[汇编]《汇编语言》第18章 附注内容(完结)
Posted 若水三千
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[汇编]《汇编语言》第18章 附注内容(完结)相关的知识,希望对你有一定的参考价值。
王爽《汇编语言》第四版 超级笔记
第18章 附注内容
18.1 Intel系列微处理器的3种工作模式
微机中常用的Intel系列微处理器的主要发展过程是:8080,8086/8088,80186,80286,80386,80486,Pentium,PentiumII,Pentiumlll,Pentium4。
8086/8088是一个重要的阶段,8086和8088是略有区别的两个功能相同的CPU。
8088被IBM用在了它所生产的第一台微机上,该微机的结构事实上成为以后微机的基本结构。
80386是第二个重要的型号,随着微机应用及性能的发展,在微机上构造可靠的多任务操作系统的问题日益突出。人们希望(或许是一种潜在的希望,一旦被挖掘出来,便形成了一个最基本的需求)自己的PC机能够稳定地同时运行多个程序,同时处理多项工作;或将PC机用作主机服务器,运行UNIX那样的多用户系统。
8086/8088不具备实现一个完善的多任务操作系统的功能。为此Intel开发了80286,80286具备了对多任务系统的支持。但对8086/8088的兼容却做得不好。这妨碍了用户对原8086机上的程序的使用。IBM最早基于80286开发了多任务系统OS/2,结果犯了一个战略错误。
随后Intel又开发了80386微处理器,这是一个划时代的产品。它可以在以下3个模式下工作。
(1)实模式:工作方式相当于一个8086。
(2)保护模式:提供支持多任务环境的工作方式,建立保护机制(这与VAX等小型机 类似)。
(3)虚拟8086模式:可从保护模式切换至其中的一种8086工作方式。这种方式的提供使用户可以方便地在保护模式下运行一个或多个原8086程序。
以后的各代微处理器都提供了上述3种工作模式。
你也许会说:“喂,先生,你说的太抽象了,这3种模式我如何感知?”
其实CPU的这3种模式只要用过PC机的人都经历过。任何一台使用Intel系列CPU的PC机只要一开机,CPU就工作在实模式下。如果你的机器装的是DOS,那么在DOS加载后CPU仍以实模式工作。如果你的机器装的是Windows,那么Windows加载后,将由Windows将CPU切换到保护模式下工作,因为Windows是多任务系统,它必须在保护模式下运行。如果你在Windows中运行一个DOS下的程序,那么Windows将CPU切换到虚拟8086模式下运行该程序。或者是这样,你点击开始菜单在程序项中进入MS-DOS方式,这时Windows也将CPU切换到虚拟8086模式下运行。
可以从保护模式直接进入能运行原8086程序的虚拟8086模式是很有意义的,这为用户提供了一种机制,可以在现有的多任务系统中方便地运行原8086系统中的程序。这一点,在Windows中我们都可以体会到,你在Windows中想运行一个原DOS中的程序,只用鼠标点击一下它的图标即可。
80286CPU的缺陷在于,它只提供了实模式和保护模式,但没有提供虚拟8086模式。这使基于80286构造的多任务系统,不能方便地运行原8086系统中的程序。如果运行原8086系统中的程序,需要重新启动计算机,使CPU工作在实模式下才行。这意味着什么?
意味着将给用户造成很大的不方便。假设你使用的是基于80286构造的Windows系统,就会发生这样的情况:你正在用Word写一篇论文,其中用到了一些从前的数据,你必须运行原DOS下的DBASE系统来看一下这些数据。这时你只能停下现有的工作,重新启动计算机,进入实模式工作。你看完了数据,继续写论文,可过了一会儿,你发现又有些数据需要参考,于是你又得停下现有的工作,重新启动计算机……
幸运的是,我们用的Windows是基于80386的,我们可以以这样轻松的方式工作,开两个窗口,一个是工作于保护模式的Word,一个是工作于虚拟8086模式的DBASE,我们可以方便地在两个窗口中切换,只要用鼠标点一下就行。
前面讲过,我们在8086PC机的基础上学习汇编语言。但现在知道,我们实际的编程环境是当前CPU的实模式。当然,有些程序也可以在虚拟8086模式下运行。
如果你仔细阅读了上面的内容,或己具备相关的知识,你会发现,从80386到当前的CPU,提供8086实模式的目的是为了兼容。现今CPU的真正有效力的工作模式是支持多任务操作系统的保护模式。这也许会引发你的一个疑问:“为什么我们不在保护模式下学习汇编语言?”
类似的问题很多,我们都希望学习更新的东西,但学习的过程是客观的。任何合理的学习过程(尽可能排除走弯路、盲目探索、不成系统)都是一个循序渐进的过程。我们必须先通过一个易于全面把握的事物,来学习和探索一般的规律和方法。信息技术是一个发展非常快、日新月异的技术,新的东西不断出现,使人在学习的时候往往无所适从。
在你的身边不断有这样的故事出现:COOL先生用了3天(或更短)的时间就学会了某某语言,并开始用它编写软件。在这个故事的感召下,一个初学者也去尝试,但完全是另外一种结果。COOL先生的快速学习只是露出水面的冰山一角,深藏水下的是他的较为系统的相关基础知识和相关的技术。在开始的时候学习保护模式下的编程,是不现实的,保护模式下所涉及的东西对初学者来说太复杂。你必须知道很多知识后,才能开始编写第一个小程序。相比之下8086就合适得多。
18.2 补码
以8位的数据为例,对于无符号数来说是从00000000b~11111111b到0-255一一对应的。那么我们如何对有符号数进行编码呢?即我们如何用8位数据表示有符号数呢?
既然表示的数有符号,则必须要能够区分正、负。
首先,我们可以考虑用8位数据的最高位来表示符号,1表示负,0表示正,而用其他位表示数值。如下:
00000000b: 0
00000001b: 1
00000010b: 2
01111111b: 127
10000000b: ?
10000001b: -1
10000010b: -2
11111111b: -127
可见,用上面的表示方法,8位数据可以表示-127-127的254个有符号数。从这里我们看出一些问题,8位数据可以表示255种不同的信息,也就是说应该可以表示255个有符号数,可用上面的方法,只能表示254个有符号数。注意,用上面的方法,00000000b和10000000b都表示0,一个是0,一个是-0,当然不可能有-0。可以看出,这种表示有符号数的方法是有问题的,它并不能正确地表示有符号数。
我们再考虑用反码来表示,这种思想是,我们先确定用00000000b〜01111111b表示0~127,然后再用它们按位取反后的数据表示负数。如下:

可以看出,用反码表示有符号数存在同样的问题,0出现重码。
为了解决这种问题,釆用一种称为补码的编码方法。这种思想是:先确定用00000000b〜01111111b表示0~127,然后再用它们按位取反加1后的数据表示负数。 如下:

观察上面的数据,我们可以发现,在补码方案中:
(1)最高位为1,表示负数;
(2)正数的补码取反加1后,为其对应的负数的补码;负数的补码取反加1后,为其绝对值。比如:
- 1的补码为:00000001b,取反加1后为:11111111b,表示T;
- T的补码为:11111111b,取反加1后为:00000001b,其绝对值为1。
我们从一个负数的补码不太容易看出它所表示的数据,比如:11010101b表示的数据是多少?
但是我们利用补码的特性,将11010101b取反加1后为:00101011b。可知11010101b表示的负数的绝对值为:2BH,则11010101b表示的负数为-2BH。
那么-20的补码是多少呢?
用补码的特性,-20的绝对值是20,00010100b,将其取反加1后为:11101100b。可知-20H的补码为:11101100b。
那么10000000b表示多少呢?
10000000b取反加1后为:10000000b,其大小为128,所以10000000b表示-128。
8位补码所表示的数的范围:-128~127。
补码为有符号数的运算提供了方便,运算后的结果依旧满足补码规则。
比如:
计算 补码表示
10 00001010b
+ (-20) 11101100b
-10 11110110b
18.3 用栈传递参数
这种技术和高级语言编译器的工作原理密切相关。我们下面结合c语言的函数调用,看一下用栈传递参数的思想。
用栈传递参数的原理十分简单,就是由调用者将需要传递给子程序的参数压入栈中,子程序从栈中取得参数。我们看下面的例子。
;说明:计算(a-b)^3,a、b为字型数据
;参数:进入子程序时,栈顶存放IP,后面依次存放a、b
;结果:(dx:ax) = (a-b)^3
difeube:push bp
mov bp,sp
mov ax, [bp+4] ;将栈中a的值送入ax中
sub ax, [bp+6] ;减栈中b的值
mov bp,ax
mul bp
mul bp
pop bp
ret 4
指令retn的含义用汇编语法描述为:
pop ip
add sp,n
因为用栈传递参数,所以调用者在调用程序的时候要向栈中压入参数,子程序在返回的时候可以用ret n指令将栈顶指针修改为调用前的值。调用上面的子程序之前,需要压入两个参数,所以用ret 4返回。
我们看一下如何调用上面的程序,设a=3、b=1,下面的程序段计算(a-b)^3:
mov ax,1
push ax
mov ax,3
push ax ;注意参数压栈的顺序
call difcube
程序的执行过程中栈的变化如下。
(1)假设栈的初始情况如下:

(2)执行以下指令:
mov ax,1
push ax
mov ax,3
push ax

(3)执行指令 call difcube,栈的情况变为:

(4)执行指令push bp,栈的情况变为:

(5)执行指令mov bp,sp,ss:bp指向1000:8
(6)执行以下指令:
mov ax,[bp+4];将栈中a的值送入ax中
sub ax,[bp+6];减栈中b的值
mov bp,ax
mul bp
mul bp
(7)执行指令pop bp,栈的情况变为:

(8)执行指令ret 4,栈的情况变为:
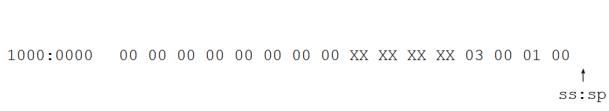
下面,我们通过一个C语言程序编译后的汇编语言程序,看一下栈在参数传递中的应用。要注意的是,在C语言中局部变量也在栈中存储。
C程序
void add(int,int,int);
main ()
{
int a=1;
int b=2;
int c=0;
add(a,b,c);
c++;
}
void add(int a,int b,int c)
{
c=a+b;
}
编译后的汇编程序
mov bp,sp
sub sp,6
mov word ptr [bp-6],0001 ;int a
mov word ptr [bp-4],0002 ;int b
mov word ptr [bp-2],0000 ;int c
push [bp-2]
push [bp-4]
push [bp-6]
call ADDR
add sp,6
inc word ptr [bp-2]
ADDR: push bp
mov bp,sp
mov ax,[bp+4]
add ax,[bp+6]
mov [bp+8],ax
mov sp,bp
pop bp
ret
汇编语言(第3版)王爽第八章学习内容
- 只要在[]中使用寄存器bp,而指令中没有显性地给出段地址,段地址就默认在ss中。
- mov ax,[bp] 含义:(ax) = ((ss)*16+(bp))
- mov ax,[bp+idata] 含义:(ax) = ((ss)*16+(bp)+idata)
- mov ax,[bp+si] 含义:(ax) = ((ss)*16+(bp)+(si))
- mov ax,[bp+si+idata] 含义:(ax) = ((ss)*16+(si)+idata)
- 寻址方式:
- 直接寻址:
- 表达式: [idata]
- 直接根据常量寻址,在C语言中表示为arr[0]
- 寄存器间接寻址:
- 表达式:[bx]、[si]、[di]、[bp]
- 根据寄存器的数据寻址,在C语言中表示为arr[i]
- 寄存器相对寻址:
- 表达式:[bx+idata]、[si+idata]、[di+idata]、[bp+idata]
- 根据寄存器和常量寻址,在C语言中表示为arr[i+10]
- 基址变址寻址:
- 表达式:[bx+si+idata]、[bx+di+idata]、[bp+si+idata]、[bp+di+idata]
- 根据两个寄存器和一个常量寻址,在C语言中表示为arr[i+j+5]
- 要操作的数据的长度:
- 如果操作符两边有寄存器,以寄存器的大小确定操作的是字还是字节。
- 如果没有寄存器,可以自行指定:
- mov word ptr [2],1
- mov byte ptr [2],1
- 有些指定默认指定了访问的是字还是字节:
- 比如push [1000h]默认操作的是字。
- div指
-

- data segment中:
- db(data byte)定义的是字节型数据,每1个数据占1个字节。
- dw(data word)定义的是字型数据,每1个数据占1个字,即2个字节。
- dd(data double word)定义的是双字型数据,每1个数据占2个字,即4个字节。
- 问题8.1
assume cs:codesg, ds:datasg datasg segment dd 100001 dw 100 dw 0 datasg ends codesg segment start: mov ax,datasg mov ds,ax mov dx,ds:[2] ;注意高位在低位后面 mov ax,ds:[0] div word ptr ds:[4] mov ds:[6],ax codesg ends end start
以上是关于[汇编]《汇编语言》第18章 附注内容(完结)的主要内容,如果未能解决你的问题,请参考以下文章