曝肝三天,两千行Python代码,制作B站视频下载工具(附源码)
Posted python可乐编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了曝肝三天,两千行Python代码,制作B站视频下载工具(附源码)相关的知识,希望对你有一定的参考价值。
文章目录
一.准备工作
二.预览
- 1.启动
- 2.解析
- 3.下载中
- 4.下载完成
- 5.结果
三.设计流程
- 1.bilibili_video_spider
- 2.视频json的查找
四.源代码
- 1.Bilibili_Video_Downloader-GUI
- 2.bilibili_video_spider
五.总结
由于B站没有PC客户端,电脑下载视频很不方便,遂使用Tk编写一款B站视频下载工具,输入一个网址选择清晰度之后就能够下载对应的视频,可以下载单P、合集、合集单P,使用可视化GUI图形界面,交互性更强,来吧,展示~
很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。 很多已经做案例的人,却不知道如何去学习更加高深的知识。 那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码! QQ群:701698587 欢迎加入,一起讨论 一起学习!
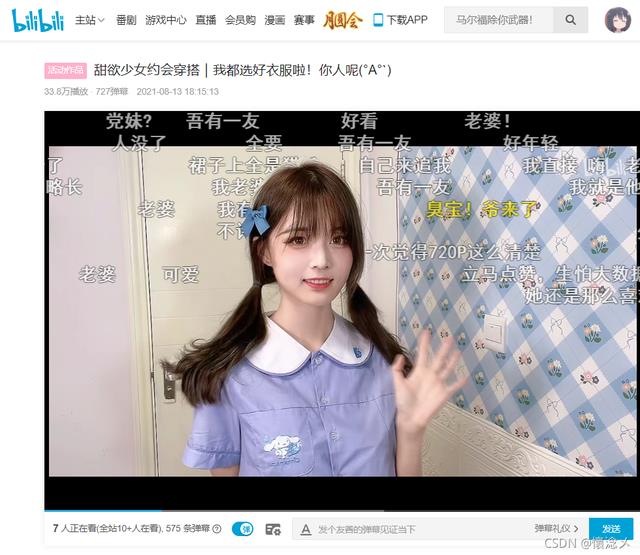
一.准备工作
tkinter、os系统模块、re正则模块、subprocess新的进程模块、还有本次比较重要的ffmpeg.exe用于视频和音频的合并,关于ffmpeg请参考:ffmpeg - 百度百科
二.预览
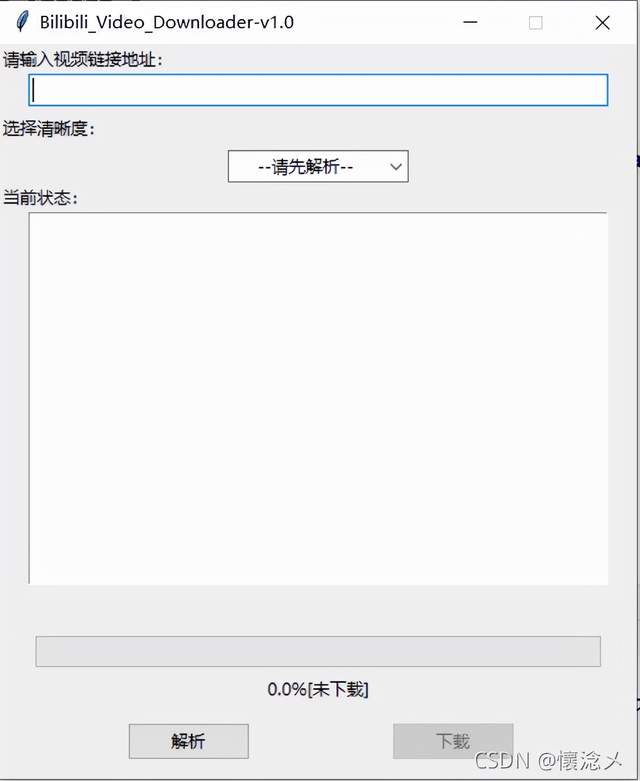
1.启动
2.解析
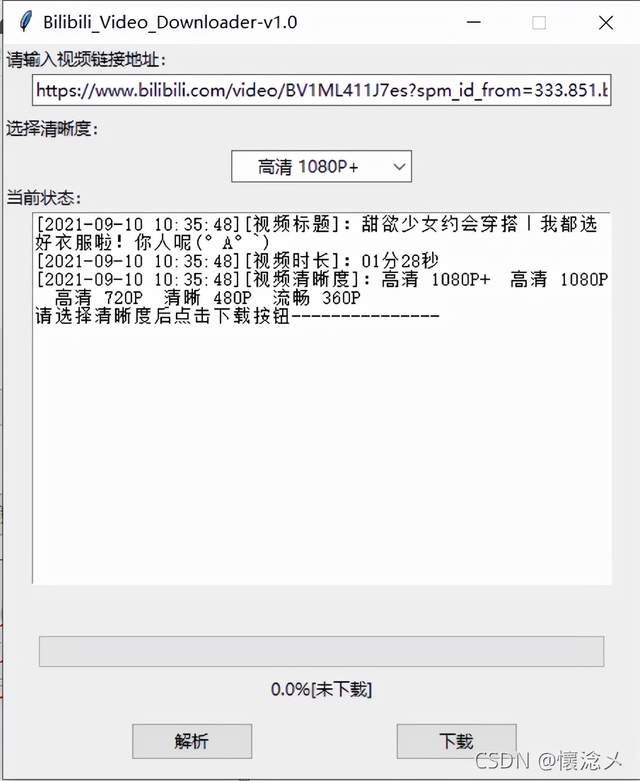
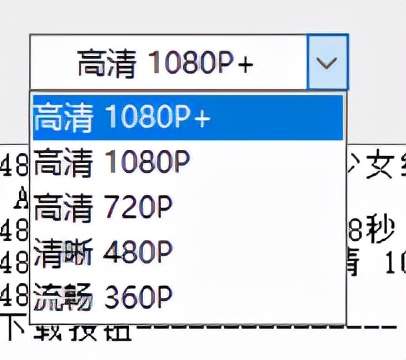
解析出多个清晰度视频以供下载
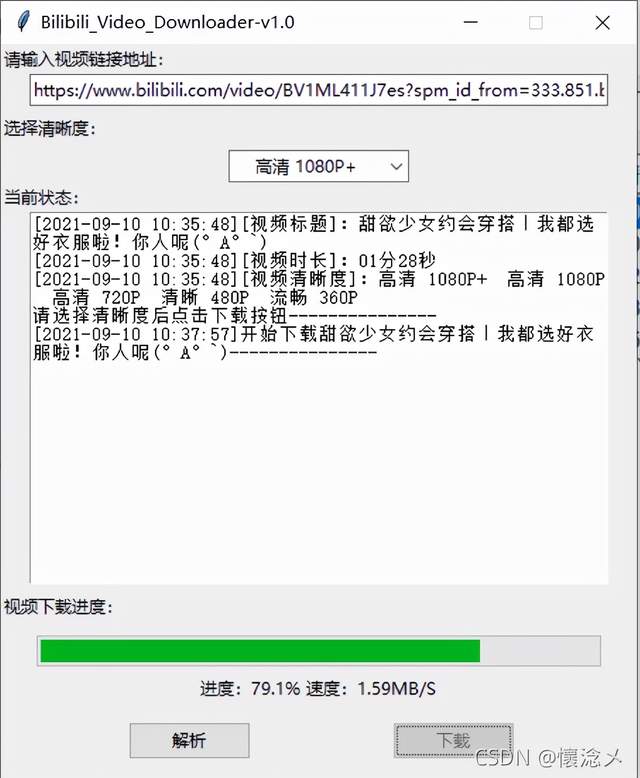
3.下载中
4.下载完成
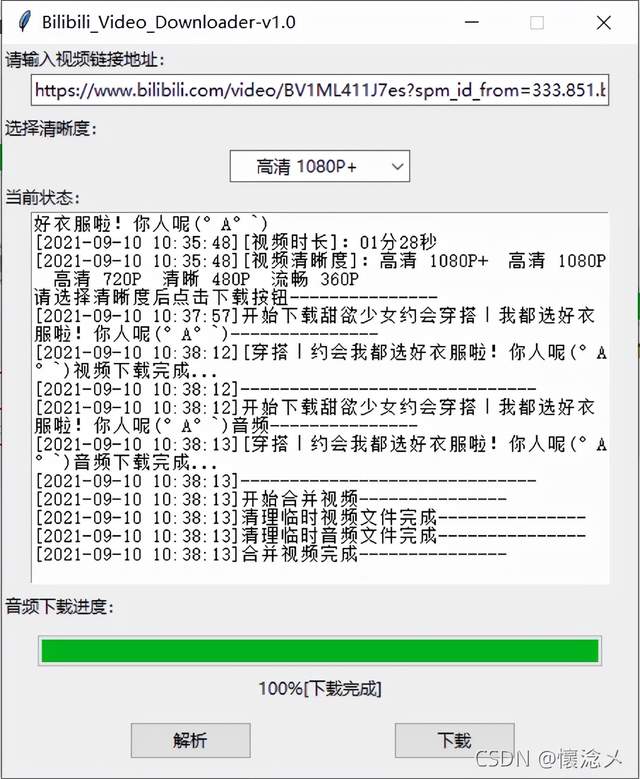
分别下载完视频和音频后,对它们进行合并,最后输出一个完整的视频文件
5.结果

1080P+,针不戳
三.设计流程
1.bilibili_video_spider
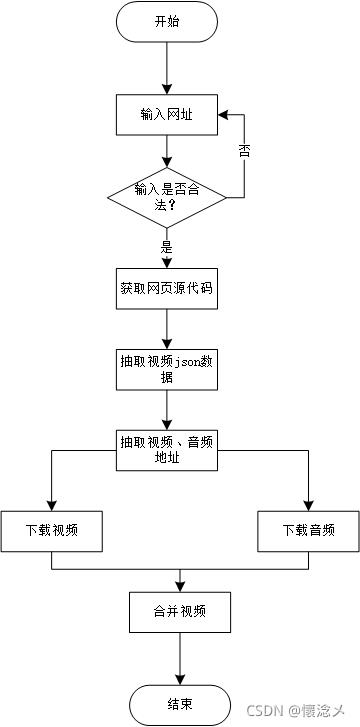
2.视频json的查找
- 首先查看网页源代码
- 在网页的这个js里,能够找到关于视频的相关视频、音频、视频质量、长度、格式…等信息,直接正则截取就好啦

紧接着,下面这个js里,就是视频的aid、分P信息、up主信息、相关视频推荐信息,也用正则就能截取

四.源代码
1.Bilibili_Video_Downloader-GUI
from tkinter import * from tkinter import ttk from tkinter import messagebox import os import threading from bilibili_video_spider import Bibili_Video_Spider as sp2 import re from my_util import My_Util """ GUI+Spider """ class App: def __init__(self): self.base_dir = \'./bilibili_videos/\' self.start_flag=\'\' self.has_more_flag=\'\' self.spider=sp2() self.create_widget() self.set_widget() self.place_widget() self.window.mainloop() def create_widget(self): self.window = Tk() self.window.title(\'Bilibili_Video_Downloader-v1.0\') width = 450 height = 520 screen_width = self.window.winfo_screenwidth() screen_height = self.window.winfo_screenheight() left = (screen_width - width) / 2 top = (screen_height - height) / 2 self.window.geometry("%dx%d+%d+%d" % (width, height, left, top)) self.window.resizable(0, 0) self.l1 = ttk.Label(self.window, text=\'请输入视频链接地址:\') self.e1_var=StringVar() self.e1 = ttk.Entry(self.window, width=90,textvariable=self.e1_var) self.l5 = ttk.Label(self.window, text=\'选择清晰度:\') self.combobox=ttk.Combobox(self.window,state=\'readonly\',width=15,justify=\'center\') self.l2 = ttk.Label(self.window, text=\'当前状态:\') self.t1 = Text(self.window, width=80, height=20) self.l3_var=StringVar() self.l3 = ttk.Label(self.window, text=\'当前下载进度:\',textvariable=self.l3_var) self.progress=ttk.Progressbar(self.window,orient=HORIZONTAL,length=400,mode=\'determinate\',value=0,maximum=100) self.l4_var = StringVar() self.l4_var.set(\'0.0%[未下载]\') self.l4 = ttk.Label(self.window, textvariable=self.l4_var) self.b1 = ttk.Button(self.window, text=\'解析\', command=lambda: self.thread_it(self.pre_analysis)) self.b2 = ttk.Button(self.window, text=\'下载\', command=lambda: self.thread_it(self.donwload_video)) def set_widget(self): self.window.protocol(\'WM_DELETE_WINDOW\', self.quit_window) self.window.bind(\'<Escape>\', self.escape) self.e1.bind(\'<Return>\', self.enter) self.b2.config(state=DISABLED) self.combobox.config(value=[\'--请先解析--\']) self.combobox.current(0) def place_widget(self): self.l1.pack(anchor="w") self.e1.pack(anchor="w", padx=20) self.l5.pack(anchor="w",pady=5) self.combobox.pack(anchor="center") self.l2.pack(anchor="w") self.t1.pack(anchor="w", padx=20) self.l3.pack(anchor="w",pady=5) self.progress.pack(pady=5) self.l4.pack() self.b1.pack(side=\'left\', padx=90) self.b2.pack(side=\'left\', padx=10) def pre_analysis(self): input_video_link = self.e1.get() input_video_link=input_video_link.strip() if input_video_link.startswith(r\'https://www.bilibili.com/video/\'): if \'&\' in input_video_link: raw_link=input_video_link.split(\'&\')[0] else: raw_link=input_video_link try: #av 转 bv av_number = int(re.findall(\'https://www.bilibili.com/video/av(\\d+)?\', raw_link)[0]) url=raw_link.replace(av_number,My_Util().av_convert_bv(av_number)) except IndexError: url=raw_link self.spider.set_start_url(url) self.spider.get_page_html() self.video_number = self.spider.get_video_number() base_title = self.spider.get_video_title() if re.match(\'https://www.bilibili.com/video/.*\\?p=\\d+\',url): current_num=re.findall(\'https://www.bilibili.com/video/.*\\?p=(\\d+)\',url) self.has_more_flag=True self.current_video_title=self.spider.part_name_list[int(current_num[0])] else: self.has_more_flag=False self.current_video_title=base_title self.entrace_url=url self.analysis_videos(url) if self.start_flag!=True: self.b2.config(state=NORMAL) # self.b1.config(state=DISABLED) else: messagebox.showwarning(\'警告\', \'请输入正确的分享链接!\') self.e1_var.set(\'\') def analysis_videos(self,url): """ :param url: :return: """ My_Util().do_makedirs(self.base_dir) self.video_item_ = self.spider.get_video_and_audio(self.spider.get_video_detail_json()) video_quality_list=[] for video_detail in self.video_item_[\'video_detail\']: for data in video_detail.items(): video_quality_list.append(data[0]) self.combobox.config(value=video_quality_list) self.combobox.current(0) self.t1.delete(0.0,END) self.insert_to_t1(f\'[视频标题]:{self.current_video_title}\') self.insert_to_t1(f\'[视频时长]:{self.video_item_["video_length"]}\') self.insert_to_t1(f\'[视频清晰度]:{" ".join(video_quality_list)}\') self.insert_to_t1(f\'请选择清晰度后点击下载按钮---------------\',time_str=False) def donwload_video(self): self.start_flag=True self.b2.config(state=DISABLED) if self.has_more_flag: ret = messagebox.askyesno(\'提示\', \'此视频包含多P,是否下载全集?\') if ret: download_more=True else: download_more=False else: download_more=False for i in range(self.video_number): if download_more: begin_url = self.entrace_url.split(\'?\')[0] + f\'?p={i+1}\' self.spider.video_title = self.spider.part_name_list[i] current_title=self.spider.part_name_list[i] else: begin_url=self.entrace_url self.spider.video_title = self.current_video_title current_title =self.current_video_title self.insert_to_t1(f\'开始下载{current_title}---------------\') self.l3_var.set(\'视频下载进度:\') self.spider.set_start_url(begin_url) video_item_ = self.spider.get_video_and_audio(self.spider.get_video_detail_json()) video_url_list=[] for video_detail in video_item_[\'video_detail\']: for data in video_detail.items(): video_url_list.append(data[1]) download_url = video_url_list[self.combobox.current()] current_video_name=self.spider.part_name_list[i] for progrees, speed in self.spider.down_video(download_url,): self.progress[\'value\'] = progrees self.l4_var.set(f\'进度:%.1f%% 速度:%s\' % (progrees, speed)) self.progress.update() self.insert_to_t1(f\'[{current_video_name}视频下载完成...\') self.l4_var.set(\'100%[下载完成]\') self.insert_to_t1(\'-\' * 30) audio_url = video_item_[\'audio_url\'] self.insert_to_t1(f\'开始下载{current_title}音频---------------\') self.l3_var.set(\'音频下载进度:\') for progrees, speed in self.spider.downlonad_autio(audio_url,): self.progress[\'value\'] = progrees self.l4_var.set(f\'进度:%.1f%% 速度:%s\' % (progrees, speed)) self.progress.update() self.insert_to_t1(f\'[{current_video_name}音频下载完成...\') self.l4_var.set(\'100%[下载完成]\') self.insert_to_t1(\'-\' * 30) self.insert_to_t1(f\'开始合并视频---------------\') if (self.spider.mix_video()): self.insert_to_t1(f\'清理临时视频文件完成---------------\') self.insert_to_t1(f\'清理临时音频文件完成---------------\') self.insert_to_t1(f\'合并视频完成---------------\') else: self.insert_to_t1(f\'发生了异常错误!---------------\') if not download_more: break self.b1.config(state=NORMAL) self.b2.config(state=NORMAL) def insert_to_t1(self,line,time_str=True): if time_str==True: time_string=My_Util().get_time_string() self.t1.insert(END,f\'[{time_string}]\'+line+\'\\n\') else: self.t1.insert(END,line+\'\\n\') self.t1.yview_moveto(1) def open_dir(self): abs_path = os.path.abspath(self.base_dir) # 使用绝对路径打开文件夹 os.startfile(abs_path) def quit_window(self): ret = messagebox.askyesno(\'提示\', \'是否要退出?\') if ret == True: self.window.destroy() def escape(self,event): self.quit_window() def connect_author(self): messagebox.showinfo(\'联系作者\', \'作者QQ:懷淰メ\') def enter(self,event): self.thread_it(self.pre_analysis) def thread_it(self,func, *args): t = threading.Thread(target=func, args=args) self.window.update() t.setDaemon(True) # 设置守护,主线程结束,子线程结束 t.start() if __name__ == \'__main__\': App() """ test https://www.bilibili.com/video/BV1ML411J7es """
2.bilibili_video_spider
import json import requests import re import os import subprocess from my_util import My_Util import time """ 版本2分别下载音频和视频,通过ffmpeg合并 三种情况 1.单P 2.多P下载单集 3.多P下载全集 """ class Bibili_Video_Spider(object): def __init__(self,): self.s=requests.session() self.headers={ \'Content-Range\': \'bytes 0-xxxxxx\', "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" } self.util=My_Util() def set_start_url(self,start_url): self.start_url=start_url self.get_page_html() def get_video_title(self): """ 起始视频标题,作为下载视频的目录名 :return: """ regx=\'name="keywords" content="(.*?),\' title=re.findall(regx,self.srart_html) title=title[0] return title def get_page_html(self): """ 获取网页源代码 :return: """ headers={ \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\', \'Content-Range\': \'bytes 0-xxxxxx\', \'Referer\': self.start_url } r=self.s.get(self.start_url,headers=headers) if r.status_code==200: r.encoding=\'utf-8\' self.srart_html=r.text def get_video_number(self): """ 是否含有多P,若含有分P,则将所有分P名字存入list :return: """ html_part = re.findall(\'window.__INITIAL_STATE__=(.*?)</script> <link rel="stylesheet"\', self.srart_html) part_json_str = html_part[0].split(\';(function(){var\')[0] part_json = json.loads(part_json_str.strip()) pages = part_json[\'videoData\'][\'pages\'] self.part_name_list = [part_name[\'part\'] for part_name in pages] if len(pages)!=1: part_number=len(pages) else: part_number=1 return part_number def get_video_detail_json(self): """ 获取视频详情json,里面包括视频m4a地址,以及audio音频,版本2主要依赖此Json :return: """ regx=\'window.__playinfo__=(.*?)</script><script>window.__INITIAL_STATE\' video_json_=re.findall(regx,self.srart_html) if video_json_: video_json=json.loads(video_json_[0]) return video_json def get_video_and_audio(self,page_json,): """ 获取视频的视频和音频,准备合并 :param page_json: :return: """ video_item={} video_data=[] data=page_json[\'data\'] video_definition_list = data.get(\'accept_description\') video_detail_=data.get(\'dash\').get(\'video\') video_link_list=[] for video_detail__ in video_detail_: video_url=video_detail__.get(\'baseUrl\') video_link_list.append(video_url) for v in zip(video_definition_list,video_link_list): item = {} item[v[0]]=v[1] video_data.append(item) video_item[\'video_length\']=self.util.Convert_Millis(page_json["data"][\'timelength\']) video_item[\'audio_url\'] = page_json["data"]["dash"]["audio"][0]["baseUrl"] video_item[\'video_detail\'] = video_data return video_item def down_video(self,video_url): """ 下载视频 :param video_url: :param number: 分P的索引从1开始 :return: """ start_time=time.time() headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\', \'Content-Range\': \'bytes 0-xxxxxx\', \'Referer\': self.start_url } #下载视频 r = self.s.get(video_url, stream=True, headers=headers) file_size=int(r.headers[\'Content-Length\']) count=0 with open(self.video_title+\'-temp.mp4\',\'wb\')as f: for chunk in r.iter_content(chunk_size=1024): f.write(chunk) count+=len(chunk) progress=float(count/file_size*100) speed = My_Util().format_size((count) / (time.time() - start_time)) + \'/S\' yield progress,speed def downlonad_autio(self,audio_url): start_time=time.time() headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\', \'Content-Range\': \'bytes 0-xxxxxx\', \'Referer\': self.start_url } r = self.s.get(audio_url, stream=True, headers=headers) file_size=int(r.headers[\'Content-Length\']) count=0 with open(self.video_title+\'-temp.aac\',\'wb\')as f: for chunk in r.iter_content(chunk_size=1024): f.write(chunk) count+=len(chunk) progress=float(count/file_size*100) speed = My_Util().format_size((count) / (time.time() - start_time)) + \'/S\' yield progress,speed def mix_video(self,): try: # print(f\'开始合并{self.video_title}...\') path = "ffmpeg.exe -i " + self.video_title + "-temp.mp4 -i " + self.video_title + "-temp.aac -vcodec copy -acodec copy " + self.video_title + ".mp4" subprocess.call(path, shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) os.remove(self.video_title + "-temp.mp4") # print(\'[清理临时视频文件完成]...\') os.remove(self.video_title + "-temp.aac") # print(\'[清理临时音频文件完成]...\') return True except : return False
五.总结
- 本次使用tkinter加ffmpeg实现了B站视频的下载,支持所选视频的所有画质的下载,tkinter完成GUI的搭建,实现交互,spider实现视频的解析与下载,ffmpeg实现视频与音频的合并,初步实现了B站视频的下载,当然这只是1.0版本,仍存在一些不足。
1.代码逻辑混乱,复用率不高。(因为是分几天写成的,可能一些想法找不到了)。
2.主要功能较少,GUI的优势没有明显凸显出来(当前的功能,打包成命令行也能轻易实现)。
3.视频下载到了一个目录,应当将带有分P的全集视频,新建目录后下载(这里确实有点吹毛求疵,毕竟是1.0)。
以上是关于曝肝三天,两千行Python代码,制作B站视频下载工具(附源码)的主要内容,如果未能解决你的问题,请参考以下文章