深入理解Linux Kernel调度器的身世之谜
Posted ludongguoa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解Linux Kernel调度器的身世之谜相关的知识,希望对你有一定的参考价值。
引言
Linux Kernel Development 一书中,关于 Linux 的进程调度器并没有讲解的很全面,只是提到了 CFS 调度器的基本思想和一些实现细节;并没有 Linux 早期的调度器介绍,以及最近这些年新增的在内核源码树外维护的调度器思想。所以在经过一番搜寻后,看到了这篇论文 A complete guide to Linux process scheduling,对 Linux 的调度器历史进行了回顾,并且相对细致地讲解了 CFS 调度器。整体来说,虽然比较啰嗦,但是对于想要知道更多细节的我来说非常适合,所以就有了翻译它的冲动。当然,在学习过程也参考了其它论文。下面开启学习之旅吧,如有任何问题,欢迎指正~
需要注意的是,在 Linux 中,线程和进程都是由同一个结构体(task_struct,即任务描述符)表示的,所以文中会交叉使用进程、线程和任务等术语,可以将它们视作同义词。当然,也可以将线程(任务)称为最小执行单元。但 Linux 的调度算法(如 CFS)可以应用更加通用的调度单元(如线程、cgroup、用户等)。总之,不要过度纠结这里的术语,重要的是了解每种调度算法的思想!
为什么需要调度
Linux 是一个多任务的操作系统,这就意味着它可以「同时」执行多个任务。在单核处理器上,任意时刻只能有一个进程可以执行(并发);而在多核处理器中,则允许任务并行执行。然而,不管是何种硬件类型的机器上,可能同时还有很多在内存中无法得到执行的进程,它们正在等待运行,或者正在睡眠。负责将 CPU 时间分配给进程的内核组件就是「进程调度器」。
调度器负责维护进程调度顺序,选择下一个待执行的任务。如同多数其它的现代操作系统,Linux 实现了抢占式多任务机制。也就是说,调度器可以随时决定任意进程停止运行,而让其它进程获得 CPU 资源。这种违背正在运行的进程意愿,停止其运行的行为就是所谓的「抢占」。抢占通常可以在定时器中断时发生,当中断发生时,调度器会检查是否需要切换任务,如果是,则会完成进程上下文切换。每个进程所获得的运行时间叫做进程的时间片(timeslice)。
任务通常可以区分为交互式(I/O 密集型)和非交互式(CPU 密集型)任务。交互式任务通常会重度依赖 I/O 操作(如 GUI 应用),并且通常用不完分配给它的时间片。而非交互式任务(如数学运算)则需要使用更多的 CPU 资源。它们通常会用完自己的时间片之后被抢占,并不会被 I/O 请求频繁阻塞。当然,现实中的应用程序可能同时包含上述两种分类任务。例如,文本编辑器,多数情况下,它会等待用户输入,但是在执行拼写检查时也会需要占用大量 CPU 资源。
操作系统的调度策略就需要均衡这两种类型的任务,并且保证每个任务都能得到足够的执行资源,而不会对其它任务产生明显的性能影响。 Linux 为了保证 CPU 利用率最大化,同时又能保证更快的响应时间,倾向于为非交互式任务分配更大的时间片,但是以较低的频率运行它们;而针对 I/O 密集型任务,则会在较短周期内频繁地执行。
调度有关的进程描述符
进程描述符(task_struct)中的很多字段会被调度机制直接使用。以下仅列出一些核心的部分,并在后文详细讨论。
struct task_struct { int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; … unsigned int policy; cpumask_t cpus_allowed; …};关于这些字段的说明如下:
prio表示进程的优先级。进程运行时间,抢占频率都依赖于这些值。rt_priority则用于实时(real-time)任务;sched_class表示进程位于哪个调度类;sched_entity的意义比较特殊。通常把一个线程(Linux 中的进程、任务同义词)叫作最小调度单元。但是 Linux 调度器不仅仅只能够调度单个任务,而且还可以将一组进程,甚至属于某个用户的所有进程作为整体进行调度。这就允许我们实现组调度,从而将 CPU 时间先分配到进程组,再在组内分配到单个线程。当引入这项功能后,可以大幅度提升桌面系统的交互性。比如,可以将编译任务聚集成一个组,然后进行调度,从而不会对交互性产生明显的影响。这里再次强调下,**Linux 调度器不仅仅能直接调度进程,也能对调度单元(schedulable entities)进行调度。这样的调度单元正是用struct sched_entity来表示的。需要说明的是,它并非一个指针,而是直接嵌套在进程描述符中的。当然,后面的谈论将聚焦在单进程调度这种简单场景。由于调度器是面向调度单元设计的,所以它会将单个进程也视为调度单元,因此会使用sched_entity结构体操作它们。sched_rt_entity则是实时调度时使用的。policy表明任务的调度策略:通常意味着针对某些特定的进程组(如需要更长时间片,更高优先级等)应用特殊的调度决策。Linux 内核目前支持的调度策略如下:SCHED_NORMAL:普通任务使用的调度策略;SCHED_BATCH:不像普通任务那样被频繁抢占,可允许任务运行尽可能长的时间,从而更好地利用缓存,但是代价自然是损失交互性能。这种非常适合批量任务调度(批量的 CPU 密集型任务);SCHED_IDLE:它要比 nice 19 的任务优先级还要低,但它并非真的空闲任务;SCHED_FIFO和SCHED_RR是软实时进程调度策略。它们是由 POSIX 标准定义的,由<kernel/sched/rt.c>里面定义的实时调度器负责调度。RR 实现的是带有固定时间片的轮转调度方式;SCHED_FIFO 则使用的是先进先出的队列机制。cpus_allowed:用来表示任务的 CPU 亲和性。用户空间可以通过sched_setaffinity系统调用来设置。
优先级 Priority
进程优先级:
普通任务优先级:
所有的类 Unix 操作系统都实现了优先级调度机制。它的核心思想就是给任务设定一个值,然后通过该值决定任务的重要程度。如果任务的优先级一致,则一次重复运行它们。在 Linux 中,每一个普通任务都被赋予了一个 nice 值,它的范围是 -20 到 +19,任务默认 nice 值是 0。
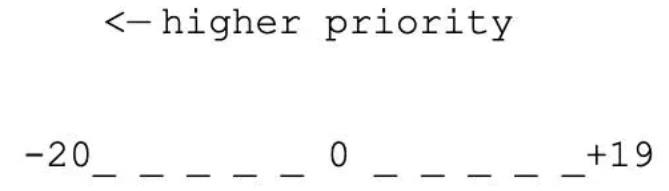
nice 值越高,任务优先级越低(it\'s nice to others)。Linux 中可以使用 nice(int increment) 系统调用来修改当前进程的优先级。该系统调用的实现位于 <kernel/shced/core.c> 中。默认情况下,用户只能为该用户启动的进程增加 nice 值(即降低优先级)。如果需要增加优先级(减少 nice 值),或者修改其它用户进程优先级,则必须以 root 身份操作。
实时任务优先级:在 Linux 中,除了普通任务外,还有一类任务属于实时任务。实时任务是确保它们能够在一定时间范围内执行的任务,有两类实时任务,列举如下:
- 硬实时任务:会有严格的时间限制,任务必须在时限内完成。比如直升机的飞控系统,就需要及时响应驾驶员的操控,并做出预期的动作。然而,Linux 本身并不支持硬实时任务,但是有一些基于它修改的版本,如 RTLinux(它们通常被称为 RTOS)则是支持硬实时调度的。
- 软实时任务:软实时任务其实也会有时间限制,但不是那么严格。也就是说,任务晚一点运行任务,并不会造成不可挽回的灾难性事故。实践中,软实时任务会提供一定的时间限制保障,但是不要过度依赖这种特性。例如,VOIP 软件会使用软实时保障的协议传来送音视频信号,但是即便因为操作系统负载过高,而产生一点延迟,也不会造成很大影响。无论如何,软实时任务总会比普通任务的优先级更高。
Linux 中实时任务的优先级范围是 0~99,但是有趣的是,它和 nice 值的作用刚好相反,这里的优先级值越大,就意味着优先级越高。

类似其它的 Unix 系统,Linux 也是基于 POSIX 1b 标准定义的 「Real-time Extensions」实现实时优先级。可以通过如下的命令查看系统中的实时任务:
$ ps -eo pid, rtprio, cmd
也可通过 chrt -p pid 查看单个进程的详情。Linux 中可以通过 chrt -p prio pid 更改实时任务优先级。这里需要注意的是,如果操作的是一个系统进程(通常并不会将普通用户的进程设置为实时的),则必须有 root 权限才可以修改实时优先级。
内核视角下的进程优先级:
实时上,内核看到的任务优先级和用户看到的并不相同,在计算和管理优先级时也需要考虑很多方面。Linux 内核中使用 0~139 表示任务的优先级,并且,值越小,优先级越高(注意和用户空间的区别)。其中 0~99 保留给实时进程,100~139(映射成 nice 值就是 -20~19)保留给普通进程。

我们可以在 <include/linux/sched/prio.h> 头文件中看到内核表示进程优先级的单位(scale)和宏定义(macros),它们用来将用户空间优先级映射到到内核空间。
#define MAX_NICE 19#define MIN_NICE -20#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)…#define MAX_USER_RT_PRIO 100#define MAX_RT_PRIO MAX_USER_RT_PRIO#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)/** Convert user-nice values [ -20 ... ... 19 ]* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],* and back.*/#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)/** \'User priority\' is the nice value converted to something we* can work with better when scaling various scheduler parameters,* it\'s a [ 0 ... 39 ] range.*/#define USER_PRIO(p) ((p)-MAX_RT_PRIO)#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
优先级计算:
在 task_struct 中有几个字段用来表示进程优先级:
int prio, static_prio, normal_prio;unsigned int rt_priority;static_prio 是由用户或系统设定的「静态」优先级映射成内核表示的优先级:
p->static_prio = NICE_TO_PRIO(nice_value);normal_prio 存放的是基于 static_prio 和进程调度策略(实时或普通)决定的优先级,相同的静态优先级,在不同的调度策略下,得到的正常优先级是不同的。子进程在 fork 时,会继承父进程的 normal_prio。
prio 则是「动态优先级」,在某些场景下优先级会发生变动。一种场景就是,系统可以通过给某个任务优先级提升一段时间,从而抢占其它高优先级任务,一旦 static_prio 确定,prio 字段就可以通过下面的方式计算:
p->prio = effective_prio(p);// kernel/sched/core.c 中定义了计算方法static int effective_prio(struct task_struct *p){ p->normal_prio = normal_prio(p); /* * If we are RT tasks or we were boosted to RT priority, * keep the priority unchanged. Otherwise, update priority * to the normal priority: */ if (!rt_prio(p->prio)) return p->normal_prio; return p->prio;}
static inline int normal_prio(struct task_struct *p){ int prio; if (task_has_dl_policy(p)) prio = MAX_DL_PRIO-1; else if (task_has_rt_policy(p)) prio = MAX_RT_PRIO-1 - p->rt_priority; else prio = __normal_prio(p); return prio;}
static inline int __normal_prio(struct task_struct *p){ return p->static_prio;}
负载权重(Load Weights):优先级会让一些任务比别的任务更重要,因此也会获得更多的 CPU 使用时间。nice 值和时间片的比例关系是通过负载权重(Load Weights)进行维护的,我们可以在 task_struct->se.load 中看到进程的权重,定义如下:
struct sched_entity { struct load_weight load; /* for load-balancing */ …}struct load_weight { unsigned long weight; u32 inv_weight;};为了让 nice 值的变化反映到 CPU 时间变化片上更加合理,Linux 内核中定义了一个数组,用于映射 nice 值到权重:
static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15,};来看看如何使用上面的映射表,假设有两个优先级都是 0 的任务,每个都能获得 50% 的 CPU 时间(1024 / (1024 + 1024) = 0.5)。如果突然给其中的一个任务优先级提升了 1 (nice 值 -1)。此时,一个任务应该会获得额外 10% 左右的 CPU 时间,而另一个则会减少 10% CPU 时间。来看看计算结果:1277 / (1024 + 1277) ≈ 0.55,1024 / (1024 + 1277) ≈ 0.45,二者差距刚好在 10% 左右,符合预期。完整的计算函数定义在 <kernel/sched/core.c> 中:
static void set_load_weight(struct task_struct *p){ int prio = p->static_prio - MAX_RT_PRIO; struct load_weight *load = &p->se.load; /* * SCHED_IDLE tasks get minimal weight: */ if (p->policy == SCHED_IDLE) { load->weight = scale_load(WEIGHT_IDLEPRIO); load->inv_weight = WMULT_IDLEPRIO; return; } load->weight = scale_load(prio_to_weight[prio]); load->inv_weight = prio_to_wmult[prio];}
调度类 Scheduling Classes
虽说 Linux 内核使用的 C 语言并非所谓的 OOP 语言(没有类似 C++/Java 中的 class 概念),但是我们可以在内核代码中看到一些使用 C 语言结构体 + 函数指针(Hooks)的方式来模拟面向对象的方式,抽象行为和数据。调度类也是这样实现的(此外,还有 inode_operations, super_block_operations 等),它的定义如下(位于 <kernel/shced/sched.h>):
// 为了简单起见,隐藏了部分代码(如 SMP 相关的)struct sched_class { // 多个 sched_class 是链接在一起的 const struct sched_class *next; // 该 hook 会在任务进入可运行状态时调用。它会将调度单元(如一个任务)放到 // 队列中,同时递增 `nr_running` 变量(该变量表示运行队列中可运行的任务数) void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 会在任务不可运行时调用。它会将任务移出队列,同时递减 `nr_running` void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 可以在任务需要主动放弃 CPU 时调用,但是需要注意的是,它不会改变 // 任务的可运行状态,也就是说依然会在队列中等待下次调度。类似于先 dequeue_task, // 再 enqueue_task void (*yield_task) (struct rq *rq); // 该 hook 会在任务进入可运行状态时调用并检查是否需要抢占当前任务 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); // 该 hook 用来选择最适合运行的下一个任务 struct task_struct * (*pick_next_task) (struct rq *rq, struct task_struct *prev); // 该 hook 会在任务修改自身的调度类或者任务组时调用 void (*set_curr_task) (struct rq *rq); // 通常是在时钟中断时调用,可能会导致任务切换 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); // 当任务被 fork 时通知调度器 void (*task_fork) (struct task_struct *p); // 当任务挂掉时通知调度器 void (*task_dead) (struct task_struct *p);};关于调度策略的具体细节的实现有如下几个模块:
core.c包含调度器的核心部分;fair.c实现了 CFS(Comple Faire Scheduler,完全公平任务调度器) 调度器,应用于普通任务;rt.c实现了实时调度,应用于实时任务;idle_task.c当没有其它可运行的任务时,会运行空闲任务。
内核是基于任务的调度策略(SCHED_*)来决定使用何种调度类实现,并会调用相应的方法。SCHED_NORMAL,SCHED_BATCH和SCHED_IDLE进程会映射到fair_sched_class(由 CFS 实现);SCHED_RR和SCHED_FIFO则映射的rt_sched_class(实时调度器)。
运行队列 runqueue
所有可运行的任务是放在运行队列中的,并且等待 CPU 运行。每个 CPU 核心都有自己的运行队列,每个任务任意时刻只能处于其中一个队列中。在多处理器机器中,会有负载均衡策略,任务就会转移到其它 CPU 上运行的可能。
运行队列数据结构定义如下(位于 <kernel/sched/sched.h>):
// 为了简单起见,隐藏了部分代码(SMP 相关)// 这个是每个 CPU 都会有的一个任务运行队列struct rq{ // 表示当前队列中总共有多少个可运行的任务(包含所有的 sched class) unsigned int nr_running;#define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; // 运行队列负载记录 struct load_weight load; // 嵌套的 CFS 调度器运行队列 struct cfs_rq cfs; // 嵌套的实时任务调度器运行队列 struct rt_rq rt; // curr 指向当前正在运行的进程描述符 // idle 则指向空闲进程描述符(当没有其它可运行任务时,该任务才会启动) struct task_struct *curr, *idle; u64 clock; int cpu;}
何时运行调度器?
实时上,调度函数 schedule() 会在很多场景下被调用。有的是直接调用,有的则是隐式调用(通过设置 TIF_NEED_RESCHED 来提示操作系统尽快运行调度函数)。以下三个调度时机值得关注下:
-
时钟中断发生时,会调用 scheduler_tick() 函数,该函数会更新一些和调度有关的数据统计,并触发调度类的周期调度方法,从而间接地进行调度。以 2.6.39 源码为例,可能的调用链路如下:
scheduler_tick└── task_tick└── entity_tick└── check_preempt_tick└── resched_task└── set_tsk_need_resched
-
当前正在运行的任务进入睡眠状态。在这种情况下,任务会主动释放 CPU。通常情况下,该任务会因为等待指定的事件而睡眠,它可以将自己添加到等待队列,并启动循环检查期望的条件是否满足。在进入睡眠前,任务可以将自己的状态设置为 TASK_INTERRUPTABLE(除了任务要等待的事件可唤醒外,也可以被信号唤醒)或者 TASK_UNINTERRUPTABLE(自然是不会理会信号咯),然后调用 schedule() 选择下一个任务运行。
Linux 调度器
早期版本:
Linux 0.0.1 版本就已经有了一个简单的调度器,当然并非适合拥有特别多处理器的系统。该调度器只维护了一个全局的进程队列,每次都需要遍历该队列来寻找新的进程执行,而且对任务数量还有严格限制(NR_TASKS 在最初的版本中只有 32)。下面来看看这个调度器是如何实现的吧:
// \'schedule()\' is the scheduler function. // This is GOOD CODE! There probably won\'t be any reason to change // this, as it should work well in all circumstances (ie gives // IO-bound processes good response etc)...void schedule(void){ int i, next, c; struct task_struct **p; // 遍历所有任务,如果有信号,则需要唤醒 `TASK_INTERRUPTABLE` 的任务 for (p = &LAST_TASK; p > &FIRST_TASK; --p) if (*p) { if ((*p)->alarm && (*p)->alarm < jiffies) { (*p)->signal |= (1 << (SIGALRM - 1)); (*p)->alarm = ; } if ((*p)->signal && (*p)->state == TASK_INTERRUPTIBLE) (*p)->state = TASK_RUNNING; } while (1) { c = -1; next = ; i = NR_TASKS; p = &task[NR_TASKS]; // 遍历所有任务,找到时间片最长的那个 while (--i) { if (!*--p) continue; if ((*p)->state == TASK_RUNNING && (*p)->counter > c) c = (*p)->counter, next = i; } if (c) break; // 遍历任务,重新设值时间片 for (p = &LAST_TASK; p > &FIRST_TASK; --p) if (*p) (*p)->counter = ((*p)->counter >> 1) + (*p)->priority; } // 切换到下一个需要执行的任务 switch_to(next);}
O(n):
2.4 版本的 Linux 内核使用的调度算法非常简单和直接,由于每次在寻找下一个任务时需要遍历系统中所有的任务(链表),因此被称为 O(n) 调度器(时间复杂度)。
当然,该调度器要比 0.01 版本内核中的调度算法稍微复杂点,它引入了 epoch 概念。也就是将时间分成纪元(epochs),也就是每个进程的生命周期。理论上来说,每个纪元结束,每个进程都应该运行过一次了,而且通常用光了它当前的时间片。但实际上,有些任务并没有完全用完时间片,那么它剩余时间片的一半将会和新的时间片相加,从而在下一个纪元运行更长的时间。
我们来看下 schedule() 算法的核心源码:
// schedule() 算法会遍历所有的任务(O(N)),并且计算出每个任务的// goodness 值,且挑选出「最好」的任务来运行。// 以下是部分核心源码,主要是了解下它的思路。as以上是关于深入理解Linux Kernel调度器的身世之谜的主要内容,如果未能解决你的问题,请参考以下文章