如何用好MySQL索引
Posted M-Anonymous
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用好MySQL索引相关的知识,希望对你有一定的参考价值。
在了解mysql索引之前,我们先过一遍磁盘和操作系统:手把手教你了解电脑磁盘的结构
一、磁盘的结构
Ⅰ、盘片
一个磁盘(如一个 1T 的机械硬盘)由多个盘片(如下图中的 0 号盘片)叠加而成。
盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据。因为正反两面都可涂上磁性物质,故一个盘片可能会有两个盘面。
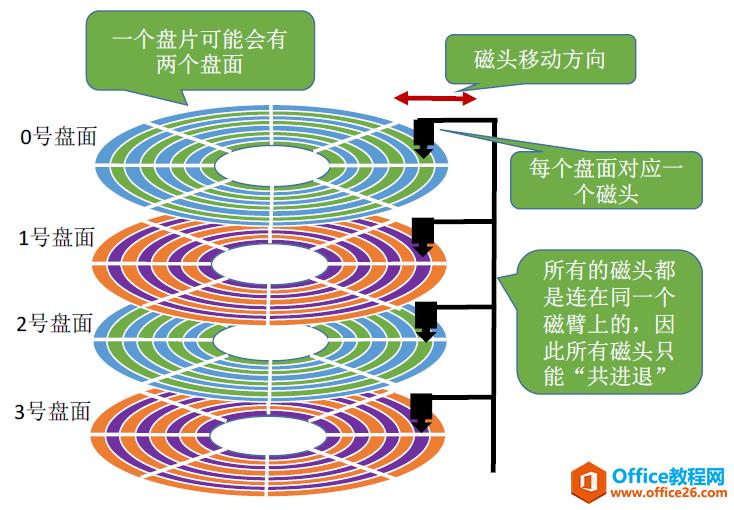
Ⅱ、磁道、扇区
每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区。如下图:
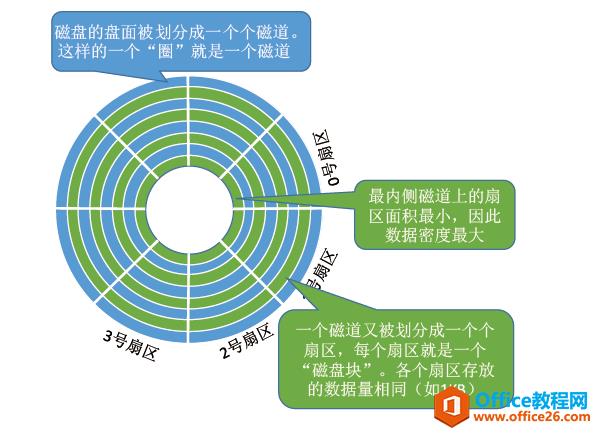
Ⅲ、柱面
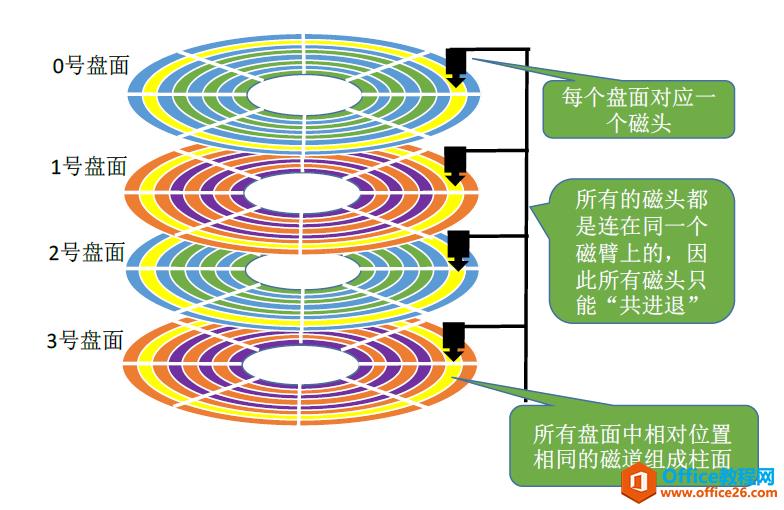
Ⅳ、磁盘的物理地址
由上,可用(柱面号,盘面号,扇区号)来定位任意一个“磁盘块”(也就是物理块)。
可根据该地址读取一个“块”,操作如下:
① 根据“柱面号”移动磁臂,让磁头指向指定柱面;
② 激活指定盘面对应的磁头;
③ 磁盘旋转的过程中,指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读/写。
二、页面、页表、逻辑块
逻辑块:操作系统中的概念,指的是物理块,由多个相邻的扇区组成。(通常块大小为4KB,扇区大小512Byte)
页表:页面到逻辑块之间的映射,一对一的关系。
页面:和逻辑块一一对应。
三、存储
计算机系统利用各种技术来提供存储能力。一个计算机系统的主存通常由硅存储芯片组成。
这种技术每位的存储代价一般要比磁存储技术高不止一个数量级。
尽管磁盘比主存便宜并且具有更多容量,但是它比主存要慢五个数量级。
为了摊还机械移动所花费的等待时间,磁盘会一次存储多个数据项而不是一个。
信息被分为一系列相等大小的在柱面内连续出现的位页面。
由于要处理的数据量非常大,以至于所有数据无法一次装入主存,所以就出现了页面置换算法。
我们使用需要读出或写入磁盘的信息的页数来衡量磁盘存储次数。
四、MySQL的数据结构
众所周知,MySQL采用的是B+树的数据结构,在介绍B+树数据结构之前,我们先来认识一下B树:
B树是为磁盘或其他直接存储的辅助存储而设计的一种平衡搜索树。
它类似于红黑树,就是每棵含有n个节点的B树高度为O(lgn)。
因此,我们也可以使用B树在时间O(lgn)内完成一些动态集合的操作。
由于在大多数系统中,一个B树算法的运行时间主要由它所执行的磁盘读和磁盘写操作的次数决定,
所以我们希望这些操作能够读或者写尽可能多的信息,这样就会减少操作次数。
因此,一个B树节点通常和一个完整磁盘页一样大,并且磁盘页的大小限制了一个B树节点可以含有的孩子个数。
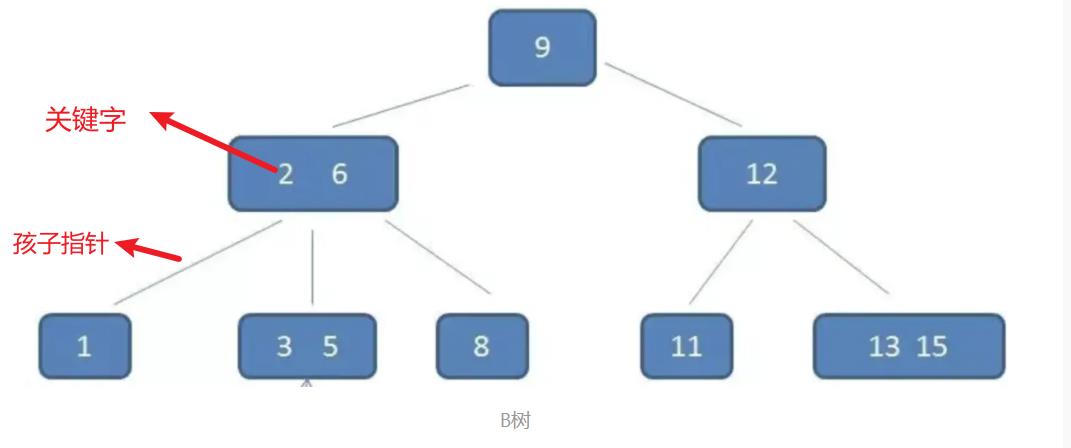
现在我们来了解一下B树的性质,一颗B树T是具有以下性质的有根树(根为T.root):
1、每个节点x有下面属性:
- x.n,当前存储在节点x中的关键字个数
- x.n个关键字本身x.key1,x.key2,...,x.keyn,以非降序存放,使得x.key1 <= x.key2 <= ... <= x.keyn。
- x.leaf,一个布尔值,如果x是叶节点,则为TRUE;如果x是内部节点,则为FALSE。
2、每个内部节点x还包含x.n+1个指向其孩子的指针x.c1,x.c2,...,x.cn+1。叶节点没有孩子,所以它们ci属性没有定义。
3、关键字x.keyi对存储在各子树中的关键字范围加以分割:如果ki为任意一个存储在以x.ci为根的子树中的关键字,那么:
k1 <= x.key1 <= k2 <= x.key2 <= ... <= x.keyn <= kn
4、每个叶节点具有相同的深度,即树的高度h.
5、每个节点所包含的关键字个数有上界和下界。用一个被称为B树的最小度数的固定整数t>=2来表示这些界:
- 除了根节点以外的每个节点必须至少有t-1个关键字。
- 每个节点至多可包含2t-1个关键字。
B树的高度:
B树上大部分的操作所需的磁盘存取次数与B树的高度是成正比的。
示例:
B+树和B树的区别:
B+树在B树的基础上做了一些改进,明显的有如下几点:
1、B+的内部节点不存储关键字对应的数据了,只存关键字和孩子指针,转而把数据都存在叶子节点中。
2、B+树的叶子节点从左到右使用指针连接起来了,相当于一条有序的单链表。
3、B+树的关键字个数和孩子指针个数相同
现在我们思考一个问题,MySQL使用B+树相比于B树有哪些好处:
很明显由于B+树的内部节点不存储关键字对应的数据,所以每页能存更多的节点。
我们MySQL的InnoDB引擎有自己的最小存储单元(页),默认16KB。
内部节点=关键字+指针
叶子节点=数据行
假如一个指针和关键字合起来是16Byte,每个数据行是1KB的话,那么每页可以有1024个内部节点,16个数据行。
如果是三层B+树的话,那就是1024*1024*16=16777216,大约一千六百七十万条数据,并且只用经过三次IO。
如果你对该算式有疑问,可以这么理解,根节点的树高为0,每个叶子节点存储了16条数据行。
现在假设你用B树的话,每个节点都当作1KB处理,那么每页只能存16个节点,想要存千万条数据的话,那么需要多少次IO呢!
另外,由于B+树的叶子节点从左到右使用指针连接起来了,并且是有序的,所以提高了范围查询的效率。
五、MySQL索引
MySQL索引按照实际使用可以分为如下五种:
主键索引、唯一索引、普通索引、组合索引、全文索引
当日还有另外一种分类,不是聚集索引,就是非聚集索引。
一张表只能有一个聚集索引,通常就是表的主键,其他的都是非聚集索引。
它们之间最明显的区别是什么呢?
使用聚集索引进行查询一定不需要回表查询,但是非聚集索引也不一定会回表查询。
比如说现在有个表student,有如下属性id、name、no,主键是id,no是索引,我们通过id查name就不会回表(再查一次):
select name from student where id = \'123456\'
如果我们通过no来查name:
select name from student where no = \'654321\'
它就会先通过no索引查到对应的student的id,再进行一次查询。
那什么情况下他不会回表查询呢,这里就有个叫做覆盖索引的东西,它属于组合索引。
现在student表的索引是(no,name),我们同样执行上面那句,它就不会回标查询了,这就是覆盖索引。
六、索引失效
这里借鉴池允的MySQL索引失效原理
索引失效我们针对的是联合索引,我们之前有讲到过,在没有遵守最佳左前缀法则或使用like或者比较的情况下索引会失效。
但是到底为什么索引失效了并没有解释。索引失效和innodb引擎的B+树存储方式有关。
我们知道单索引的B+树是这样的:
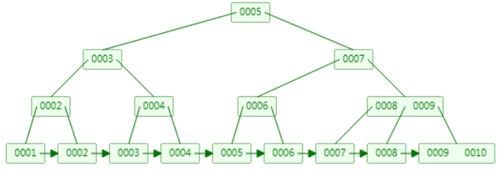
联合索引的B+树也相差不多,因为联合所有有多个字段,下面的图以两个字段为例子:
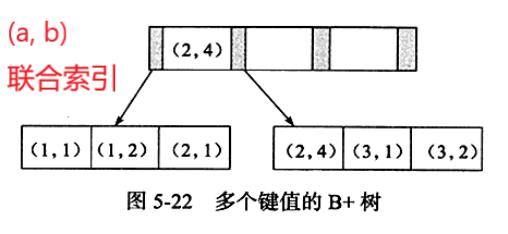
我们现在分析这个构建出来的树
当我们只分析a时,会发现a是有序的,1,1,2,2,3,3 当我们只分析b时,会发现b是无序的,1,2,1,4,1,2 但是如果我们先根据a排序,再来看b,就会发现在a确定的情况b其实也是有序的。 这个就是我们联合索引命中的原理。即a本身有序,在a确定的情况下,b又是有序的,所以就相当于都是有序的
Ⅰ、最左前缀法则:
根据上图我们就可以理解为什么在我们没有遵守最佳左前缀法则的时候无法命中索引。看下面的例子:
select * from test where a=1 and b=2; -- 上述语句是直接命中索引的,首先找a,a是有序的,在确定了a之后找b,在a确定后b也是有序的。 select * from test where b=2; -- 上述语句未命中索引,此时在构建的树中,b是无序的,无法使用二分查找。mysql找无序的数据就是全表扫描。
Ⅱ、范围查找右边失效问题:
其实和上面相同,当你使用了范围查找,能够锁定部分的a值,但是去除掉了这些a之后,还有许多其他的a值绑定的b值依然是无序的。
select * from test where a>1 and b=2;
要找到一个b有序的前提是缺点a的值,范围查找中大于a的值可能是一个,也可能是一百万个。
Ⅲ、like索引失效问题
like一般要配合百分号,一般是查字符类型的。在mysql里字符会按照自己的算法排好,当然也是从小到大,如字母就是用ascii码表排序。
a%代表找以a开头的所有,a叫前缀 %a%代表任意包含a的值,a叫中缀 %a代表找以a结尾的所有,a叫后缀
根据我们之前是结论,要命中索引必须要确定a的值,那么只有a%是符合的,因为后两种都无法确定前面的值。
Ⅳ、数据类型隐式转换索引失效问题
Ⅴ、索引字段使用表达式计算
Ⅵ、索引字段使用了函数
六、如何知道有没有走索引呢?
explain
以上是关于如何用好MySQL索引的主要内容,如果未能解决你的问题,请参考以下文章