Java Case Interview two
Posted WhaleFall541
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java Case Interview two相关的知识,希望对你有一定的参考价值。
并发相关知识点
为什么使用线程池?线程池有哪些参数?
- 降低资源消耗
- 提高响应速度
- 提高线程的可管理性
corePoolSize 核心线程数 正常工作创建的线程数
maxinumPoolSize 最大线程数 表示最大允许被创建的线程。
keepAliveTime、unit 存活时间 心线程数之外的线程的空间存活时间。
workQueue 工作队列 用来存放待执行的任务
THreadFactory 线程工厂用来产生线程执行任务(可以使用默认的具有相同的优先级,且均不是守护线程也可以自定义)
handler 拒绝策略 当线程池关闭或者无法执行新的线程(最大线程数和队列都已满)
线程池执行流程:
- 判断核心线程是否都被占用
- 判断任务队列是否已满
- 是否达到最大线程数
- 拒绝策略
线程池中阻塞队列的作用?为什么先添加到工作队列,而不是创建最大线程?
作用
- 一般队列当任务数超出缓冲长度时,就无法保留,阻塞队列可以通过阻塞保留住当前 想要继续入队的任务。
- 没有任务时,可以阻塞获取任务的线程,使线程进入wait状态,释放CPU资源。
- 阻塞队列自带阻塞和唤醒功能
原因
- 在创建新线程的时候,要获取全局锁, 这个时候其他的就要阻塞,影像了整体的效率。
线程复用
线程池中每次执行任务不是调用Thread.start()方法,而是让线程执行一个循环任务,
在这个循环任务中不停的检查是否有任务需要执行,如果有调用线程的run()执行。
BeanFactory 和 ApplicationContext 有什么区别
-
ApplicatioinContext是BeanFactory子接口;
-
ApplicationContext扩展了BeanFactory:
- 继承MessageSource,支持国际化信息
- 继承ResourcePatternResolver,统一的资源文件访问方式
- 继承ApplicationEventPublisher,提供监听器中注册bean时间
- 同时加载多个配置文件;载入多个上下文,使得每一个上下文都专注于一个特定的层次。比如web层。
-
BeanFactory 采用的懒加载模式
-
ApplicationContext 在容器启动时一次创建所有非懒加载单例的bean
-
BeanFactory只能编程式创建,而ApplicationContext还能声明式创建,如使用ContextLoader
-
BeanFactory 和 ApplicationContext 都支持BeanPostProcessor, BeanFactoryPostProcessor的使用,
但是BeanFactory需要手动注册,而ApplicationContext则是自动注册
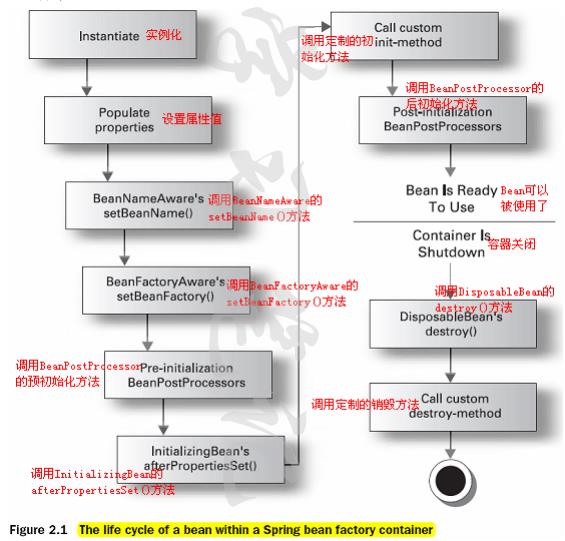
SpringBean 生命周期
- 实例化
- 设置属性autoware注入
- 设置实现Aware接口相关的属性
- 调用BeanPostProcessor的postProcessBeforeInitialization方法
(包括 BeanPostProcessor的 初始化前或者后方法 和 InitializingBean的 afterPropertiesSet方法) - 调用容器中该bean指定的init方法
- 调用BeanPostProcessor的postProcessAfterInitialization方法
- 使用bean
- 调用DisposableBean 的 destroy()方法
Spring中Bean支持的几种作用域
sigleton 默认,每一个容器只有一个Bean实例,单例模式由BeanFactory自身来维护。
prototype 为每一个bean请求提供一个实例,每次注入式都会创建一个新对象
request bean被定义为在每个HTTP请求中创建一个单例对象
session 确保每个session中有一个bean实例
application bean被定义为在ServletContext的生命周期中复用的一个单例对象
websocket bean被定义为在websocket生命周期中复用一个单例独享
global-session:全局作用
事务传播机制
REQUIRED 默认的事务传播类型,如果有事务则加入;没有则新建一个事务
SUPPORTS 如果有事务则加入;如果没有则以非事务方式执行
MANDATORY 当前存在事务,则加入事务;没有则抛出异常
REQUEST_NEW 有则挂起该事务;没有则创建一个事务;
NOT_SUPPORTED 有则挂起该事务;没有则以非事务方式执行
NERVER 不使用事务,如果存在事务则抛出异常
NESTED 有则嵌套事务中执行;否则开启一个事务
Note
- REQUEST_NEW 是开启一个事务,并且新开启的事务与事务无关
- NESTED 开启一个嵌套事务,父事务回滚,子事务必回滚;反之,
子事务回滚,父事务不一定回滚,可以catch吃掉异常。 - REQUIRED 要求调用方和被调用方使用同一事务
事务的基本特性和隔离级别
事务的基本特性ACID
atomiticy 一个事务中的操作要么全部失败,要么全部成功
consistency 在一个系统中,整体的资源保持最终一致
isolation 隔离性 指事务在提交前不可被其他事务读到
durability 事务提交后,所做的修改就会永久的保存到数据库中
隔离级别
Read Uncommit 未提交读,读到未提交的数据 脏读
Read Commit 提交读,读到提交后的数据 不可重复读(lock in share mode 共享锁来避免) Oracle默认级别
Read Repeatable 可重复读 每次读到的结果一样,一个事务开始读到就认定这个值,不管其他事务有没有该这条数据
但是如果是范围查询,可能查到的结果会变,这就造成幻读(加间隙锁避免)
serializable 串行,一般不会使用,会给每一行读到的数据加锁,影响并发
spring 事务什么时候失效
- 发生自调用,处理办法,不要自调用,使用注入对象调用
- 被
@Transactional修饰的方法不是public修饰符,如果要在非public上实现事务
可以使用AspectJ代理模式 - 数据库不支持事务
- 要开启事务方法的类未交给容器管理
- 异常被吃掉,事务不会回滚
Spring Boot、Spring MVC 和 Spring 有什么区别
Spring 是一个 IOC 容器用来管理Bean,使用依赖注入和控制反转,可以很方便的整合各种框架;
提供了AOP特性可以对日志,事务等功能从业务代码中剥离出来,集中管理。
Spring MVC 是 Spring 对Web框架的一个解决方案,提供了前段控制器Servlet,用来接收请求,
然后定义了一套路由策略(url->handler)以及适配执行hanle,将handle结果使用视图解析计数生
成视图展示给前端。
Spring Boot 是Spring提供的一个快速开发工具,让程序员快速使用Spring+Spring MVC。简化配置
(约定了默认配置),整合了一系列解决方案(Starter机制)、Redis、MongoDB、elasticsearch
Spring MVC工作流程
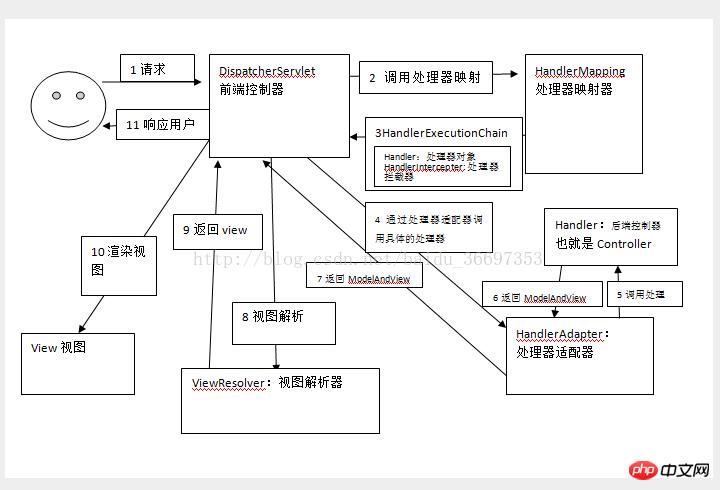
- 用户请求发往前端控制器 DispatcherServlet
- DispatcherServlet 调用处理器映射器 RequestMapping
- 处理映射器找到具体的处理器,和相关的拦截器组合成一个 HandlerExecutionChain
- DispatcherServlet 获取处理器适配器,并调用处理器适配器的 handle() 方法
并且返回ModelAndView给 DispatcherServlet - DispatcherServlet 将 ModelAndView 传给视图解析器 ViewResolver 进行解析
- 执行拦截器进行一些处理
- DispatcherServlet 返回 processedRequest, response, mappedHandler, mv, dispatchException
DispatcherServlet 中的方法
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request);
// Determine handler for the current request.
mappedHandler = getHandler(processedRequest);
if (mappedHandler == null) {
noHandlerFound(processedRequest, response);
return;
}
// Determine handler adapter for the current request.
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Process last-modified header, if supported by the handler.
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
}
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
// Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
}
catch (Exception ex) {
dispatchException = ex;
}
catch (Throwable err) {
// As of 4.3, we\'re processing Errors thrown from handler methods as well,
// making them available for @ExceptionHandler methods and other scenarios.
dispatchException = new NestedServletException("Handler dispatch failed", err);
}
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
}
catch (Exception ex) {
triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
}
catch (Throwable err) {
triggerAfterCompletion(processedRequest, response, mappedHandler,
new NestedServletException("Handler processing failed", err));
}
finally {
if (asyncManager.isConcurrentHandlingStarted()) {
// Instead of postHandle and afterCompletion
if (mappedHandler != null) {
mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
}
}
else {
// Clean up any resources used by a multipart request.
if (multipartRequestParsed) {
cleanupMultipart(processedRequest);
}
}
}
}
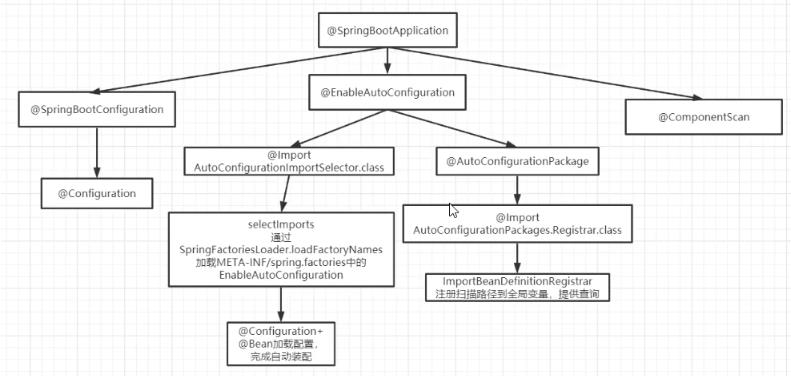
Spring Boot 自动配置原理
@improt 处理文件包路径
SPI SpringFactoriesLoader.loaderFactoryNames() 方法加载在 META-INF/spring.factories下配置的类
,PS:在此文件中添加jar包中相应的类,可以注入jar包中的类到容器中
@Configuration 指定该类为配置类
@Bean 在配置类中指定需要配置的类,并加载到容器中,比如redis,kafka配置类
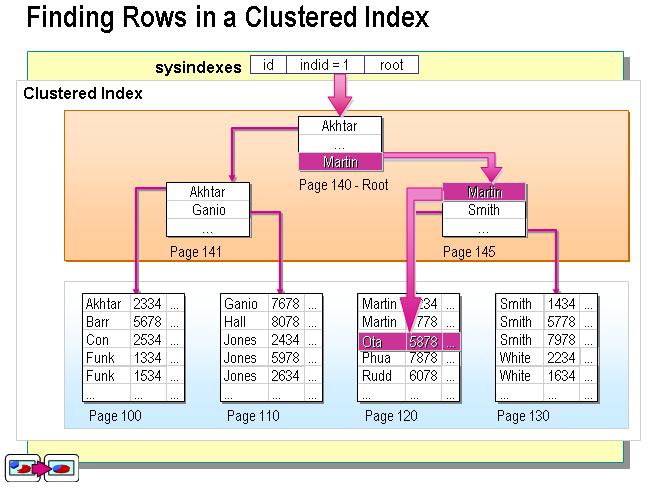
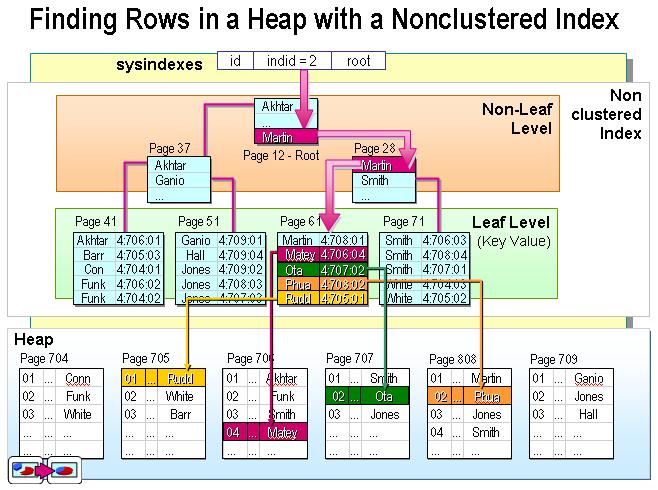
mysql 聚族索引和非聚族索引的区别
聚族索引 将数据和索引放到一块,并且按照一定的顺序排列
非聚族索引 叶子节点不放数据,存储数据的地址值
索引数据结构 B+ Tree Hash Index
MySql Select 时索引type
- const 通过索引一次命中,匹配一行数据
- system 表中只有一行数据,相当于系统表
- eq_ref 唯一性索引扫描,对于每个索引建,表中只有一条记录与之匹配
- ref 非唯一性索引扫描,返回匹配的某个值的所有
- range 只检索给定范围的行,使用一个索引来选择航 一般用于betweeen < >
- inedex 只遍历索引树
- all 全表扫描
MySQL 数据库锁
-
共享锁 读锁
-
排它锁 写锁
-
表锁 锁力度大 并发不好
-
行锁 锁力度大小 并发好 会出现死锁
-
记录锁
- 只锁表中的一行,精确条件命中,并且命中条件字段是唯一索引 可以避免重复度 脏读问题
-
页锁 会出现死锁
-
间隙锁 锁住表记录的某一个区间,左开右闭
-
临建锁 锁住表记录的某一个区间,左闭右闭
-
意向共享锁 当一个事务视图对整个表加共享锁之前,首先获得这个表的意向共享锁
-
意向排它锁 当一个事务视图对整个表加排他锁之前,首先获得这个表的意向排他锁
InnoDB 默认 行锁
MyISAM 默认 表锁
MVCC(Multi-Version Concurrency Control)
多版本并发控制 读取数据时通过一种类似快照的方式将数据保存下来,这样读锁和写锁不冲突了,不同的事务session 会看到自己特定版本的数据;
MVCC只在Read Commit 和 Read Repeatable 隔离级别下工作。其他两个隔离级别和MVCC不兼容,因为Read Uncommit总是读取到最新的数据,而不是符合当前事务版本的数据;而Serializable则对所有读取到的行都加锁
聚族索引中有 trx_id 和 roll_pointer 隐藏列
trx_id 类似于git版本控制中的hash码
roll_pointer 每次对哪条聚族索引记录有修改时,会把老版本写入undo日志中。roll_pointer存储了指向了聚族索引中上一个版本的位置。通过它可以获取上一个版本的信息。(insert 没有undo日志,因为)
RC RR 两种隔离级别中 生产ReadView区别
-
开始事务创建ReadView 维护未提交的事务,并将它们按事务id从小 到大放入一个数组中;
-
如果数据行中的事务id比数组中都要小,说明行数据对应的事务已经提交
-
如果数据行中的事务id比数组中都要大,说明行数据对应的事务未提交;获取 roll_pointer 拿到上一个版本的数据重新对比。
-
RC 每次查询都会生成一个独立的ReaView RR 每次都复用第一次生成的ReadView
MyISAM 和 InnoDB
MyISAM
不支持事务
支持表级锁
存储表的总行数
采用非聚族索引,索引文件的数据域存储指向数据文件的指针。辅助索引和主索引一致,但是辅助索引不保证唯一性
三个文件:索引文件 表结构文件 数据文件
InnoDB
支持ACID事务,支持事务的四种隔离级别
支持行级锁和外键约束
不存储表的总行数
主键采用聚族索引(索引的数据域存储数据文件本身),辅助索引的数据域存储主键的值;
最好使用自增逐渐,防止插入数据时,为维持B+树结构文件的调整过大
Redis 两中持久化方式的区别
RDB Redis Database
在指定时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,现将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
优点
- 整个Redis数据库质保函一个dump.rdb文件,容灾性好,方便备份
- 性能最大化,fork子进程来完成写操作,让主进程继续处理命令,使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证Redis的高性能
- 数据集比较大是,启动效率比AOF更高
缺点
- 数据安全性低,RDB间隔一段时间持久化,如果持久化间Redis发生故障,会发生数据丢失。
- 由于RDB是通过fork子进程来协助完成持久化工作,如果当数据集比较大时,可能会导致整个服务停止服务几百毫秒,甚至1秒钟
AOF Append Only File
优点
- 有三种同步策略 每秒同步、每修改同步、不同步
- 通过append 模式写文件,即使中途服务器宕机也不会破坏已经存在的内容,可以通过redis-check-aof工具解决数据一致性问题
- AOF 机制的rewrite模式。定期对AOF文件进行重写,已达到压缩的目的
缺点
- AOF文件比较大
- 数据集大的时候,启动效率低
- 运行效率没有RDB高
进程 线程
进程
静态概念 分配资源
进程时系统分配资源的基本单元
线程
动态概念 共享资源
主线程 第一个启动的是Main线程
线程是执行任务的基本单元
Redis 单线程为什么效率还那么高
Redis 基于Reactor 模型开发了文件事件处理器,这个文件事件处理器是单线程的,
它采用IO多路复用机制来同时监听多个Socket,根据Socket上的事件类型来选择对应的事件处理器来处理这个事件。
文件事件处理器结构: 多个Socket 、IO多路复用程序、文件事件分派器、事件处理器
并发时,IO多路复用监听程序会把Socket放入一个队列中,,每次从队列中取出一个Socket给事件分派器
,事件分派器把Socket交给对应的事件处理器;处理完一个Socket事件以后,IO多路复用程序才会将队列中
的下一个Socket给事件分派器。
可以参考这篇文章更详细
- Redis 基于内存操作
- 核心是基于非阻塞的IO多路复用机制
- 单线程反而避免了多线程频繁切换上下文带来性能的问题(每次操作事件较短)
缓存雪崩 、 缓存穿透、 缓存击穿
缓存雪崩 同一时间大量的缓存失效,后面请求量过大导致数据库崩掉
- 随机设置缓存数据的过期时间
- 给每个热点缓存数据增加标记,如果失效,自动更新
- 缓存预热,在应用启动时初始化热点数据到缓存中
缓存穿透 缓存数据和数据库中都没有数据,导致大量的请求到到了数据库,造成数据库负载过大。
- 接口层增加检验,比如用户鉴权,或者访问频率限制
- 从缓存和数据库都没有取到的数据,可以设置短时间的key-null值缓存
- 采用布隆过滤器,一定不存在的数据一定会被布隆过滤器拦截
缓存击穿 缓存中没有数据,数据库中有数据。缓存失效时,所有的请求压力都到数据库上了。
- 设置热点数据永不过期,修改之后动态更正缓存
- 加互斥锁
sql优化
- 尽量不要使用!= 、not in 、like \'%xxx\'
- 尽量使用in 而不是or,当值连续时,使用between而不是in
- 如果使用子查询,子查询会先执行,所以子查询里面要写小表的查询
- 联合索引 where条件中 要遵循最左原则
- sql语句最好全大写提高执行效率 执行引擎会把所有的小写转成大写
- FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。
- in 子查询中要写小表 exist 主查询要为小表 (小表驱动大表)
参考资料
- B站视频地址
- JDK 8 源码
以上是关于Java Case Interview two的主要内容,如果未能解决你的问题,请参考以下文章
Interview - Add two number - #2
leetcode mock interview-two sum II
Coursera Algorithms week2 基础排序 Interview Questions: 1 Intersection of two sets
Coursera Algorithms week2 栈和队列 Interview Questions: Queue with two stacks
spring bootmybatis启动报错:Consider defining a bean of type 'com.newhope.interview.dao.UserMapper&(代