第一次个人编程作业
Posted YahAHaCH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次个人编程作业相关的知识,希望对你有一定的参考价值。
https://github.com/YahAHaCH/061900309
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 300 | 480 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 30 | 15 |
| · Design Review | · 设计复审 | 5 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 45 |
| · Coding | · 具体编码 | 300 | 600 |
| · Code Review | · 代码复审 | 10 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 855 | 1345 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。
-
3.1.1 需求分析
作业需求在于在给定敏感词和待检测文本的情形下,扫描文本中的敏感词并输出。其本质是一个多模式模糊字符串匹配问题,而最显然的解决办法即是同时使用正则表达式匹配算法(DFA)和多模式精准匹配算法(AC自动机),但针对此项目仍有可优化的余地。
-
3.1.2类及函数设计
- Trie类,对敏感词文本生成Trie树(字典树),并跑出Fail数组,完成AC自动机的功能。
- Word类,存储敏感词文本,并生成其各种变形,如拆字变形,繁体变形,谐音变形等。
- expansion函数,对汉字文本,通过调库的方式,得到其繁体、拆偏旁、拼音等信息。
- Ans类,存储答案对应的敏感词编号,在文本中的行号,已经在文本中出现的开始位置和结束位置方便输出。
-
3.1.3 关键实现
首先实现一个中文AC自动机完成多模式精准字符串匹配,而模糊匹配的部分,首先是在敏感词间插入特殊字符,或许是由于测试需要的特殊性,插入的字符都是除了英文汉字以外的特殊字符,可以事先提取,输出答案时还原,这样一来避免了DFA算法,方便实现,也提高了运行效率。而在部首拆分,拼音谐音替换等方面,以谐音替换为例,调用库得到所有汉字的拼音,将整份文本的中文以及敏感词都替换成其拼音,也进行一遍匹配,即可解决谐音替换问题。
(3.2)计算模块接口部分的性能改进。
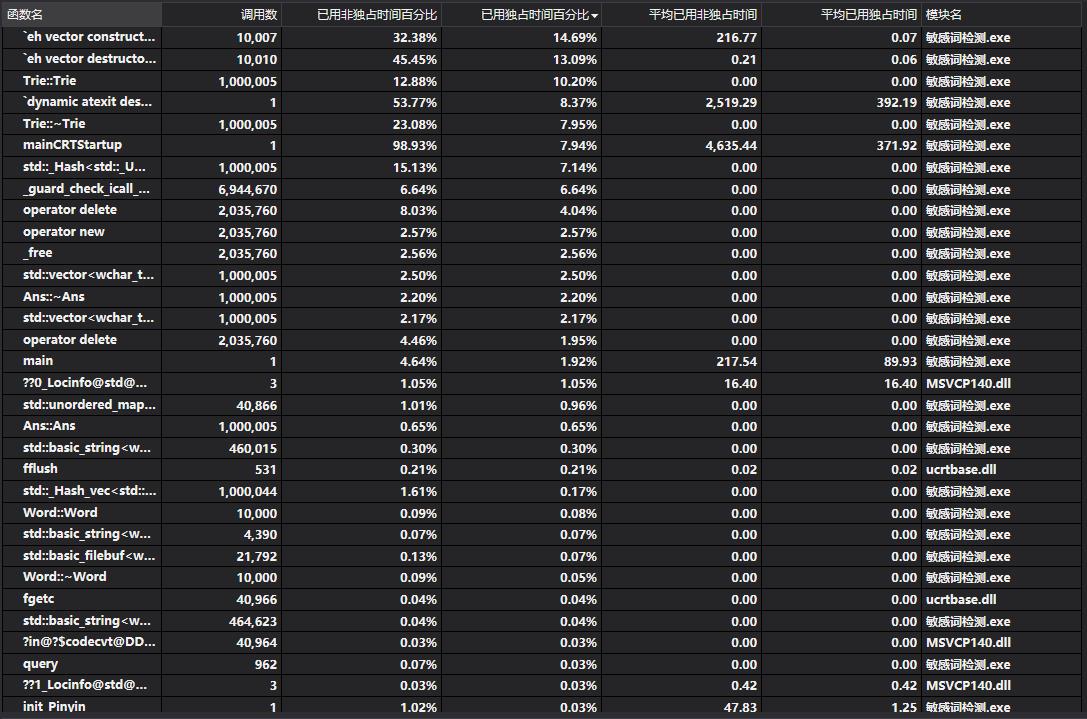
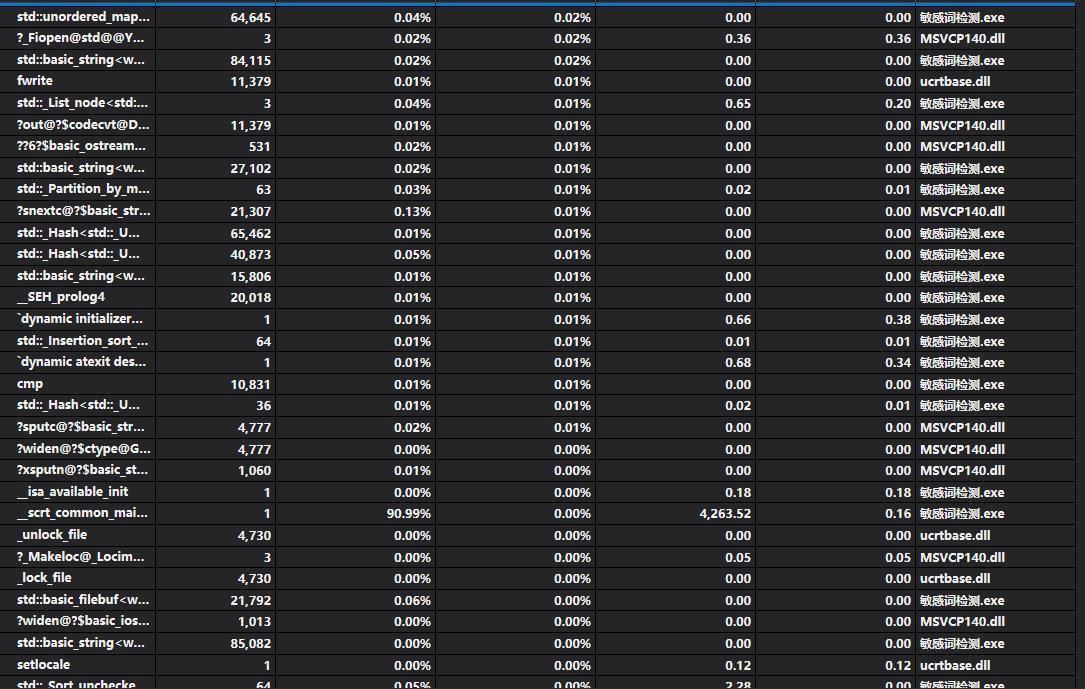

点击查看代码
class Trie {
public:
int Fail, id, len;
unordered_map<wchar_t, int> Child;
vector<wchar_t> v;
};
void insert(wstring &str,int ID)
{
int now = root, i,len=str.length();
wchar_t x;
for (i = 0; str[i]; ++i) {
x = str[i];
if (x >= 65 && x <= 90)x += 32;
if (!t[now].Child.count(x)) {
t[now].Child[x] = ++tot;
t[now].v.pb(x);
}
now = t[now].Child[x];
}
t[now].len = i;
t[now].id = ID;
}
void getFail()
{
queue<int> q;
for (auto x : t[0].v) {
t[t[0].Child[x]].Fail = 0;
q.push(t[0].Child[x]);
}
int now, fail;
while (!q.empty()) {
now = q.front();
q.pop();
fail = t[now].Fail;
for (auto x : t[now].v) {
t[t[now].Child[x]].Fail = t[fail].Child[x];
q.push(t[now].Child[x]);
}
for (auto x : t[fail].v)
if (t[now].Child.count(x))
t[now].Child[x] = t[fail].Child[x];
}
}
- 从上面分析的表格可以看到,调用最多最耗时的是Trie类及其相关函数,是因为此项目的核心部分在于AC自动机,query函数的运行次数直接取决于文本量的大小,而Trie树的规模也取决于敏感词文本及其延伸的文字量,而其复杂度瓶颈在于Trie树实现时带来的字符集大小常数,考虑将Trie树结点的儿子结点信息存储在一个C++ STL库中自带的unordered_map类里(本质是实现一个Hash表,提升运行效率)
(3.3)计算模块部分单元测试展示。
- getPinyin模块测试,测试是否能获得正确的汉字拼音
点击查看代码
int main(int argc, char* argv[])
{
init_Pinyin();
Word w;
w.s[0] = L"碳";
w.getPinyin();
assert(L"tan" == w.s[1]);
w.s[0] = L"烤";
w.getPinyin();
assert(L"kao" == w.s[1]);
w.s[0] = L"熊";
w.getPinyin();
assert(L"xiong" == w.s[1]);
w.s[0] = L"卡";
w.getPinyin();
assert(L"ka" == w.s[1]);
cout << "YEAH";
}
- getChaizi模块测试,测试是否能获得正确的拆偏旁结果
点击查看代码
int main(int argc, char* argv[])
{
init_Chaizi();
Word w;
w.s[0] = L"碳";
w.getChaizi();
assert(L"石炭" == w.s[3]);
w.s[0] = L"烤";
w.getChaizi();
assert(L"火考" == w.s[3]);
cout << "YEAH";
}
-
运行样例文件结果及参考答案比较

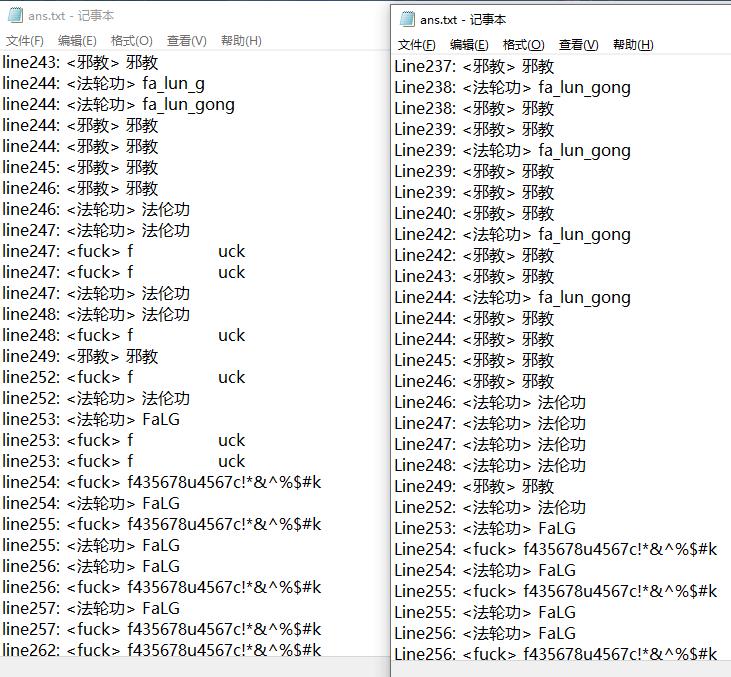
比较两份文件发现在文本的247行等位置,出现了样例中本应被检测出但是测试组没有给到的敏感词,由此可见代码的检测性能还是比较优秀,但是也出现了一些多的敏感词,发现原因其实是例如若敏感词为碳烤,而文本中出现了tankao,由于我的代码将taokao(即两个字都用拼音替换)和tank(第二个字用拼音首字母替换)加入了敏感词典,产生了多余的结果,解决这一问题需要的工程量和程序耗时巨大,而这本身也不是一个代码的缺陷,考虑再三于是放弃更改。
(3.4)计算模块部分异常处理说明。
- 命令行参数给定地址不存在导致IO异常
点击查看代码
int main(int argc, char* argv[])
{
wifstream r(argv[1], ios::in);
r.imbue((locale)"chs");
assert(r);
wofstream w(argc[3]);
w.imbue((locale)"chs");
assert(w);
}
三、心得
- 本次作业对算法的要求较为复杂和严苛,简单的做出来并不能,但想要优秀的运行效率,就需要考虑更适合更高级的算法,另一方面题面描述不够严谨,给coding造成了许多困扰。C++对宽字符的处理也很让人头疼,原先所说不能导入文件使得我将所有的特殊库写在代码里导致了代码冗长。但是严格的算法要求和复杂的Case确实让人得到锻炼,我进一步了解了C++宽字符的使用和文件输入输出的使用,对AC自动机的理解也深刻了不少(搞ACM的时候其实一知半解,现在通过这个项目算是完全搞懂了),也锻炼了自己的code能力。
以上是关于第一次个人编程作业的主要内容,如果未能解决你的问题,请参考以下文章