Linux下中文乱码
Posted 刘草草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux下中文乱码相关的知识,希望对你有一定的参考价值。
引用:https://www.jianshu.com/p/bcede182647e
一、原因分析
这原因由于Linux是开源的,很多的字体没有被默认安装,在生成PDF的时候找不到对应字体找不到导致的。
1.查看系统预装字体
如果找不到 fc-list的命令,就执行下面的安装命令
cat /etc/issue # 查看Linux发行版本
Ubuntu
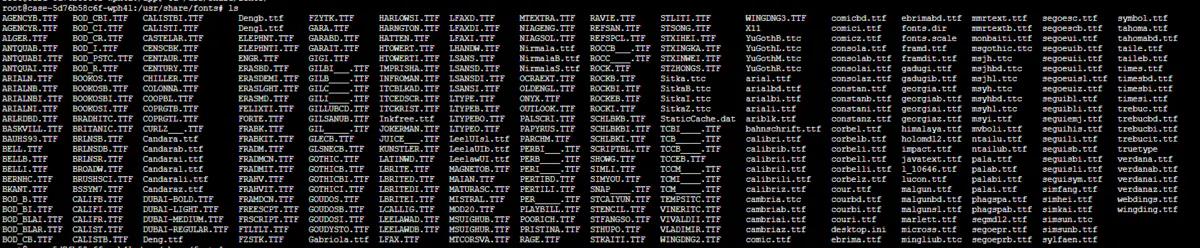
fc-list # 查看已有字体
fc-list :lang=zh # 查看中文字体
如果找到了中文字体,就需要查看PDF中的字体是否有被安装,没有被安装就需要安装相对应的字体。
2.安装字体
安装字体这玩意,可以只安装自己需要的字体,但是建议是将Win的所有字体全部安装好,这样一步到位,比较省心。
首先将Win的字体全部打包成Zip导入到需要被安装的Linux主机上。
Win字体存放路径 C:\\Windows\\Fonts
如果安装全部的字体就直接将这个文件夹Copy一份到其他的目录下然后直接将这个文件夹打包成压缩包。(这样比较靠谱)

然后将这个压缩包上传到服务器上的 /usr/share/fonts/目录下
我的是用Powershell上传的
scp xxx/xxx/Fonts.zip root@192.168.1.122:/usr/share/fonts/
然后上到Linux机器上 执行如下命令
unzip ./Fonts.ziprm -rf ./Fonts.zip
rm -rf ./*.fon #这种字体是安装不上的
mkfontscale
mkfontdir
fc-cache
这个压缩包中的字体不会被全部安装的,有几个是安装不上的,但是不影响基本使用
应该是只能安装ttf和ttc的字体,我猜的
fc-list :lang=zh
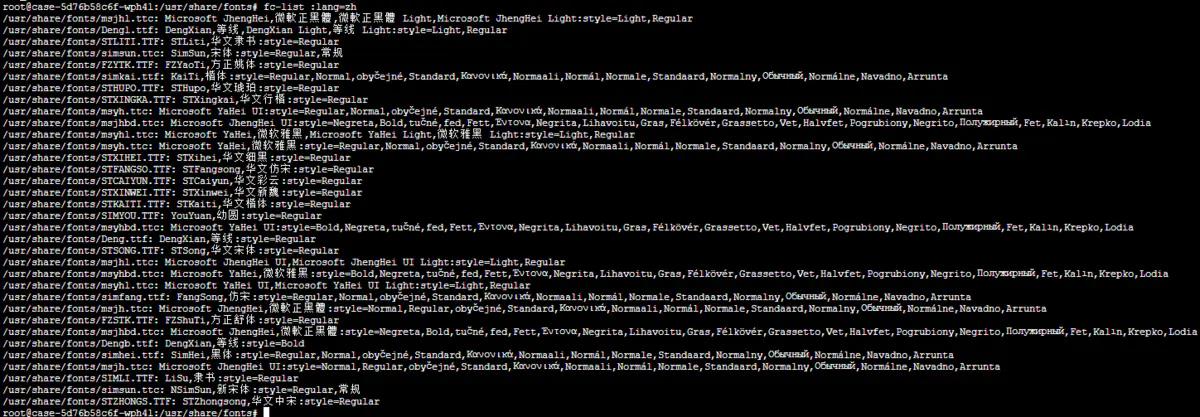
到这里字体就安装完毕了,再试试生成PDF应该就没有问题了。
3.运行在Docker中的程序如何解决这个问题
首先将源镜像下载下来
然后直接启动源镜像
docker run -it -d xxxx/dotnet/aspnet:3.1-buster-slim
然后将文件拷贝进去
cd .\\Desktop\\
docker cp .\\Fonts.zip quizzical_darwin:/ # 这里要用容器名字
docker exec -it quizzical_darwin /bin/bash # 进入容器中
再执行ubuntu的那些操作(使用本文上面的字体安装步骤,安装成功后退出)
然后再将这个有字体的镜像做成源镜像
docker commit -a "hulailai" -m ".net core for pdf-service" 20269bb55607 dotnet-font-base
如果需要上传到服务器就直接大哥标签然后上传到服务器
docker tag dotnet-font-base xxxx
docker push xxxx
搞定
再将这个源镜像作为你容器运行的 源镜像就OK了。
windows下中文正常,Linux下乱码
由于项目需要我重写了getWriter(),并定义ByteArrayOutputStream()字符集编码为“GBK”在window下生成的静态页面能正常显示中文!后面放到Linux上部署,可能是Linux默认是utf-8的编码于是出现乱码,把字符集编码改为“UTF-8”生成的静态中文HTML页面,但是改成“utf-8”后在window下生成的静态中文页面又变成乱码,我只能改为“GBK”编码!请教大家有什么办法可以让我只用一种字符集编码就可以让项目在两种系统上面正常部署!!谢谢了
我只能说这个项目你应该重做。所有内部处理一律用 UTF8 ,包括你开发时所有数据也都用 UTF8写。Wndows 用英文版的服务器。或者在输出数据时,都做一次编码转换。
重做的最主要是重新检查所有的输入输出函数。都调用编码转换函数,这个转换函数检测系统版本作处理(哪怕作 GBK->GBK 这种无意义的转换工作)。
Windows 的编码混乱问题确实不好解决,你可以事实让服务器发送编码信息,编码用 UTF8 ,则样浏览器端默认就用 UTF8 就没乱码了。 参考技术A 统一用UTF-8生成,不要用GBK。并定义ByteArrayOutputStream()字符集编码为“UTF-8” 参考技术B 使用该命令:
iconv -f gbk -t utf8 文件名 > 重命名 参考技术C 应该是要做编码识别 或者系统识别,然后再设定相应的编码集 参考技术D 编码不同的问题
以上是关于Linux下中文乱码的主要内容,如果未能解决你的问题,请参考以下文章