5,Spark中文件格式压缩和序列化
Posted 平凡的神灯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5,Spark中文件格式压缩和序列化相关的知识,希望对你有一定的参考价值。
Spark中文件格式、压缩和序列化
1.1 文件格式
1.1.1 行存储:
特点:适合OLTP,写密集的场景(或是要求所有列的查询);
- text:spark直接读入并按行切分;需要保持一行的size在合理的范围;支持有限的schema;
- csv:常用于日志收集,写性能比读性能好,缺点是文件规范不够标准(例如分隔符、转义符、引号),对嵌套类型支持不足等;
- json:通常被当做一个结构体,需要注意key的数目(容易OOM),对schema支持不够好;优点是轻量、便于部署和debug;属于半结构化的文本结构;
1.1.2 列存储:
特点:适合OLAP,读密集的场景,可以列裁剪,压缩率高;
- parquet:
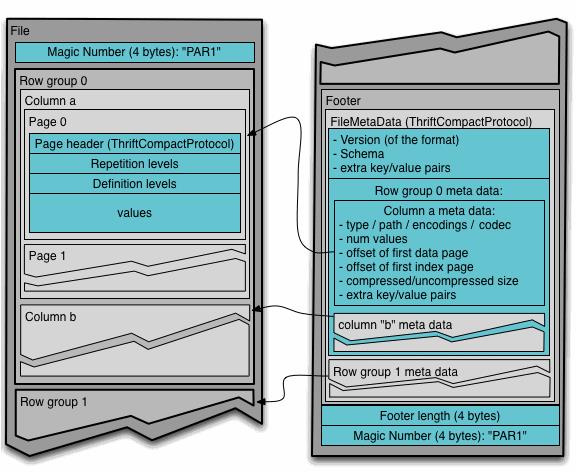
-
文件组织格式:首尾都有magic number校验这个是parquet文件;Footer放在文件末尾,存放了元数据信息,包括schema信息,以及以及每个row group的meta data和统计信息;row group(默认128M)是一批行数据的组成(例如0~1万行数据),row group中的每个column是一个列;一个列又分为多个page(默认1M)页,页是最小的编码单位;二进制存储;
-
谓词下推:parquet原生支持谓词下推;parquet每次扫描一个row group的数据,每个row group都是按列存储的,便可以只读取需要的column chunk列块,每个column chunk会生成统计信息(最大值、最小值、空值个数),通过这些统计信息和该列的过滤条件,可以判断该row group是否需要扫描;
-
应用:存储parquet文件时,通常会按照HDFS的Block大小设置row group的大小,因为MR和Spark在读取文件时一个task读取的最小单元就是一个Block,这样可以增大任务的并行度;相对于ORC格式,parquet对嵌套类型的支持更好,内部默认使用snappy压缩;但是压缩率、查询性能比ORC差一点点(有的测试比ORC要好),并且不支持update和acid,但是olap场景也不需要update和acid;常用于impala和spark;spark中row group大小为 parquet.block.size(默认128M,压缩后的),row group是一个切片的最小单位;page大小为parquet.page.size(默认1M,压缩后的),page是压缩和一次读取的最小单位;
-
spark和hive读取parquet:spark会使用自定义的serde来读取parquet文件(性能更高),如果读取异常,可以改用hive的serde来读取,将参数spark.sql.hive.convertMetastoreParquet(默认true)设为false即可;spark在处理时会缓存parquet的元数据信息,如果其他地方修改了,需要手动刷新;
-
结合压缩: parquet + snappy(lzo)的方式用的较多;这里要特别注意snappy压缩,如果用snappy对一个text文件压缩,那么这个文件是不可分割的,而使用snappy对parquet内部的page压缩,则内部压缩后的文件是可分割的,并且读取时是以row group为切片的;orc同理;parquet+snappy综合性能最高;spark中parquet的压缩格式是spark.sql.parquet.compression.codec(默认是snappy);
- ORC:
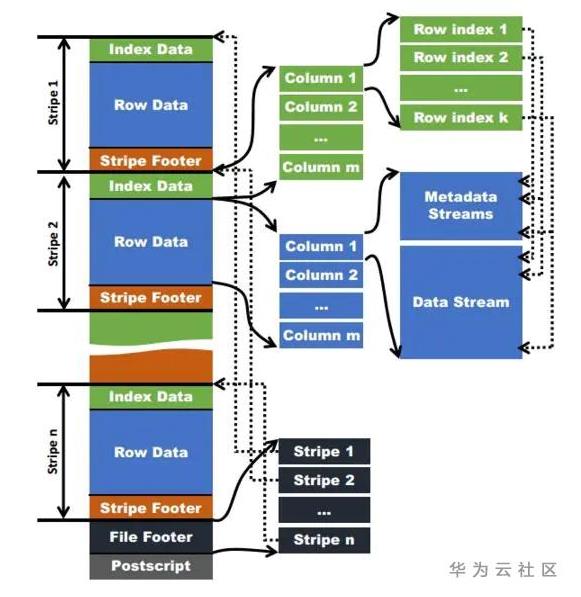
- 文件组织格式:与parquet类似,Postscript保存该表的行数、压缩参数等信息;File Footer保存各个stripe的位置信息,列的类型,以及表的统计信息(最大值、最小值、行计数等);stripe条带(对应parquet的row group)大小为HDFS的Block大小,其中分为三部分:stripe footer保存stripe位置,stripe的统计信息;row data就是具体的数据,由row group组成,一个row group默认1万行数据;index data保存每个row group的metadata stream具体位置;metadata stream保存了每一个row group在data stream中的位置和统计信息;
- 谓词下推:同样的ORC也支持列裁剪,并且ORC保存了三个层级的统计信息:file footer保存了文件级别的统计信息;stripe footer保存了stripe级别的统计信息;metadata stream中保存了row group级别的统计信息;例如某个stripe的max(a)=10, min(a)=3,当where a > 10或者where a<3时,那么这个stripe就可以跳过,不用读取;
- 应用:spark中ORC内部默认使用snappy压缩;支持数据update和acid,但是对嵌套类型支持不好;
1.2 文件压缩
1.2.1 spark默认支持的压缩格式
- snappy:压缩率22%,parquet格式可达到14%;不可分割;压缩解压速度特别快(250M/s~500M/s);parquet用;
- gzip:压缩率13.4%,parquet格式可达到6%;不可分割;压缩(17.5M/s),解压(58M/s)速度慢;大文件用;
- lzo:压缩率20.5%,可分割;压缩(49M/s),解压(74M/s)速度较快;支持分割,但是要建索引文件;
- lz4:spark2.2默认的压缩格式;不可分割;压缩率不好(30%?),但是压缩和解压速度非常快(400M/s~4000M/s),比gzip快一个量级,比snappy还快一点;spark2.2之前默认使用snappy压缩;
1.2.2 spark可压缩的地方
压缩格式:spark.io.compression.codec(默认lz4,spark2.2之前是snappy)
- rdd缓存(spark.rdd.compress默认false):由于rdd缓存到磁盘就是想用磁盘IO换取cpu计算;缓存到内存要考虑缓存的大小,要考虑内存gc问题;而使用压缩会增加cpu计算,所以默认是关闭的;如果磁盘IO或者gc成为问题且没有更好的解决方法,就可以考虑开启rdd缓存压缩,压缩后的数据量少了,对磁盘IO和gc都有提升;要启用rdd缓存压缩,存储级别就必须带序列化;
- 广播变量(spark.broadcast.compress默认true):广播是每个executor的第一个task启动时,获取一份广播数据,之后的task都从本地的BlockManager中获取;广播时有网络IO,并且要存储在本地的BlockManager中,所以默认是开启的;
- shuffle输出(spark.shuffle.compress默认true):shuffle最后输出的data文件压缩;要考虑CPU负载与IO负载(磁盘IO和网络IO),如果CPU负载影响远大于IO负载,则可以关闭该参数;
- shuffle溢写(spark.shuffle.spill.compress默认为true):shuffle溢写的中间文件压缩;由于中间溢写的文件不需要经过网络IO,并且需要在一个task中同时执行压缩和解压缩,对cpu负载较大;所以对于cpu负载较大,磁盘IO性能好的任务,可以考虑关闭该参数;
1.3 序列化格式
-
序列化的地方:广播变量、shuffle数据、缓存rdd(缓存级别带序列化SER)等;
-
Kryo序列化:Kryo序列化性能(大小和时间)是spark默认的java序列化的10倍(实际中可能3~6倍);但是Kryo需要注册自定义的类才能达到高性能,这也是spark默认没有选择Kryo的唯一原因;因为如果不注册自定义的类,Kryo需要为每一个对象保存它的全类名,这是非常浪费的;所以序列化大量没有注册的自定义对象时,序列化后的大小甚至会大于java序列化后的大小还大,但是序列化的时间还是优于java序列化的;
-
使用步骤:设置spark的序列化器,注册自定义类型;
val conf = new SparkConf()
// 设置序列化器为KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
以上是关于5,Spark中文件格式压缩和序列化的主要内容,如果未能解决你的问题,请参考以下文章