Base64
Posted 李卓桐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Base64相关的知识,希望对你有一定的参考价值。
关于Base64
什么是Base64
-
百度百科上说:base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。可查看RFC2045~RFC2049,上面有MIME的详细规范Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。Base64由于以上优点被广泛应用于计算机的各个领域,然而由于输出内容中包括两个以上“符号类”字符(+, /, =),不同的应用场景又分别研制了Base64的各种“变种”。为统一和规范化Base64的输出,Base62x被视为无符号化的改进版本。
-
通俗一点,base64就是一种基于64个可打印字符来表示二进制数据的表示方法
The Base64 Alphabet
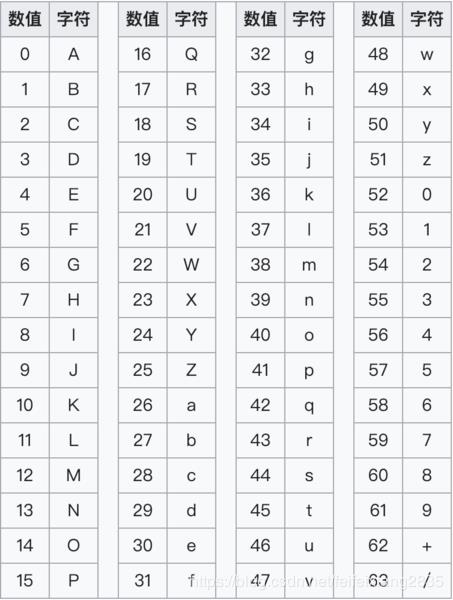
base64的编码过程
- base64的编码都是按字符串长度,以每3个8bit的字符为一组,
- 然后针对每组,首先获取每个字符的ASCII编码,
- 然后将ASCII编码转换成8bit的二进制,得到一组3*8=24bit的字节
- 然后再将这24bit划分为4个6bit的字节,并在每个6bit的字节前面都填两个高位0,得到4个8bit的字节
- 然后将这4个8bit的字节转换成10进制,对照Base64编码表 (下表),得到对应编码后的字符。
base64的应用实例

Python中使用base64

Base64解码,直到没有Base64
所以我认为我的问题非常简单。我需要解码Base64,直到没有Base64,如果有一些Base64,我用RegEx检查,但我不知道如何解码,直到没有Base64。
在这个简短的代码中我可以解码Base64,直到没有Base64,因为我的文本是定义的。 (直到Base64 Decode Stuff不是“Hello World”解码)
# Import Libraries
from base64 import *
import re
# Text & Base64 String
strText = "Hello World"
strEncode = "VmxSQ2ExWXlUWGxUYTJoUVVqSlNXRlJYY0hOT1ZteHlXa1pLVVZWWE9EbERaejA5Q2c9PQo=".encode("utf-8")
# Decode
objRgx = re.search('^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$', strEncode.decode("utf-8"))
strDecode = b64decode(objRgx.group(0).encode("utf-8"))
print(strDecode.decode("utf-8"))
while strDecode != strText.encode("utf-8"):
strDecode = b64decode(strDecode)
print(strDecode.decode("utf-8"))
有没有人有一个想法如何解码Base64,直到有真正的文本(没有更多base64)
P. S.抱歉我的英语不好。
你不能,不能在任意意义上。问题很简单就是正常,每天的单词也可以是BASE64。所以,没有真正的方法来区分两者之间的区别。
BASE64没有长度以外的终结符。它可以用=或==终止,但不能终止。 =只是填充。不需要填充,然后没有=。因此BASE64可能会结束并且一些文本将开始,而您无法检测到它。
编辑“所以我真的没办法做我想要的事情吗?”:
不,不是确定性的,不可靠的。即使使用启发式方法,也有可能出现失败的情况,最终会消耗太多字符,导致二进制块结尾处出现垃圾,以及后续文本流中的字符丢失。
现在这是一个任意的BASE64块。如果你知道二进制数据是什么,那么也许是希望。
例如,如果你知道二进制数据是什么,大多数二进制格式“知道”何时“完成”。我不知道有效的二进制格式是“读到EOF”。它们通常包含内部描述符“这是下一个块有多少数据”或终结者说“我已经完成”。
在这些情况下,您可以将BASE64视为流。 BASE64基本上非常简单。它需要3个字节并将它们转换为4个字符。
因此,B64流读取器需要简单地读取4个字符并返回它们代表的3个字节。
如果你有一个PNG阅读器,它可以开始读取转换后的流。当它“完成”时,它“关闭”流,你的原始文本“在BASE64的末尾”。
如果您知道原始附件的大小,它也可以工作。如果有人发送“10,000字节”,那么您使用BASE64流解码器并从中读取“10,000”字节。
通常情况下,您将使用带有=或==终止符的BASE64。在这种情况下,你不会这是一个问题。解码的流以任何一种方式工作。
如果你不知道附件的原始大小,或编码二进制文件的格式,那么你几乎没有运气。
作为启发式,您可以计算结果中的平均字长。自然语言会有短语,例如“作为启发式,你可以看一下单词长度。”仍然是Base64编码的字符串将在空格之间具有很少的空格和长字符串。
作为另一种启发式方法,您可以计算元音(a,e,i,o,u)与辅音的比例或单词中间的大写字母数。
那么你正在处理可能已经反复进行base64编码的数据块?为什么不通过b64decode()循环字符串直到它出错呢?
此外,我认为你可能不需要洒这么多的.encode("utf-8")。
我在这里看到两个有价值的答案,指的是平均字长(Mark Lutton)和原始数据的字节大小(Will Hartung)。另一个有用的东西:寻找预期的词典单词,有意义的数字或/和日期。
以上是关于Base64的主要内容,如果未能解决你的问题,请参考以下文章