浅析Stream是如何提高遍历集合效率的:
Posted 古兰精
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析Stream是如何提高遍历集合效率的:相关的知识,希望对你有一定的参考价值。
一、为什么需要 Stream —— 分库分表之后大数据需要合并,传统方式效率不理想
现在很多大数据量系统中都存在分表分库的情况。例如,电商系统中的订单表,常常使用用户ID的Hash值来实现分表分库,这样是为了减少单个表的数据量,优化用户查询订单的速度。但在后台管理员审核订单时,他们需要将各个数据源的数据查询到应用层之后进行合并操作。
例如,当我们需要查询出过滤条件下的所有订单,并按照订单的某个条件进行排序,单个数据源查询出来的数据是可以按照某个条件进行排序的,但多个数据源查询出来已经排序好的数据,并不代表合并后是正确的排序,所以我们需要在应用层对合并数据集合重新进行排序。
在Java8之前,我们通常是通过for循环或者Iterator迭代来重新排序合并数据,又或者通过重新定义Collections.sorts的Comparator方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8中添加了一个新的接口类Stream,它和我们之前接触的字节流概念不太一样,Java8集合中的Stream相当于高级版的Iterator,他可以通过Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream的聚合操作与数据库SQL的聚合操作sorted、filter、map等类似。我们在应用层就可以高效地实现类似数据库SQL的聚合操作了,而在数据操作方面,Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
二、Stream的简洁与强大
接下来我们就用一个简单的例子来体验下Stream的简洁与强大。这个Demo的需求是过滤分组一所中学里身高在160cm以上的男女同学,我们先用传统的迭代方式来实现,代码如下:
Map> stuMap = new HashMap>();
for (Student stu: studentsList) {
if (stu.getHeight() > 160) { //如果身高大于160
if (stuMap.get(stu.getSex()) == null) { //该性别还没分类
List list = new ArrayList(); //新建该性别学生的列表
list.add(stu); //将学生放进去列表
stuMap.put(stu.getSex(), list);//将列表放到map中
} else { //该性别分类已存在
stuMap.get(stu.getSex()).add(stu);//该性别分类已存在,则直接放进去即可
}
}
}
我们再使用Java8中的Stream API进行实现:
// 串行实现 Map> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160)
.collect(Collectors.groupingBy(Student ::getSex)) // 并行实现 Map> stuMap = stuList.parallelStream().filter((Student s) -> s.getHeight() > 160)
.collect(Collectors.groupingBy(Student ::getSex));
通过上面两个简单的例子,我们可以发现,Stream结合Lambda表达式实现遍历筛选功能非常得简洁和便捷。
三、Stream 如何优化遍历
上面我们初步了解了Java8中的Stream API,那Stream是如何做到优化迭代的呢?并行又是如何实现的?下面我们就透过Stream源码剖析Stream的实现原理。
在了解Stream的实现原理之前,我们先来了解下Stream的操作分类,因为它的操作分类其实是实现高效迭代大数据集合的重要原因之一。为什么这样说,分析完你就清楚了。
官方将Stream中的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。
中间操作只对操作进行了记录,即只会返回一个 <typo id="typo-1767" data-origin="流" ignoretag="true">流</typo>,不会进行计算操作,而终结操作是实现了计算操作。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。
操作分类详情如下图所示:
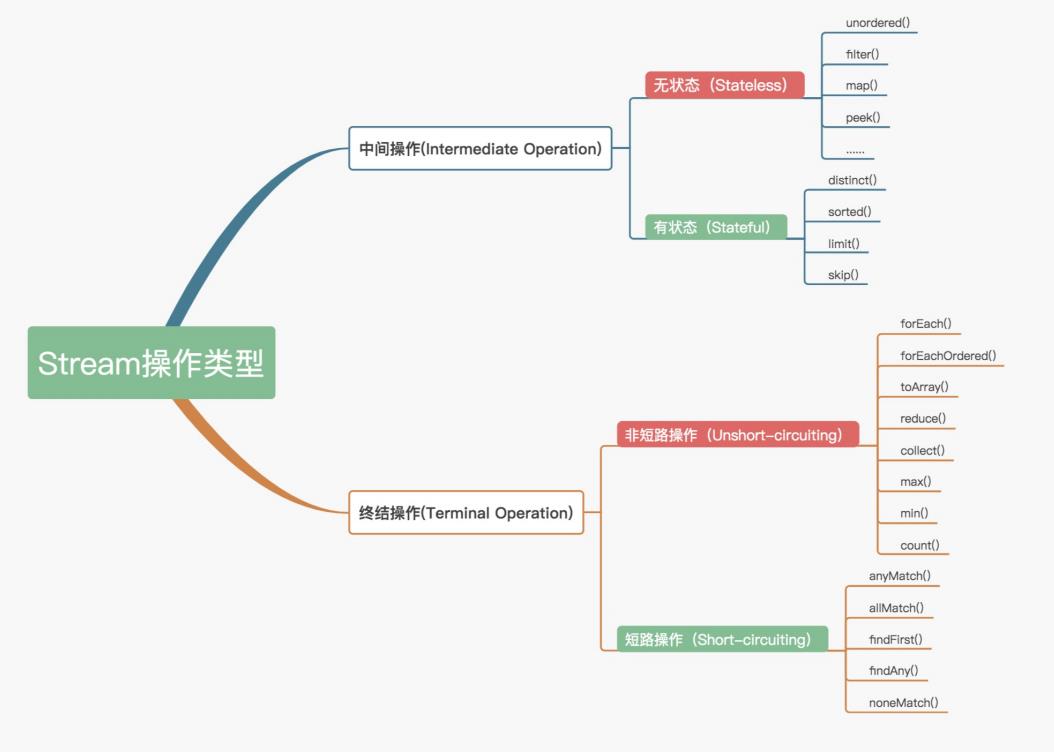
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了Stream的高效。
在了解Stream如何工作之前,我们先来了解下Stream包是由哪些主要结构类组合而成的,各个类的职责是什么。参照下图:
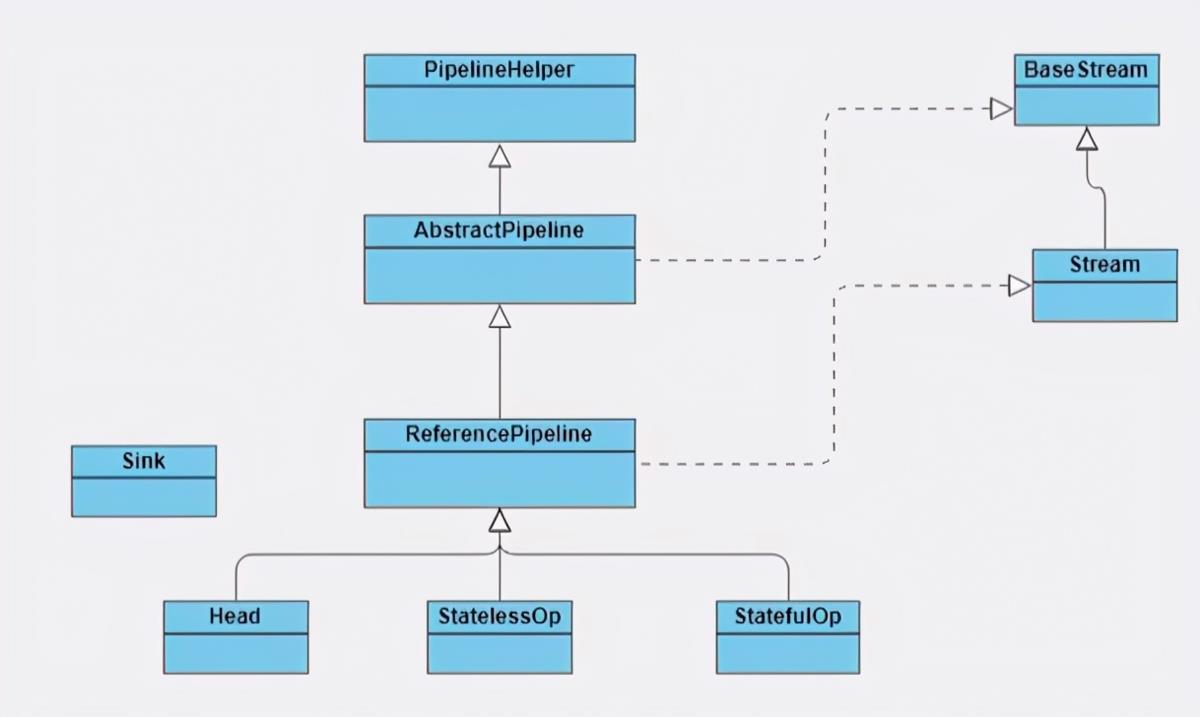
BaseStream和Stream为最顶端的接口类。BaseStream主要定义了流的基本接口方法,例如,spliterator、isParallel等;Stream则定义了一些流的常用操作方法,例如map、filter等。
ReferencePipeline是一个结构类,他通过定义内部类组装了各种操作流。他定义了Head、StatelessOp、StatefulOp三个内部类,实现了BaseStream与Stream的接口方法。
Sink接口是定义每个Stream操作之间关系的协议,他包含begin()、end()、cancellationRequested()、accpt()四个方法。ReferencePipeline最终会将整个Stream流操作组装成一个调用链,而这条调用链上的各个Stream操作的上下关系就是通过Sink接口协议来定义实现的。
我们知道,一个Stream的各个操作是由处理管道组装,并统一完成数据处理的。在JDK中每次的中断操作会以使用阶段(Stage)命名。
管道结构通常是由ReferencePipeline类实现的,前面讲解Stream包结构时,我提到过ReferencePipeline包含了Head、StatelessOp、StatefulOp三种内部类。
(1)Head类主要用来定义数据源操作,在我们初次调用names.stream()方法时,会初次加载Head对象,此时为加载数据源操作;
(2)接着加载的是中间操作,分别为无状态中间操作StatelessOp对象和有状态操作StatefulOp对象,此时的Stage并没有执行,而是通过AbstractPipeline生成了一个中间操作Stage链表;
(3)当我们调用终结操作时,会生成一个最终的Stage,通过这个Stage触发之前的中间操作,从最后一个Stage开始,递归产生一个Sink链。
List names = Arrays.asList("张三", "李四", "王老五", "李三", "刘老四", "王小二", "张四", "张五六七");
String maxLenStartWithZ = names.stream().filter(name -> name.startsWith("张"))
.mapToint(String::length).max().toString();
这个例子的需求是查找出一个长度最长,并且以张为姓氏的名字。从代码角度来看,你可能会认为是这样的操作流程:首先遍历一次集合,得到以“张”开头的所有名字;然后遍历一次filter得到的集合,将名字转换成数字长度;最后再从长度集合中找到最长的那个名字并且返回。
这里我要很明确地告诉你,实际情况并非如此。我们来逐步分析下这个方法里所有的操作是如何执行的。
(1)首先 ,因为names是ArrayList集合,所以names.stream()方法将会调用集合类基础接口Collection的Stream方法:
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
然后,Stream方法就会调用StreamSupport类的Stream方法,方法中初始化了一个ReferencePipeline的Head内部类对象:
public static Stream stream(Spliterator spliterator, Boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);
}
再调用filter和map方法,这两个方法都是无状态的中间操作,所以执行filter和map操作时,并没有进行任何的操作,而是分别创建了一个Stage来标识用户的每一次操作。
而通常情况下Stream的操作又需要一个回调函数,所以一个完整的Stage是由数据来源、操作、回调函数组成的三元组来表示。如下图所示,分别是ReferencePipeline的filter方法和map方法:
@Overridepublic final Stream filter(Predicate predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {
@OverrideSink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
@Overridepublic void begin(long size) {
downstream.begin(-1);
}
@Override public void accept(P_OUT u) {
if (predicate.test(u)) downstream.accept(u);
}
}
;
}
}
;
}
@Override@SuppressWarnings("unchecked")public final Stream map(Function mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@OverrideSink opWrapSink(int flags, Sink sink) {
return new Sink.ChainedReference(sink) {
@Overridepublic void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
}
;
}
}
;
}
new StatelessOp将会调用父类AbstractPipeline的构造函数,这个构造函数将前后的Stage联系起来,生成一个Stage链表。
AbstractPipeline(AbstractPipeline previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;previousStage.nextStage = this;//将当前的stage的next指针指向之前的
stagethis.previousStage = previousStage;//赋值当前stage当全局变量
previousStage this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful()) sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
因为在创建每一个Stage时,都会包含一个opWrapSink()方法,该方法会把一个操作的具体实现封装在Sink类中,Sink采用(处理->转发)的模式来叠加操作。
当执行max方法时,会调用ReferencePipeline的max方法,此时由于max方法是终结操作,所以会创建一个TerminalOp操作,同时创建一个ReducingSink,并且将操作封装在Sink类中。
最后,调用AbstractPipeline的wrapSink方法,该方法会调用opWrapSink生成一个Sink链表,Sink链表中的每一个Sink都封装了一个操作的具体实现。
@Override@SuppressWarnings("unchecked")final Sink wrapSink(Sink sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink) sink;
}
当Sink链表生成完成后,Stream开始执行,通过spliterator迭代集合,执行Sink链表中的具体操作。
@Overridefinal void copyInto(Sink wrappedSink, Spliterator spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
} else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
Java8中的Spliterator的forEachRemaining会迭代集合,每迭代一次,都会执行一次filter操作,如果filter操作通过,就会触发map操作,然后将结果放入到临时数组object中,再进行下一次的迭代。完成中间操作后,就会触发终结操作max。
这就是串行处理方式了,那么Stream的另一种处理数据的方式又是怎么操作的呢?
4、Stream并行处理
Stream处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在例子的代码中新增一个Parallel()方法,代码如下所示:
String maxLenStartWithZ = names.stream().parallel()
.filter(name -> name.startsWith("张")).mapToint(String::length).max().toString();
Stream的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用TerminalOp的evaluateParallel方法进行并行处理。
final R evaluate(TerminalOp terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel() ? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) : terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
这里的并行处理指的是,Stream结合了ForkJoin框架,对 Stream 处理进行了分片,Splititerator中的 estimateSize方法会估算出分片的数据量。
通过预估的数据量获取最小处理单元的阈值,如果当前分片大小大于最小处理单元的阈值,就继续切分集合。每个分片将会生成一个Sink链表,当所有的分片操作完成后,ForkJoin框架将会合并分片任何结果集。
四、合理使用Stream
看到这里,你应该对Stream API是如何优化集合遍历有个清晰的认知了。Stream API用起来简洁,还能并行处理,那是不是使用Stream API,系统性能就更好呢?通过一组测试,我们一探究竟。
我们将对常规的迭代、Stream串行迭代以及Stream并行迭代进行性能测试对比,迭代循环中,我们将对数据进行过滤、分组等操作。分别进行以下几组测试:
- 多核CPU服务器配置环境下,对比长度100的int数组的性能;
- 多核CPU服务器配置环境下,对比长度1.00E+8的int数组的性能;
- 多核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组的性能;
- 单核CPU服务器配置环境下,对比长度1.00E+8对象数组过滤分组的性能。
由于篇幅有限,我这里直接给出统计结果,你也可以自己去验证一下,具体的测试代码可以在Github上查看。通过以上测试,我统计出的测试结果如下(迭代使用时间):
- 常规的迭代
- Stream并行迭代<常规的迭代
- Stream并行迭代<常规的迭代
- 常规的迭代
通过以上测试结果,我们可以看到:在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核CPU服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核CPU的情况下,Stream的并行迭代优势明显。所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核CPU环境下,并且使用Stream的并行迭代方式进行处理。
用事实说话,我们看到其实使用Stream未必可以使系统性能更佳,还是要结合应用场景进行选择,也就是合理地使用Stream。
五、总结
1、纵观Stream的设计实现,非常值得我们学习。
(1)从大的设计方向上来说,Stream将整个操作分解为了链式结构,不仅简化了遍历操作,还为实现了并行计算打下了基础。
(2)从小的分类方向上来说,Stream将遍历元素的操作和对元素的计算分为中间操作和终结操作,而中间操作又根据元素之间状态有无干扰分为有状态和无状态操作,实现了链结构中的不同阶段。
2、在串行处理操作中,
(1)Stream在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,
(2)通过Java8中的Spliterator迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;
(3)最后就是进行终结操作的数据处理。
3、在并行处理操作中,Stream对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream将结合ForkJoin框架对集合进行切片处理,ForkJoin框架将每个切片的处理结果Join合并起来。
4、最后就是要注意Stream的使用场景。
据说是网易三面,原文链接:https://www.jianshu.com/p/b91161b8edf1
以上是关于浅析Stream是如何提高遍历集合效率的:的主要内容,如果未能解决你的问题,请参考以下文章