原创C语言和C++常见误区
Posted 计算机知识杂谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创C语言和C++常见误区相关的知识,希望对你有一定的参考价值。
本文仅在博客园发布,认准原文地址:https://www.cnblogs.com/jisuanjizhishizatan/p/15414469.html
问题1:int类型占几个字节?
常见误区:占4个字节。
实际上,C语言标准并未规定int类型所占的字节数。因此,在不同的机型上,所输出的结果可能不同。部分较老版本的C编译器,可能int类型是2字节。
问题1-1:char类型占几个字节?
答案是1个字节。C标准规定了sizeof(char)的结果必定为1,不受处理环境影响。
问题2:下面的代码有何错误?
char s1[10];
//省略的很多操作
if(s1=="123456789")...
很多初学者都会这样写。这样写在语法上没有错误,但是在运行结果上却总会返回错误结果。
s1是一个C风格字符串,也就是char类型的数组(或指针),而"123456789"却是字符串常量。把它们使用==运算符进行比较,比较的不是字符串的内容,而是在比较指针。在表达式中,数组如果后面不带[],就会被解释作指针。
如果需要比较C风格字符串,需要使用strcmp函数来比较,这个函数包含在string.h中。因此,上述代码应该改写为这样:
char s1[10];
//省略的很多操作
if(strcmp(s1,"123456789")==0)...
问题3:下面的代码会正常运行吗?
int a[10],b[10];
for(int i=0;i<n;i++){
...
b=a;
}
在代码编写过程中,我们经常会使用“拷贝数组”这一行为,例如动态规划中的滚动数组。
然而,上面的代码是无法正常运行的。实际上,数组名b,实际上是&b[0],也就是说,b是一个常量,是不可修改的。因此,数组名在表达式中只能作为右值出现。
而指针,其实是可以修改的。但是对于两个指针a和b,执行b=a后,实际上,结果是下面这样:
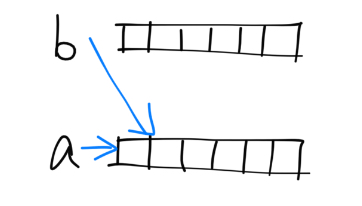
也就是说,a和b指向同一数组,这显然不是我们想要的。如果要拷贝数组,我们需要使用memcpy函数,同样包含在string.h中。因此,我们应该这样写:
memcpy(b,a,sizeof(a));
这样就可以拷贝数组了。
问题4:const的一些疑问
关于const和指针连在一起,经常让初学者们摸不着头脑。
例如下面几句:
const char *p
char const *p
char* const p
const char* const p
它们各有什么区别?
我这里曾经从《征服C指针》看到了几条非常好的内容,在此给大家分享一下:
因为C语言是美国人发明的,最好还是用英语来读(声明语句)。
规则:从后往前倒序,如果遇到*号,就加上“pointer to”,如果有const,就追加“read-only”。
const在前面和在后面完全相同。
例如,对const char *p进行翻译:
首先看到p:p is
然后是*:p is pointer to
然后是char:p is pointer to char
然后是const:p is pointer to read-only char
翻译为中文:p是指向只读的char的指针
按照这种方式解释,我们对上面四个语句解释如下:
p is pointer to read-only char
p is pointer to read-only char
p is read-only pointer to char
p is read-only pointer to read-only char
照这样,我们得出结论:
const char* p 和char const* p含义完全相同,表示指向的字符是不可变的。
char* const p表示指针自身不可变,指向的字符可变。
而最后一个,指向的字符和指针自身都不可变。
本期内容到此为止。
手把手写C++服务器:网络编程常见误区
目录
1、业务代码和IO操作混合
业务代码和IO操作混合,对单测和维护造成极大困难,只是写时一时爽,维护火葬场。
2、TCP接受数据不完整、不可靠
TCP连接与断开的时候与条件,在设计应用层协议时候,将TCP的连接与断开放到设计中。
2、TCP是一个流
TCP是字节流协议,TCP 的模型是单个无限长度的连续流,保证字节流按顺序到达,但不保留消息边界,因为对于TCP来说本身没有消息的概念。
例如当尝试通过socket发送消息时候:
socket.write("Hi Sandy.");
socket.write("Can we appointment tonight?");TCP 不会将写入视为单独的数据。 TCP 将所有写入视为单个连续流的一部分。因此,当发出上述写操作时,TCP 会将数据简单地复制到其缓冲区中:
TCP_Buffer = "Hi Sandy.Can we appointment tonight?"然后尽可能快的把数据发出去。为了通过网络发送数据,TCP 和其他网络协议将会把数据分成一小块一小块的,这样就可以通过媒介传输(WiFi,以太网等等)了。为了这么做,TCP 会以它任何最合适的方式来分解数据。以下是一些有关如何分解和发送数据的示例:
- “Hi Sandy.Can we appointment tonight?”
- “Hi Sandy.Can we”,“appointment tonight?”
- “Hi San”,“tonight”,“Can we”,“tonight”,“appointment”,“dy.”
所以当发出了socket.read()命令,然后等待接收数据。读取到的第一条数据可能是 "Hi San”。Sandy 可能正准备开始处理这个数据。在应用程序处理数据的同时,TCP 流继续接收第二个和第三个数据包。然后 Sandy 发出另一个 socket.read() 命令。并且这次她收到了 "dy.”。在使用 TCP 协议的 API 时绝没有数据包和数据分离的这些概念。
如果参考其他基于TCP设计的协议,比如HTTP 是一个很好的例子,因为它非常简单,而且因为大多数人以前都看过它。当客户端连接服务器并发送请求时,它以非常特定的方式进行。它发送一个 HTTP header,并且标头的每一行都以 CRLF(回车,换行)终止。所以像这样:
GET /page.html HTTP/1.1
Host: google.com
此外,HTTP header 的结尾由两个连续的 CRLF 作为标记。由于协议指定了终止符,因此很容易从 TCP socket 读取数据,直到到达终结符为止。
HTTP/1.1 200 OK
Content-Length: 216
{ Exactly 216 bytes of data go here }
HTTP 协议让 TCP 使用起来方便了不少。读取数据,直到获得连续的 CRLF。这就是你的 header。然后从 header 里解析出 content-length,现在你就可以直接读取这个长度的字节数据了。
所以需要设计实现TCP分包逻辑,将TCP字节流切成一个个可以分开的消息。
当TCP写入数据时候:
- 必须将所有发送和接收的数据分解成小段,以便通过网络发送。
- TCP 处理许多复杂的问题,例如重新发送丢失的数据包,提供有序的传输,以便信息按正确的顺序到达。
因此,当发出写操作时,数据仅被复制到 OS 网络堆栈中的基础缓冲区中。这时候TCP会执行以下操作:
- 将数据分解成小块,以便可以通过网络发送
- 保证丢失的数据得到正确的重发
- 保证数据按正确的顺序送达
- 监控网络总的拥堵情况
- 采用各种各样的算法来尽快处理这些任务
4、直接发送C语言结构体
结构体存在对齐问题,如果定义全局结构体,修改全局对齐方式,会直接导致:
- 第三方library扩大,破坏二进制接口。
- 系统高度不可拓展,当增大/减少字段的时,客户端/服务端都要同时进行修改。
5、TCP自连接
什么是TCP自连接问题?
自连接就是自己连接自己的现象。当我们去连接一个正在监听的端口时,系统自动为我们分配一个临时端口去进行连接,这样就有可能分配到正在监听的端口号,然后出现自己连接自己的问题。
TCP自连接带来的危害?
当程序去connect一个不处于监听的端口时,必然期待其连接失败,如果自连接出现,就意味着该端口被占用了,那么:
- 真正需要监听该端口的服务会启动失败,抛出端口已被占用的异常。
- 客户端无法正常完成数据通信,因为这是个自连接,并不是一个正常的服务。
如何解决TCP自连接问题?
断开连接重试即可。
为什么说是坑?
因为当没意识到出现TCP自连接的时候,很难找到端口被占用的真正原因,给问题定位带来困难。具体的解决方法很简单。
参考
以上是关于原创C语言和C++常见误区的主要内容,如果未能解决你的问题,请参考以下文章