RocketMQ底层详解
Posted 会编程的老六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ底层详解相关的知识,希望对你有一定的参考价值。
RocketMQ底层详解
架构
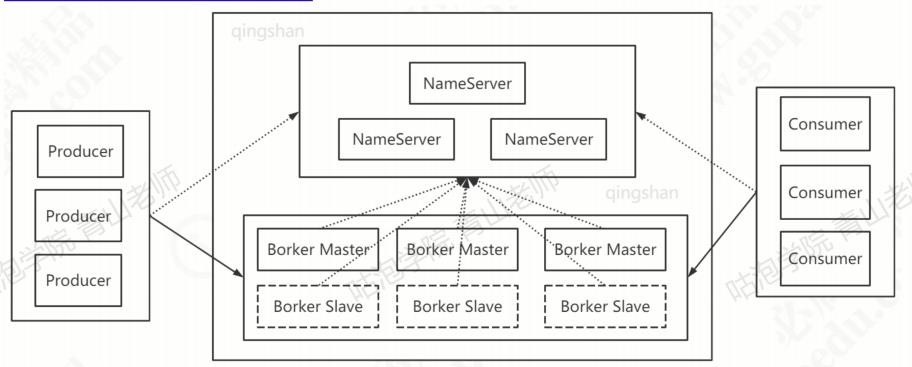
Broker
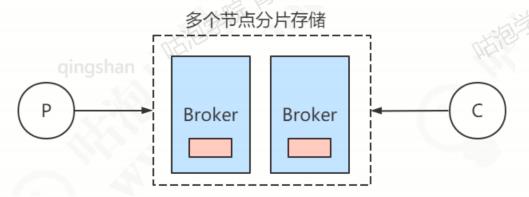
RocketMQ的服务,或者说是一个进程叫做Broker,作用是存储和转发消息。RocketMQ单机大约能承受10万QPS的请求。为了提升Broker的可用性,以及提升服务器性能,通常会做集群的部署。每个Broker保存总数据的一部分,因此可以实现横向扩展。
为了提升可靠性(防止数据丢失),每个Broker可以拥有自己的副本(slave)。
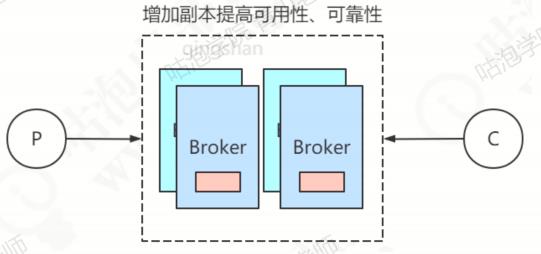
默认情况,读写都发生在主节点上。在slaveReadEnable = true的情况下,slave也可以参与读负载,但是默认只有BrokerId=1 的slave才会参与,而且是在主节点消费慢的情况下,由参数whichBrokerWhenConsumeSlowly决定,
private long whichBrokerWhenConsumeSlowly = 1;
Topic
用于将消息按照主题做划分,比如订单消息、物流消息。Topic是一个逻辑概念,消息并不是按照Topic划分存储的。
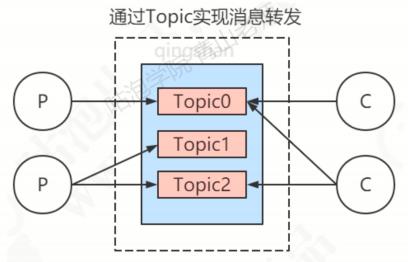
生产者将消息发往指定的Topic,消费者通过订阅这个Topic就可以收到相应的消息。private boolean autoCreateTopicEnable = true设定了如果Topic不存在,就会自动创建。
NameServer
当不同消息存储到不同的Broker上,生产者和消费者对于Broker的读取,由自己实现了一个服务来完成——NameServer。可以理解为RocketMQ的路由中心,自身也可以做集群的部署,作用有点像Eureka和Redis Sentinel。
也就是说,Broker会在NameServer上注册自己,生产者和消费者用NameServer来发现Broker。
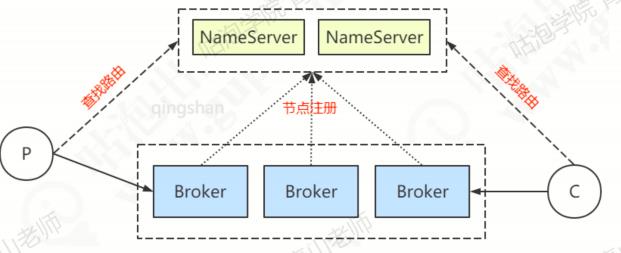
NameServer作为路由中心时到底是怎么工作的?
每个Broker节点启动的时候,都会根据配置遍历NameServer列表。
位于:rocketmq/conf/broker.conf
nameserAddr = localhost:9876
与每个NameServer建立TCP长连接,注册自己的信息,之后每隔30s发送心跳信息(服务主动注册)。
如果Broker挂了,不发送心跳了,NameServer怎么发现?
除了主从注册还有定时探活,每隔10s检查一下各个Broker的最近一次心跳时间,如果发现某个Broker超过120s都没有发送心跳,就认为这个Broker已经挂掉,会将其从路由信息里移除。
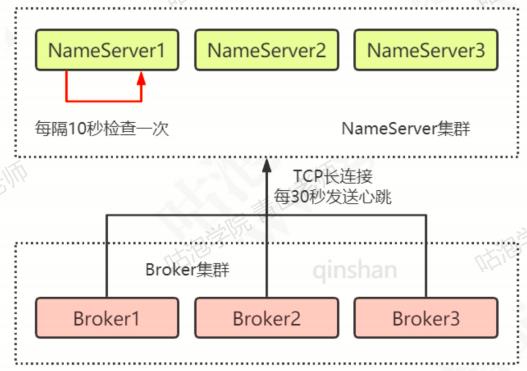
为什么不使用Zookeeper来作为路由中心?
在之前确实用过,但是后来采用了NameServer。因为架构设计决定了只需要一个轻量级的元数据服务器就够了,只需要保持最终一致性,而不需要Zookeeper这样的强一致性解决方案不需要再依赖里一个中间件,从而减少整体维护的成本。
CAP:C(一致性,Consistency),A(可用性,Availability),P(分区容错,Partiton Tolerance)。
Zookeeper 实现了CP,NameServer 选择了AP,放弃了实时一致性。
一致性问题如何解决?
NameServer之间是互相不通信的,也没有主从之分,是如何保持一致性的呢。从三点进行分析:
-
服务注册:如果新增了Broker,如何新增到所有的NameServer中?因为没有主节点,Broker每隔30s会向所有的NameServer发送心跳信息,所以还是可以保持一致的。
-
服务剔除:如果一个Broker挂了,怎么从所有的NameServer中移除它的信息?
- 如果Broker正常关闭:连接断开,Netty的通道关闭监听器会监听到连接断开事件,然后会将这个Broker信息剔除。
- 如果Broker关闭异常:NameServer的定时任务每10s扫描Broker列表,如果某个Broker的心跳包的最新时间戳超过当前时间120s,就会被移除。
因此,不管是Broker挂了还是恢复了,增加了还是减少了,NameServer都能够保持数据一致。
-
路由发现:如果Broker的信息更新了(增加或减少节点),客户端如何获得最新的Broker列表?
- 对于生产者:发送第一条消息的时候,根据Topic从NameServer获取路由信息
- 对于消费者:消费者一般是订阅固定的Topic,在启动的时候就要获取Broker信息。
在这之后,如果Broker的信息动态变化了怎么办?
因为NameServer不会主动推送服务信息给客户端,客户端也不会发送心跳到Nameserver,所以建立连接之后,需要生产者和消费者定期更新。
在MQClientInstance类(生产者消费者通用)的start方法中,启动了一个定时任务,其中第二个任务:
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() { @Override public void run() { try { MQClientInstance.this.updateTopicRouteInfoFromNameServer(); } catch (Exception e) { log.error("ScheduledTask updateTopicRouteInfoFromNameServer exception", e); } } }, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);updateTopicRouteInfoFromNameServer()方法,是用来定期更新NameServer信息的,默认是30s一次。public void updateTopicRouteInfoFromNameServer() { Set<String> topicList = new HashSet<String>(); // Consumer { Iterator<Entry<String, MQConsumerInner>> it = this.consumerTable.entrySet().iterator(); while (it.hasNext()) { Entry<String, MQConsumerInner> entry = it.next(); MQConsumerInner impl = entry.getValue(); if (impl != null) { Set<SubscriptionData> subList = impl.subscriptions(); if (subList != null) { for (SubscriptionData subData : subList) { topicList.add(subData.getTopic()); } } } } } // Producer { Iterator<Entry<String, MQProducerInner>> it = this.producerTable.entrySet().iterator(); while (it.hasNext()) { Entry<String, MQProducerInner> entry = it.next(); MQProducerInner impl = entry.getValue(); if (impl != null) { Set<String> lst = impl.getPublishTopicList(); topicList.addAll(lst); } } } for (String topic : topicList) { this.updateTopicRouteInfoFromNameServer(topic); } }消费者和生产者以相同的时间间隔,更新NameServer信息。拉取的时间间隔由DefaultMQPushConsumer的pollNameServerInterval参数决定,默认是30s。
总结一下:各个NameServer的数据能够保持一致,而且生产者和消费者会定期更新路由信息,所以可以获取最新的消息。
如果Broker刚挂,客户端30s以后才更新路由信息,那是不是会出现最多30s的数据延迟?
解决思路:
- 重试
- 把无法连接的Broker进行隔离,不再连接
- 优先选择延迟小的节点,就能避免连接到容易挂的Broker了。
如果作为路由中心的NameServer全部挂掉了,而且暂时没有恢复呢?
客户端也会缓存Broker信息,所以没有关系,不能完全依赖于NameServer。
Producer
生产者,用于生产消息,会定时从NameServer拉去路由信息(不用配置RocketMQ的服务地址),然后根据路由信息与指定的Broker建立TCP长连接,从而将消息发送到Broker中。发送逻辑一致的Producer可以组成一个Group。
RocketMQ的生产者同样支持批量发送,不过List要自己传进去。Producer写数据只能操作主节点。
Consumer
消息的消费者,通过NameServer集群获得Topic的路由信息,连接到对应的Broker上消费信息。消费逻辑一致的Consumer可以组成一个Group,这时候消息会在Consumer之间负载。由于主节点和从节点都可以读取消息,因此Consumer与所有节点都会建立连接。
一个消费者组中的消费者应该订阅同一个topic。或者反过来,消费不同topic的消费者不应该采用相同的消费者组名字。如果消费了不同的topic,后面的消费者的订阅会覆盖之前消费者的订阅。
两种消费模式:
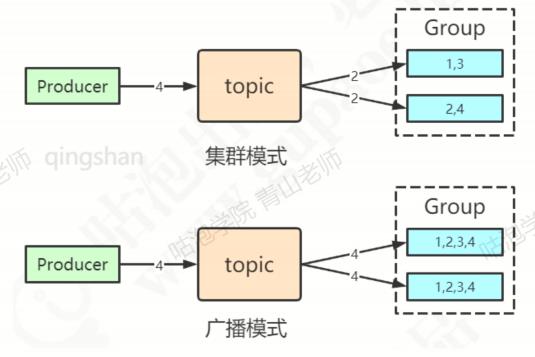
RocketMQ支持pull和push两种消费模型。
pull
consumer轮询从broker拉取消息。使用DefaultPullConsumer创建实例。
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("xxxxx");
两种实现方式:
- 普通的轮询(Polling):不管服务端数据有无更新,客户端每隔定长时间请求拉去一次数据,可能有更新数据返回,也可能什么都没有。缺点就是大部分时候都没有数据,这些无效的请求会大大地浪费服务器的资源,而且定时请求的间隔过长的时候会导致消息延迟。
- 长轮询(RocketMQ的pull实现方式):客户端发起Long Polling,如果此时服务端没有相关数据,会hold住请求,直到服务端有相关数据,或者等待一定时间超时才会返回。返回后,客户端有会立即再次发起下一次长轮询。
轮询唯一的缺点就是服务器在挂起的时候比较消耗内存。
push
这种方式采用Broker将消息推送给Consumer,实现类:DefaultMQPushConsumer
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("xxxxx");
RocketMQ的push模式实际上是基于pull模式实现的,只不过在pull模式上封装了一层,所以Rocketmq push模式并不是真正意义上的“推模式”。
PushConsumer会注册MessageListener监听器,取到消息后,唤醒MessageListener的consumerMessage()来消费,对用户而言,感觉就像是被推送过来的。
Message Queue
rocketmq支持多主节点的架构。如果发往某一个Topic的多条消息,是不是在所有的Broker上都存储完全相同的内容呢?
肯定不是的。这样不仅浪费了存储空间,还无法通过增加机器数量线性地提升Broker的性能,只能垂直扩展,无法横向水平扩展,性能受限。
那么,如何将一个Topic里面的消息分布到不同的master上呢?
Rocketmq中提供了一个叫做Message Queue的逻辑概念。首先,创建Topic的时候会指定队列的数量,分别是writeQueueNums(写队列数量)和readQueueNums(读队列数量)。
写队列的数量决定了有几个MessageQueue,读队列的数量决定了有几个线程来消费这些MessageQueue(只是用来负载的)。如果没有指定MQ的时候,默认一个Topic拥有8个队列:
private int defaultTopicQueueNums = 8;
//BrokerConfig
topic不存在,生产者发送消息时创建默认4个队列:
private volatile int defaultTopicQueueNums = 4;
//DefaultMQProducer
服务器创建的时候有一个判断,取小一点的值:
int queueNums = Math.min(defaultMQProducer.getDefaultTopicQueueNums(),data.getReadQueueNums());
MQ在磁盘上是可以看到的,但是数量只跟写队列相关,而且在所有主节点上个数是一样的(数据存储不一样)。
发送消息的时候,生产者会根据一定的规则,获得MessageQueue,只要拿到了queueid,就知道要往哪个Broker发送,然后在commitlog写入消息。
RocketMQ 原理
生产者
生产者利用队列可以实现消息的负载和平均分布,那什么时候消息会发到哪个队列呢?
消息发送规则
从Producer的send方法开始跟踪,在DefaultMQProducerImpl的select方法会选择要发送的Queue:
public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) {
return this.mqFaultStrategy.selectOneMessageQueue(tpInfo, lastBrokerName);
}
调用MQFaultStratage的选择队列的方法,这个类是MQ负载均衡的核心类:
int index = tpInfo.getSendWhichQueue().incrementAndGet();
for (int i = 0; i < tpInfo.getMessageQueueList().size(); i++) {
int pos = Math.abs(index++) % tpInfo.getMessageQueueList().size();
if (pos < 0)
pos = 0;
MessageQueue mq = tpInfo.getMessageQueueList().get(pos);
if (latencyFaultTolerance.isAvailable(mq.getBrokerName()))
return mq;
}
MessageQueueSelector 有三个实现类:

- 默认,他是一种不断自增、轮询的方式
- 随机选择一个队列
- 返回空,没有实现
也可以自定义MessageQueueSelector,作为参数传进去:
SendResult sendResult = producer.send(msg,new MessageQueueSelector(){
public MessageQueue select(List<MessageQueue> mqs,Message msg,Object arg){
Integer id = (Integer)arg;
int index = id%mqs.size();
return mqs.get(index);
}
},i);
顺序消息
原本代码中调用是有序的,但是消息中间件经过了Broker的转发,而且可能出现多个消费者并发消费,就会导致乱序的问题。
全局有序:不管有几个生产者,在服务端怎么写入,有几个消费者。消费的顺序和生产顺序是一致的。实现比较麻烦,即使实现了,也会对MQ的性能产生很大的影响。
顺序消息:实际上就是局部有序。那么,例如:订单服务。只需要同一个订单相关的消费是有序的就ok了。
保证消息有序,要分成几个环节分析:
- 生产者发送消息的时候,到达Broker应该是有序的,所以对于生产者,不能使用多线程异步发送,而是顺序发送。
- 写入Broker的时候,应该是顺序写入的。也就是相同主题的消息应该是集中写入,选择同一个queue,而不是分散写入。
- 消费者消费的时候只能有一个线程。否则由于消费的速率不同,有可能出现记录到数据库的时候无序。
RocketMQ的顺序消息怎么实现呢?
-
首先生产者发送消息,是单线程的。追踪send方法发现,消息是同步发送的,最终调用了sendMessageSyn方法同步发送消息。生产者接受到Broker的成功的Response才算是消息发送成功。
-
其次,消息要路由到相同的queue(关键是要在相同的通道排序,才能实现先进先出)。生产者是如何控制队列的选择?通过MessageQueueSelector,默认使用hashkey进行选择。
producer sendOneway(rocketMsg,messageQueueSelector,hashKey); //这边其实时传入了一个hashKey只要传入相同的hashKey,就会选择同一个队列。
-
最后,在消费者需要保证一个队列只有一个线程消费。Spring Boot中,consumeMode设置为ORDERLY。Java API中,传入MessageListenerOrderly的实现类。
consumer.registerMessageListener(new MessageListenerOrderly(){}); //根据注释:一个队列只能有一个线程来消费消费者在启动consumer.start()的时候会判断getMessageListenerInner的实现是哪种(通过instanceof判断),根据Listener类型使用不同的Service,紧接就启动这个Servcie。调用DefaultMQPushConsumerImpl中的pullMessage方法,将拉取到的消息放入ProcessQueue。然后进入ConsumeMessageOrderlyService的submitConsumeRequest方法。拉取到的消息构成了ConsumeRequest(实现了Runnable),然后放入线程池等待执行。
@Override public void submitConsumeRequest( final List<MessageExt> msgs, final ProcessQueue processQueue, final MessageQueue messageQueue, final boolean dispathToConsume) { if (dispathToConsume) { ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue); this.consumeExecutor.submit(consumeRequest); } }既然放入了线程池,多线程还能保证有序吗?
ProcessQueue是使用TreeMap来存放消息的:

TreeMap是红黑树的实现,自平衡的排序二叉树。因为Key是当前消息的offset,消息是按照offset排序的。再查看ConsumeRequest的run方法:
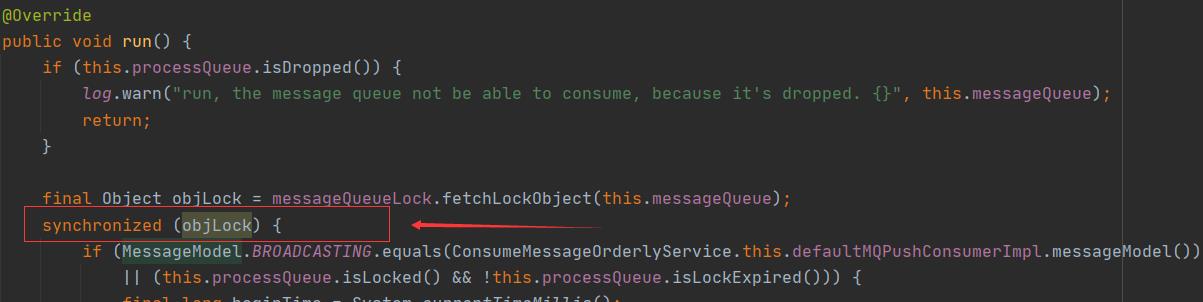
在消费的时候加上了锁,RocketMQ顺序消息消费会将队列锁定,当队列获取锁之后才能进行消费,所以能够实现有序消费。
事务消息
半消息:暂时不能投递消费者的消息,发送方已经将消息成功发送到了MQ服务器,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”的状态,处于该种状态下的消息即为半消息。
**消息回查: **由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,MQ服务端通过扫描发现某条消息长期处于“半消息”时,需要主动向消息生产者询问该消息的最终状态(Commit或者是Rollback),该过程即消息回查。
整体流程:
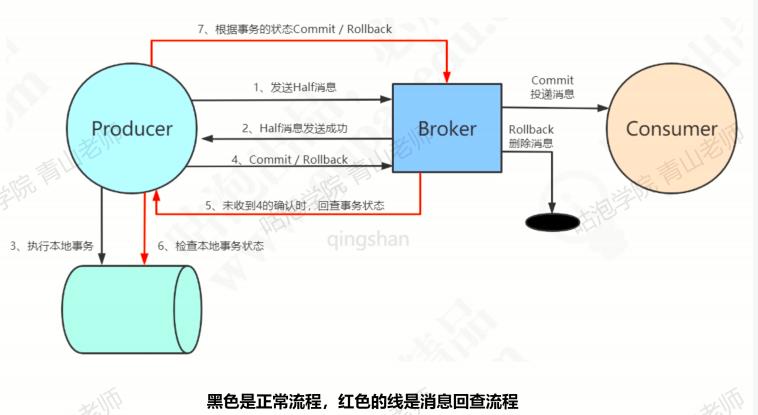
代码实现:RocketMQ提供了一个TransactionListener接口,这个里面可以实现执行本地事务。
public interface TransactionListener {
/**
* When send transactional prepare(half) message succeed, this method will be invoked to execute local transaction.
*
* @param msg Half(prepare) message
* @param arg Custom business parameter
* @return Transaction state
*/
LocalTransactionState executeLocalTransaction(final Message msg, final Object arg);
/**
* When no response to prepare(half) message. broker will send check message to check the transaction status, and this
* method will be invoked to get local transaction status.
*
* @param msg Check message
* @return Transaction state
*/
LocalTransactionState checkLocalTransaction(final MessageExt msg);
}
默认回查总次数是15次,第一次回查间隔时间是6s,后续每次间隔60s。
延迟消息
RocketMQ可以直接支持延迟消息。但是开源版本功能被阉割了,只能支持特定等级的消息,商业版本可以任意指定时间。比如:
msg.setDelayLevel(3);
//level 3 = 10s,延迟级别配置代码在MessageStoreConfig#messageDelayLevel中
//springboot中可以这样使用:
rocketMQtTemplate.syncSend(topic,message,1000,3);
**实现原理: **Broker中内置延迟消息处理能力,核心实现思路都是一样的:将延迟消息通过一个临时存储进行暂存,到期后才投递到目标Topic中。
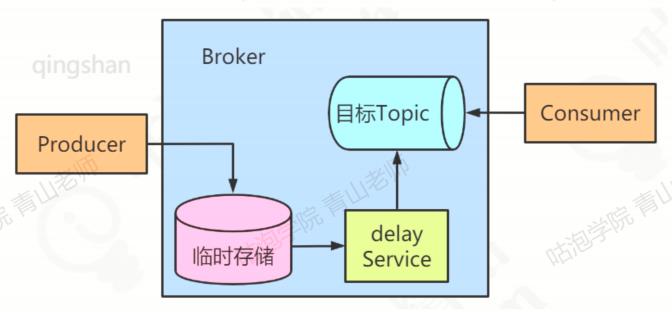
步骤:
- producer要将一个延迟消息发送到某个Topic中。
- Broker判断这是一个延迟消息后,将其通过临时存储进行暂存。
- Broker内部通过一个延迟服务(delay Service)检查消息是否到期,将到期的消息投递到目标Topic中。
- 消费者消费目标Topic中的延迟投递的消息。
临时存储和延迟服务都是在Broker中内部实现,对业务透明。
CommitLog#putMessage:
// Delay Delivery
if (msg.getDelayTimeLevel() > 0) {
if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
}
topic = TopicValidator.RMQ_SYS_SCHEDULE_TOPIC;
queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
// Backup real topic, queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
msg.setTopic(topic);
msg.setQueueId(queueId);
}
消息实际存储是在commitlog,异步写入consume queue。调用ScheduleMessageService#start:
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
if (timeDelay != null) {
this.timer.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME);
}
}
为每个延迟级别都创建一个任务,获得每个级别的延迟时间,并且创建TimerTask。时间到期后,调用了DeliverDelayedMessageTimerTask#messageTimeup(内部类),其中获取索引之后,读取消息,获取源Topic名称等等,重新将消息持久化到commitlog中并异步写入consume queue。最后消息可以正常消费。
rocketmq的消息重试也是基于延迟消息来完成的。在消费失败的情况下,将其重新当作延迟消息投递回Broker。
Broker
消息存储
既没有分区的概念,也没有按分区存储消息。
为什么这样设计?
- 每个分区存储整个消息数据。尽管每个分区都是有序写入磁盘的,但随着并发写入分区的数量增加,从操作系统来开,写入就变成了随机的。
- 由于写入数据文件分散,很难使用批量刷盘
所以RocketMQ设计了一种新的文件存储方式,就是所有的Topic的所有的消息全部写在同一个文件中(这种存储方式叫集中型存储或混合型存储),这样能够保证绝对的顺序写。
优势:
- 对列轻量化,单个数据队列数据量非常少。
- 对磁盘的访问串行化,完全顺序写,避免磁盘竞争,不会因为队列增加导致IOWAIT增高。
消费消息的时候,如果想要consumer group 只查找自己的topic的offset消息,可以为每一个consumer group把他们消费的topic的最后消费到的offset单独存储在一个地方。这个存储消息的偏移量的对象就叫做consume queue。
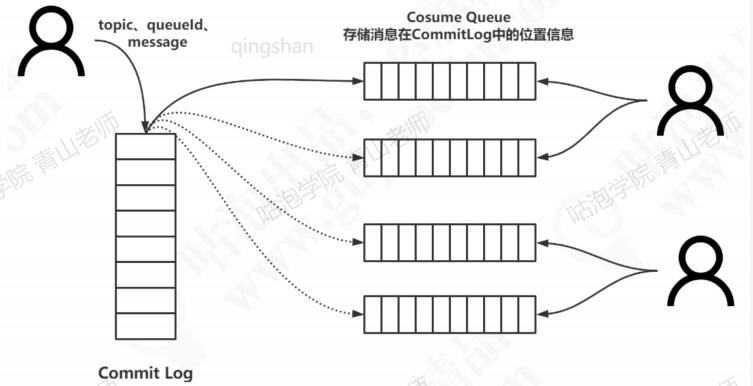
也就是说,消息在Broker存储的时候,不仅写入commitlog,同时也把在commitlog中的最新的offset异步写入对应的consume queue。
消费者在消费消息的时候,先从consume queue读取持久化消息的起始物理位置偏移量offset,大小size和消息tag的hashCode值,随后在从commit log中进行读取待拉取消费消息的真正实体内容部分。
存储关键技术(持久化/硬盘)
CPU如果要读取或者操作磁盘上的数据,必须要把磁盘的数据加载到内存,这个是由硬件结构和访问速度的差异决定的。这个加载的大小有一个固定的单位,叫做Page。x86的linux中一个标准页面大小是4KB。如果要提升磁盘访问速度,或者说尽量减少磁盘I/O,可以把访问过的Page在内存中缓存起来。这个内存的区域就叫做Page Cache。下次处理I/O的时候,就先到Page Cache里面查找,找到了就直接操作。没找到就到磁盘里面查找。
Page Cache本身也会对数据文件进行预读取,对于每个文件的第一个请求操作,系统就在读入所请求页面的同时读入紧跟其后的少数几个页面。
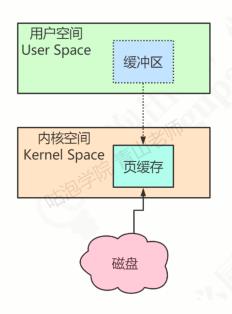
因为虚拟内存分为内核空间和用户空间。Page Cache属于内核空间,用户空间访问不了,因此读取数据据还需要从内核空间拷贝到用户空间缓冲区。这样会降低数据访问的速度。因此在这里使用了一种零拷贝技术。
将Page Cache的数据在用户空间中做一个地址映射,这样用户进程就可以通过指针操作直接读写Page Cache,不需要再使用系统调用和内存拷贝。
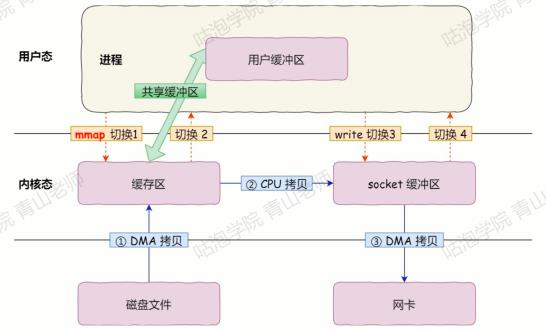
在RocketMQ中具体的实现是使用mmap(memory map,内存映射),不论是commitlog 还是 ConsumerQueue都采用了mmap。
文件清理策略
RocketMQ中被消费过的消息是不会删除的,所以保证了文件的顺序写入。因此需要进行文件清理。
需要清理的文件应该满足这几个条件 :
- 是Commitlog 或者是 ConsumeQueue中的文件
- 超过72小时的文件(才算是过期文件)
那么什么时候删除呢?(分两种情况)
- 通过定时任务,每天凌晨4点,删除这些过期的文件
- 磁盘使用空间超过了75%,开始删除过期文件。
当然如果磁盘使用率超过了85%,会开始批量清理文件,不管有没有过期,直到空间充足。如果磁盘空间使用率超过了90%,会拒绝消息的写入。
消费者
如果我们需要提高消费者的负载能力,必然要增加消费者的数量。那么如果做到尽量平均的消费消息?队列如何分配给对应的消费者?
消费端的负载均衡与rebalance
消费者增加的时候,肯定会引起rebalance。在消费者启动的入口函数中调用了RebalanceService中的run方法。也就是说:
消费者启动的时候或者由消费者挂掉的时候,默认最多20秒(实际上在DefaultMQPushConsumerImpl的start方法末尾还有一句:this.mQClientFactory.rebalanceImmediately();会唤醒沉睡的线程,也就是立即执行RebalanceService的run方法),就会做一次rebalance,让所有的消费者可以尽量均匀的消费队列消息。
具体是如何进行rebalance的呢?
一共存在六种已经实现的策略(可以指定,也可以通过consumer.setAllocateMessageQueueStrategy();自定义实现):
-
AllocateMessageQueueAveragely: 连续分配(默认)
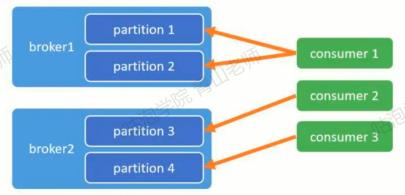
-
AllocateMessageQueueAveragelyByCircle: 每人轮流一个
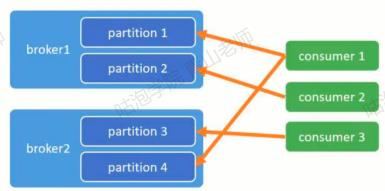
-
AllocateMessageQueueByConfig: 通过配置
-
AllocateMessageQueueConsistentHash: 一致性哈希
-
AllocateMessageQueueByMachineRoom: 指定一个Broker的topic中的queue消费
-
AllocateMachineRoomNearby: 按Broker的机房就近分配
队列的数量尽量大于消费者数量。
消费端重试与死信队列
如果一条消息消费失败,返还给Broker的是RECONSUME_LATER,表示稍后重试。这个时候,消息会发回到Broker,进入到RocketMQ的重试队列中,服务端会为consumer group创建一个名字为%RETRY%开头的重试队列。
重试队列的消息会过一段时间再次发送给消费者,如果还是异常,会再次进入重试队列,重试的时间间隔不会不断衰减,从10秒开始直到2个小时最多重试16次:10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。(同样也是延迟消息的时间等级,从level = 3开始。也就是说重试队列使用延迟队列的功能实现的)发到对应的SCHEDULE_TOPIC_XXXX,到时间后再替换成真实的topic,实现重试。
那么如果重试了16次都没有成功,这个时候消息就会丢到死信队列中。Broker会创建一个死信队列,名字是:%DLQ%+ConsumerGroupName。死信队列中的消息最后需要人工处理,可以写一个线程进行对死信队列的订阅,人工消费消息。
高可用架构
在高可用架构中,我们主要关注两个模块:主从同步和故障转移。
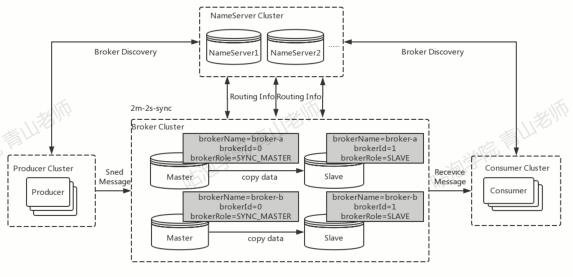
数据同步
主从的关联
主从服务器如何联系在一起?
- 集群的名字设置为相同,
borkerClusterName = xxxx-cluster - 连接到相同的NameServer。
- 在配置文件中配置:brokerId = 0 代表是主节点,brokerId = 1 代表是slave。
主从同步和刷盘类型
在部署节点的时候,配置文件中设置了Broker角色和刷盘方式:
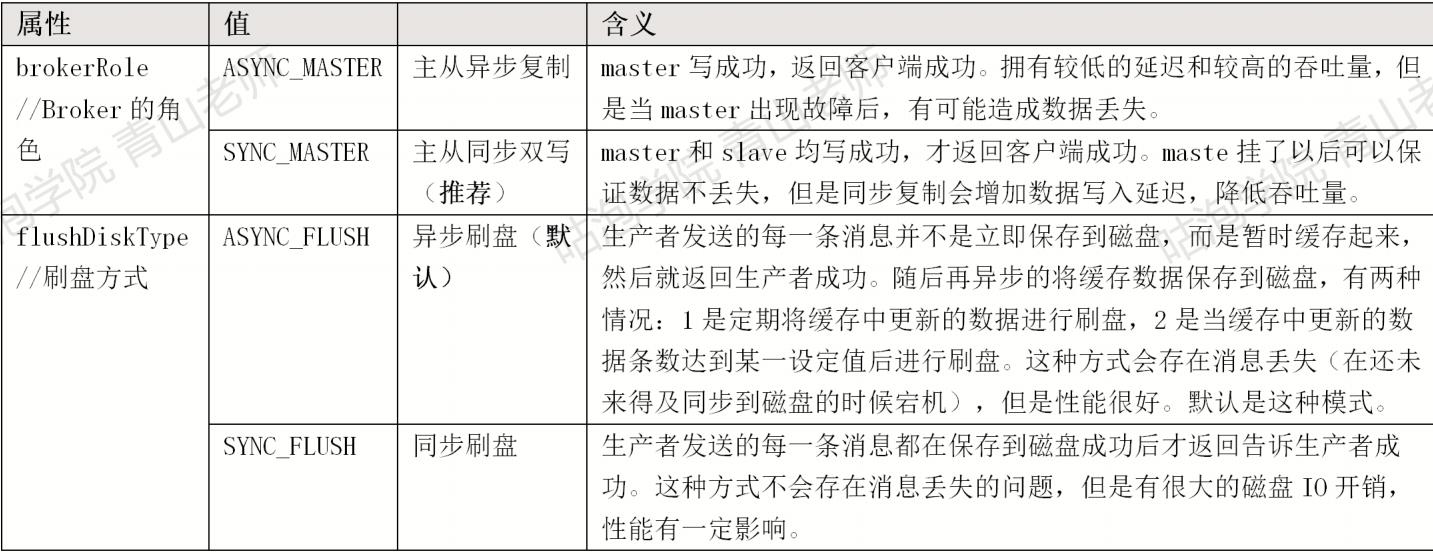
通常情况下,会把主节点和从节点的Broker配置成ASYNC_FLUSH异步刷盘的方式,主从之间配置成SYNC_MASTER同步复制的方式,即:异步刷盘+同步复制。
下图是异步刷盘和同步刷盘的理解图:
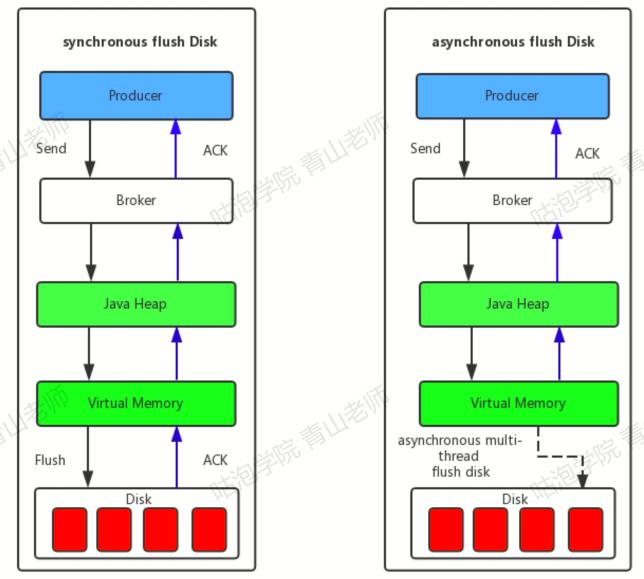
主从同步的流程
- 从服务器主动建立TCP连接主服务器,然后每隔5s向主服务器发送commitLog文件最大偏移量拉取还未同步的消息。
- 主服务器开启监听端口,监听从服务器发送过来的信息,主服务器收到从服务器发过来的偏移量进行解析,并返回查找出未同步的消息给从服务器。
- 客户端收到主服务器的消息后,将这批消息写入commitLog文件中,然后更新commitLog拉取偏移量,接着继续向主服务器拉取未同步消息。
高可用与故障转移
在之前的版本中,RocketMQ只有一种master/slave部署方式:一组Broker中有一个master和零个到多个slave,slave通过同步复制或异步复制的方式去同步master的数据。提供了一定的高可用性。
但是这样的部署模式具有一定的缺陷。比如故障转移方面:如果主节点挂了还需要人为手动的进行重启或者切换。
在4.5.0的版本中,rocketmq利用了Dledger技术解决了自动选主的问题。引入Dledger技术,其实就是使用Dledger的CommitLog来替换掉Broker自己的CommitLog。然后Broker仍然可以基于Dledger的CommitLog,把消息的位置信息保存到ConsumeQueue中。
Dledger是一个基于raft协议的commitlog存储库,也是rocketmq实现新的高可用多副本架构的关键。优点是:不需要外部引入组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
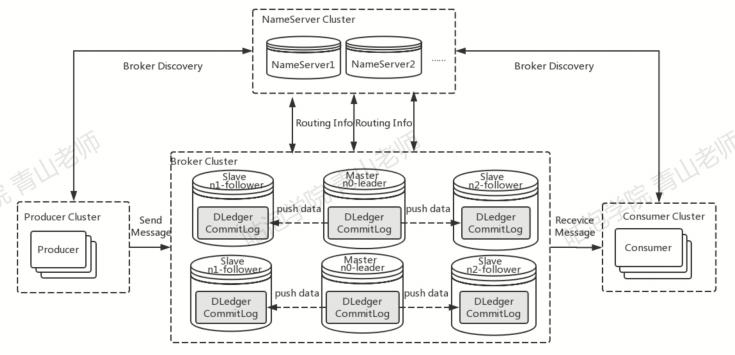
在这种情况下,commitlog是Dledger管理的,具有选主的功能。
#是否启用Dledger,即是否启用主从切换,默认值为false
enableDLegerCommitLog = true
#DLedger Raft Group 的名字
dLegerGroup = broker-a
#DLedger Group 内各节点的地址和端口,至少需要3个节点
dLegerPeers = n0-192.168.44.163:10911;n1-[server-ip]:[server:port];n[number]-[server-ip]:[server-port]
#本节点ID
dLegerSelfId = n0
知识点补充:raft协议选主过程
假设我们的一组Broker中有三台机器,它们之间首先要选择一个Leader,这需要发起一轮一轮的投票,三台机器互相投票最终确定出Leader。
在刚刚启动的时候,这三台机器都会投给自己一票,说:"我要当Leader,别跟老子抢",然后把这条消息通知给其他机器。
为了方便说明,我们把三台机器分别命名为A,B,C.
那么经过第一轮投票后,A,B,C分别给自己投了一票,并发送给了别人。
这个时候A接到消息一看,好家伙,每个人都投的自己,都很自私,那算了,这次投票直接无效。
接着,每个人开始一段随机时间的休眠,比如A休眠了3秒,B休眠了4秒,C休眠了5秒。
那么3秒过去了,A醒了,抓紧给自己投了一票,又发给别人了。
又过了1秒,B醒了,它也想给自己投票,但是它发现已经有人发给了它消息,现在A已经有一票了,这个时候B会尊重别人的选择,也把票投给A,然后发送给别人。
又过了1秒,C醒了,同样也想给自己投票,但是发现别人已经投了两票给A了,那这时候它也会直接尊重别人的选择,投票给A,然后发送给别人。
这个时候所有人都收到了投票,全是投票给A的,那么A就光荣上岗了。
选举的时候就是谁的票数多,谁就去当老大。
这就是Raft协议中选举Leader的简单解释,总结起来就是,假如一轮投票不能得到结果,那就每个人随机休眠一下,先醒过来的投给自己,后醒过来的尊重大多数人的意见。
依靠这种方式的投票,几轮下来就能选出一个Leader了。
当然,职位越高,责任越大,选举出Leader后,所有的接收消息操作全都由Leader来负责了,Follower只能同步Leader的数据。
Dledger的数据同步机制
Dledger也是通过Raft协议进行多副本同步的,简单来讲,数据同步分为两个阶段,uncommitted阶段和committed阶段。
首先,当Leader接到消息数据后,会先标记消息为uncommitted状态,然后通过Dledger的组件把uncommitted状态的消息发送给Follower上的DledgerServer。
接着Follower接到消息后进行数据同步后,会发送一个ack给Leader上的DledgerServer,然后如果Leader发现超过半数的Follower已经给自己返回了ack,那么就认为同步成功了,这时候把状态改为committed。
然后再发消息给Follower,将Follower上的状态也改为committed。
这就是基于Dledger的数据同步机制。
深度挖掘RocketMQ底层源码「底层系列」深度挖掘RocketMQ底层导致消息丢失透析(Broker Busy和ToManyRequest)
承接上文
通过上一篇文章《【深度挖掘 RocketMQ 底层源码】「底层问题分析系列」深度挖掘 RocketMQ 底层那些导致消息丢失的汇总盘点透析([REJECTREQUEST]》,我们知道了对应的“[REJECTREQUEST]system busy, start flow control for a while”的主要原因。
回顾问题要点
再次追踪以下问题代码的未知,我们可以看到其抛出的源码入口点:NettyRemotingAbstract#processRequestCommand。

上面的原理分析部分已经详细介绍其实现原理,总结如下:
主要由两种场景的考虑
- 在不开启transientStorePoolEnable机制时,如果Broker PageCache繁忙时则抛出上述错误,判断PageCache繁忙的依据就是向PageCache追加消息时,如果持有锁的时间超过1s,则会抛出该错误。
- 在开启transientStorePoolEnable机制时,其判断依据是如果TransientStorePool中不存在可用的堆外内存时抛出该错误。
本章内容方向
-
too many requests and system thread pool busy, RejectedExecutionException
-
[PC_SYNCHRONIZED]broker busy, start flow control for a while
-
[PCBUSY_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d
问题:too many requests and system thread pool busy, RejectedExecutionException
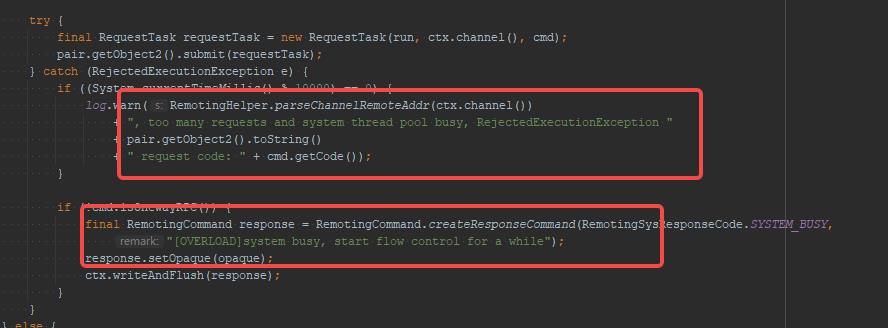
其抛出的源码入口点:NettyRemotingAbstract#processRequestCommand,其调用地方紧跟3.1,是在向线程池执行任务时,被线程池拒绝执行时抛出的,我们可以顺便看看Broker消息处理发送的线程信息:
BrokerController#registerProcessor
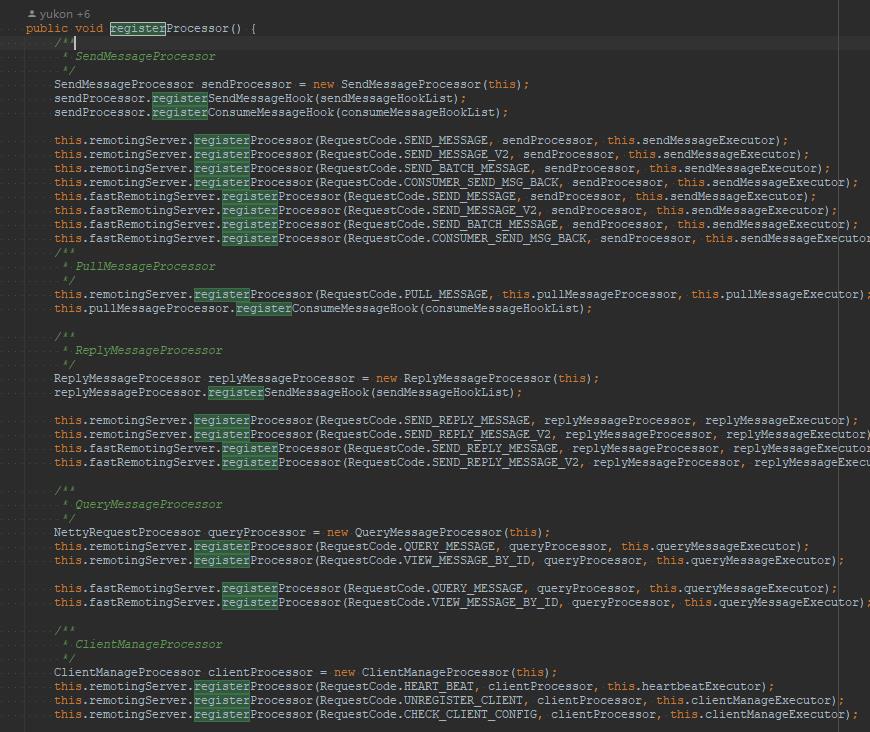
主要看的是队列的BlockedQueue的长度进行控制说明:

该线程池的队列长度默认为10000,我们可以通过sendThreadPoolQueueCapacity来改变默认值,如下图所示。
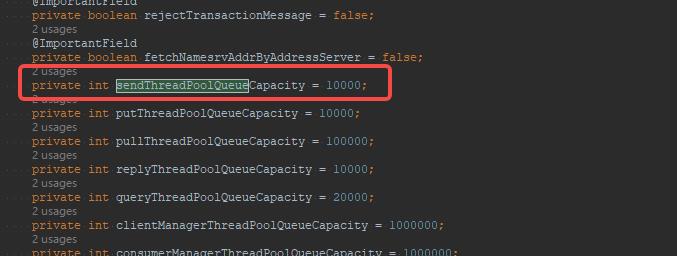
private int sendThreadPoolQueueCapacity = 10000;
[PC_SYNCHRONIZED]broker busy
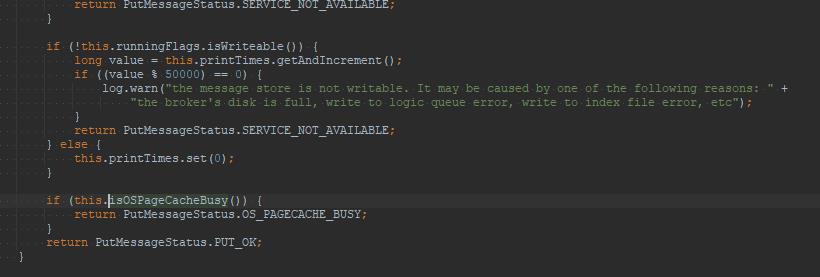
其抛出的源码入口点:DefaultMessageStore#putMessage,在进行消息追加时,再一次判断PageCache是否繁忙,如果繁忙,则抛出上述错误。
@Override
public boolean isOSPageCacheBusy()
long begin = this.getCommitLog().getBeginTimeInLock();
long diff = this.systemClock.now() - begin;
return diff < 10000000
&& diff > this.messageStoreConfig.getOsPageCacheBusyTimeOutMills();
@Override
public long lockTimeMills()
return this.commitLog.lockTimeMills();
public SystemClock getSystemClock()
return systemClock;
public CommitLog getCommitLog()
return commitLog;
上述的代码已经在上一章节已经完成了介绍,对应的服务处理和逻辑引发的问题,大家可以关注上一章的内容即可。
broker busy, period in queue: %sms, size of queue: %d
其源码的入口点
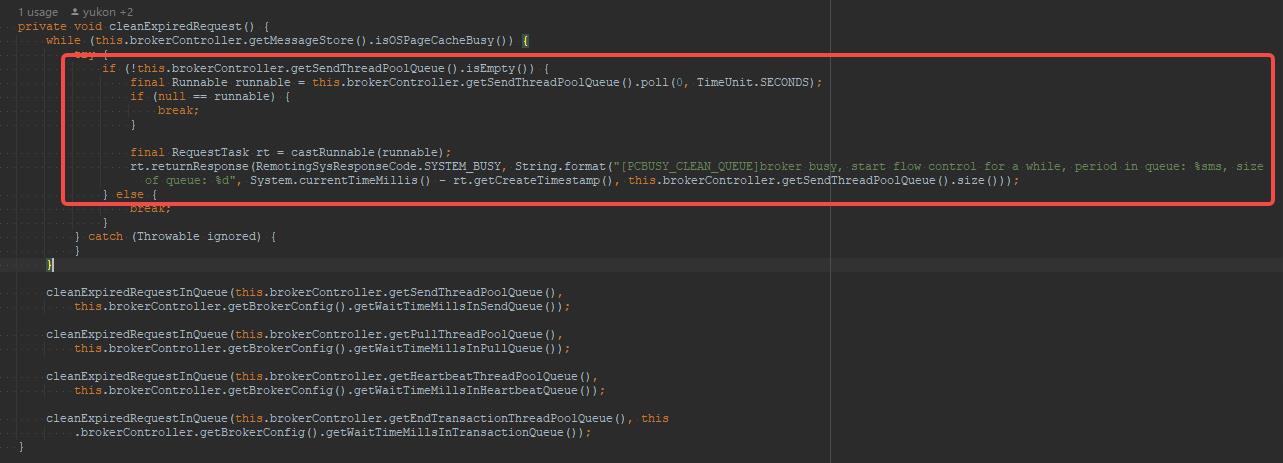
BrokerFastFailure#cleanExpiredRequest,该方法的调用频率为每隔10s中执行一次,不过有一个执行前提条件就是Broker端要开启快速失败,默认为开启,可以通过参数brokerFastFailureEnable来设置。该方法的实现要点是每隔10s,检测一次,如果检测到PageCache繁忙,并且发送队列中还有排队的任务,则直接不再等待,直接抛出系统繁忙错误,使正在排队的线程快速失败,结束等待。
不靠谱得方案
消息发送时抛出system busy、broker busy的原因都是PageCache繁忙,那是不是可以通过调整上述提到的某些参数来避免抛出错误呢?例如,如下参数:
osPageCacheBusyTimeOutMills
设置PageCache系统超时的时间,默认为1000,表示1s,那是不是可以把增加这个值,例如设置为2000或3000。不推荐
sendThreadPoolQueueCapacity
Broker服务器处理的排队队列,默认为10000,如果队列中积压了10000个请求,则会抛出RejectExecutionException。不推荐
brokerFastFailureEnable
是否启用快速失败,默认为true,表示当如果发现Broker服务器的PageCache繁忙,如果发现sendThreadPoolQueue队列中不为空,表示还有排队的发送请求在排队等待执行,则直接结束等待,返回broker busy。那如果不开启快速失败,则同样可以避免抛出这个错误。不推荐
问题总结
修改上述参数,都不可取,原因是出现system busy、broker busy这个错误,其本质是系统的PageCache繁忙,通俗一点讲就是向PageCache追加消息时,单个消息发送占用的时间超过1s了,如果继续往该Broker服务器发送消息并等待,其TPS根本无法满足,哪还是高性能的消息中间了呀。
靠谱得方案
开启transientStorePoolEnable,在broker配置文件中将transientStorePoolEnable设置为true。这个方案在上一篇文章已经介绍过了,再次就不过多赘余。
它得问题重点是集中于
会增加数据丢失的可能性,如果Broker JVM进程异常退出,提交到PageCache中的消息是不会丢失的,但存在堆外内存(DirectByteBuffer)中但还未提交到PageCache中的这部分消息,将会丢失。但通常情况下,RocketMQ进程退出的可能性不大。
扩容Broker服务器
当Broker服务器自身比较忙的时候,才会采用快速失败机制,直接给消息发送者返回错误,消息发送者默认情况会重试2次,将消息发往其他Broker,保证其高可用,并且在接下来的一段时间内会规避该Broker,这样该Broker恢复提供了时间保证,Broker本身的架构是支持分布式水平扩容的,增加Topic的队列数,降低单台Broker服务器的负载,从而避免出现PageCache。
Broker扩容时候,可以复制集群中任意一台Broker服务下$ROCKETMQ_HOME/store/config/topics.json到新Broker服务器指定目录,避免在新Broker服务器上为Broker创建队列,然后,消息发送者、消息消费者都能动态获取Topic的路由信息。
以上是关于RocketMQ底层详解的主要内容,如果未能解决你的问题,请参考以下文章