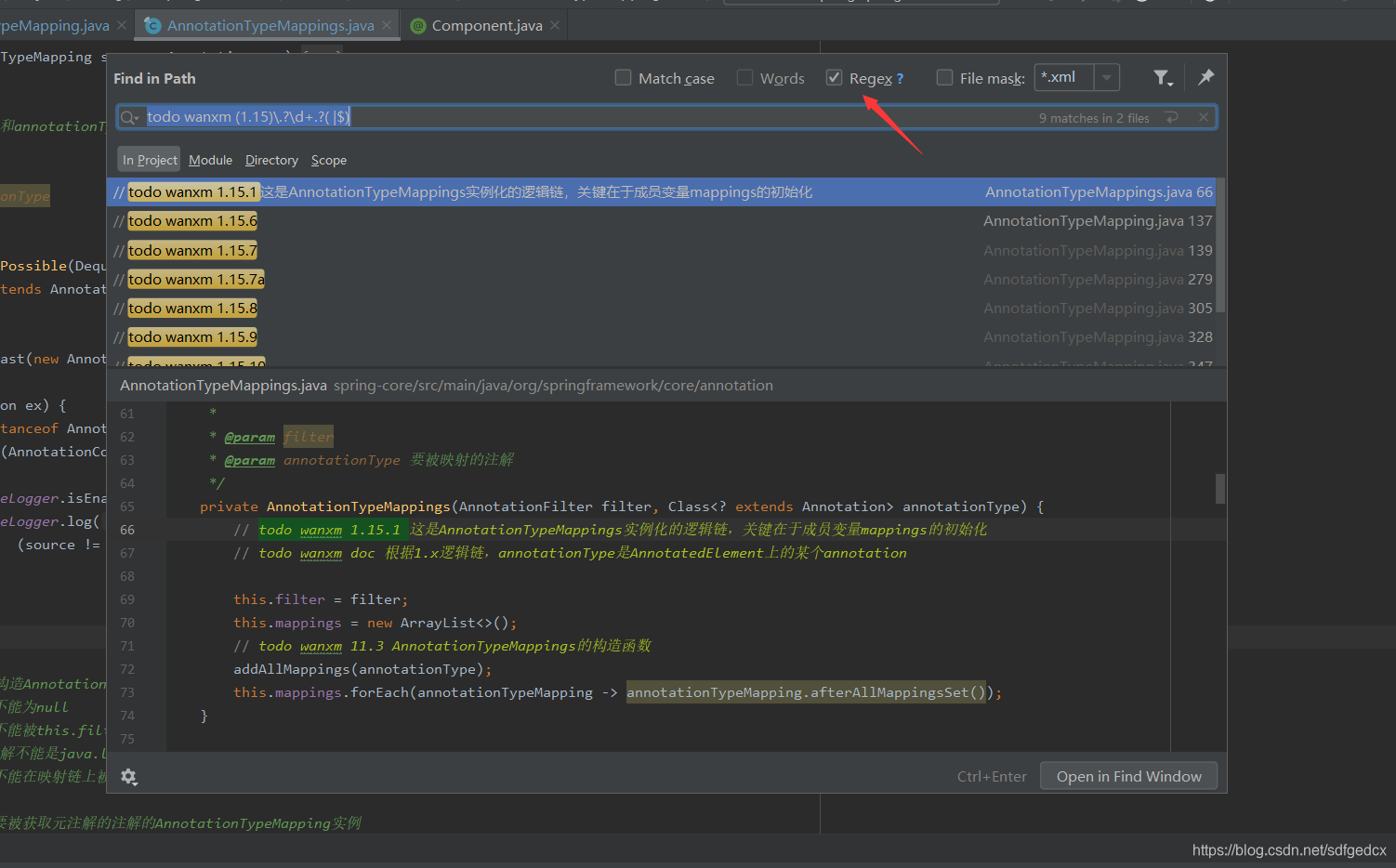
打锚点是通过在关键代码上标注 todo 注释实现的。例如下图中的“// todo wanxm 1.15.1”。配合这个正则表达式:
todo wanxm (1.15).?d+.?( |$)这里相当于列出了一条1.15.x的链,x可以是增量的,表示着某种你想要的先后顺序(比如方法调用顺序,逻辑点顺序等)。前缀1.15也是可变的,例如你在图中看到的这条1.15.x的链,其实是我在读一条1.x的链,读到1.15这个点上时,我发现它后面有挺多内容,于是我在1.15这个点上使用1.15.0开了一条嵌套链。当我使用Idea的Ctrl + Shift + F 搜索时,使用“todo wanxm (1).?d+.?( |$)”我就能看到那条1.x的链,使用“todo wanxm (1.15).?d+.?( |$)”时,就能看到那条1.15.x的链。
-
使用idea的Ctrl + Alt + H,来跟踪类的初始化链。
-
使用“设”,来简化描述语言。例如后面的文章我将会展示的一段“设”:
/** * 设AnnotationTypeMapping的某个实例为M,M所映射的注解为A。 * A中有5个属性(方法):H0,H1,H2,H3,H4。(H后面的数字表示方法的行文索引) */
源码阅读方法论——步骤
-
开始之前先定目的
目的,在我们读源码的过程中,是非常重要的,其一:如果没有一个清晰明确的目的,你很可能被程序中纷繁的细节所包围,抓不住重点,搞不清楚自己要干什么,有了明确的目的,可以让你在深陷细节泥潭时跳脱出来,重新寻找支点。其二:要确定目的则你必需对你所要阅读的代码有一定的了解,这能促使你在阅读前,先去做一定的准备工作,从侧面先对代码有一个概念性的,笼统的认识。
-
构建依赖图
依赖图的构建方法有很多,你可以是从其他文章中看来的,也可以是自己找一个切入点,速读代码构建依赖图。
-
根据依赖图,自底向上,逐个理解类以及接口
理解类的时候,先以类的构造函数(或设值函数)为主,功能方法为辅理解类的表;后以表为支点,理解类。
有一些类,其表很简单甚至没有,而其功能方法决定了类的能力,这种类就以功能方法为支点来理解,通常这种类,读懂了功能方法,也就明了了
有时,会因为我们不理解构造函数的参数的用意而导致我们无法有效的通过构造函数去理解表,此时从依赖图中找到最底层,最接近该类的一处实例化过程去阅读,以搞清楚构造函数中参数的语义。
带着方法论,探索Spring
到这里,今天的主角AnnotatedElementUtils就要登场了,它虽然名字叫做utils,但它可不是一个工具类那么简单,它蕴含着spring对注解这种语法的思考。
我是通过阅读《Spring Boot 编程思想》这本书了解到AnnotatedElementUtils的,书中没有详细展开介绍它,但是通过书中的描述,我知道了spring对注解的处理,是不同于java反射的语义的。我们就来读一读,看看有什么奥秘。我的阅读目的就是:spring怎样让注解实现属性覆写?
先展示一下AnnotatedElementUtils的作用
@TestA
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestRoot {
}
@TestB
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestA {
@AliasFor(value = "c1", annotation = TestC.class)
String bb() default "testA";
}
@TestC
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestB {
@AliasFor(value = "c2", annotation = TestC.class)
String cc() default "testB";
}
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestC {
@AliasFor(value = "c2")
String c1() default "testC";
@AliasFor(value = "c1")
String c2() default "testC";
}
从AnnotatedElementUtils开始构建依赖图
AnnotatedElementUtils这个类没有表,显然它只是某些其他类的代理,既然没有表,按照我们的方法论,它就没有什么太多可理解的了,我们读一读它的注释:
AnnotatedElementUtils(类)
- 查找注释通用方法。就是从AnnotatedElement上获取注释信息。
- 它和jdk提供的原生反省不一样。
- 它提供了两类查找,一类是get语义的查找,一类是find语义的查找
- get语义的查找可查找到直接定义在AnnotatedElement上的,或继承来的注解。
- find则比get要广
- AnnotatedElement是类,则搜索这个类的超类,和接口
- AnnotatedElement是方法,则搜索这个方法的桥接方法,以及超类和接口中的方法。(桥接方法:https://blog.csdn.net/alex_xfboy/article/details/86609055)
- get和find都支持@Inherited
- 在组合注解中的元注解的属性复写功能被以下方法(及其重载方法)支持
- getMergedAnnotationAttributes
- getMergedAnnotation
- getAllMergedAnnotations
- getMergedRepeatableAnnotations
- findMergedAnnotationAttributes
- findMergedAnnotation
- findAllMergedAnnotations
- findMergedRepeatableAnnotations
黑帽seo从注释里我们知道,它有一堆get和find方法,find方法的语义看起来更接近我所提出的问题,所以我选择了findMergedAnnotationAttributes来作为切入点。迅速的阅读一下这个方方法,找出它当中依赖了些什么。
(下面给出依赖图)
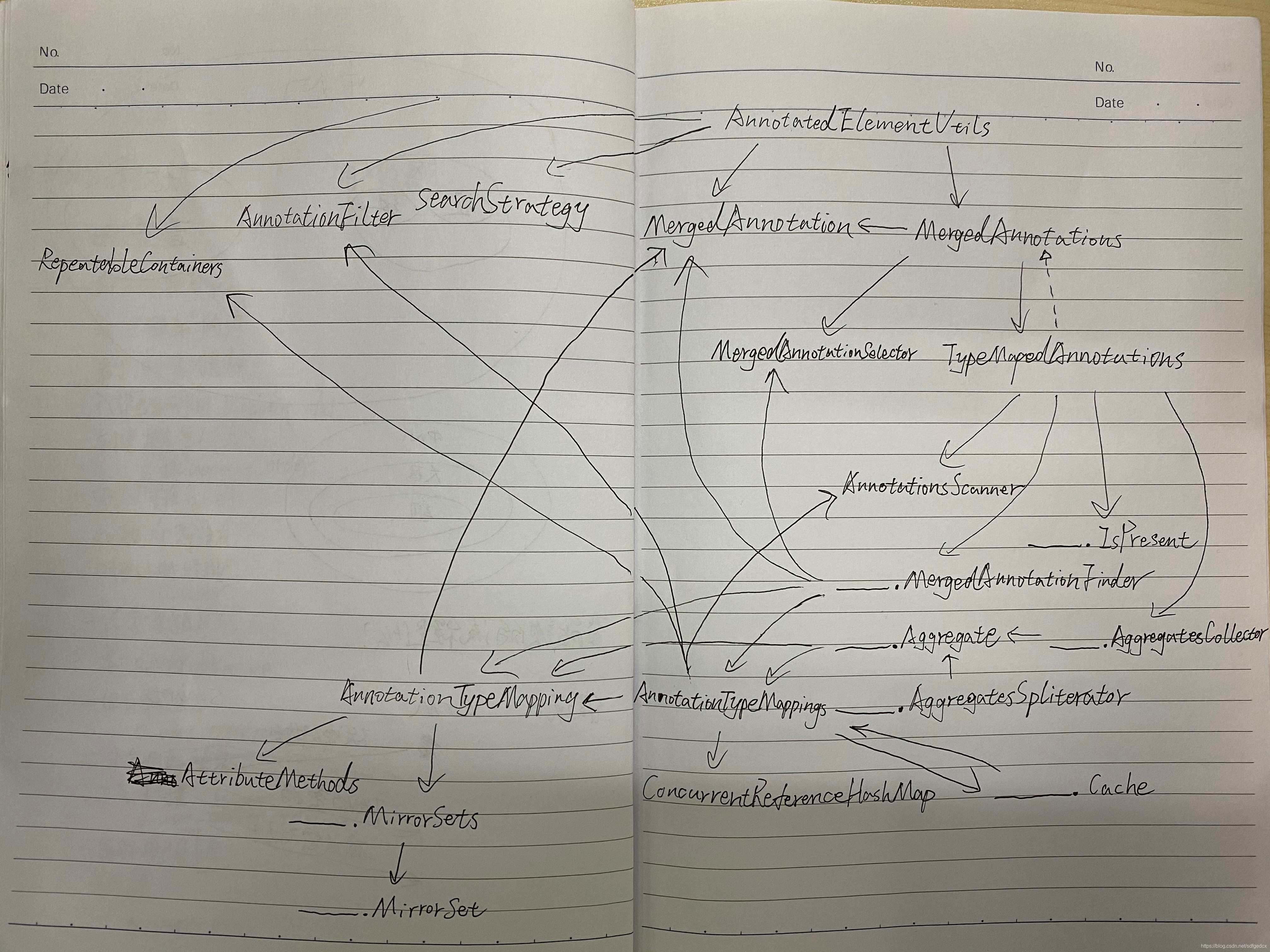
从底层开始阅读
在这个依赖图中,最底层的类是:AttributeMethods,RepeatableContainers的实现类,AnnotationsScanner的实现类,AnnotationFilter,这几个底层类是比较简单的,所以今天我不讲他们,我讲AnnotationTypeMapping,按照正常的顺序,你应该是先去读它们的。
-
阅读注释
现在让我们聚焦到AnnotationTypeMapping这个类上,它的注释是这样写的:
Provides mapping information for a single annotation (or meta-annotation) in the context of a root annotation type.
以根注解为上下文,提供单个注解的映射信息。第一次读这句话我觉得没有几个中国人能理解,好在注释只是理解的手段之一。
-
阅读构造函数
-
source, root,distance
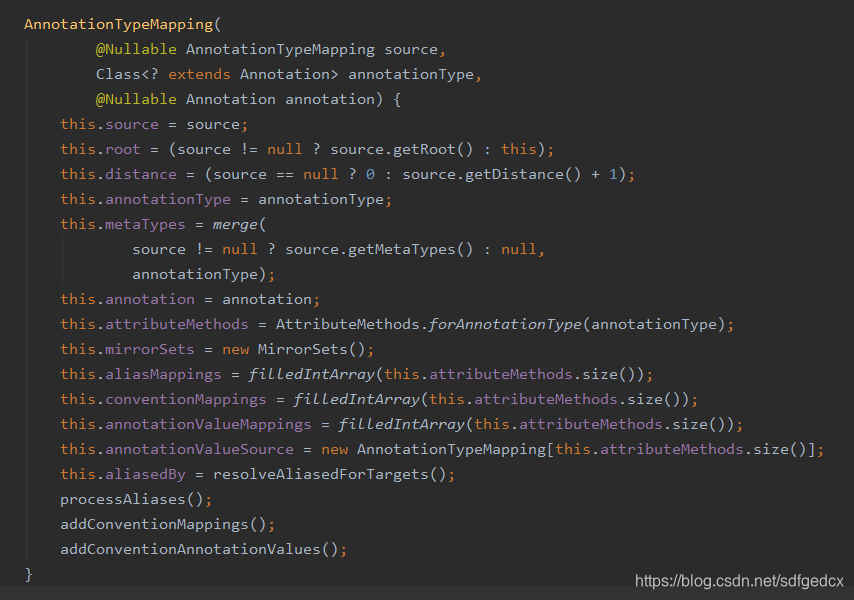
构造函数第一句就遇到麻烦了,只看前三行,大家能看出来什么逻辑吗?
不理解没关系,根据方法论,我们应该从依赖图中找到最底层,最接近该类的一处实例化过程去阅读,如果你严格画出了依赖图,并且从依赖图的底部着手去阅读,那么当你去寻找最近的实例化过程时,你会发现,它就在隔壁。
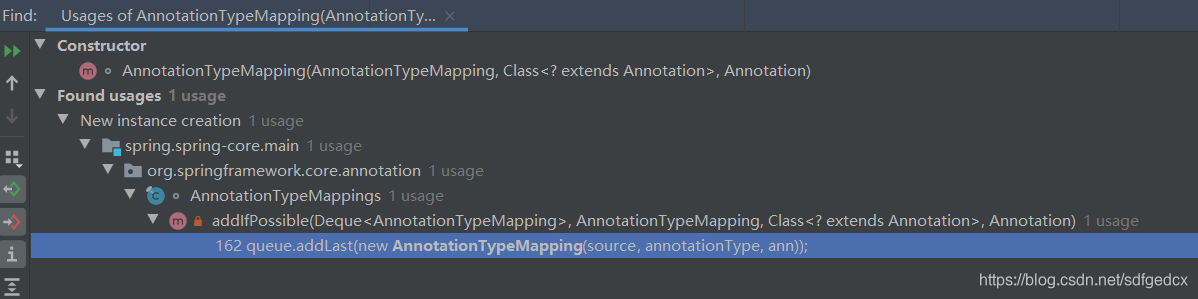
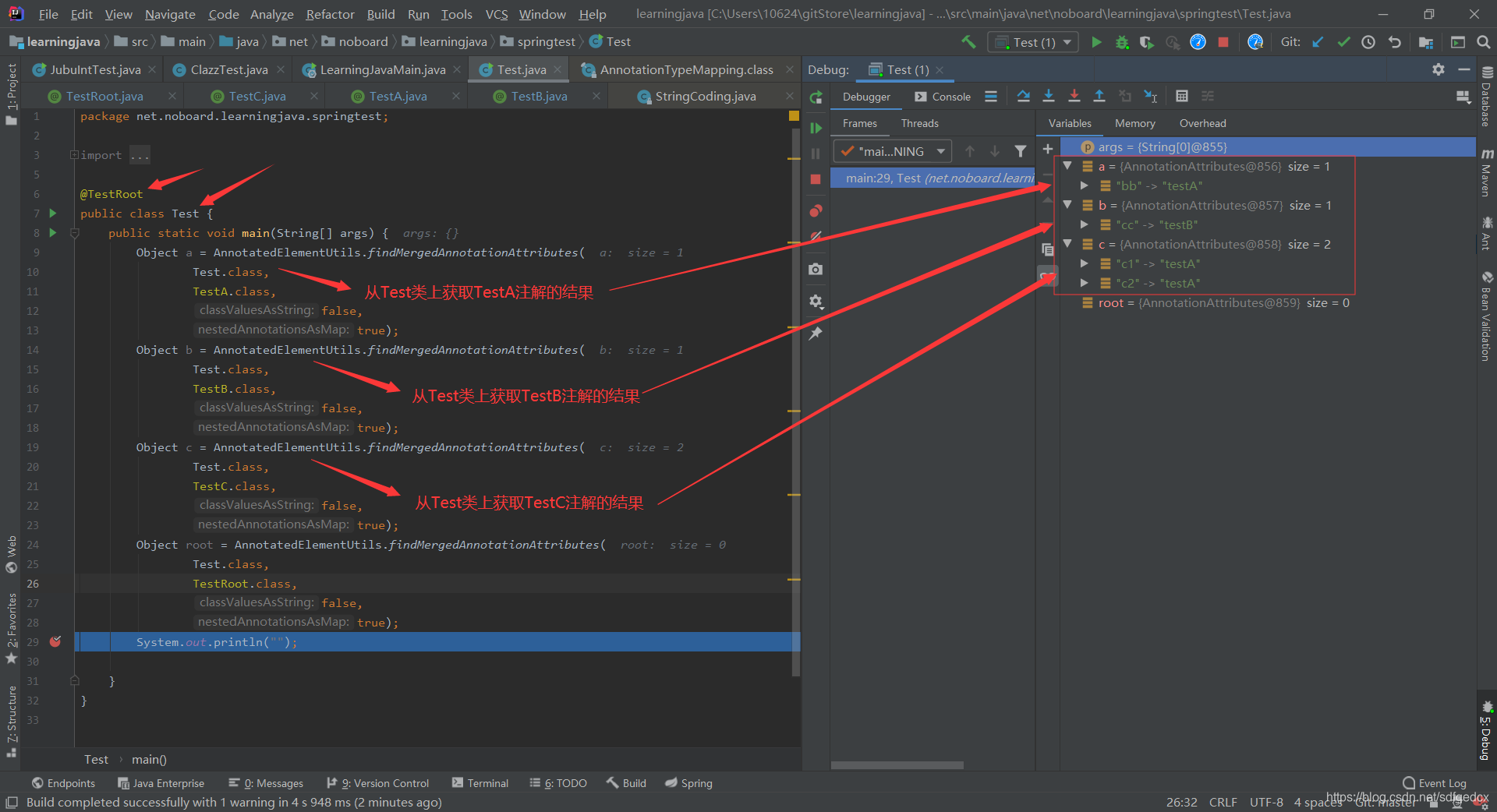
进入实例化点,利用Idea的功能, 得到调用层级
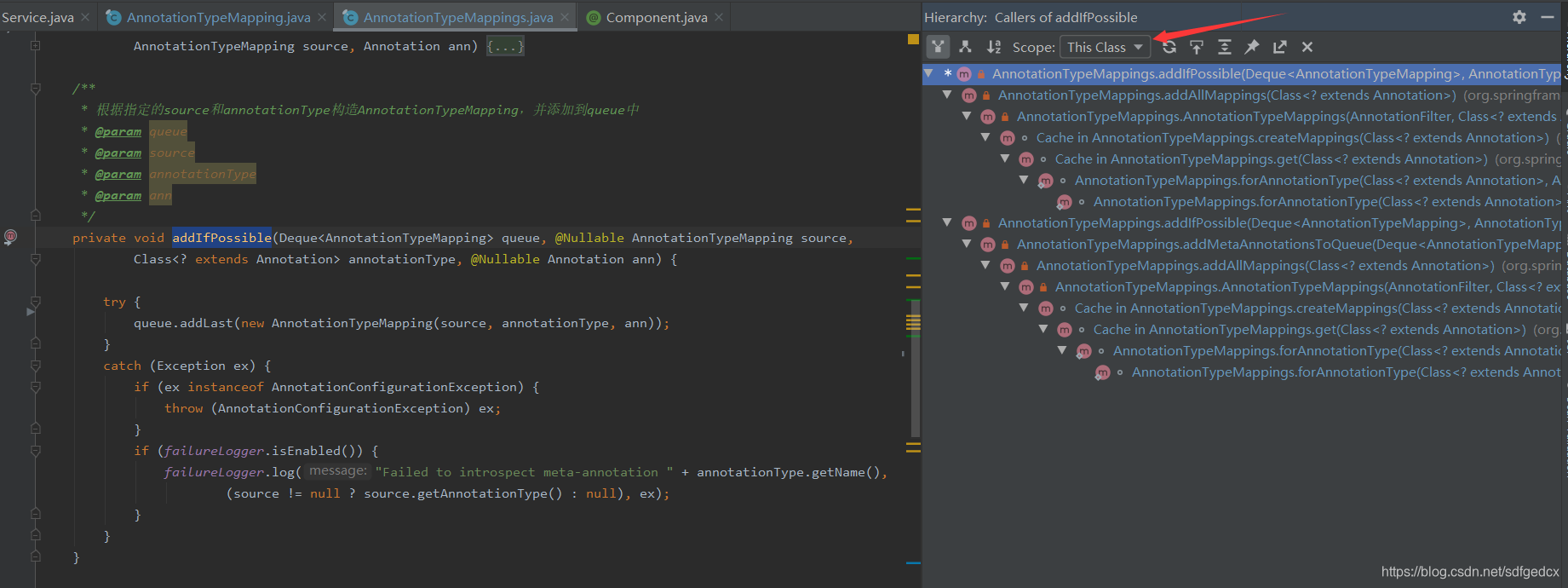
好了,现在你已经拥有一条实例化链了,注意scope选this class,实例化链的阅读要小心,不要被太多细节干扰,我们的目标仅仅是搞清楚构造函数参数的含义,一旦你在阅读的过程中理解了,就可以立刻停下,回到最初的那个类了,不要在此有多余的停留。
通过实例化链的阅读,我们明白了,AnnotationTypeMapping的实例是由AnnotationTypeMappings创建的,创建的过程是根据注解的注释体系从下往上进行的,可以参考“展示AnnotatedElementUtils的作用”那一节的示例(TestRoot -> TestA -> TestB -> TestC,它们将会串起来,后者的source指向前者,而所有的root都指向TestRoot)。这样前三个成员变量的含义是不是就清晰了。

-
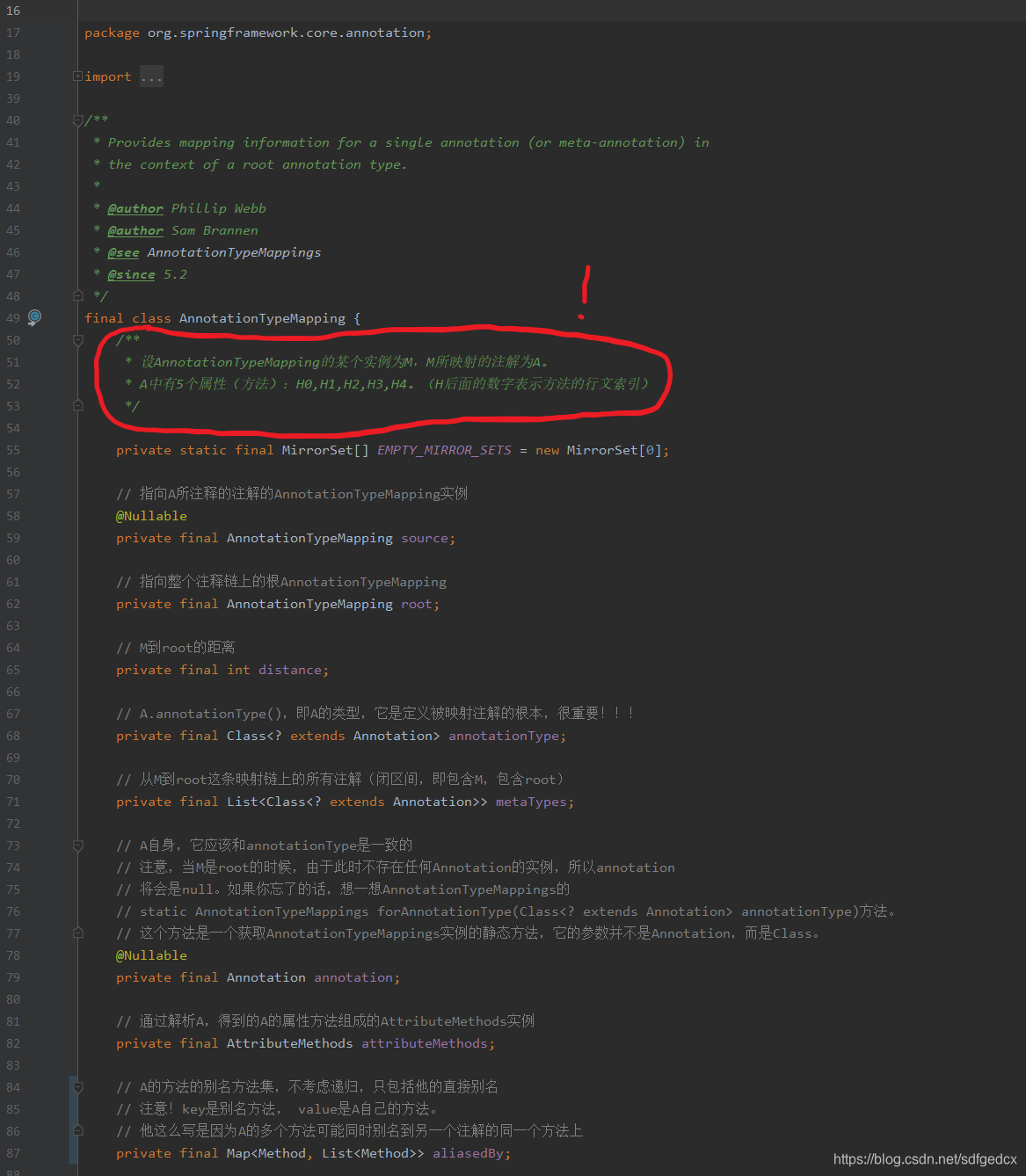
metaTypes,annotationType,annotation,attributeMethods,aliasMappings,aliasedBy
在这里我就不赘述所有成员变量(也就是这个类的表)的阅读过程了,总之它们都是通过读AnnotationTypeMapping的构造函数而理解的,下面我直接贴图,展示了我如何对已经搞清楚的成员变量进行注释的。
-
mirrorSets,conventionMappings,annotationValueMappings,annotationValueSource
这几个则是依赖MirrorSet这个类的逻辑。MirrorSet是一个内部类,内部类和普通类的一个重要区别就是,当它被实例化的时候,所使用的数据不全来自构造函数的参数,还会来自其外部类的表,所以在阅读内部类的构造函数时,要先将它所使用的外部类的表理解了。
我面对内部类的策略是,尽量推迟阅读内部类的时间,也就是说,如果不是它阻碍了流程,那么就先将其搁置。(你掌握越多的外部类信息,则理解内部类时就越少会遇到卡壳的情况,避免在两个类之间反复切换的情况发生)
在不理会MirrorSets及其相关逻辑的情况下,我们已经疏通了上面那部分数据表的逻辑,根据那些信息,我可以比较容易的得出MirrorSets以及MirrorSet的表。
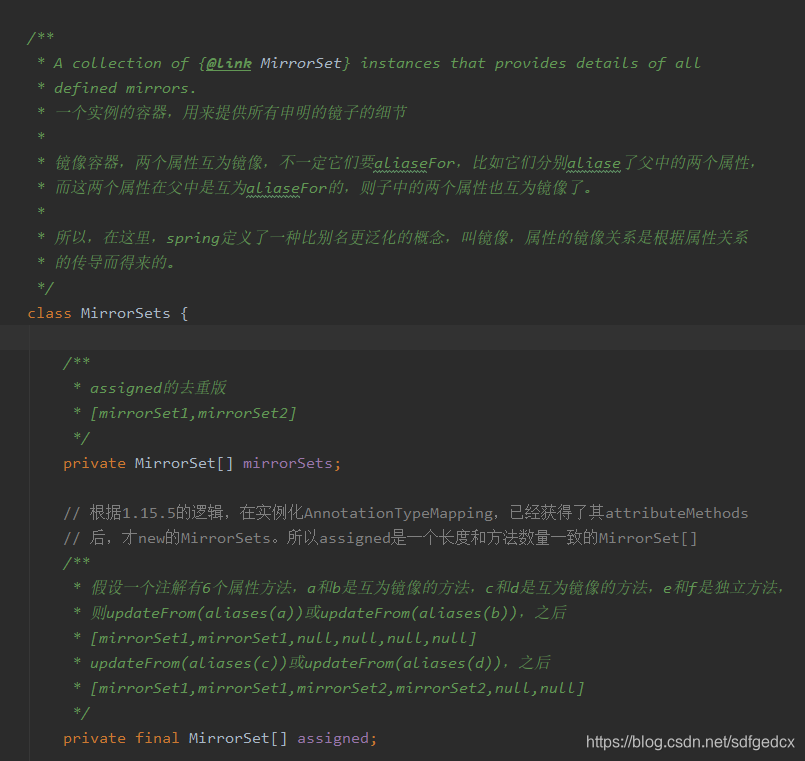
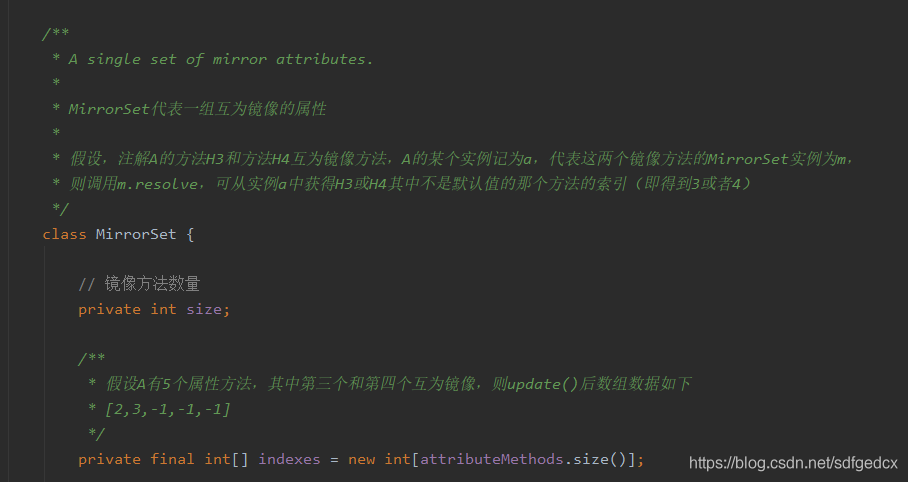
这两内部类就属于,表很简单,其功能更多由功能方法决定的类。我们去读一读它的各个功能方法(如果功能方法的参数你无法理解,有两种策略,1:使用类似阅读构造函数的方法;2:先不理他,等以后阅读其他代码时,发现调用到了这个功能方法,那时你带着相关参数的含义再来读这个功能方法)(我在这使用了第二种方法)。
这里贴出展现这两个内部类核心能力的代码注释:
MirrorSets的:
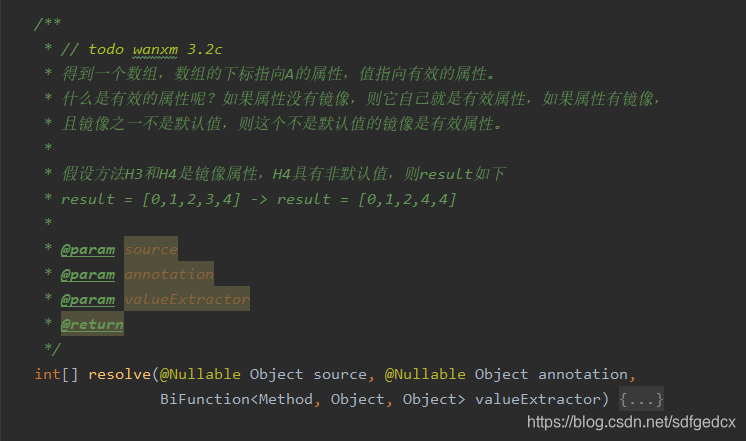
MirrorSet的:
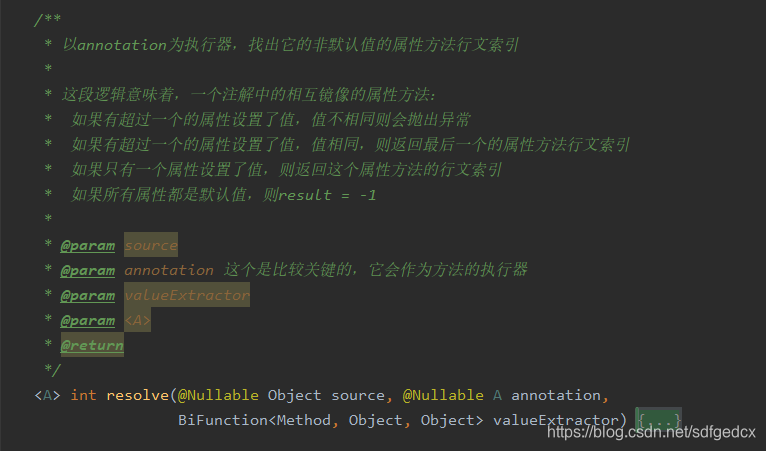
-
读完MirrorSets的相关逻辑后,整个AnnotationTypeMapping的表的信息就有了。这里贴出它的全部表信息。
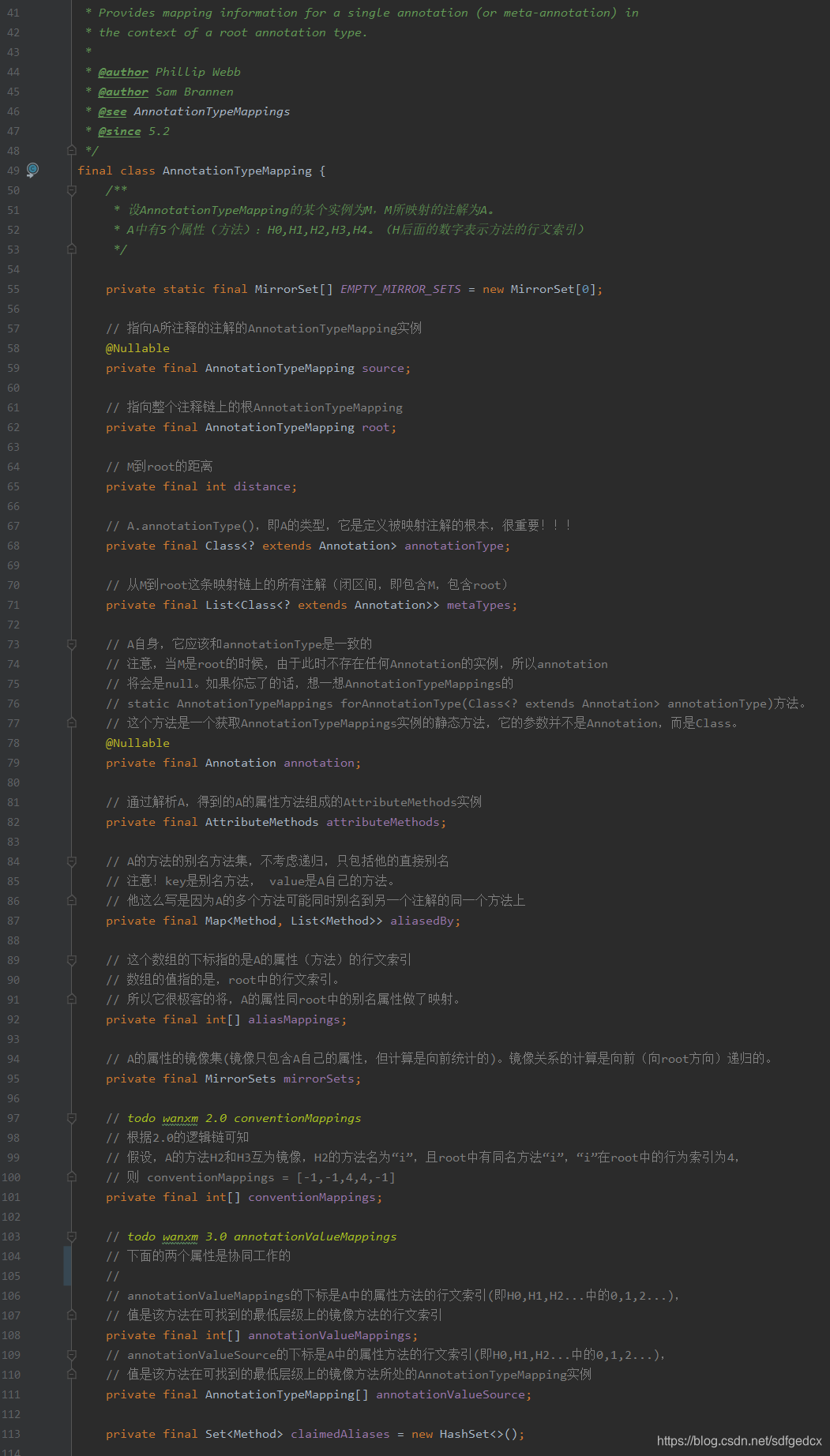
-
-
到这里,AnnotationTypeMapping这个类其实已经读的差不多了,总结一下,spring引入了如下层级属性概念:
-
别名属性
直接通过@AliaseFor关联起来的属性
-
镜像属性
由于直接或间接的@AliaseFor关系,使得某些属性实际上一定拥有相同的值,这些属性被称为镜像属性。
-
惯例属性
位于注解A中的和Root中同名的属性,被称为惯例属性,并且,同一注解中的惯例属性的镜像属性也是惯例属性。如,A中的H0和H1互为镜像属性,Root中的某个方法Hr和A中的H0名字相同,则Hr是Ho的惯例属性,Hr也是H1的惯例属性。
-
最低阶属性
A的最接近Root的有效属性。相当于,对A的某个属性来说,当低阶上存在它的镜像时,就取低阶的值,否则取它自己的值。由于低阶具有高优先级,所以我将它称作“最低阶属性”。
-
看了AnnotationTypeMapping的表,你的脑袋里是否已经有了它的概念了呢?
AnnotationTypeMapping提供了三个关键功能方法,分别是
-
getAliasMapping
用以获取root中的别名属性行文索引
-
getConventionMapping
用以获取root中的惯例属性的行文索引
-
getMappedAnnotationValue
获取最低阶属性的值
这三个方法就形成了spring获取注解属性的基础能力。
回到开篇——spring是如何赋予注解覆写能力的?
在spring中,注解之间具有多种关系,并且存在层级概念。使用者输入“别名关系”,spring则将这种关系深化,最终落到“惯例关系”与“最低阶关系”上,从而赋予低阶注解属性影响高阶注解属性的能力,实现低阶对高阶的覆写,就像子类对父类的覆写一样。并且,值得注意的是,spring并没有真的去修改高阶注解的属性值,而是通过类似指针的方式,将获取高阶注解属性值的操作指向它的低阶镜像,从而在外部看来,像是高阶属性被低阶属性覆写。
这种能力可以为我们带来什么优势?
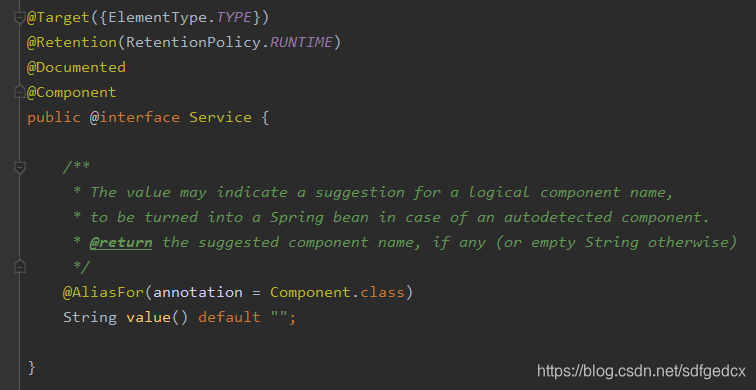
以spring的@Service注解为例,它被@Component注解元标注,并且其value属性被标识了是@Component的value属性的别名。spring在为我们提供@Service注解的时候,并不需要专门去写一个注解处理器来将被@Service标注的类注册成Bean,spring只需要一个@Component的注解处理器就可以,因为它可以从任何被@Service标注的类上获取到@Component,并且获取到被覆写的value值。这是不是很像向上转型,很像多态?
对于广大的互联网开发人员来说,我们的基础工作栈之一就是spring,当我们在spring应用中开发时,何不使用spring已经搭建好的脚手架呢,当我们需要开发一些注解处理器的时候,完全可以使用spring封装好的AnnotatedElementUtils。
题外话
大家有没有注意到MirrorSet的resolve方法有问题?
问题出在:“如果所有属性都是默认值,则result = -1”(参看前文对MirrorSet的resolve方法的注释截图)。
-1表示的是它在某组镜像属性中没有找到有效属性,如果没有找到有效属性,那么某个高层注解的“最低阶属性”就不可能定位到这组镜像上来。
举个例子说明它会导致的问题:
@TestB
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestA {
@AliasFor(value = "b1", annotation = TestB.class)
String a1() default "testA";
}
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestB {
@AliasFor(value = "b2")
String b1() default "testB";
@AliasFor(value = "b1")
String b2() default "testB";
}
@TestA
public class Test {
public static void main(String[] args) {
// 这里你得到的实例b有两个key,b1和b2,值都是"testA"
AnnotationAttributes b = AnnotatedElementUtils.findMergedAnnotationAttributes(Test.class, TestB.class, false, true);
}
}
但是当你将TestA修改成这样,使得a1和a2成为镜像属性时,得到的结果就比较奇怪了
@TestB
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface TestA {
@AliasFor(value = "b1", annotation = TestB.class)
String a1() default "testA";
@AliasFor(value = "b2", annotation = TestB.class)
String a2() default "testA";
}
@TestA
public class Test {
public static void main(String[] args) {
// 这里你得到的实例b有两个key,b1和b2,值都是"testB"
AnnotationAttributes b = AnnotatedElementUtils.findMergedAnnotationAttributes(Test.class, TestB.class, false, true);
}
}
注解TestB中的属性并没有被TestA中的属性覆盖,但TestA确实是TestB的低层级属性,它理应具有覆写上层属性的能力,当TestA中的属性没有形成镜像时,它确实表现出了这种能力,但当TestA中的属性形成镜像时,这种能力消失了(这个bug在spring-framework5.2.x版本下存在,将可能于5.2.3版本修复)。
比较幸运,我们发现了一个spring的bug。也从侧面证明了,我们的源码阅读方法论是有效的。给spring提一个PR,我们就能收到几个感谢。
福州SEO结语
AnnotatedElementUtils的能力其实并不是一个AnnotationTypeMapping可以概括的,还有其他一些类在整个逻辑中发挥重要作用,我会继续更新博客,慢慢将完整的AnnotatedElementUtils展现出来,而面对今天的AnnotationTypeMapping,你在看了表的注释后,有一个概括性的认识就可以了。
希望我的方法能对大家有所帮助,也期望大家和我分享你们的方法,让我们取长补短,最后能得出一套高效的方法论。
以上是关于[所思所想]观《长津湖》有感的主要内容,如果未能解决你的问题,请参考以下文章