云原生落地思考实践
Posted 云架构师大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生落地思考实践相关的知识,希望对你有一定的参考价值。
最近交流谈论最多的就是云原生,企业内部也在努力实践落地云原生,今天就来写写这个话题。
一、云原生需要一个强壮的底座
谈云原生离不开一个健壮的基础层,所以先说一下这个底座应该长啥样,分为三部分IaaS、PaaS和云管平台:
1、IaaS
1.2、SDN提供了网络控制转发分离,例如openstack Neutron调用SDN控制器的北向接口实现网络策略动态分配和变更(例如创建vrouter、vfw、subnet、配置vtep等)并在之上形成了VPC(Virtual Private Cloud, 虚拟私有云),可配置的虚拟网络可参考下表(同openstack概念一致):
元素名称 |
描述 |
Tenant |
租户。 |
Network |
一个虚拟的二层隔离网络。可以看作是一个虚拟的或逻辑的交换机。 |
Subnet |
|
Port |
一个虚拟的或逻辑的交换机端口。 |
vRouter |
代表逻辑三层网关/网络,分散在各个虚拟设备上; |
vFW vLB vIPS |
网络服务功能NFV,为每个租户提供独立的FW、LB及IPS服务; |
Security Group |
vSwitch上的安全组功能。 |
另外SDN的控制范围最好是整个数据中心甚至某个区域,这样可以做好数据中心层面的二层网络打通。
1.3、全互联的spine-leaf网络架构提供了强大的横向高带宽和扩展能力
IaaS计算资源管理层面可以使用vmware vcenter或openstack+kvm,如果使用vcenter一般使用vmware nsx作为SDN控制器,且nsx控制范围只能是在一个vcenter内部。所以目前还是推荐使用openstack+kvm同商用SDN结合的方式。
存储:
存储分为块存储、文件存储和对象存储。传统块存储可以是本地磁盘或者集中式的SAN存储等。SAN存储基本结构都是冗余的存储控制器、缓存、SSD、HDD存储和SAN网络组成。传统的文件存储一般使用natapp HP等厂商的商用集中式存储。如果具备一定的运维和研发能力,更推荐使用分布式存储,例如ceph,可以同时支持块存储、文件存储和对象存储(兼容S3)的分配能力。ceph基本能力见下图:
补充一点openstack基本可以兼容主流厂商的集中式存储和ceph等。
安全能力:
另外对于数据中心还需要具备一些基础安全防护和网络服务能力、基本的如DNS、HTTPDNS(推荐使用替代DNS)、CDN、负载均衡(绑定bgp或者公网IP实现SNAT和DNAT,有钱用F5没钱可用OSPF+LVS)、DDOS流量清洗、入侵检测IDS、WAF防火墙、传统防火墙、数据中心设置不同的网络区域、低安全区域到高安全区域需要进行防火墙隔离(例如从DMZ到核心网)、稍微高级点的具备安全风险动态感知处理能力,简单来说就是自动收集外部披露的安全漏洞信息和进行内部系统日志、网络设备、端口和主机漏洞扫描,实时进行安全风险分析预警甚至自动化处理。还有最近大热的DevSecOps简单来说就是对程序、基础镜像、代码进行扫描从开发的源头开始就介入进行安全管控,镜像代码有漏洞直接打回别走后面CICD了。
2、PaaS
一个完整的应用怎么能少得了各类中间件的加持,还有应用微服务多了怎么管理?必然需要进行服务治理、统一监控、统一日志、APM、全链路压测、混沌功能等来保障微服务更好更高效的运营,所以PaaS的重要性不言而喻。
PaaS层提供的能力矩阵主要包括容器、负载均衡、数据库、消息中间件、微服务框架、全链路监控、统一日志及监控中心,DevOps等,每个展开说下:
kubernetes:
采用容器的最大好处在于dockerfile本身就是运行环境,可通过git和apollo就可以完成配置管理,一切既代码,任何问题git里面一清二楚完整可追溯,将运维工作前移至开发,运维人员只要负责维护好容器平台即可,不在有什么war包、配置文件、上线变更控制表之内的东西,彻底解放了运维人员,可以抽出精力做更多提效的事情;
kubernetes监控和中间件监控可以统一采用promethues,promethues提供了各类通用中间件的exporter用来采集指标,非常好用。
支持对接底层分布式存储为用户提供PV、PVC;镜像仓库habor;支持Istio和Knative;
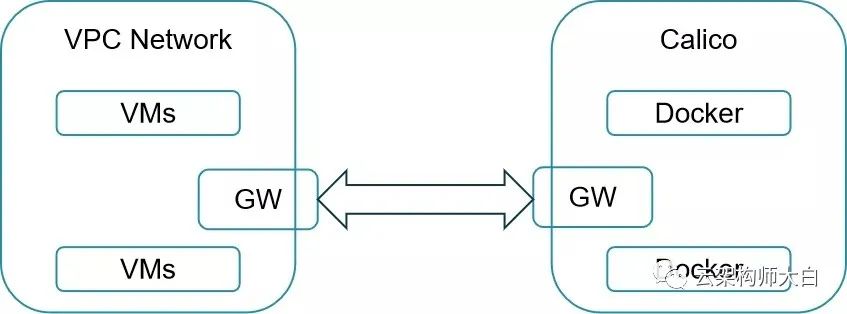
可以在SDN VPC网络基础之上构建kubernetes,可使用Flannel vxlan模式(使用这种模式,无疑产生了2层overlay,性能影响略大,解决方法可参考https://blog.csdn.net/wangyiyungw/article/details/84334552),如果是一个VPC内部的一个subnet也可以使用flannel host-gw模式。另外也可以使用calico(calico是基于BGP协议,如果是在同一个子网subnet下使用没有问题,如果是跨二层的话需要容器所在宿主机和vrouter组成一个BGP,需要vrouter支持;还有一个折中方式就是采用calico的IPIP模式,本质还是overlay),其他如macvlan模式可以直接使用VPC的IP网段可以直接和VPC内的其他虚拟机通信;也可以在非VPC网络构建kubernetes,采用网关GW做路由转发,如下图:
负载均衡:如nginx、lvs等,支持正向代理、反向代理、各类负载均衡策略、亦可支撑URL或者header解析级别灰度发布、客户端IP透传等能力。特别要注意TCP参数优化非常重要,否则很难适应大并发,例如tw_reuse、syn_backlog等参数。
消息中间件:pulsar、kafka、rocketMQ,日志采集等其他对数据丢失或重复消费不是极其敏感的且要求吞吐量极大的场景建议使用kafka;对数据消息一致性顺序性要求特别严格的场景,例如账务数据等建议使用rocketMQ,pulsar研究中。
数据库:mysql注意索引优化、不要设置强制的主键外键依赖、同时具备数据库复制、利用mycat等实现分库分表等;redis最推荐使用集群模式,可以同城跨中心部署,具备跨中心高可用,且支持更新扩展,集群的TPS可以轻松达到百万级,合理处理穿透击穿雪崩,同时注意避免O(n)操作,redis6.X支持多租户和IO的多线程,推荐使用,另外推荐使用ucloud开源的redis cluster operator 支持容器部署和动态扩容故障自愈非常强大。设计思路可参考:https://blog.csdn.net/Ucloud_TShare/article/details/101196246
部署实例如下图:
大数据:elasticsearchflink等,flink支持流式处理和批处理,拥有极低的延时、高吞吐、完善的状态管理和一定的容错恢复能力,可以跑在YARN上也可以直接跑在kubernetes上,使用flink提供的SQL或者stream方式和大量函数可以很方便的实现一些流式任务,目前智能指标告警、智能投顾、量化交易的一些需要大量数据输入的核心算法都跑在上面,时间效率和计算速度比以前一个python程序单机算快了不是一点半点,强烈推荐。ES更不用说了,存储日志告警数据的大仓库,TB、PB级别的数据都不在话下,倒排索引查询效率一流,上面支持grafana展示。
微服务相关:服务注册发现中心和API网关,服务注册发现解决大量微服务之间互相调用问题可以使用的技术很多,API网关对外提供统一的服务入口,解决安全、灰度、流控、熔断、降级等问题。技术上选择比较多zookeeper、consul、eureka等各有优劣,个人比较推荐eureka,主要原因是符合cap的AP原则,可用性是最需要保障的。
统一配置中心(推荐使用apollo)。另外特别强调的是使用诸如dubbo或者spring cloud这类微服务架构的问题在于限制了开发语言和调用方式(RPC or restful)。建议关注并使用istio,istio最大的优势在于和开发语言无关,和开发框架无关,对开发完全透明。
DevOps平台:底层技术基于git、jenkins webhook、静态sonar、jenkins利用启动K8s容器做持续集成,CI完毕后立刻释放容器资源、对接saltstack CD虚拟机部署和对接k8s进行容器部署。
全链路业务监控:例如zipkin采用SDK方式,需支持open tracing,未来有可能会换用istio jeager方式,值得关注。
统一日志及监控中心:操作系统层采用open falcon、开源中间件层采用promethus exporter、应用层采用自研程序采集后吐给open falcon、操作系统和应用日志统一通过filebeat采集、后端统一对接ES做存储、grafana展现和flink做告警。
生产环境全链路压测:这是一个系统工程,要考虑的点包括业务范围梳理、测试数据准备、测试路径梳理、相关程序改造(如区分哪些是测试数据、数据库是使用单独的还是共用生产的,kafka是使用同一个topic还是不同的topic等)、测试数据清理、结果数据收集报告等环节。
混沌工程:指定时间在生产环境一定场景内随机的故障注入(故障场景涵盖网络、应用、OS、硬件等),同时需防止大规模的生产中断,如chaomonkey。
分布式事务:可参看之前的 ,推荐尽量避免分布式事务或使用rocketMQ。
3、统一大云管平台
统一的大云管平台需要具备的能力如下:
对接底层IaaS接口提供IaaS资源管理能力,包括openstack、vmware、SDN、存储、网络等;
对接PaaS中间件,包括中间件资源的全生命周期管理、用户自服务等;
提供用户关心的各类资源监控告警能力;
自动化运维能力;
对接k8s接口提供容器管理能力;
确保企业CMDB数据准确性,ITIL事件驱动,CMDB数据准确性自动校验;
认证、角色权限、配额、计量计费管理;
报表和运营数据;
统一云管平台同样要遵循和业务系统一样的架构设计原则,例如领域驱动开发、开发规范、微服务、使用统一的API网关、服务注册发现、全链路监控、统一日志等等,现在例如蓝鲸等运维PaaS平台也基本是按照这个设计理念,这里就不在赘述了。
二、云原生怎么落地
首先说说什么是云原生,CNCF定义:云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用,云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
再复制一下网上找的图片:
以上技术好像在上面的PaaS里面全部都说过了,确实是这样,云原生底层的技术基本就是这些,但是想要落地云原生,必须以业务为核心同时需要一个与之适配的组织架构。真的痛了,才会更有动力去落地云原生,企业架构永远不是一蹴而就,而是螺旋式上升。痛苦的过程我简单列举一下:
随着业务发展,产品功能需求越来越多,单体应用功能越来越庞大,同时单体应用随便一点改动升级都要影响所有上面的所有其他业务功能,重新测试部署,业务响应相对较慢,各种能力其他应用也很难复用。所以为了更快的响应业务各类需求,需要进行服务拆分微服务改造,这样也可以同步进行开发组织架构的拆分,毕竟一个开发小组人员也不宜过多。
拆分成微服务后,这么多服务,部署就需要大量虚拟机,资源存在浪费;这么多服务如何进行微服务治理?出问题如何分析调用链延时和成功失败情况?缓慢增长的运维人员数量同应用的快速增加和发布频率的增加的矛盾日益尖锐。
如果落地云原生其实技术路线不一定完全相同,但是一般来说要具备如下能力:
开发者输出最必要的信息(例如GIT url、需要的部署模式、规模配置等)即可完成服务的一键打包测试部署,部署升级过程可做到全自动;
应用创建部署后既具备基础的监控、日志展现、运营数据等运维能力;
代码既基础设施,运维人员可全程完全不参与;
具备弹性伸缩、灰度发布、流控降级等能力,方便运维人员使用;
这里也分享一个落地步骤和经验,底座基于Kubernetes:
业务模块拆分:
按照业务需求和业务功能进行拆分,没有需求没有痛点的挺好拆他干嘛。每个微服务具备独立的数据库并通过restful或者RPC方式同其他微服务通信。
另外对于WEB应用,现在流行做WEB前后端分离,其中前端使用react nodejs部署放置在DMZ区,后端放置在核心网。前端甚至也可以使用微服务架构,KS8一般分区域部署,这时候就要考虑不同k8s集群通信问题。
代码开发:
--> 遵循开发测试规范,每个模块工程目录结构命令规范,API命名规范、swagger注释规范方便形成统一的API文档库,测试覆盖率、mock规范、异常处理、敏感信息加密等等。
--> 开发者在开发代码时使用注册中心发布服务和使用其他team提供的服务。
--> 使用统一配置中心实现配置的统一管理和在线动态发布。
--> 使用统一SDK、统一标准化日志、或者直接使用云原生的istio+jeager方式接入APM系统,形成全链路微服务调用链监控。
--> 其他服务治理类的工作(例如熔断路由降级等)无需改造,建议使用service mesh,Istio会主动完成灰度熔断降低流控等,k8s平台默认会收集容器应用的输出日志。
--> 容器化部署,运维人员负责维护基础的容器镜像和标准dockerfile模板,开发人员在此基础上完成业务dockerfile的编写(如果能做到标准化,开发是可以不需要写dockerfile了)。
应用部署模式抽象
开发人员是很难理解k8s的各类概念(pod deployment statefulset service configmap secret pv等),需要运维人员对k8s 声明式API通过服务编排的模式抽象形成标准的容器化部署模式(例如ingress+application statefulset pod部署应用jar包+service+redis+service+mysql主备的整体解决方案部署模式,见下图),业务只需要选择不同的部署模式即可。
部署和状态保持
在DevOps平台上选择容器部署模式、录入git url或修改dockerfile(包括例如数据库初始化工作),自动完成持续集成、测试和生产部署,K8s会负责整个应用集群的状态保持。
当然云原生技术一直在发展,可以看到的还有如Knative等新技术值得持续关注,最终都是为了支撑企业业务稳定和快速发展。
最后还是想说说运维,经过上面的工作,运维人员现在已经基本彻底摆脱了日复一日重复上线变更的工作,可以把精力放到关注服务器、中间件、K8s平台、数据库和其他PaaS组件的监控告警处置、AIops和日常巡检,避免出现类似于数据库慢查询、消息队列堵塞、丢包等问题;经常做一下演练和生产环境压测工作;根据业务需求扩展K8s部署模式;进行上面提到的相关PaaS平台和工具的持续优化;将更多精力投入到运维数字化运营,逐步形成大数据运营体系。回头看看SRE是不是也就是水到渠成?
以上是关于云原生落地思考实践的主要内容,如果未能解决你的问题,请参考以下文章