Flink+Clickhouse实时数仓在广投集团的最佳实践
Posted ludongguoa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink+Clickhouse实时数仓在广投集团的最佳实践相关的知识,希望对你有一定的参考价值。
一、业务背景
由于历史原因,大型集团企业往往多个帐套系统共存,包括国内知名ERP厂商浪潮、用友、金蝶、速达所提供的财务系统,集团财务共享中心的财务人员在核对财务凭证数据时经常需要跨多个系统查询且每个系统使用方式不一,同时因为系统累计数据庞大,制单和查询操作经常出现卡顿,工作效率非常低。
数据中台天然就是为了解决数据孤岛和数据口径不一致问题应运而生的,总的来说就是要将原本存在各帐套系统的数据实时接入中台,中台再将不同系统的数据模型进行归一化处理,并且在数据分析平台上提供统一的查询入口。从下面的架构图可以直观地了解。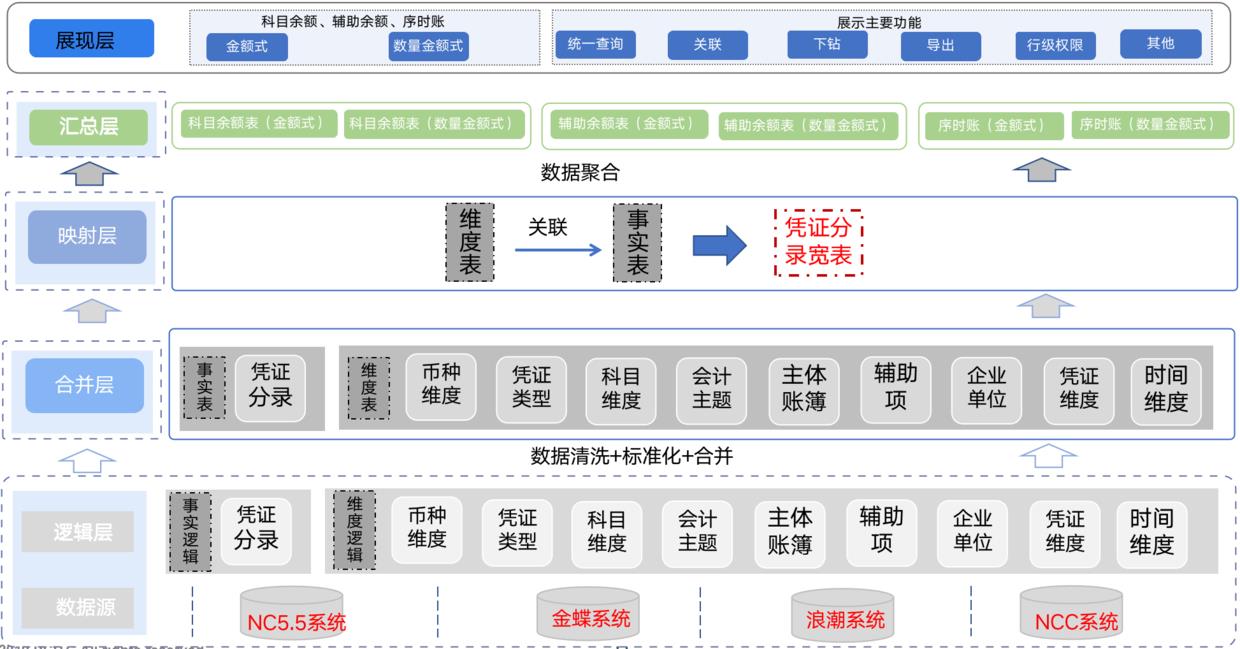
一方面,数据中台提供的数据查询服务需要覆盖原系统的帐套查询功能,这意味着原系统做的任何业务操作(插入分录、删除凭证、废弃凭证、保存等)在数据中台都需要有同步的事务反应,确保中台提供的数据结果与原系统客户端保持严格一致;另一方面,数据分析平台需要提供级联、上卷下钻、多维聚合等附加能力,满足海量数据分析的需求。重点需要考虑以下几个问题:
- 开源的CDC监控产品大都是针对mysql或Postgresql的,然而财务核算系统大多使用Oracel数据库,如何选择一套稳定且满足业务需求(可监控增删改事务操作)的CDC插件或lib库;
- 如何保证端到端的数据一致性,包括维度一致性以及全流程数据一致性;
- 实时流处理过程中数据到达顺序无法预知时,如何保证双流join时数据能及时关联同时不造成数据堵塞;
- 这个需求是典型的集多维分析和事务更新为一体的场景,并且对多维分析的响应时间(毫秒级)以及事务更新效率有极高的要求,所以如何解决HTAP的问题成为一大难题,目前开源社区并没有提供一个能较好处理此问题的解决方案,包括Tidb和Greenplum。
我们一起来看看广投集团实时数仓是如何巧妙解决这些问题的。
二、常见的实时数仓方案
常见的实时数仓架构有三种。
第一种是Lambda架构,是目前主流的一套实时数仓架构,存在离线和实时两条链路。实时部分以消息队列的方式实时增量消费,一般以Flink+Kafka的组合实现,维度表存在关系型数据库或者HBase;离线部分一般采用T+1周期调度分析历史存量数据,每天凌晨产出,更新覆盖前一天的结果数据,计算引擎通常会选择Hive或者Spark。优点是数据准确度高,不易出错;缺点是架构复杂,运维成本高。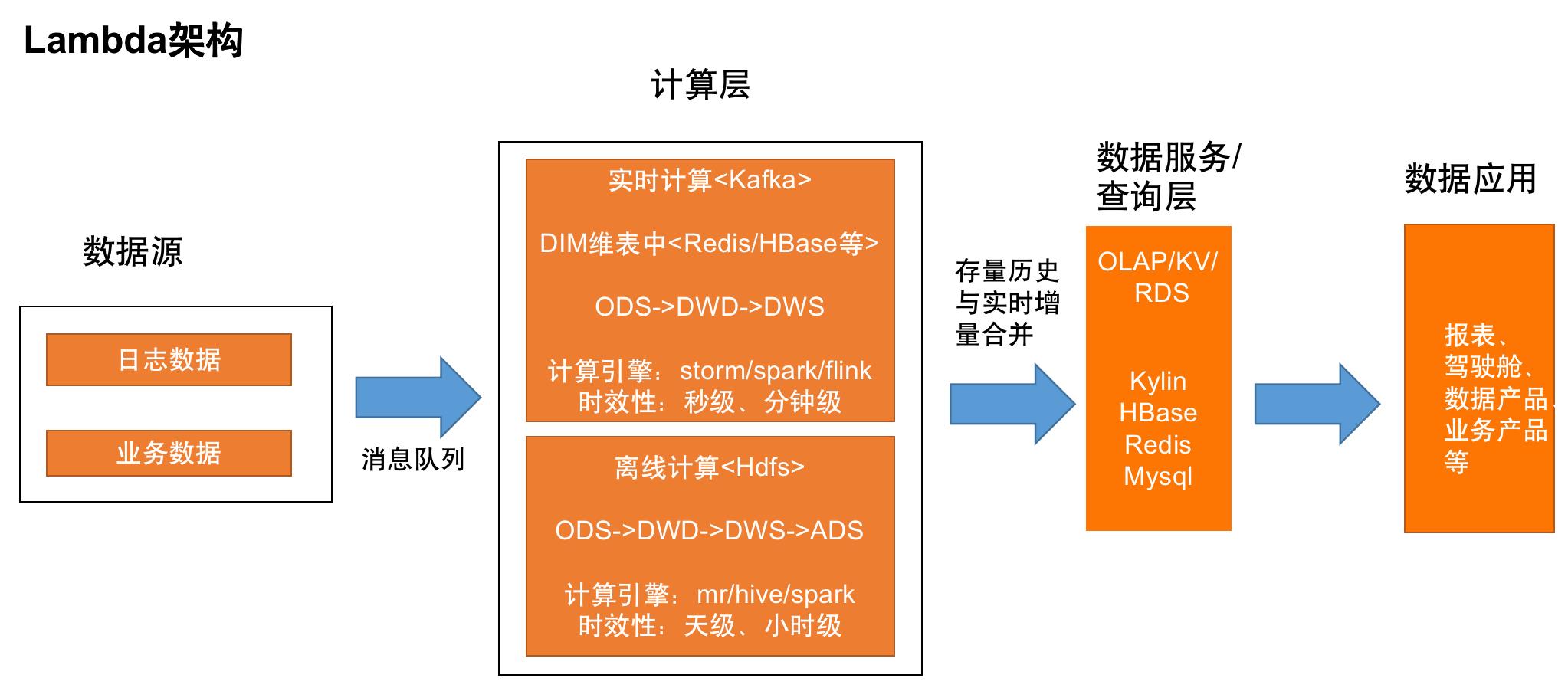
第二种是Kappa架构,相较于Lambda架构,它移除了离线生产链路,思路是通过传递任意想要的offset(偏移量)来达到重新消费处理历史数据的目的。优点是架构相对简化,数据来源单一,共用一套代码,开发效率高;缺点是必须要求消息队列中保存了存量数据,而且主要业务逻辑在计算层,比较消耗内存资源。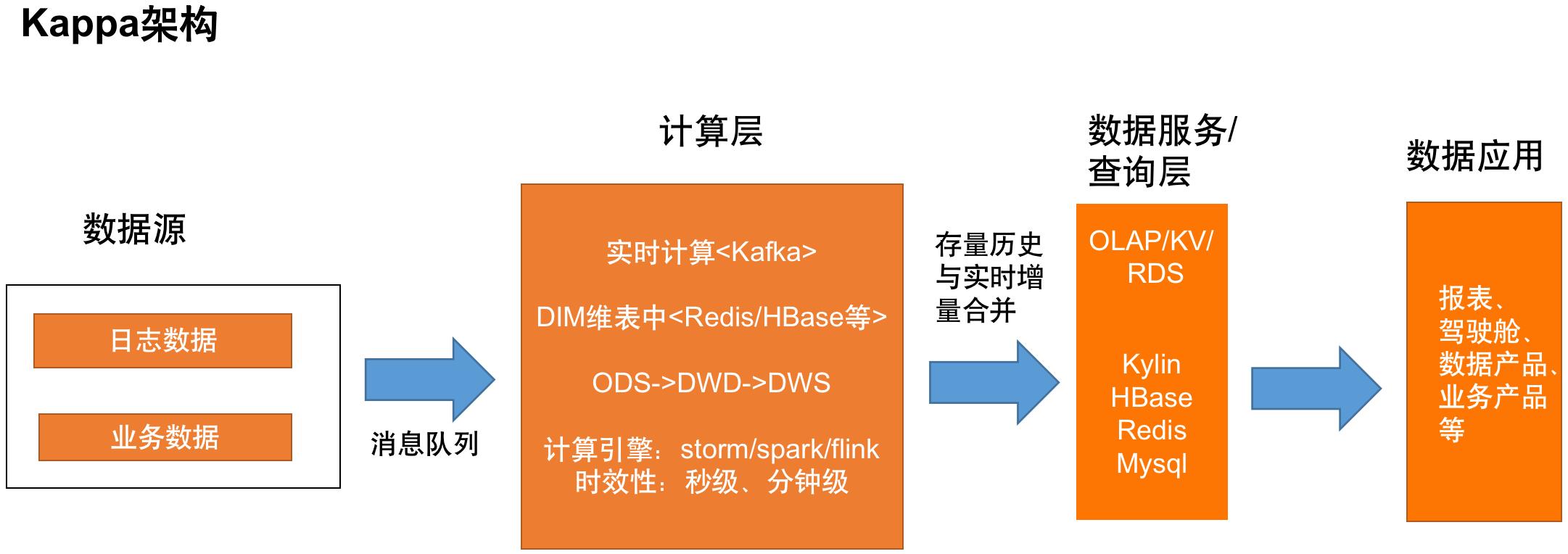
第三种是实时OLAP变体架构,是Kappa架构的进一步演化,它的思路是将聚合分析计算由OLAP引擎承担,减轻实时计算部分的聚合处理压力。优点是自由度高,可以满足数据分析师的实时自助分析需求,减轻了计算引擎的处理压力;缺点是必须要求消息队列中保存存量数据,且因为是将计算部分的压力转移到了查询层,对查询引擎的吞吐和实时摄入性能要求较高。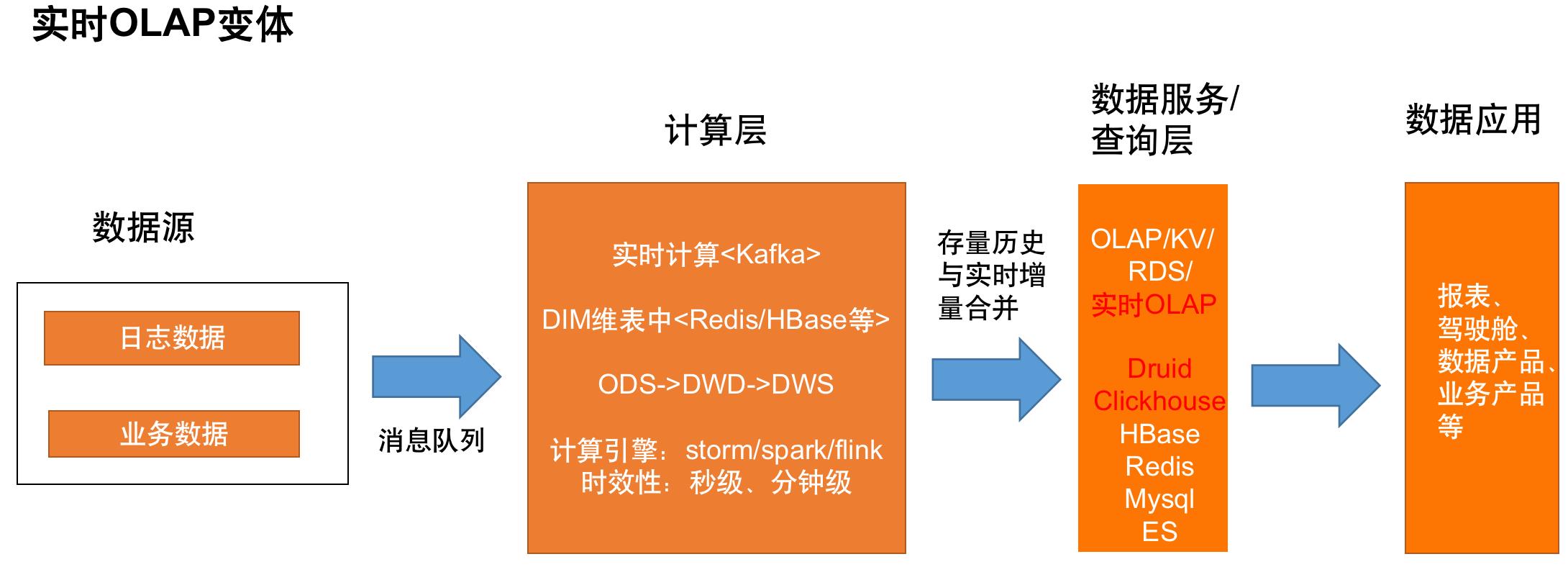
三、为什么选择Flink+Clickhouse?
以上任何一种架构都难以解决开篇提出的第四个问题,它是影响技术选型的关键制约因素。为什么这么说呢?Lambda架构的数据服务层无法同时满足批量数据查询、单条数据检索以及Merge合并,而Kappa架构和实时OLAP变体架构要求实时采集侧要拿到全量的Oracle归档日志数据,这在实际操作上没有可行性,一方面Oracle是第三方厂商维护的,不允许对线上系统有过多的侵入,容易造成监听故障甚至系统瘫痪,另一方面归档日志是在开启那一刻起才开始生成的,之前的存量数据难以进入kafka,但是后来实时数据又必须依赖前面的计算结果。
怎么走出这样的窘境呢?首先需要达成一个共识,就是计算层必须是Lambda架构,并且计算层离线链路的数据归档不再来源于实时日志,而是直接从业务库定期抽取或导入。实际项目中由于产品体系技术兼容性的原因,离线链路这里选择了Hive;实时链路上,Flink依靠其状态管理、容错机制、低时延和Exactly Once语义的优势依然占据着流式计算领域难以撼动的地位,所以计算层我们确定了Hive+Flink的架构选型。有了这个共识我们再进一步分析数据服务层,这一层的性能要求有哪些呢,不妨先从大数据领域的4类场景分析:
·batch (B):离线计算
·Analytical(A):交互式分析
·Servering (S):高并发的在线服务
·Transaction (T):事务隔离机制
离线计算通常在计算层,所以我们重点考虑A、S和T,这三个场景在广投计财实时查询业务中都有涉及,这也是区别一般互联网场景的地方,A、S、T的统一服务成为了亟待解决的难题。A要求快速的响应时间,S需要满足高并发,T支持实时事务更新(传统数据库,一般交易场景对事务要求高)。市面上很多号称能做到HTAP的产品,例如Tidb和Greeplum,深入分析就会发现,HTAP其实是一个伪命题,因为A和T的优化方向不同,为了保证T必然要牺牲A的性能,相反,如果想做到极致的A,则T的写入链路将非常复杂,事务机制和QPS无法满足需求。所以,不可能在一个系统上性能同时满足高效的A、S、T。
大数据技术高速发展的时期,涌现出了一批A性能非常好的OLAP引擎,比如基于cube预聚合的kylin、Impala、阿里AnalyticsDB,但是适合实时摄入又能够做离线分析的数据分析系统选择性并不多,当前流行的有Druid或Clickhouse,它们是典型的列存架构,能构建index、或者通过向量化计算加速列式计算的分析。在Clickhouse还未被广泛接受之前,Druid作为实时OLAP被一些互联网大厂极力推崇使用,但是一直被诟病的是它复杂的技术架构,组件非常多,包括4个节点3个依赖,四个节点分别是实时节点(Realtime Node)、历史节点(Histrical Node)、查询节点(Broker Node)、协调节点(Coodinator Node),三个依赖分别是Mysql、Deep storage(如本地磁盘、Hdfs、S3)、Zookeeper,相当于内部实现了一个Lambda+OLAP的架构,学习成本和使用成本都非常高。下面从TPC-DH性能测试来看看几大OLAP引擎对比。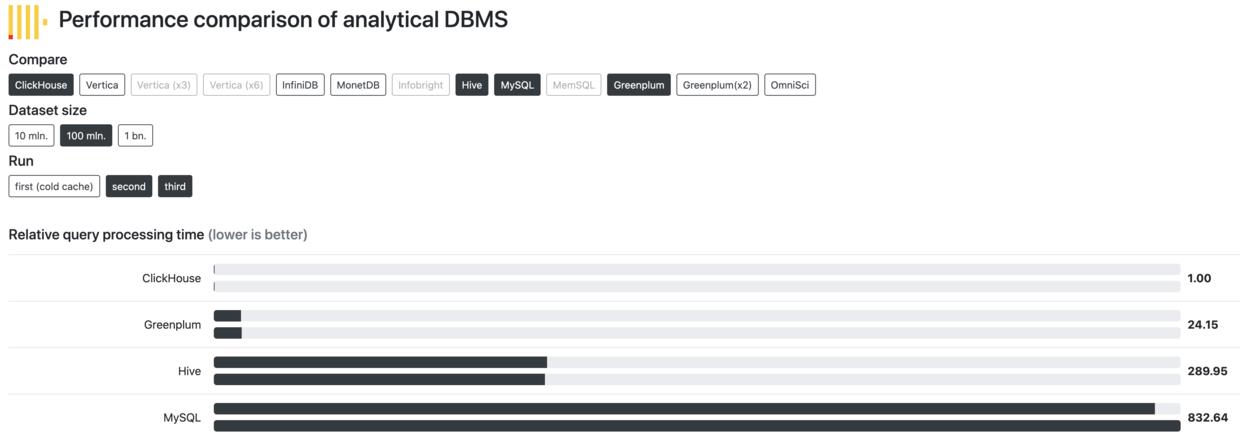
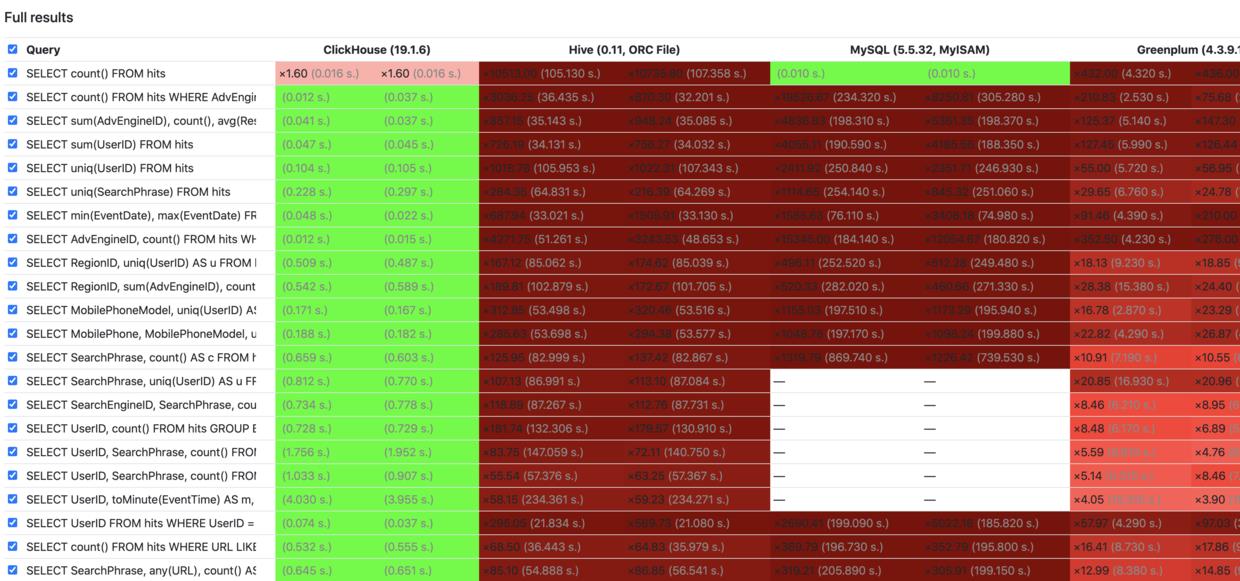
从性能对比数据可以看出,Clickhouse在亿量级数据集上平均响应时间为毫秒级,是其他分析性系统的几十倍甚至上百倍。
为什么Clickhouse在A方向表现如此优异?它的S性能又如何呢?我们从存储和查询两个维度来论证。
存储架构
Clickhouse存储中的最小单位是DataPart,写入链路为了提升吞吐,放弃了部分写入实时可见性,即数据攒批写入,一次批量写入的数据会落盘成一个DataPart,它不像Druid那样一条一条实时摄入。但ClickHouse把数据延迟攒批写入的工作交给来客户端实现,比如达到10条记录或每过5s间隔写入,换句话说就是可以在用户侧平衡吞吐量和时延,如果在业务高峰期流量不是太大,可以结合实际场景将参数调小,以达到极致的实时效果。
查询架构
(1)计算能力方面,Clickhouse采用向量化函数和aggregator算子极大地提升了聚合计算性能,配合完备的SQL能力使得数据分析变得更加简单、灵活。
(2)数据扫描方面,ClickHouse是完全列式的存储计算引擎,而且是以有序存储为核心,在查询扫描数据的过程中,首先会根据存储的有序性、列存块统计信息、分区键等信息推断出需要扫描的列存块,然后进行并行的数据扫描,像表达式计算、聚合算子都是在正规的计算引擎中处理。从计算引擎到数据扫描,数据流转都是以列存块为单位,高度向量化的。
(3)高并发服务方面,Clickhouse的并发能力其实是与并行计算量和机器资源决定的。如果查询需要扫描的数据量和计算复杂度很大,并发度就会降低,但是如果保证单个query的latency足够低(增加内存和cpu资源),部分场景下用户可以通过设置合适的系统参数来提升并发能力,比如max_threads等。其他分析型系统(例如Elasticsearch)的并发能力为什么很好,从Cache设计层面来看,ES的Cache包括Query Cache, Request Cache,Data Cache,Index Cache,从查询结果到索引扫描结果层层的Cache加速,因为Elasticsearch认为它的场景下存在热点数据,可能被反复查询。反观ClickHouse,只有一个面向IO的UnCompressedBlockCache和系统的PageCache,为了实现更优秀的并发,我们很容易想到在Clickhouse外面加一层Cache,比如redis,但是分析场景下的数据和查询都是多变的,查询结果等Cache都不容易命中,而且在广投业务中实时查询的数据是基于T之后不断更新的数据,如果外挂缓存将降低数据查询的时效性。
事实上,Clickhouse在亿数量级数据集基础上聚合分析查询响应时间、吞吐和并发能力不亚于ES,并且随着数据量的增大而扩大。下图是分别在2亿和5亿数据集上的测试结果,Q1、Q2、Q3、Q4表示数据量依次增大的sql query。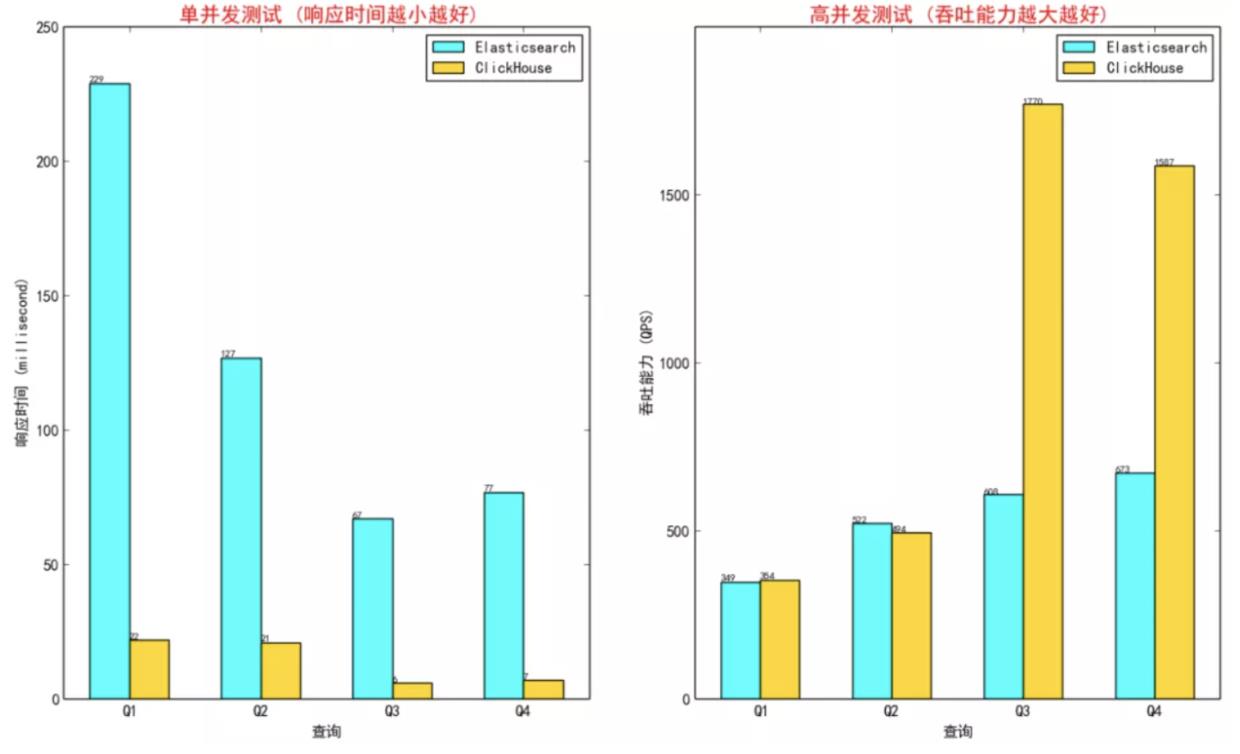
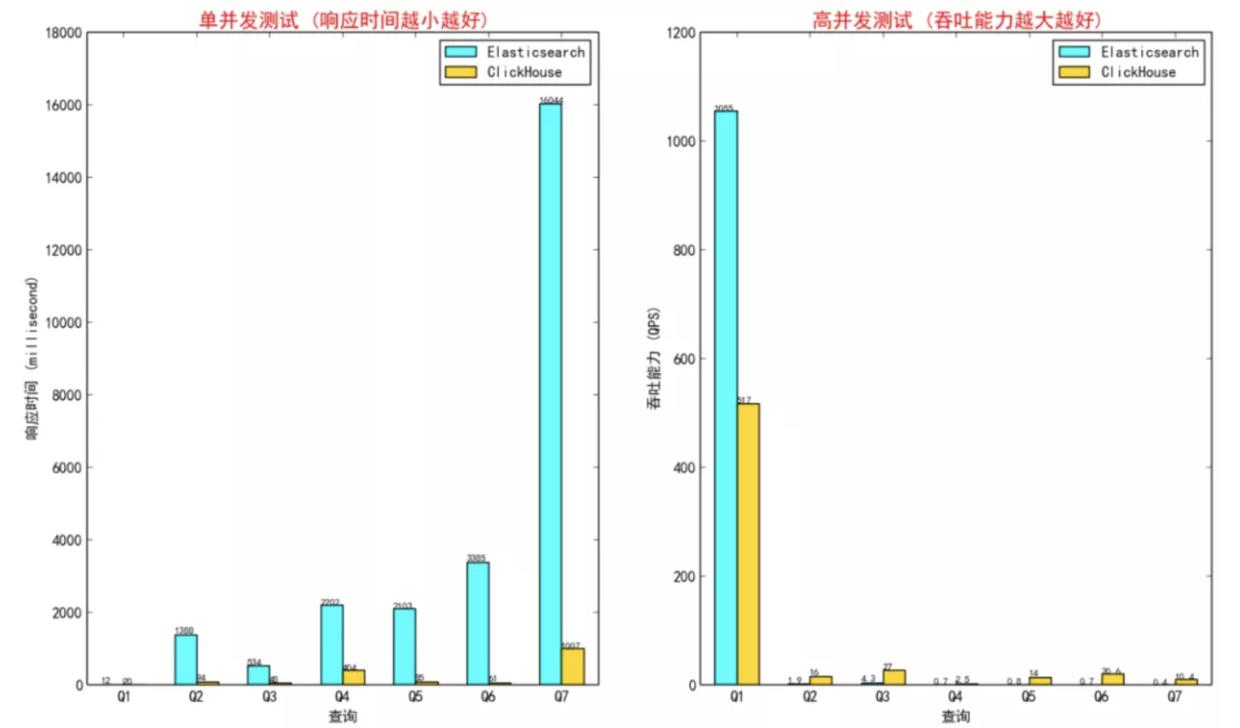
我们已经分析Clickhouse在A和S方面的优势,那么它又该如何承载T的业务呢?
前面我们已经讲了,在一个系统中不可能同时实现A和T,为什么不让他们做自己擅长的事情呢?经过深入业务洞察发现,广投计财实时查询业务中T的作用范围是最近一年的数据,经过估算,频繁发生删改操作的数据有500万左右,不到总数据量2.5亿的1/50。我们完全可以用两个不同系统协作实现,其中一个系统实现S和T,一般的关系型数据库就可以满足,例如Mysql、Postgresql;另外一个系统实现A,这里我们选择Clickhouse。我们很容易想到联邦查询,例如Presto和Drill的解决方案,其实Clickhouse内部已经集成了多个数据库引擎来替代联邦查询,没必要引入第三方框架,于是适合广投计财实时查询业务的实时数仓架构如下,笔者暂且称它为LSTAP架构(Lambda+HSTP+OLAP)。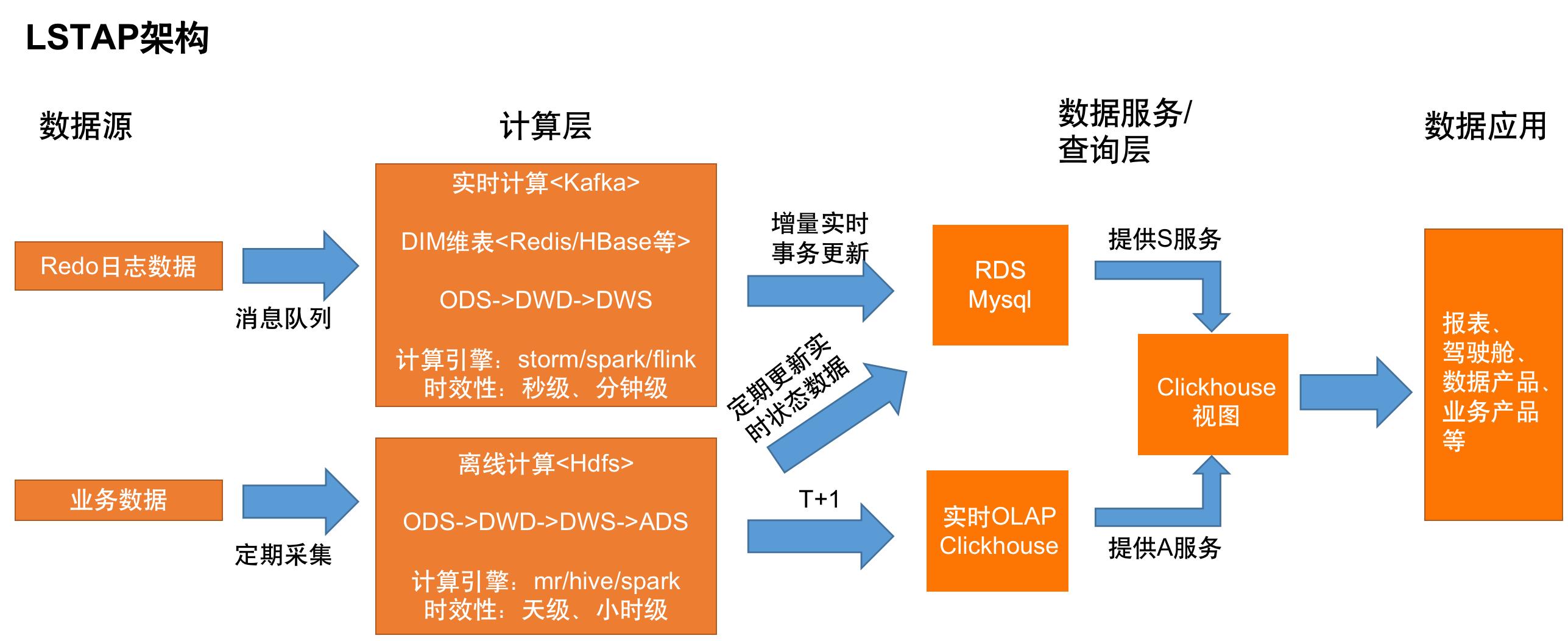
在这个架构中,最外层以一个Clickhouse视图连接Mysql引擎和Distributed引擎对应的表数据,Mysql只储存需要实时更新的那部分数据,实时链路每天从Mysql中取离线定期刷新的状态数据,确保不会因为实时链路网络原因、系统故障、应用逻辑错误等造成数据质量问题;Distributed引擎对应的Clickhouse表存储历史数据,类似于Druid里面的Histrical Node,满足统计分析和历史账单数据的查询需求。
--映射Mysql表提取最新一年的数据
CREATE TABLE jc_bi.ads_journal_recent_1year
(
`pk_detail` String,
...
`datasource` String,
`synctime` String
)
ENGINE = MySQL(\'10.100.x.xx:3306\',
\'jc_bi\',
\'ads_journal\',
\'xxx\',
\'xxx\');
--副本表
CREATE TABLE jc_bi.ads_journal_replica
(
`pk_detail` String,
...
`datasource` String,
`synctime` String
)
ENGINE = ReplicatedMergeTree(\'/clickhouse/tables/{shard}/ads_journal_replica\',
\'{replica}\')
PARTITION BY datasource
ORDER BY (unitcode,...)
SETTINGS index_granularity = 8192;
--Clickhouse分布式表,与副本表ads_journal_replica对应
CREATE TABLE jc_bi.ads_journal_dist
(
`pk_detail` String,
...
`datasource` String,
`synctime` String
)
ENGINE = Distributed(\'cluster_3shards_1replicas\',
\'jc_bi\',
\'ads_journal_replica\',
rand() % 3);
--以视图合并Mysql引擎和distributed引擎的两张表
CREATE VIEW jc_bi.v_ads_journal
(
`pk_detail` String,
...
`datasource` String,
`synctime` String
) AS
SELECT *
FROM jc_bi.jc_bi.ads_journal_recent_1year
UNION ALL
SELECT *
FROM jc_bi.ads_journal_dist;
四、实时数仓1.0
经过前期的技术调研和性能分析,基本确定了以Flink+Clickhouse为核心构建实时数仓。当然,还需要依赖一些其他技术组件来支起整个实时数仓,比如消息队列Kafka、维度存储、CDC组件等。广投数据中台项目的基础设施除了部署了开源的CDH存储与计算平台之外,还采购了“Dataphin+QuickBI”分别提供数据治理能力和可视化能力,在计财实时查询系统中,Dataphin主要用来承担离线任务调度以及起到HQL ide集成环境的作用,QuickBI作为数据分析门户提供数据查询窗口。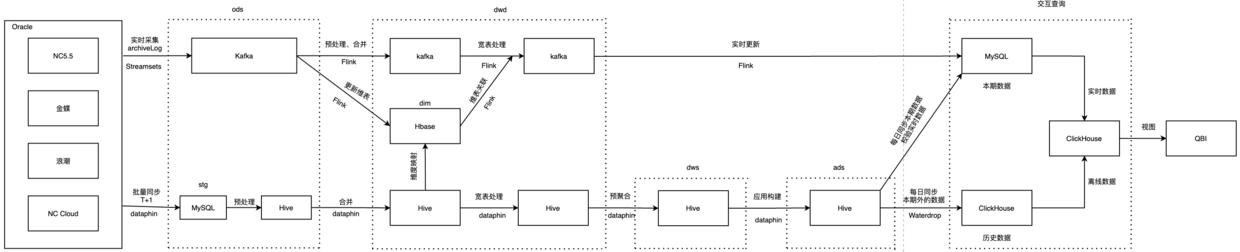
这里提几个关键的设计点:
1、实时维度存储采用Hbase,对于快变维度可以实现实时更新,rowkey采用“md5(主键)取前8位+datasource”,保证唯一性和散列性;
2、为了保证离线和实时维度数据一致性,将hive dwd层中维表数据映射到Hbase中,同时为了保障实时查询系统的稳定性,规避实时链路中由于网络延迟、数据丢失、维度未及时更新造成数据项缺失或其他不可预知的问题等导致的查询结果不可信以及例如kafka集群某节点掉线,代码bug导致任务中断等造成计算结果无法回滚,将离线计算结果每日定期供给到实时应用checkpoint,以此来解决开篇的问题2,即端到端的数据一致性;
create external table cdmd.dim_bd_accsubj_mapping_hbase(
rowkey String,
pk_accsubj String,
...
modifytime String,
datasource String
)stored by \'org.apache.hadoop.hive.hbase.HBaseStorageHandler\'
with serdeproperties("hbase.columns.mapping"=":key,f:pk_accsubj,...,f:modifytime,f:datasource")
tblproperties("hbase.table.name"="dim:DIM_BD_ACCSUBJ");
insert overwrite table cdmd.dim_bd_accsubj_mapping_hbase
select
concat(substring(md5(pk_accsubj),,8),datasource) as rowkey,
pk_accsubj,
...
modifytime,
datasource
from cdmd.dim_bd_accsubj;
3、使用Mysql结合Clickhouse的组合方式提供实时数据写入、事实数据更新、批量分析、实时响应、高并发查询为一体的数据服务能力,解决了开篇问题4,这一点在第三章已经详细论述;
4、采用“多流join+实时维度读取”的独创双保险模式,解决了多流关联场景下的数据项丢失和数据堵塞问题,即开篇的问题3,这部分将在第五章中详细介绍。
五、踩过的“坑”
在整个实时数仓构建的过程中,遇到了不少麻烦,尤其是实时Flink应用开发,现将关键问题列举如下:
(1) cdc插件选型
网上关于实时采集Oracle数据的资料并不多,通常的做法有以下几种:
- 购买Oracel原生提供的OGG,debizum的本质也是基于OGG,这种方式虽然省事但是价格昂贵;
- Kafka提供了连接各种关系型数据库的Connect,但是它是基于时间戳或整型增量主键的触发式拉取,对源系统压力大且时延较高,最主要的是无法感知删除操作;
- 自研kafka的connect,基于Logminer实现重做日志监控和解析,并实现Kafka的connect接口将解析后的数据推送到Kafka topic;
前两种方案很快就被pass掉了,只剩下第三种方案,在死磕Logminer实现机制和历经艰辛的研发后,终于实现了Oracle数据增删改的实时监控并推送到Kafka。但是在使用一段时间以后会出现数据丢失和无响应的情况,主要原因是对Logminer查询的优化不够,鉴于项目紧急程度和时间成本的考量,项目组评估决定暂时放弃自研,于是寻求另外的解决方案,最终使用了Streamsets。Streamsets图形化的配置非常友好,监控也比较稳定。但是很快就发现了它的弊端:online模式(streamsets分为redo模式和online模式,redo模式生成的是原生sql,online模式产生的是解析后的json)下更新操作时无法拿到旧数据。由于后续的架构优化需要利用这个特性,为了解决这个问题,下一步我们将在这个基础上进行二次开发,具体方案在“实时数仓2.0”章节中介绍。
(2) Idea调试Flink代码在开启checkpoint的情况下,触发报错时不输出异常信息且不断重启
Flink默认开启任务重启策略,当开启checkpoint时,如果代码有bug会导致整个任务不断重启,而不会抛出异常,很难排查问题。
解决思路:在开发环境注释checkpoint调试运行,如果业务逻辑代码没有问题再开启恢复checkpoint代码后重新发布到线上。
(3) hive映射Hbase后数据类型不对应问题
将维度表从hive映射到hbase时,假如在hive中的数据类型是smallint类型,如果映射到hbase中然后将get到的字节数组转int会报错。
解决办法:先将get到的字节数据转String类型然后使用包装类转int。
(4) hdfs配置高可用后namenode节点切换导致hdfs地址失效
在使用RocksDb状态后端时需要设置一个hdfs路径用来保存checkpoint文件。如果hdfs路径写死为active的节点,当集群出现问题namenode切换时,原来的active状态的namenode变为standby状态,代码会抛出异常: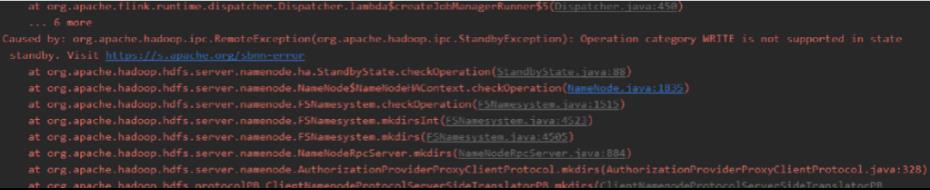
解决办法:
Hadoop配置nameservice,然后hdfs路径使用nameservice路径。
(5) fastjson的坑
用fastjson将一个pojo对象转换为json字符串时,如果pojo的属性名同时有大小写,那么直接使用JSONObject.toJSONString方法转换json会造成属性的大小写改变。另外使用fastjson将json字符串转换为JSONObject时可能丢失一些属性。为了稳定选择Gson。
(6)实时数据乱序导致计算结果错误
财务人员在核算系统上的每个操作动作在数据库中都有对应的事务变化,但是这个变化可能不是一一对应的,一个动作可能产生多个事务,而且每个系统的规则可能都不一样:删除操作可能是物理删除也可能标记删除,更新操作可能在原纪录直接更新,也可能标记删除后再插入新的数据。比如其中一个核算系统的更新凭证表现为:insert-update-delete-insert,删除凭证操作表现为:update标志位。
在分布式场景下,数据流从kafka(多个partition分区)到Flink的过程中,数据的先后顺序会发生改变导致计算结果错误,解决数据乱序问题有两种方案:第一种是kafka设置单分区,第二种是在Flink中分组处理。第一种方案在生产环境业务高峰期显然是不太合适的,对kafka单节点压力较大且无法发挥分布式系统并行处理能力的优势。于是我们选择了第二种方案,以主键或联合主键作为分区键,保证同一主键或联合主键对应的数据有序。
(7) 关联维度等待数据导致数据阻塞问题
在对事实表数据进行拉宽操作时,需要从hbase关联维度数据,对于实时更新的维度,并不能保证在从hbase取维度数据之前,维度数据已经更新到hbase。
最初的方案是游戏转让平台地图如果从hbase拿不到维度数据则继续查,直到拿到维度数据或者超过500毫秒。
Demon如下:
public static byte[] getCellBytes(Connection connection, String tableName, String rowkey, String columnFamily, String column) {
//获取表的连接
Table table = null;
try {
table = connection.getTable(TableName.valueOf("dim", tableName));
} catch (IOException e) {
e.printStackTrace();
log.error("查询hbase中维表过程中创建table出错!!!");
}
//创建get对象
Get get = new Get(Bytes.toBytes(rowkey));
Result result = null;
if ("T_GL_VOUCHERENTRY_Data".equals(tableName)) {
long time = System.currentTimeMillis();
byte[] value;
do {
try {
result = table.get(get);
} catch (IOException e) {
e.printStackTrace();
log.error("查询hbase中维表过程中get result出错!!!");
}
value = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
} while ( value == null && System.currentTimeMillis() <= time + 500); //未拿到维度数据则等待500ms
return value;
} else {
try {
result = table.get(get);
} catch (IOException e) {
e.printStackTrace();
log.error("查询hbase中维表过程中get result出错!!!");
}
byte[] value = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
return value;
}
}
这个方案带来了致命性问题:
数据处理时延非常高,达不到理想的实时效果。每条凭证数据要关联多个字段,假如每关联一个字段都要等待500ms,每条数据都要等好几秒才能拿到全部维度,在数据量大的情况下数据堵塞非常严重,时延超过一小时。
为了解决这个问题,决定采用“多流join”的方案:使用开窗函数,三流join关联维度。拿浪潮核算系统为例,Flink消费Kafka中事实数据为一条事实流,消费凭证维度数据为一条维度流,消费辅助项维度数据为另一条维度流,采用处理时间(process time)语义,对三条流进行开窗,窗口长度时间为5秒,使用coGroup算子左连接进行三流join。
多join虽然能解决时延问题,但是假如事实数据和维度数据所在的窗口不对齐,那么会导致拿不到相应的维度数据。为了解决这一问题,同时另外运行一个维度更新的Flink任务将更新的维度数据写入hbase。在事实流与维度流进行左连接join的时候,若维度流中拿不到该维度数据则往hbase查询,即“多流join+Hbase维度读取”的双重保险方案。
Demon如下:
DataStream<DWD_GL_DETAIL> joinDs1 = LangChaoFctDs.coGroup(LangChaoVoucherDim)
.where(new KeySelector<FCT_GL_DETAIL, String>() {
@Override
public String getKey(FCT_GL_DETAIL value) throws Exception {
String pk_voucher = value.getPk_voucher();
return pk_voucher;
}
})
.equalTo(new KeySelector<DIM_BD_VOUCHER, String>() {
@Override
public String getKey(DIM_BD_VOUCHER value) throws Exception {
String pk_voucher = value.getPk_voucher();
return pk_voucher;
}
})
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new RichCoGroupFunction<FCT_GL_DETAIL, DIM_BD_VOUCHER, DWD_GL_DETAIL>() {
Connection connection;
Gson gson;
@Override
public void open(Configuration parameters) throws Exception {
connection = HbaseConnection.createConnection();
gson = new Gson();
}
@Override
public void coGroup(Iterable<FCT_GL_DETAIL> first, Iterable<DIM_BD_VOUCHER> second, Collector<DWD_GL_DETAIL> out) throws Exception {
for (FCT_GL_DETAIL fct_gl_detail : first) {
String pk_voucher = fct_gl_detail.getPk_voucher();
String datasource = fct_gl_detail.getDatasource();
DWD_GL_DETAIL dwdpojo = new DWD_GL_DETAIL();
DWD_GL_DETAIL dwd_gl_detail = handleDwdLc(connection, gson, fct_gl_detail, dwdpojo);
Boolean ishave = false;
for (DIM_BD_VOUCHER dim_bd_voucher : second) {
//省略中间处理过程
ishave = true;
}
//如果维度流中拿不到维度数据则从hbase中查询
if (!ishave && pk_voucher != null) {
String rowkey1 = Md5Util.getMD5Str(pk_voucher).substring(, 8) + datasource;
//省略往hbase查询凭证维度代码
}
out.collect(dwd_gl_detail);
}
}
@Override
public void close() throws Exception {
if (connection != null) {
connection.close();
}
}
});
//双join关联辅助项维度与关联凭证维度的逻辑类似,这里省略。
新方案解决了数据处理不过来导致的背压问题,将处理时延降低到5秒以内。
六、实践展望-实时数仓2.0
实时数仓1.0在广投集团已经稳定上线运行近一个月,但是回顾技术架构,尽管它解决了实时计算领域的AST共存问题,其实还有一些优化改进的地方,比如存储冗余、实时和离线独立开发、查询系统依赖组件较多等,接下来我们逐一分析。
统一存储
仔细分析实时数仓1.0的架构我们会发现:为了解决离线计算问题,往Hive里面存储一份数据;为了解决流式数据缓冲问题,在Kafka存储了一份;为了解决维度更新和点查询的问题,又往HBase里面存储一份;为了解决列存的快速分析,数据需要Clickhouse里面存一份,甚至为了提供S和T的服务能力,我们又加入了Mysql。这样带来的问题就是:
(1)存储成本高
同一份数据在多个系统中做了冗余存储,增加了存储成本。
(2)维护难度大
每个系统的存储格式不一致,导入导出需要做类型转换,而且随着业务量增加,系统本身的维护变得困难,甚至需要配置专业的集群运维人员,对系统异常和安全管控做日常巡检。
(3)学习成本高
每一套存储系统运行原理和开发方式都不一样,对于新人来讲很难快速上手,增加了培训成本。
有没有一个统一的存储产品呢?有,数据湖,目前关注度比较高的有Databricks推出的Delta Lake、Uber的Hudi以及Netflix的Iceberg,详细的参数对比可参考https://mp.weixin.qq.com/s/m8-iFg-ekykWGrG3gXlLew。 Delta Lake和Hudi都和Spark结合的比较好,不得不说,在数据湖的实践方面,Spark生态构建走在了Flink前面,但是也已经有一些互联网大厂开始实践Hudi、Iceberg与Flink结合的实时数仓,期待数据湖开源社区能够兼容Flink。
统一计算
目前离线和实时采用两套代码开发,离线采用HQL,实时使用Flink DataStream API 进行开发,会导致开发时间长,可阅读性差,代码交接和运维难度大。
基于数据湖的流批一体、版本管理、自管理schema的特性,以及Flink 1.12以后具备批流API的统一以及与Hive的集成,我们很方便地将Hive中的数据迁移到数据湖,使用Flink SQL进行离线和实时程序开发,并且可以共用一套代码。但是目前数据湖在写多读少的场景性能还有待提升,我们不妨拭目以待。
统一查询
查询层为了实现AST服务能力,我们引入了Clickhouse+Mysql的架构。查询层的架构能否再简化呢?答案是肯定的。
Flink Sql 集成 Clickhouse快速查询
首先,通过 jdbc连接器的方式 create table 创建Clickhouse 表
CREATE TABLE gl_detail_ck
( `PK_DETAIL` STRING,
...
`TABLENAME` STRING,
`OPERATION` STRING,
`DATASOURCE` STRING,
`SCN` BIGINT )
WITH (\'connector\' = \'jdbc\',
\'url\' = \'jdbc:clickhouse://:/\',
\'table-name\' = \'gl_detail\',
\'username\' = \'\', \'password\' = \'\' );
Flink Sql jdbc的方式默认是不能集成Clickhouse的,为什么呢?
因为在源码中已经写死了只支持Derby,Mysql,Postgres方言。如果非要集成,有以下两种途径:
(1)修改Flink源代码,重新打包,添加修改后的jar包
(2)使用反射修改DIALECTS静态final属性
第一种方式太麻烦了,在这里我们采用第二种方案:
使用VersionedCollapsingMergeTree引擎实现修改删除操作
CREATE TABLE jc_bi.gl_detail (
`pk_detail` String,
...
`sign` Int8,
`version` UInt32 )
ENGINE = VersionedCollapsingMergeTree(sign,version)
PARTITION BY datasource
ORDER BY pk_detail
SETTINGS index_granularity = 8192;

以增量折叠代替事务更新的方式需要注意的问题
(1)为了解决数据爆发式增长问题,需要定期执行
optimize table 表名
(2)如果要实现数据增量折叠,必须拿到修改之前的旧数据来以此来抵消上个版本对应的数据,这里采用“Streamsets+原生SQL解析”的方式实现。
demo示例
通过 Sstreamsets data controller(scd)消费归档日志获取执行语句后写入 Kafka 中
{
"sql":"update \'GL_DETAIL\' set \'ERRMESSAGE\' = NULL where PK_DETAIL=********,、、、",
"TABLENAME":"GL_DETAIL",
"OPERATION":"UPDATE",
"DATASOURCE":"NC",
"SCN":"91685778"
}
通过Flink消费 Kafka 并且解析 Sql 获取更新前的字段
Sql解析逻辑简化如下:
public void parse(String sqlRedo) throws JSQLParserException {
//通过jsqlparser开源sql解析框架对Sql进行解析获取Satement
Statement stmt = CCJSqlParserUtil.parse(sqlRedo);
LinkedHashMap<String,String> afterDataMap = new LinkedHashMap<>();
LinkedHashMap<String,String> beforeDataMap = new LinkedHashMap<>();
parseUpdateStmt((Update) stmt, beforeDataMap, afterDataMap, sqlRedo);
}
private static void parseUpdateStmt(Update update, LinkedHashMap<String,String> beforeDataMap, LinkedHashMap<String,String> afterDataMap, String sqlRedo){
Iterator<Expression> iterator = update.getExpressions().iterator();
//通过获取更新字段的迭代器填充afterDataMap
for (Column c : update.getColumns()){
afterDataMap.put(cleanString(c.getColumnName()), cleanString(iterator.next().toString()));
}
//通过where语句来获取未修改的字段的值
if(update.getWhere() != null){
update.getWhere().accept(new ExpressionVisitorAdapter() {
@Override
public void visit(final EqualsTo expr){
String col = cleanString(expr.getLeftExpression().toString());
if(afterDataMap.containsKey(col)){
String value = cleanString(expr.getRightExpression().toString());
beforeDataMap.put(col, value);
} else {
String value = cleanString(expr.getRightExpression().toString());
beforeDataMap.put(col, value);
afterDataMap.put(col, value);
}
}
});
}else{
LOG.error("where is null when LogParser parse sqlRedo, sqlRedo = {}, update = {}", sqlRedo, update.toString());
}
}
最终解析后将数据再写入到kafka,数据如下:
{
"scn":91685778,
"type":"UPDATE",
"schema":"nc",
"table":"GL_DETAIL",
"ts":6797472127529390080,
"opTime":91945745,
"after_TS":"2021-05-10 18:50:53"、、、、,
"before_TS":"2021-05-10 18:50:23"、、、、
}
Flink Sql进行数据版本标记,再写入到Clickhouse中,至此实现了与关系型数据库一致的增删改查, 主要逻辑如下。
Table sqlParsertest =
tEnv.sqlQuery(
"select "+ "*"+"from (\\n" +
"select "+ before_column + " , -1 AS sign ,abs(hashcode("+before_column_string+")) AS version from sqlParsertest where type = \'UPDATE\'\\n" +
"union all\\n" +
"select "+ after_column + ", 1 AS sign , abs(hashcode("+after_column_string+")) AS version from sqlParsertest where type = \'UPDATE\' " +
"union all\\n" +
"select " +after_column +" ,1 AS sign, abs(hashcode(" +after_column_string +")) AS version from sqlParsertest where type = \'INSERT\'\\n" +
"union all\\n" +
"select "+ before_column+",-1 AS sign, abs(hashcode( "+before_column_string +")) AS version from sqlParsertest where type = \'DELETE\' "+
") \\n"
);
tEnv.executeSql( " insert into gl_detail_ck select * from " + sqlParsertest);
通过abs(hashcode(“+before_column_string+”))来得到版本号,当删除和更新时都会生成与旧数据相同的版本号,同时通过-1的标志位来实现折叠的效果,从而实现与关系型数据一样的增删改查操作。
实现效果如下: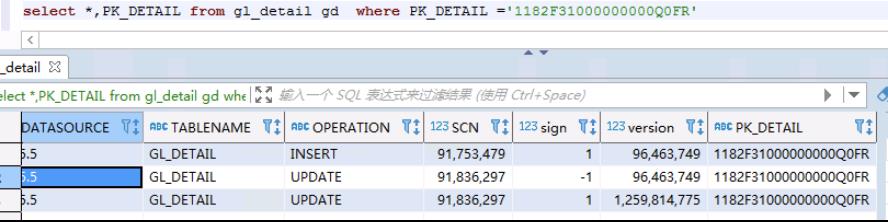
相同版本号的,并且标志位相互抵消的数据被折叠了,实现了增删改查的操作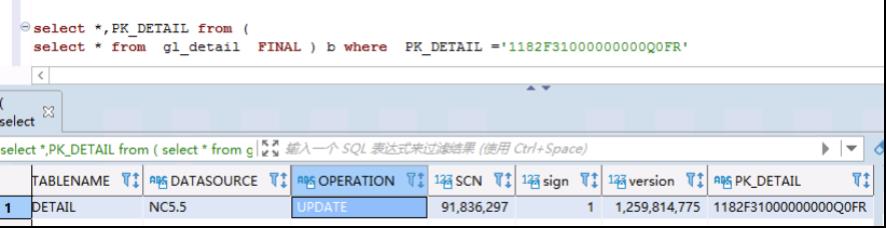
如果更新操作仅修改了度量,可以通过变体sql的查询方式实现折叠的效果,获得最新数据。
SELECT pk_detail, sum(度量 * sign) FROM gl_detail GROUP BY pk_detail HAVING sum(sign) > ;
因为在定义version字段之后,VersionedCollapsingMergeTree会自动将version作为排序条件并增加到ORDER BY的末端,就上述的例子而言,最终的排序字段为ORDER BY pk_detail,version desc。
但是如果更新操作修改了度量之外的属性信息,需要执行:
select * from gl_detail FINAL;
实时数据仓库2.0架构
在实时数仓1.0架构优化后,架构进行了极度简化,实时数仓2.0架构如下:
实时数仓2.0架构统一了存储、计算和查询,分别由三个独立产品负责,分别是数据湖、Flink和Clickhouse。数仓分层存储和维度表管理均由数据湖承担,Flink SQL负责批流任务的SQL化协同开发,Clickhouse实现变体的事务机制,为用户提供离线分析和交互查询。CDC到消息队列这一链路将来是完全可以去掉的,只需要Flink CDC家族中再添加Oracle CDC一员。未来,实时数仓架构将得到极致的简化并且性能有质的提升。
以上是关于Flink+Clickhouse实时数仓在广投集团的最佳实践的主要内容,如果未能解决你的问题,请参考以下文章