python中,如何将列表中的值,竖着存在csv文件中
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中,如何将列表中的值,竖着存在csv文件中相关的知识,希望对你有一定的参考价值。
参考技术A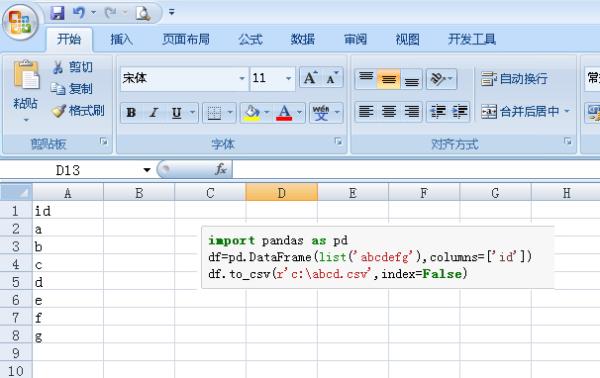
Python:将列表写入 Pandas 中的列
【中文标题】Python:将列表写入 Pandas 中的列【英文标题】:Python: Write a list to a column in Pandas 【发布时间】:2017-11-30 14:39:36 【问题描述】:我有两个列表,它们都包含我想要写入 csv 文件的值。所以我做的第一件事就是将我的 csv 文件导入到 pandas 数据框。然后我想写两个新列并将这两个列表添加到新列中。我的代码如下。请注意,原始 csv 文件已经存在一些列。
import pandas as pd
df = pd.read_csv('1.csv') ## 1.csv is the csv file I want to import.
a = [0.001, 5, 38, 70, 101, 140, 190]
b= [35, 65, 100, 160, 170, 200]
df['Start Time'] = a
df['End Time'] = b
df.to_csv('1.csv')
但是,当我运行这段代码时,它给了我一个错误,如下所示,
ValueError: Length of values does not match length of index
如果有人知道如何解决这个问题,请告诉我。赞赏!!
【问题讨论】:
我正在计算 a 中的 7 个值和 b 中的 6 个值。 【参考方案1】:我认为您需要先创建Series,但如果长度与DataFrame 的长度不同,则为df 中的所有最后一个值获取NaNs:
df['Start Time'] = pd.Series(a, index = df.index[:len(a)])
df['End Time'] = pd.Series(b, index = df.index[:len(b)])
示例:
df = pd.DataFrame('a':range(10))
a = [0.001, 9, 46, 84, 122, 153, 198]
b= [39, 76, 114, 150, 158, 210]
df['Start Time'] = pd.Series(a, index = df.index[:len(a)])
df['End Time'] = pd.Series(b, index = df.index[:len(b)])
print (df)
a Start Time End Time
0 0 0.001 39.0
1 1 9.000 76.0
2 2 46.000 114.0
3 3 84.000 150.0
4 4 122.000 158.0
5 5 153.000 210.0
6 6 198.000 NaN
7 7 NaN NaN
8 8 NaN NaN
9 9 NaN NaN
【讨论】:
我试过了,它确实有效。但它也为 csv 文件提供了 2 个新的“未命名”列,我认为这是它们的索引。您能否分享如何在不将索引写入文件的情况下添加它?谢谢!! 您需要df.to_csv('new.csv', index=False) 吗?
我明白了,是的,它有效!最后一个问题是我的 csv 文件中还有一些空白列。但是,当我运行它时,它给这些列的第一行一个“未命名”的单词。你能分享一下如何做到这一点不会发生吗?谢谢!!
那么如果使用print (df.columns.tolist()) 得到未命名的列名?
当我在括号中输入“未命名”时,它给了我一个错误“tolist() 需要 1 个位置参数但给出了 2 个”?也很抱歉,我也想提一个先前的问题。我确实想摆脱那些索引,但我想只剩下一个。有什么办法吗?我能想到的就是再次做一个枚举方法,但有没有更简单的方法?【参考方案2】:
您也可以尝试将 a 和 b 的数据类型更改为字符串。这样,NAN 值将留空。
import pandas as pd
df = pd.read_csv('1.csv') ## 1.csv is the csv file I want to import.
a = [0.001, 5, 38, 70, 101, 140, 190]
b = [35, 65, 100, 160, 170, 200]
df['Start Time'] = str(a)
df['End Time'] = str(b)
df.to_csv('1.csv')
【讨论】:
以上是关于python中,如何将列表中的值,竖着存在csv文件中的主要内容,如果未能解决你的问题,请参考以下文章