队列小哥哥喊你来排队了~(自带循环的那种)
Posted MeloJun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了队列小哥哥喊你来排队了~(自带循环的那种)相关的知识,希望对你有一定的参考价值。
 前几篇,我们已经接触了两个数据结构:链表和栈,这篇的主角呢,其实跟栈有点相似,队列和循环队列小哥哥也一样需要我们掌握,这篇带你来认识认识!
前几篇,我们已经接触了两个数据结构:链表和栈,这篇的主角呢,其实跟栈有点相似,队列和循环队列小哥哥也一样需要我们掌握,这篇带你来认识认识!
大家好,我是melo,一名大二上软件工程在读生,经历了一年的摸滚,现在已经在工作室里边准备开发后台项目啦。
不过这篇文章呢,还是想跟大家聊一聊数据结构与算法,学校也是大二上才开设了数据结构这门课,希望可以一边学习数据结构一边积累后台项目开发经验。
前几篇,我们已经接触了两个数据结构:链表和栈,这篇的主角呢,其实跟栈有点相似,队列小哥哥也一样需要我们掌握,这篇带你来认识认识!
普通队列
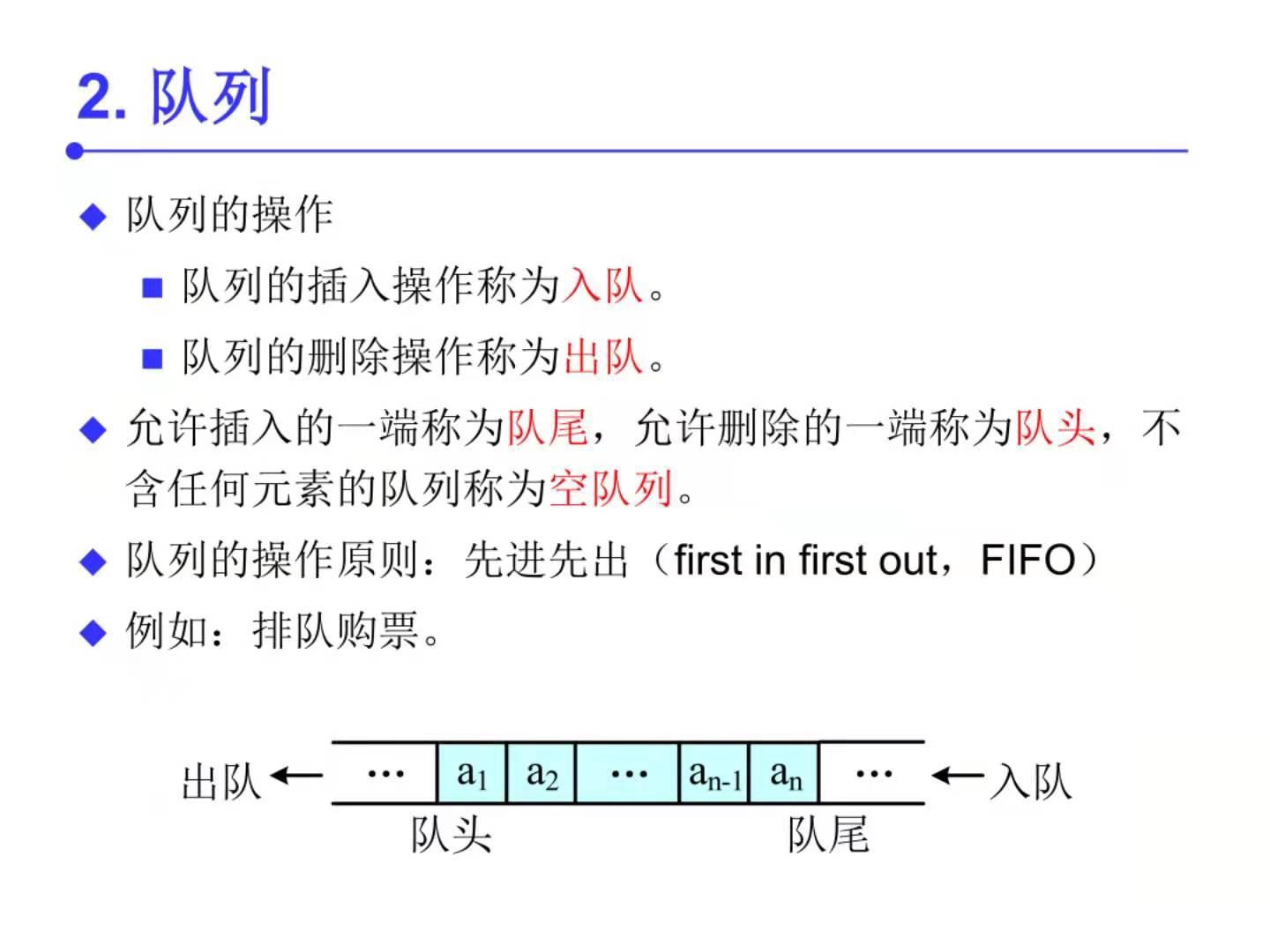
先进先出(两端操作)
只能在头部出队,尾部入队

c语言版
typedef struct {
int front;
int rear;
int capacity;
int* queue;
} MyCircularQueue;
//需要先声明
bool myCircularQueueIsEmpty(MyCircularQueue* obj);
bool myCircularQueueIsFull(MyCircularQueue* obj);
//创建队列
MyCircularQueue* myCircularQueueCreate(int k) {
MyCircularQueue* CircularQueue = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
CircularQueue->front=0;
CircularQueue->rear=0;
CircularQueue->queue=(int*)malloc( k * sizeof(int));;
CircularQueue->capacity=k;
return CircularQueue;
}
//入队列
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
if(myCircularQueueIsFull(obj)){
return false;
}
obj->queue[obj->rear]=value;
//移动rear
obj->rear=obj->rear+1;
return true;
}
//出队列
bool myCircularQueueDeQueue(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return false;
}
//移动front
obj->front= obj->front+1;
return true;
}
//得到第一个元素
int myCircularQueueFront(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return -1;
}
return obj->queue[obj->front];
}
//得到最后一个元素
int myCircularQueueRear(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return -1;
}
return obj->queue[(obj->rear)-1];
}
//判空
bool myCircularQueueIsEmpty(MyCircularQueue* obj) {
if(obj->front==obj->rear){
return true;
}
return false;
}
//判满
bool myCircularQueueIsFull(MyCircularQueue* obj) {
//若rear==最大容量了(因为我们数组计数是从0开始)
if((obj->rear)== (obj->capacity)){
return true;
}
return false;
}
循环队列
这里用了两种思路来实现
1.rear是尾部的下一个,且会留一个空位
注意数组要开大一位,因为我们的特殊设计
注意isFull
return (rear + 1) % capacity == front;
java版
public class MyCircularQueue {
private int front;
private int rear;
private int capacity;
private int[] arr;
/**
* Initialize your data structure here. Set the size of the queue to be k.
*/
public MyCircularQueue(int k) {
capacity = k + 1;
arr = new int[capacity];
// 在 front 出队,故设计在数组的头部,方便删除元素
// 删除元素的时候,只索引 +1(注意取模)
// 在 rear 入队,故设计在数组的尾部,方便插入元素
// 插入元素的时候,先赋值,后索引 +1(注意取模)
front = 0;
rear = 0;
}
/**
* 入队
*/
public boolean enQueue(int value) {
//先判断是否满了
if (isFull()) {
return false;
}
arr[rear] = value;
rear = (rear + 1) % capacity;
return true;
}
/**
* 出队
*/
public boolean deQueue() {
if (isEmpty()) {
return false;
}
front = (front + 1) % capacity;
return true;
}
/**
* 得到第一个元素(不弹出)
*/
public int Front() {
if (isEmpty()) {
return -1;
}
return arr[front];
}
/**
* 得到最后一个元素(不弹出)
*/
public int Rear() {
if (isEmpty()) {
return -1;
}
return arr[(rear - 1 + capacity) % capacity];
}
/**
* 判空
*/
public boolean isEmpty() {
return front == rear;
}
/**
* 判断是否满了
*/
public boolean isFull() {
// 注意:我们这里设计好了,只剩下一个位置的时候就是满了
//且rear是指向最后一个元素的下一位
return (rear + 1) % capacity == front;
}
}
c语言版
- 注意函数用到另一个函数的时候,如果在下边需要先声明
注意结构体内部声明一个动态数组时,需要声明成int* queue(数组指针)
然后Creat的时候去malloc
CircularQueue->queue=(int*)malloc( (k+1) * sizeof(int));;
typedef struct {
int front;
int rear;
int capacity;
int* queue;
} MyCircularQueue;
//需要先声明
bool myCircularQueueIsEmpty(MyCircularQueue* obj);
bool myCircularQueueIsFull(MyCircularQueue* obj);
//创建队列
MyCircularQueue* myCircularQueueCreate(int k) {
MyCircularQueue* CircularQueue = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
CircularQueue->front=0;
CircularQueue->rear=0;
CircularQueue->queue=(int*)malloc( (k+1) * sizeof(int));;
CircularQueue->capacity=k+1;
return CircularQueue;
}
//入队列
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
if(myCircularQueueIsFull(obj)){
return false;
}
obj->queue[obj->rear]=value;
//移动rear,注意取模
obj->rear=(obj->rear+1)%(obj->capacity);
return true;
}
//出队列
bool myCircularQueueDeQueue(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return false;
}
//移动front,注意取模
obj->front=(obj->front+1)%obj->capacity;
return true;
}
//得到第一个元素
int myCircularQueueFront(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return -1;
}
return obj->queue[obj->front];
}
//得到最后一个元素
int myCircularQueueRear(MyCircularQueue* obj) {
if(myCircularQueueIsEmpty(obj)){
return -1;
}
return obj->queue[(obj->rear-1+obj->capacity)%obj->capacity];
}
//判空
bool myCircularQueueIsEmpty(MyCircularQueue* obj) {
if(obj->front==obj->rear){
return true;
}
return false;
}
//判满
bool myCircularQueueIsFull(MyCircularQueue* obj) {
if((obj->rear+1)%obj->capacity==obj->front){
return true;
}
return false;
}
队列满的条件以及队列的长度
可能相差一圈,就要联想到去取模这个一圈的长度

***队列长度(我的版本)
rear小于front: rear-front+QueueSize
rear大于front: rear-front
- 既然如此,可以拿rear-front+QueueSize去模QueueSize,
-
- 若rear-front小于0,那结果就是rear-front+QueueSize
- 若大于0,就只剩下rear-front
2.tag标志位来标志是空了还是满了
如果我们不采用第一种方法(多留一个空位的话)
其实会发现我们判空和判满都是同一个条件: rear==front
这样我们就没有办法区分开两种情况了
所以我们用另一个tag标志位来标志是空了还是满了

单纯根据tag来判断是满还是空(错误版本)
这样是错的,因为初始化tag就是0了,一直入队没满他也还是0,总是以为是空队列
#include "allinclude.h" //DO NOT edit this line
//入队
Status EnCQueue(CTagQueue &Q, ElemType x) {
// Add your code here
//若满了
if(Q.tag==1) return ERROR;
Q.elem[Q.rear]=x;
Q.rear=(Q.rear+1)%MAXQSIZE;
//加完后满了
if(Q.rear==Q.front) Q.tag=1;
return OK;
}
//出队
Status DeCQueue(CTagQueue &Q, ElemType &x){
// Add your code here
//若空
if(Q.tag==0) return ERROR;
x=Q.elem[Q.front];
Q.front=(Q.front+1)%MAXQSIZE;
//若出队完空了
if(Q.rear==Q.front) Q.tag=0;
return OK;
}
判断rear==front以及判断tag (正解)
#include "allinclude.h" //DO NOT edit this line
//入队
Status EnCQueue(CTagQueue &Q, ElemType x) {
// Add your code here
//若满了
if(Q.tag==1&&Q.rear==Q.front) return ERROR;
Q.elem[Q.rear]=x;
Q.rear=(Q.rear+1)%MAXQSIZE;
//加完后满了
if(Q.rear==Q.front) Q.tag=1;
return OK;
}
//出队
Status DeCQueue(CTagQueue &Q, ElemType &x){
// Add your code here
//若空
if(Q.tag==0&&Q.rear==Q.front) return ERROR;
x=Q.elem[Q.front];
Q.front=(Q.front+1)%MAXQSIZE;
//若出队完空了
if(Q.rear==Q.front) Q.tag=0;
return OK;
}
写在最后
- 其实这一块知识学了蛮久了,当时没有把链队列的一并整理进来,等以后期末复习有需要的时候,会回来整理的!!!(立个flag!)
同学,运维喊你来精简日志啦 - 日志瘦身方法论
一、背景
在日常开发中,通常为了方便调试、方便查问题,会打印很多 INFO 级别的日志。

随着访问量越来越大,一不小心,某个日志文件一天的 size 就大于了某个阈值(如 5G),于是,收到了优化日志大小的告警,一定时间内不优化反馈给你主管,囧…
日志过大容易导致一些运维操作消耗机器性能,如日志文件检索、数据采集、磁盘清理等。而且,打印一些没必要的日志也会造成磁盘的浪费。因此,优化势在必行。
那么,日志瘦身哪些常见的思路呢? 本文结合某个具体案例谈谈我的看法。
二、日志瘦身方法论
2.1 只打印必要的日志
有时候为了方便测试,临时打印很多 INFO 级别日志。对于这种日志,等项目上线前,可以将非必要的日志删除或者调整为 DEBUG 级别。
但有些场景下有些日志可打印为 DEBUG 也可打印为 INFO,打印成 INFO 级别占空间,打印成 DEBUG 级别线上查问题的时候又需要用到,肿么办?

我们可以对日志工具类进行改造,支持上下文传递某个开关时(正常调用没有这个开关,通过公司的 Tracer 或者 RPC上下文传递),可以临时将 DEBUG日志提升为 INFO级别。
伪代码如下:
if(log.isDebugEnable())
log.debug(xxx);
else if(TracerUtils.openDebug2Info())
log.info("【debug2info】"+xxx);
这样,可以将一些纠结是否要打印成 INFO 日志的 log 打印成 DEBUG 级别,查问题时自动提升为INFO 日志。
为了避免误会,区分 DEBUG 提升 INFO 的日志和普通 INFO 日志,加上 类似【debug2info】 日志前缀。

当然,你也可以搞一些其他骚操作,这里只是举个例子,请自行举一反三。
2.2 合并打印
有些可以合并的日志,可以考虑合并。
如在同一个方法前后都打印了 INFO 日志:
INFO [64 位traceId] XXXService 执行前 size =10
INFO [64 位traceId] XXXService 执行后 size =4
可以合并成一条:
INFO [64 位traceId] XXXService 执行前 size =10 执行后 size =4
2.3 简化&缩写&压缩
某个日志非常有必要,但是打印的对象有些大,如果可以满足问题排查需求的情况下,我们可以:
(1)选择只打印其 ID
(2)创建一个只保留关键字段的日志专用对象,转化为日志专用对象,再打印。
(3)可以用缩写,如 write 简化为 w, read 简化为 r, execute 简化为e 等;比如 pipeline 中有 20个核心 bean ,打印日志时可以使用不同的编号替代 bean 全称,如 S1,S2 ,虽然没那么直观,但既可以查问题,又降低了日志量。
三、优化案例
3.1 场景描述
一个业务场景涉及很多 bean, 为了复用一些通用逻辑,这些 bean 都继承自某个抽象类。
在抽象类中,定义了执行 bean 前后的一些通用逻辑,如执行前后打印当前 pipeline 中 item 的数量。
最后一个 bean 执行完结果转换后需要打印出结果。
3.2 优化分析
3.2.1 只打印必要日志
(1)由于当前 bean 执行前 相当于前一个 bean 执行后,因此只打印执行后的日志就可以,执行前的INFO 日志可以删除或者改为 DEBUG (只打印必要日志)
(2)通常问题只出现在执行前后 size 不一致的情况下,因此执行后打印日志前可以加个判断,如果执行前后 size 相同则不打印。(只打印必要日志)
伪代码如下:
if(sizeBefore != sizeAfter)
log.info("service:, 前size:,后size:", getName(),sizeBefore, sizeAfter)
这招效果很明显,因为大多数 bean 的执行前后 size 是相同的,就不会打印这条日志。
而假设之前有 20 个,这条日志就需要打印 20次,改进后可能只需要打印 2-3 次。
3.2.2 日志合并
(2)为了方便查问题还需要打印执行前的 size ,那么将执行前的 size 记录在内存中,打印执行后日志时多打印出执行前的 size。(合并打印)
伪代码如下:
log.info("service:, 执行前size:", getName(),sizeBefore)
log.info("service:, 执行后size:", getName(),sizeBefore, sizeAfter)
合并后
log.info("service:, 前size:,后size:", getName(),sizeBefore, sizeAfter)
3.2.3 日志精简
对于最终结果,将结果对象(如 XXDTO)转化为只包括关键信息,如 id, title 的日志对象(XXSimpleLogDTO),转化为日志对象后再打印。
log.info("resultId:",result.getId());
或者
log.info("result:",toSimpleLog(result));
3.3 效果评估
该日志一天产生 5 G 左右,这里百分之80% 左右都是打印执行前后的 size,10%左右是打印最终结果,还有一些其他的日志。
经过上述方法优化后,每天日志量不足 1G。

在满足排查问题的需要,又实现日志瘦身之间进行了取舍。
四、总结
日志瘦身需要进行权衡,保留排查问题的必要日志情况下尽可能精简。
可以采用删除不必要日志,合并日志,日志简化等方式进行优化。
我们还可以进行一些骚操作,支持线上 DEBUG 临时提升 INFO (当然也可以使用 arthas )来辅助我们查问题。
你还有哪些不错的日志瘦身技巧?
欢迎在文章末尾评论和我交流。
创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

以上是关于队列小哥哥喊你来排队了~(自带循环的那种)的主要内容,如果未能解决你的问题,请参考以下文章