大数据ETL处理时遇到的坑
Posted 为了2025的桂花
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据ETL处理时遇到的坑相关的知识,希望对你有一定的参考价值。
一、Sqoop导入时代码规范
import
--connect jdbc:mysql://bigdata113:3306/company
--username root
--password 000000
--table staff
--target-dir /user/company
--delete-target-dir
--num-mappers 1
--fields-terminated-by "\\t"
--hive-drop-import-delims
--null-string "\\\\N"
--null-non-string "\\\\N"
配置说明:
- --hive-drop-import-delims
在导入数据到hive时,去掉数据中的\\r\\n\\013\\010这样的字符。原因是,有很多字段所存储的数据比较复杂,包含回车换行等,如果不做任何处理导入到 hdfs 中,就会发现数据错乱等情况,所以我们在导入完数据后一定要查看一遍表的数据是否有问题。
- --null-string "\\N" --null-non-string "\\N"
这两个参数一般是连续使用,并且注意一定是双引号包含 \\N,作用就是让原来关系型数据库的表中String类型的字段,并且存储的数据是空值NULL的情况,到hdfs中也是以空值存储。如果不加这两个参数,就会存储字符串型的NULL或null,在查询的的时候不能用 is null来过滤,而是以 =="NULL" 或 =="null" 过滤。
二、Sqoop导出时代码规范
export
--connect jdbc:mysql://bigdata113:3306/Andy
--username root
--password 000000
--export-dir /user/hive/warehouse/staff_hive
--table aca
--num-mappers 1
--input-fields-terminated-by "\\t"
--hive-drop-import-delims
--input-null-string "\\\\N"
--input-null-non-string "\\\\N"
- --input-fields-terminated-by "\\t"
这个配置是指定导出数据的分隔符,特别需要注意的是,最好用双引号来包裹 \\t ,原因是在不同的执行命令窗口可能会发生导出失败的状况,比如说在Hue中的 Sqoop 执行命令文本框中运行,单引号是不行的。 null-string "\\N" 这个参数也是,虽然官方文档中写的也是单引号,但在某些命令窗口中执行代码是失败的。
三、在Hue中执行的Workflow时,编写Hive Sql脚本注意的点
- 脚本文件的编码格式和档案格式
我们在windows系统下编辑的 .sh 文件,需要把文件编码改成** utf-8-bom **格式,并且档案格式改成 Unix,并且多加两行回车,否则在直接上传文件后,Linux系统执行会出脚本时会出问题。
对此,我们可以直接在Hue中找到该文件,然后在Hue页面中编辑,然后保存,文件会自动变成Linux可以识别并可执行的文件。
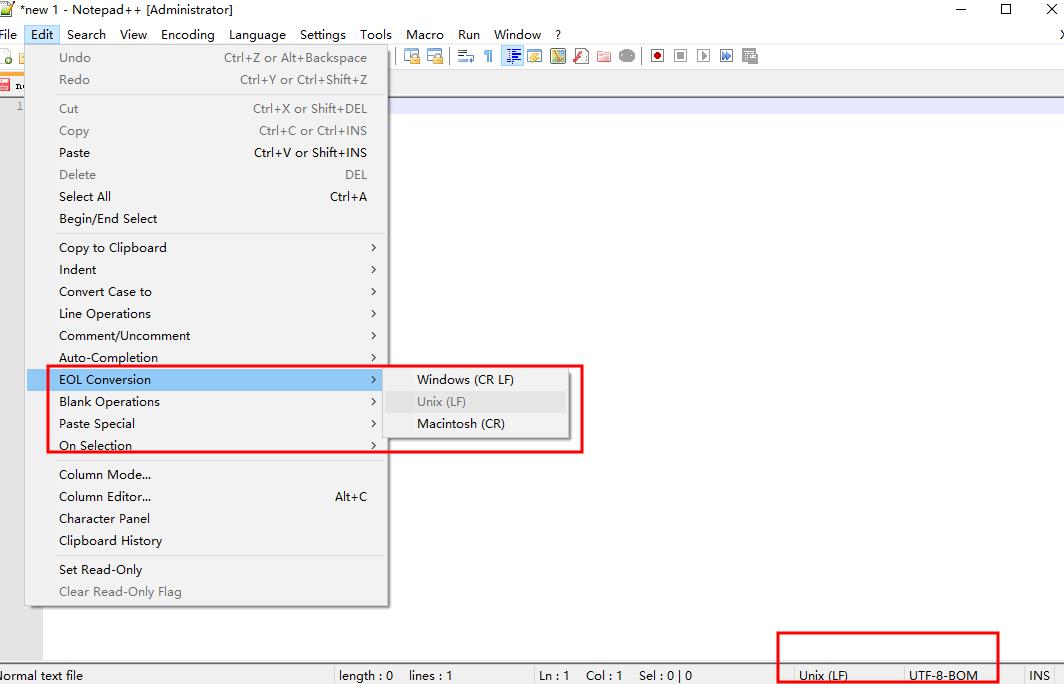
- 脚本中出现中文空格
还有一种情况,就是在脚本文件中出现中文空格的情况,执行脚本时也会报错。这种情况真的变态,去yarn里面查看日志,也找不到error信息。解决办法是,在Hue界面的 hive 执行命令窗口中把要执行的 Sql 给 Format 一下,然后再粘贴到文件中,这样中文空格就爱去掉了。
四、在Hue中的Schedule会突然反复执行
原因是,我们停止了原来提交的 Schedule 任务,假设它的提交时间是在上个月,所以它的开始执行时间也是在上个月。但由于某种原因要把它停掉,或者它自动停掉后,我们再次提交时,任务中里执行时间没有做修改依然写的是上个月,提交后它会以为之前都没跑过,然后疯狂补回来,所以接下来会不断反复的执行这个任务,所以我们再次提交时,对开始执行时间也要进行修改。
以上是关于大数据ETL处理时遇到的坑的主要内容,如果未能解决你的问题,请参考以下文章