Python中正则表达式太长,如何换行?
Posted Muen2020
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python中正则表达式太长,如何换行?相关的知识,希望对你有一定的参考价值。
Python中正则表达式太长,如何换行?
方法一 使用松散正则表达式
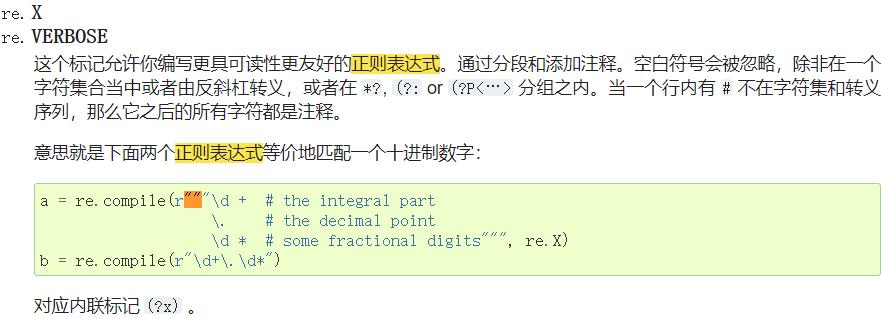
方法二 括号内自动多行拼接
括号内可以进行多行拼接,不用加其他符号。
可以这样写:
re.search(r\'aaa\'
r\'bbb\'
r\'ccc\',\'aaabbbccc\')
相当于
re.search(r\'aaabbbccc\',\'aaabbbccc\')
方法三 使用+拼接
pattern = r\'aa\'
pattern += r\'bb\'
如何在 Python 中使用正则表达式将所有内容匹配到双换行符“\n\n”?
【中文标题】如何在 Python 中使用正则表达式将所有内容匹配到双换行符“\\n\\n”?【英文标题】:How to match everything up to double newline "\n\n" using regex in Python?如何在 Python 中使用正则表达式将所有内容匹配到双换行符“\n\n”? 【发布时间】:2020-11-16 15:17:16 【问题描述】:假设我有以下 Python 字符串
str = """
....
Dummyline
Start of matching
+----------+----------------------------+
+ test + 1234 +
+ test2 + 5678 +
+----------+----------------------------+
Finish above. Do not match this
+----------+----------------------------+
+ dummy1 + 00000000000 +
+ dummy2 + 12345678910 +
+----------+----------------------------+
"""
我想匹配第一个表的所有内容。我可以使用从
开始匹配的正则表达式"Start"
匹配所有内容,直到找到双换行符
\n\n
我在另一个 *** 帖子 (How to match "anything up until this sequence of characters" in a regular expression?) 中找到了一些关于如何执行此操作的提示,但它似乎不适用于双换行符。
想到下面的代码
pattern = re.compile(r"Start[^\n\n]")
matches = pattern.finditer(str)
基本上在哪里
[^x]
表示匹配所有内容,直到找到字符 x。但这仅适用于字符,不适用于字符串(在这种情况下为“\n\n”)
有人知道吗?
【问题讨论】:
【参考方案1】:您可以匹配 Start 直到行尾,然后使用负前瞻 (?! 匹配所有以换行符开头且不紧跟换行符的行
^Start .*(?:\r?\n(?!\r?\n).*)*
说明
^Start .* 从字符串 ^ 的开头匹配 Start 和 0+ 次除换行符以外的任何字符
(?:非捕获组
\r?\n 匹配换行符
(?!\r?\n) 负前瞻,断言直接在右边的不是换行符
.* 匹配除换行符以外的任何字符 0+ 次
)*关闭非捕获组,重复0+次得到所有行
Regex demo
【讨论】:
我不太确定这是做什么的,但它确实有效。非常感谢!我会花一些时间来理解这个正则表达式 @Andrew 我稍后会添加解释。以上是关于Python中正则表达式太长,如何换行?的主要内容,如果未能解决你的问题,请参考以下文章