以云原生技术管理边缘原生应用
Posted K8S中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了以云原生技术管理边缘原生应用相关的知识,希望对你有一定的参考价值。
云计算的发展自2015年始已经进入云原生时代,以Kubernetes为代表的云原生平台更是横扫一切,已然成为云原生技术的标准之一。而边缘计算一脉更是受着云原生技术的加持,在2018年又轰轰烈烈地回到了人们的视野,至今未衰。随着边缘计算的发展,越来越多的人从学术界和产业界更提出了“边缘原生”的概念。
作者 | 华为云原生团队
在问题发展的过程中出现了变化,对应出现的技术又被冠以相同或不同的名字让事情变得更加复杂。看似二元对立的云原生和边缘原生,便如佛教临济宗门的四料简所说,“有时夺人不夺境,有时夺境不夺人,有时人境俱夺,有时人境俱不夺。”这到是像极了《state of edge 2020》这个报告中对未来的预测 ----边缘并不是绝对的事物,而是相对的位置。未来云中心和边缘之间的距离将会越来越短,界限越来越模糊、难以划分。未来不是云和边缘,而是连成一片的边缘云。
而技术的发展更如中国禅门沩仰宗禅师们爱讲的“啐啄同时”,技术本身和技术所解决的问题就好比鸡蛋里要孵出来的小鸡和外面的母鸡,小鸡要从蛋壳中出来,在里面啄,母鸡在外面啄。这个过程就很关键,啄早了不行,小鸡还没有成熟;啄迟了也不行,小鸡出来不了就会闷死在蛋壳里。
华为云的IEF(智能边缘平台)作为国内公有云厂商边缘计算的先行者和领先者,笔者有幸产品一起经历了过去两年边缘计算产业的发展,也在其间深度支撑过大大小小数十个边缘计算项目。本文试图以笔者本人的视角分析当前云原生技术在边缘计算中的应用和边缘原生的特点及应对技术,以图“啐啄同时”,表达边缘计算的技术发展之我见。
边缘计算已经进入云原生时代
记得在2018年的时候,在各种关于边缘计算的会议上,还能听到一种关于“边缘计算和雾计算异同点”的讨论。但是自2019年起,人们越来越不会纠结在这一点上。正如中国信息通信研究院在《云计算与边缘计算协同九大应用场景(2019年)》中指出的 “云计算和边缘计算并不是对立的。边缘计算是云计算向终端和用户侧延伸形成的新解决方案。可以说,边缘计算本身就是云计算概念的延伸,即便是赋予其独立的概念,也无法做到与云计算切割开,二者本就是相依而生、协同运作的。”。边缘计算其本身并不是一个孤立的存在,而是与云计算相依相生的。而雾计算,则就是一朵孤零零飘在地上的云了。
Linux基金会LF Edge理事会成员Roman Shaposhnik和他的初创公司Zededa自2017年创立之日起就一直在推广Cloud Native Edge的概念。Roman认为,边缘计算进入云原生时代的核心驱动力是当今的边缘计算需要云计算那样的业务敏捷化能力。并且分布式和业务的广泛交互已经成为边缘计算系统的基本特性。这种特点像极了前几年起在云上发生的那些事。所以云计算的技术也正在被大量地应用于边缘计算中。在《Cloud-Native Edge for Connected Operations》这篇报告中,有一个很精彩的表格,对比了传统嵌入式软件和云原生的边缘计算在整个生命周期的各个环节是如何做的:
上表由我在原表的基础上进行了稍许加工,增加了一列“对比”,展示了云原生边缘计算的优势。将其中的形容词总结起来,我们不难得到这些关键词:降本、增效、更敏捷更强大更安全。
云原生技术在边缘计算中的应用
前文提到,边缘计算作为一个相对概念,其主要的价值体现都在“边云协同”。在边缘计算产业联盟和工业互联网产业联盟共同发布的《边缘计算与云计算协同白皮书(2018)》中,边云协同被总结为六大方面:
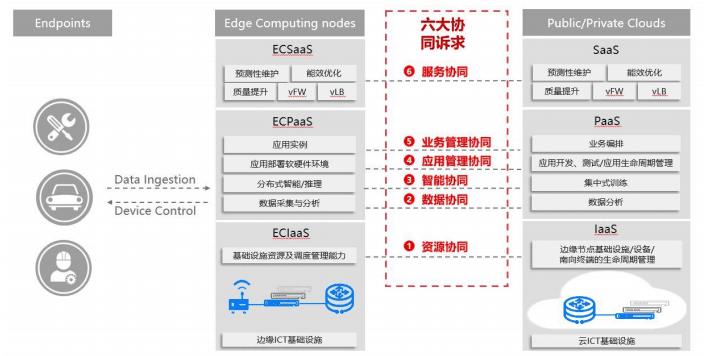
同时,作为云原生基金会中的当家花旦和当今技术界最大网红,Kubernetes在一定程度上成为了云原生技术的集大成者。围绕Kubernetes已经构成了如今最大的云原生技术生态圈。IEF和KubeEdge正是基于Kubernetes技术生态构建起来的。基本上来说,经过两年多的发展,我们认为基于Kubernetes和其生态构建边缘计算管理平台确实是一个明智的选择,本文前面所说的一些云原生技术可以直接运用在边缘计算中。
然而需要注意的是,这并不是说完全把Kubernetes跑到边缘就可以100%满足边缘计算的要求了。这一点我会在本文后面的部分展开详细的探讨。在本章节中我们就先来“夺人不夺境”,结合在KubeEdge中的开源实现,介绍上面这六大协同诉求是如何受益于Kubernetes和云原生技术的。
资源协同
边缘计算提供云-边-端的资源协同管理,在云端统一管理边-端的节点和设备。在资源协同的诉求中,需要考虑对节点、设备进行功能抽象,在云、边、端之间通过各种协议完成数据接入,在云端统一管理和运维。
常见的做法是对边缘及其连接的设备进行抽象建模,提供统一的“物模型”。将设备物理属性映射到数码的世界中,通过物模型去描述的设备的属性,抽象出不同设备之间的共性,对上层应用屏蔽底层设备细节,提升产品开发速度增加组件复用程度。例如,不同品牌的温度传感器,它们之间的区别可能是连接方式的不同,但是两个设备对应到物模型中就只是温度这个属性。我们只需要为两者进行差异性开发,实现不同的连接协仪驱动。
对于边缘节点,可以直接映射为Kubernetes的标准Node,而对边缘侧连接的设备,则需要通过Kubernetes的CRD进行扩充,在KubeEdge中,实现自己的DeviceTwin。
这些模型的共通点都是将设备的物理属性和底层协议与上层应用的访问接口解耦开,以便让不同的开发人员聚焦在模型的不同层面,并且通过模型将底层设备对接程序和上层应用解耦开。
我们对该模型的实现参考自WOT模型,在此基础上增加了以下两个部分:
设备连接底层协议的描述以及与上层模型的映射关系
设备与边缘节点的映射关系
具体模型的定义如下所示:
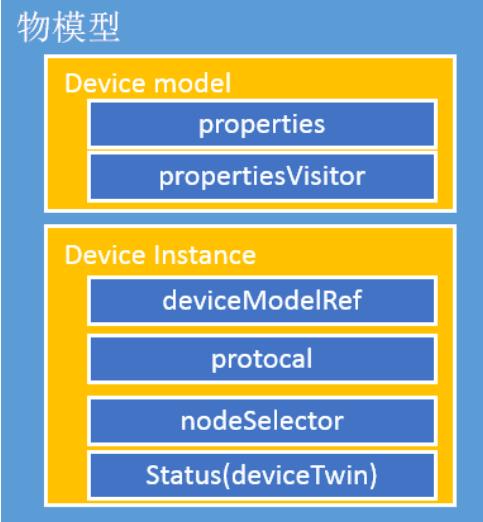
物模型中定义了两个类型Device model和device instance:
Device Model 定义设备具体模型 a. Properties定义的是设备的属性,如温度传感器的温度 b. propertyVisitor定义的设备属性的访问者,对应具体的底层协议访问参数。
Device Instance 定义一个设备的实例
a. deviceModelRef是对已定义好的设备模型的引用,通过deviceModelRef可以找到对应 的设备模型;
b. protocal通过设备协议的定义连接设备。如下就是定义了modbus-rtu协议,我们可以通过这个定义去连接对应的设备;
c. nodeSelector指定设备所关联的节点;
d. Status定义了设备传输的报文;
具体的实现可以在KubeEdge社区中参考Modbus Mapper,了解如何对边缘资源进行建模,表示一个Modbus设备的接入和数据交换。
应用/业务管理协同
作为云原生应用编排部署事实标准的Kubernetes,在多年的发展中已经积累和沉淀了一些对云原生应用的编排部署模型。而KubeEdge通过边云协同的方式,将这些编排部署能力延伸到边侧,支持边缘侧日益复杂的业务和高可用性的要求。
下图为Kubernetes的整体模型图,在下图中可以表现大多数的云原生编排部署能力:
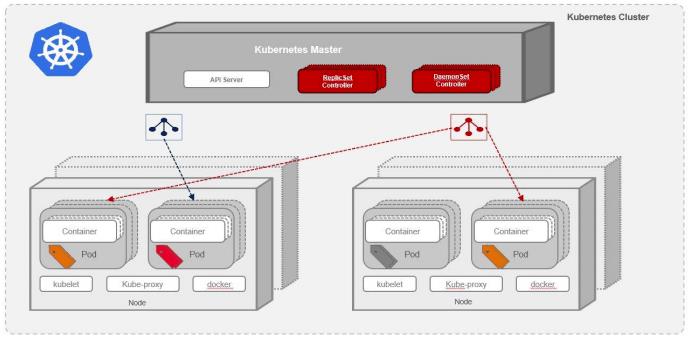
如下是对K8S中核心部署对象的解释:

在上述基本部署元素的情况下,通过对这些元素的组合和使用部署的亲和性规则,还可以实现一些更复杂的部署模型,例如:
双机热备 在一些存储持久化的场景中,例如mysql双机热备的场景,利用stafulset的机制,在应用重新调度后mysql应用还能被调度到原有的节点之上,保证访问同样的存储。
多机多活互备 可以利用replicaset创建多个副本,replicaset可以维持设定副本数的应用同时运行。
有关联的应用同节点部署以提升应用间交互效率 一个Pod里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如 namespace,cgroups或者其他的隔离资源。多个容器共享同一个network namespace,由此在一个Pod里的多个容器共享Pod的IP和端口namespace,所以一个Pod内的多个容器之间可以通过localhost来进行通信,所需要注意的是不同容器要注意不要有端口冲突即可。不同的Pod有不同的IP,不同Pod内的多个容器之前通信,不可以使用IPC(如果没有特殊指定的话)通信,通常情况下使用Pod的IP进行通信。一个Pod里的多个容器可以共享存储卷,这个存储卷会被定义为Pod的一部分,并且可以挂载到该Pod里的所有容器的文件系统上。
同一应用的不同实例跨节点部署以提升可用性 利用replicaset和应用部署的反亲和性特性,选择同一应用部署的不同实例分散在不同节点上进行部署。
依据边缘节点的不同属性将应用部署于不同分组中 在很多场景中依据边缘节点的地理位置、设备类型、功能属性、性能等分属于不同的分组,打上不同的标签,在应用部署时利用nodeselector的能力将应用部署在对应label上的边缘节点之上。
定义独立于节点的应用部署以实现满足条件的新边缘节点上线后自动安装应用 在应用部署时,应用是根据节点的label去将应用部署在对应的节点之上,当新的节点上线后,我们可以将其打上同样的label,节点上线之后K8S系统可以立刻将应用自动部署在新上线的边缘节点之上。
在K8S基本的编排(Orchestration)之上,结合CNCF生态中的众多生态项目(例如日趋火热的KNative),可以实现完整的云边协同DevOps。
智能协同
AI能力的发展可谓是近年来边缘计算持续火爆的一大主要推手。边云的智能协同也是目前边缘计算项目中一个非常重要的协同场景。
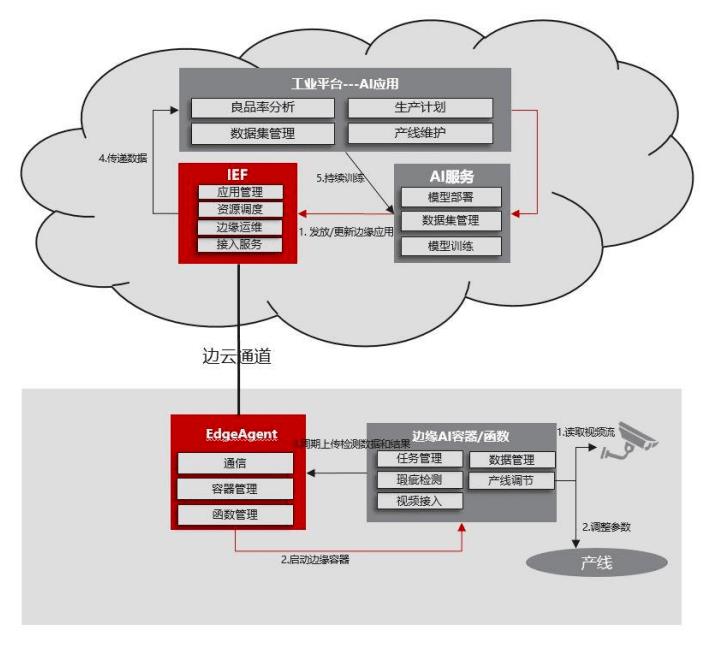
式承载的AI模型的生命周期管理。而Docker本身OverlayFS的方式也让每次有更新时只将变化的部分下发至边缘,保证了边缘文件下载的最小化。
在程序逻辑和模型文件分离的使用方式下,通常会将模型文件通过公有云的OBS服务进行存放,而模型本身的路径和更新信息则可以通过Kubernetes的Secret下发至边缘。部署于边缘容器内的应用程序发现该更新消息后主动从云端拉取更新后的模型。
数据/服务协同
在云原生技术中,微服务是标准的架构模式。整个系统被划分为不同的微服务,分别部署于云端和边缘。微服务之间的交互,已经由数据的"transportation"变为服务之间的"interaction"。
服务之间的协同更像是要求更高的数据协同。因为它在数据的传输之外还增加了服务发现、灰度路由、熔断容错等更偏向业务层的能力。或者说服务协同本身就是建立在数据协同的基础之上的,两者在云原生的微服务架构中缺一不可。
在KubeEdge里,用EdgeMesh特性主要解决了两个问题:
由跨越了边、云而组成的大型分布式系统中的微服务之间互相发现和访问
在微服务互相访问的过程中对访问过程进行治理、控制从而提升大型分布式系统整体的可用性
整个过程如下图所示:
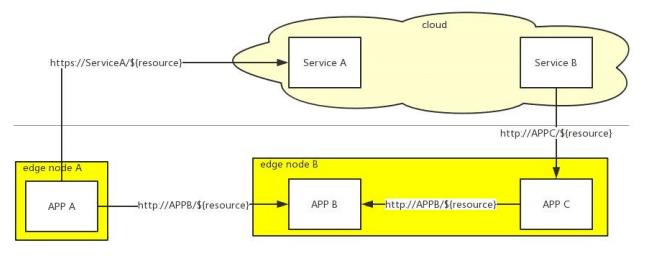
上图中所示的访问方式以7层,HTTP请求为例。整个系统中存在边边互通和边缘互通。EdgeMesh这个特性更像是Kubernetes和Istio的边缘侧实现。其具体实现思路如下:
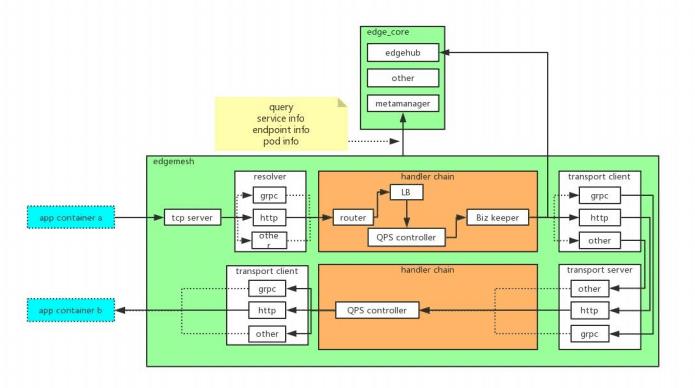
edgemesh工作在tcp server之上(tcp server)
从tcp connection中拿到数据后,猜测并最终确认上层协议(resolvers) edgemesh还会启动多种协议的server,用于接收请求然后根据配置实现服务端QPS(transport server)
通过socket方式调用metamanager接口查询Service/Endpoint/Pod等元数据(metamanager的元数据由云上的edgecontroller watch k8s master后同步),根据配置的路由/负载均衡/QPS/熔断等策略处理请求
通过对应请求的客户端转发请求到用户边缘应用
边缘原生应用
发表在2019年IEEE International Conference on Edge Computing (EDGE)的论文《The Seminal Role of Edge-Native Applications》中,作者明确了"edge-native applications"必然会具备的四大特点:
可扩展带宽
低时延负载
本地隐私的保护
WAN连接失败的弹性;
而Eclipse基金会更在2019年12月10日正式宣布创立Edge Native Working Group,致力于提供产品级的开源边缘计算项目。相比欧美学术界和产业界对Edge Native概念的热衷,中国则对Cloud Native倾注了全部的热情。
在概念的关注之外,实际上国内在边缘计算领域的应用早就在默默开展起来了。在5G概念火热之前,人们对边缘计算的关注主要在近场边缘。人们关注使用边缘计算技术将智能能力部署于数据发生地附近,让机器产生的数据通过更智慧的处理,产生更大更直接的价值。人们更想用边缘计算技术来解决边缘侧天生物理分散情况下施工、维护的高人力成本,低人效的问题。
基于两年多的边缘计算项目实践,我发现运行于边缘的应用确实展现出了一些与云上应用不同的特点。我们姑且称之为一些“边缘原生”应用之众生相。
对于边缘原生应用的众生相,我们先放下业务层面的差异,而仅仅拿出共性的特点来一一进行分析。本文会从“应用和应用管理”、“连接和故障模式”、“施工和运维”三个角度来进行介绍。
应用和应用管理
宠物还是牲口 在云计算的早期阶段,就有一种以云计算的出现颠覆当时从业人员认知的 Pets VS Cattle 的说法,说的是在云计算时代,取之于“宠物”,IT人员可以利用云平台,以对待“牲口”的方式来管理和运维他们的系统。这种理念在一定程度上深刻地影响了IT系统的管理思路。无状态应用、快速水平扩展、不可变基础设施等一定程度上已经成为了现代大规模系统的标配。
在标准云计算领域,“牲口”的定义基于每个个体的对等性,饲养人员不会给每个个体起不同的名字,每个个体都是可以互相取代的。而在边缘计算领域,可能这个认知又需要重新来思考。因为在边缘侧,每个节点都有其物理属性,每个应用都有其所连接的特定设备。结合云计算的理念,用户可以在某些场景中采取一定程度的高可用性措施,例如增加冗余设备、应用多实例部署来应对单点故障,但是其边缘侧的资源有其拥有成本和管理成本的限制,不可能像云上一样以池化的方式无限扩充。所以完全没有办法像牲口一样对待他们部署下去的每个边缘应用。而因为具备一定的高可用性措施,也不会像宠物一样对待他们。这种情况可能更像对于流浪动物的喂养 ---- 我们小区喂养流浪猫的阿姨可以在小区十多只猫中准确地叫出中每只流浪猫的名字,她固定了开饭的时间集体喂养他们,给他们用纸箱子做一些简易猫窝。而在每次开饭的时候不见的喵星人,阿姨总会认为他们可能已经被好心人领养走了而不会伤心欲绝。
简单化轻量化 应用的简单化轻量化,目的是对边缘的要求做到最低。边缘侧的部署通常受限于施工环境的要求,对计算设备都有比较严格的要求。例如在矿井中的部署,必须满足国家规定的防爆要求。边缘网络也不能像云端网络一样在速度和稳定性上得到保障。另外对边缘应用进行大规模部署,设备的成本通常是整个解决方案中需重点考虑的部分。
这几年各种SOC、硬件加速芯片的层出不穷也让方案设计者有了更多的选择。很有可能在开发阶段使用了x86,而在生产阶段却因种种限制使用了基于ARM架构的mx6ul。的所以想快速,甚至是顺利地部署边缘应用,就要去掉对边缘侧运行环境的一切假设,将应用本身做到足够简单(不是业务逻辑的简单,而是部署要求运行依赖的简单)。这样才能顺利地部署、运行和更新。这也是为什么近两年容器技术在边缘侧得到了广泛应用。应用以容器为单位进行部署,把所有运行时依赖都打入容器中,将对外面运行环境的依赖降到了最低。解耦了软件开发和硬件部署环境的选型,大大提高了方案整体交付的时间。
半状态 边缘应用的作用通常是数据汇聚类或计算类。他们是整个业务处理中的一个中间节点,后续的工作或者交给云上,或者返回给用户,不会长时间把工作的中间状态进行保存。在这个过程中的数据和应用的状态,会在本地有个临时的保存,然后就被转交给云上或其他地方的应用。因此这类应用更多地是半状态应用。
0信任 边缘计算的发展让传统中心云、私有云、企业机房的边界不断瓦解,广泛分布在各个地方的服务、设备、数据通过各种网络管道进行交互和流转,已经无法依赖防火墙实现保护。
0信任安全的核心思想是:默认情况下不应该信任网络内部和外部的任何人/设备/系统,需要基于认证和授权重构访问控制的信任基础,其本质是以身份为中心进行动态访问控制。在“所有网络流量都不可信”的基础上,“零信任模型”的还有三个基本理念:验证并保护所有来源,限制并严格执行访问控制,检查并记录所有网络流量的日志。在包含边缘部分的整体系统中,一定要保持“丢车保帅”的觉悟。做好系统的安全隔离,因为整个边缘部分在机房之外,必须时刻做好整个边缘都被侵入的准备并在这种假设的基础上来构建云上的系统。
通常需要以节点为单位进行调度 因为边缘侧的节点具备了“地域”这个物理属性,所以每一个都是独一无二的。如果我们到现场就会对这一点的体会更加深刻。我们在管理界面上看到的一个编号和一条记录,可能都是施工人员用一天时间爬到高塔之上才能安装完成。因此在对这些边缘节点进行管理的时候,除了需要具备大规模批量操作能力的能力之外,还需要能够以单个节点为单位对其之上的应用进行调整。
例如我们在部署一个园区中位于东、南、西、北四个大门处的视频分析人脸识别应用时,因为这种视频分析应用的逻辑都是通过相同的端口获取视频数据,做AI分析后使用相同的逻辑通过相同的方式向用户进行反馈。我们可能很自然地想到把这四个节点打成相同的tag,然后在Kubernetes中用一个Deployment部署一个应用的四个实例到四个节点上去。但是忽略了物理唯一性的问题通常会导致后面的灾难。过了一段时间后,这个视频分析应用推出了另外一个可以同时进行车辆识别的版本,而在我们之前部署的那个小区,只有东、西两个门是可以走车的,这个新版应用只能升级部署在东西两个门才可以。在这种情况下,基于我们之前的Deployment模型,将四个节点一视同仁的方式就很难在尽量少影响业务的情况下做出调整。
连接和故障模式
短时间离线 我们谈的边缘计算本身就是一个相对的概念,有了中心才会有边缘。所以我们现在说边缘计算并不等同于本地计算。能被称之为边缘计算的业务一定是与中心云有协同的。而边缘计算业务的特点会导致它的短时间离线是正常情况。有可能因为环境问题导致的离线,例如网络故障、现场断电。也有可能是业务本身导致的短时间离线,例如潜水器入水,无人机在高空作业等。所以需要避免因为离线而导致该节点在调度平台中被认为是故障从而进行驱逐和重调度。
大面积同时上下线 边缘节点具备了空间的物理属性,因此在具体施工的时候,很有可能是一个区域内所有的边缘节点都通过一个统一的出口对接到云上。所以在这个出口出现问题的时候,很容易出现这个区域内所有边缘节点同时下线,而当问题解决后,所有的边缘节点又会同时上线。例如在笔者接触的某部署于专网内的大型边缘项目时,省内数千边缘节点先接入省内网,然后再通过统一的出口接入到部级网络,云上的业务就在部级网络中部署,边缘节点的统一管理服务也在部级网络中。省部网络在进行维护、调整的时候,接入省级网络的数千边缘节点会同时上下线。这种具备明显连接波峰的情况在云端发生的概率不大,而在边缘侧,则可能是频繁发生的事情。所以在进行云上系统和边缘管理平台的设计时,对于大量节点的同时接入和下线,要做好相应的处理。
网络情况复杂、有分层 边缘的网络情况通常是根据项目的情况而不同。在我们遇到的边缘项目中,似乎每个项目的边缘侧网络都各有各的特点。主要的差异点之一在于边缘侧接入云端的接入方式。因为不同的行业对于安全的要求和技术条件各有不同,所以也呈现出在不同的边缘现场,网络接入方式的差异化非常大。例如在一些政务网,节点需通过DMZ区的代理连接才能接入云平台,而且这个连接也不是能够7*24小时保证的。
在交通专网中,网络以省为单位汇集,然后再统一接入上层网络。而在公安系统的网络中,网闸又是一个不可忽视的存在。一个典型的水务领域的边缘节点,则通常会通过4G无线网络接入。因此一个好的边缘计算方案,应该是可以适应这多种不同的网络情况。另外一个比较大的差异在于边云连接的带宽。很多情况下,网络要经过多层代理才能连上云端,连接速度根本不能得到保证。而且边缘侧通常量会很大,我们在计算网络带宽占用时,常常忽略这个因素。在我们的一个项目中,发生的情况是边缘节点之间的连接带宽非常大,所以部署于边缘节点的不同微服务之间的交互完全可以得到满足。而边云连接的带宽相对较小。而这里就发生了因为大量边缘节点连接将边云通道完全堵死的情况。
施工和运维
0-Touch 在所有真正实践过的边缘计算项目中,没有哪一个没有经历过边缘侧实施的痛苦。只要真正实践过边缘计算项目,就会体会到对0-touch的热切期待。从云往下走,越往下走,垂直整合的意思越明确,相反从边往云上走,越往上走水平解耦的色彩就越浓烈。
人们于边缘系统的期待,就好像我们对电视、洗衣机、冰箱的期待 --- 上电就能用,想要的功能一键到达,多余的事情不要做; 出了问题不需要我做任何事情,我也做不了任何事情,直接找厂家售后就完事。以上,是所有边缘项目中,人们对于边缘系统的期待。边缘系统它本身跟私有云、本地系统都是完全不一样的。在这个原则的前提下,让我感到疑惑的就是当下很多自称边缘计算管理系统的软件,还需要考虑边缘侧的管理节点部署,还需要考虑这些管理节点的高可用性保证。这就好像我们家里的电视跟洗衣机旁边还放着一个什么事也不做的盒子,我们被告知这个盒子是为了保证家里其他家电的正常工作。这个盒子没有任何按钮,而是有一个键盘。我们需要通过日志去确定这个盒子的工作情况并且通过命令去维持它的运转。这种系统所构成的边缘大概不是我所理解的边缘。
施工成本巨大 注意,在这里我用的是“施工”二字,而不是部署。两者本身的差别巨大,因为边缘计算设备的安装部署本身可能就是一个独立的工程。且不说那些通过火箭卫星发射至其他星球的装置,就是我们身边的设备,在通常情况下,每个单独的设备都需要经过供电设计和施工、网络组网和施工、防水防雷设计和施工、通风散热的处理等等等等。在一个设备被集中放置的数据机房中,所有这些成本会被机房中的大量设备平摊。而在边缘侧这种广泛分布的场景中,每个边缘设备都需要付出相同的成本。在我们经历的一个边缘项目中,设备被安置于路边的灯杆之上。每次设备死机对于系统维护人员来说就是噩梦 ---- 他需要坐车到这个灯杆下面,爬上去,按一下重启键。
施工和维护人员缺乏IT技能 我们不能否认的是,具备IT技能的人相比需要部署在边缘侧的设备相比还是非常缺乏的。而具备IT技能的人也不可能长期驻扎于分散的边缘中的每一个点。大多数情况下,每个边缘设备可能就位于园区的中控室或者是门岗。而其日常的维护人员就是园区里的保安。对于其软件层面的维护只能通过远程的方式进行。
因此,对于边缘计算系统中的边缘侧设备和系统,我们不能假设任何现场的操作。我们需要考虑发货前的预装、大规模的批量管理等等。我们对现场维护人员唯一可以期待的事情就是插上电源,最多再按一下开关。
总结
以上,在本篇文章中,我们介绍了云原生技术在边缘计算领域的发展和一些技术的具体应用。在此基础之上,结合我们在边缘计算项目中的实践,总结了边缘原生应用的一些特殊之处。因为这些特殊之处,认为“只要简单地把Kubernetes搬到边缘部署就可以解决所有的边缘计算问题”这种想法还是too young too simple了。在下篇文章中,我会重点介绍我们在IEF服务和KubeEdge项目中是如何对现有的Kubernetes进行扩展和增强以解决这些边缘计算的特有问题的。
以上是关于以云原生技术管理边缘原生应用的主要内容,如果未能解决你的问题,请参考以下文章
Addon SuperEdge 让原生 K8s 集群可管理边缘应用和节点
KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现