论文查重
Posted 一颗柠檬猹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文查重相关的知识,希望对你有一定的参考价值。
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/InformationSecurity1912-Softwareengineering/homework/12146 |
| 这个作业在哪里 | https://github.com/linghuiba/3219005442 |
| 这个作业的目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
目录
- 需求分析
- PSP表格
- 算法设计及实现过程
- 代码流程图
- 主要代码分析
- 性能的改进
- 部分单元测试展示
- 异常处理
- 总结
一、需求分析
设计一个论文查重算法,从命令行参数给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件的地址,计算两个文件的文本重复率。再在命令行参数给出地址,并在该地址输出答案(重复率)。
首先计算重复率可以使用python自带的jieba包分别对两个txt文件中的句子进行分词。其次,一个文件的内容中出现频率越高的词,越能描述该文档,因此可以统计每个词项在每篇文档中出现的次数向量,这就获得了一系列文档在同一向量空间(又称为 VSM词袋模型)。每篇文档在VSM中用向量表示,那么就可以想到用余弦相似度计算结果来作为文本相似度。
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| Estimate | 估计这个任务需要多少时间 | 3 | 5 |
| Development | 开发 | 1200 | 1000 |
| Analysis | 需求分析(包括学习新技术) | 30 | 60 |
| Design Spec | 生成设计文档 | 15 | 20 |
| Design Review | 设计复审 | 10 | 5 |
| Coding Standard | 代码规范(为目前的开发制定合适的) | 60 | 75 |
| Design | 具体设计 | 30 | 25 |
| Coding | 具体编码 | 200 | 180 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试、修改代码、提交修改) | 10 | 60 |
| Reporting | 报告 | 60 | 100 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 30 |
三、算法设计及实现过程
1、VSM词袋模型
统计每个词在每篇文档中出现的次数即词频率,获得文档中每个词的权重,一篇文档则转换成了词-权重的集合,通常称为词袋模型。
我们通常用词袋模型来描述一篇文档。词袋的含义就是说,像是把一篇文档拆分成一个一个的词条,然后将它们扔进一个袋子里。在袋子里的词与词之间是没有关系的。因此词袋模型中,词在文档中出现的次序被忽略。将词项在每篇文档中出现的次数保存在向量中,就是这篇文档的文档向量。
2、余弦相似度计算
VSM向量空间模型是信息检索、文本分析中基本的模型。通过该模型,可以进行有序文档检索、文档聚类、文档分类等。每篇文档在VSM中用向量表示,一开始可能会想到用差值来描述两篇文档的相似度。但是,如果两篇相似的文档,由于文档长度不一样。他们的向量的差值会很大。因此还是选择余弦相似度来计算两个向量相似度,因为它可以去除文档长度的影响。
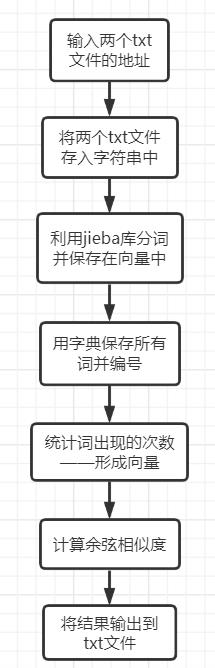
3、代码流程图
四、部分性能的改进
1、性能分析图
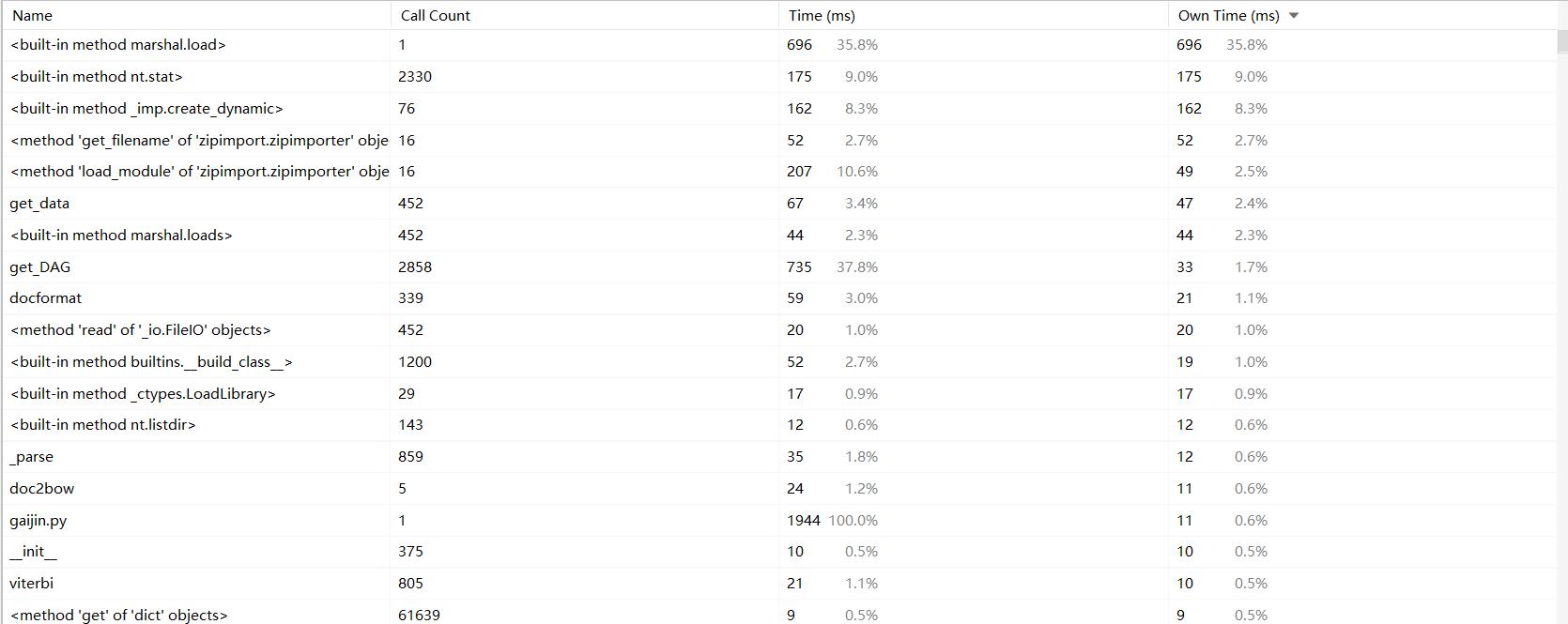
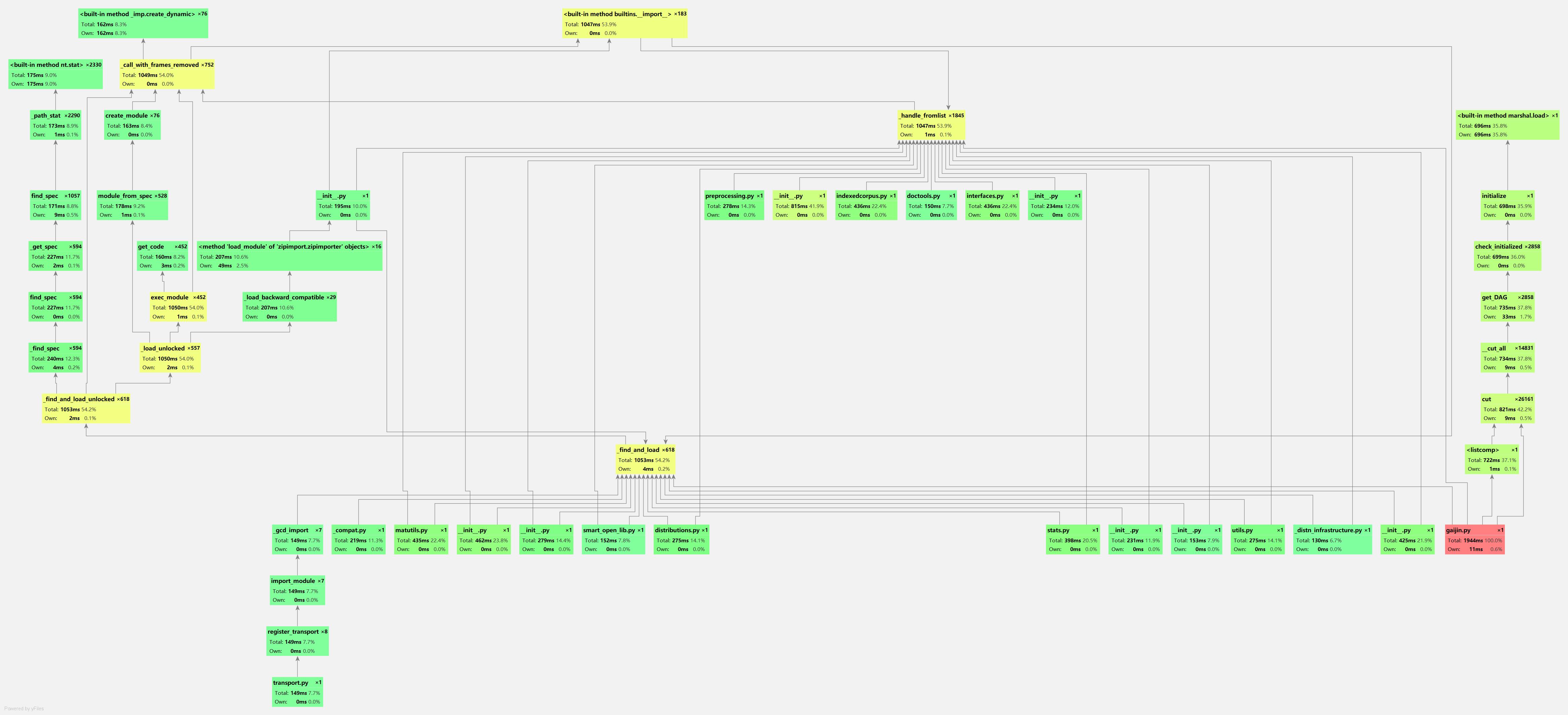
2、消耗最大的部分
1、加载数据
2、计算余弦相似度

五、部分单元测试展示
1、部分单元测试代码

该过程主要是利用jieba库将语气词、助词等自身无明确意义的词划分出去,将其余词保存到向量中
该过程就是根据词袋模型统计词在每篇文本中出现的次数所形成的向量计算其余弦相似度,也就是文本重复率
2、测试覆盖率
3、测试结果
以原版以及第一篇文本为例,计算出两篇文本的相似度,结果如下:
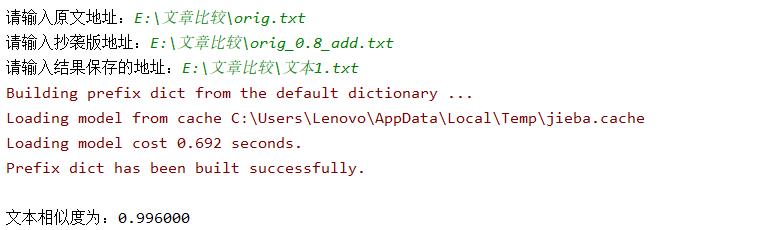
六、异常处理

最后就要进行异常处理。计算时,如果没有出现错误,则结果返回余弦相似度。若出现错误,不管如何结果都返回0
七、总结
1、可以看出根据该算法所得出的重复率是过高的,那么是什么原因造成的呢?首先,余弦相似度计算只注意两个向量在方向上的差异,而不是距离或长度上的差异。也就是说在信息检索中,它主要是给出两篇文档其主题方面的相似度,而文本的相似度并不是那么准确。比如,如果只在一篇文章上增加或删除内容,该方法计算出的重复率仍然很大,因为主题没有变化。其次,该方法无法扩展到海量数据,因为如果每条记录都计算一下余弦角度,其计算量是相当恐怖的。
2、如果想要改变这种情况,可以使用SimHash算法来提升文本相似度检测的准确性。该过程主要如下图: 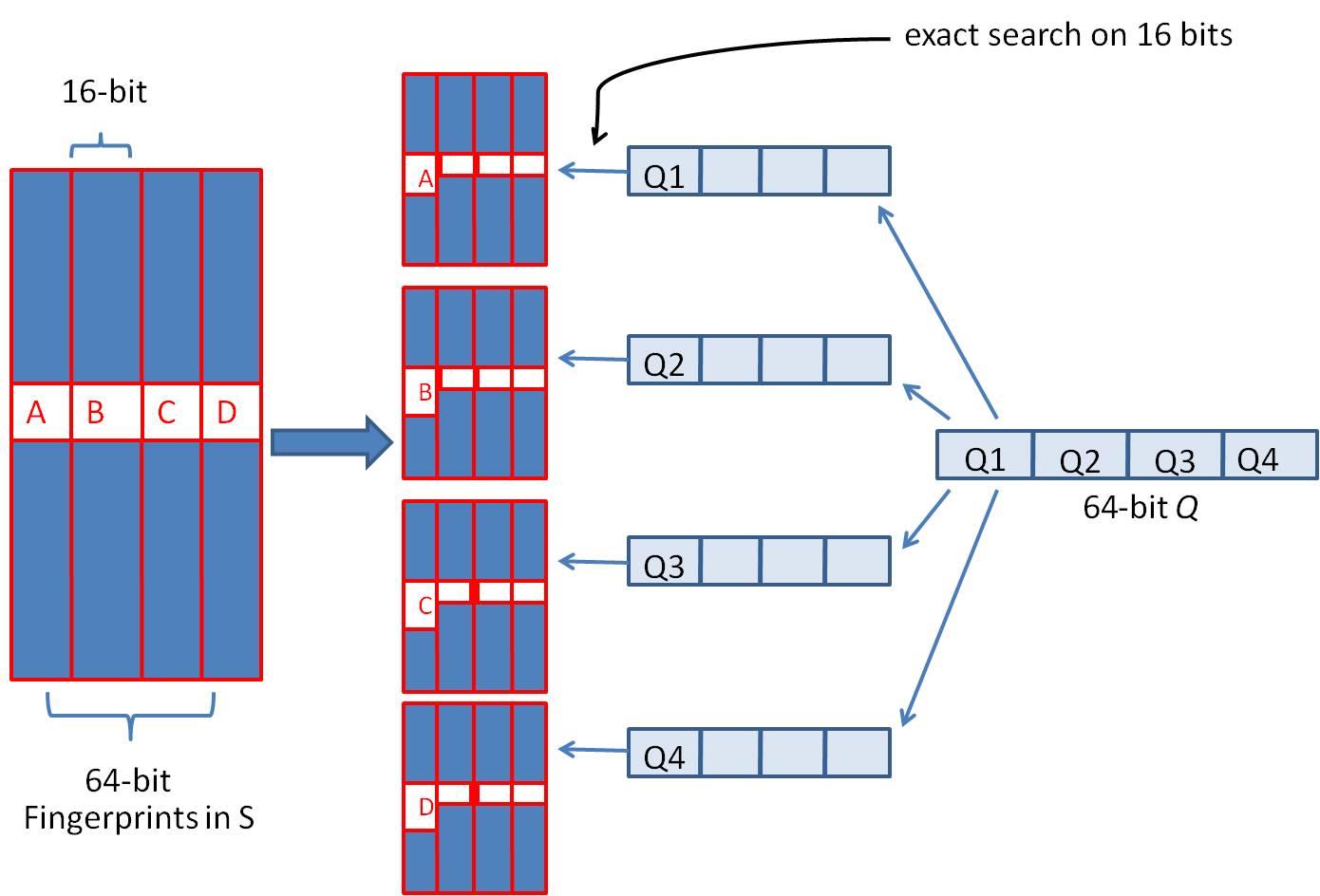
1)将64位的二进制串等分成四块
2)调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
3)采用精确匹配的方式查找前16位
4)如果样本库中存有2^34 (差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
3、改进的代码我会放入gitlab中。
以上是关于论文查重的主要内容,如果未能解决你的问题,请参考以下文章