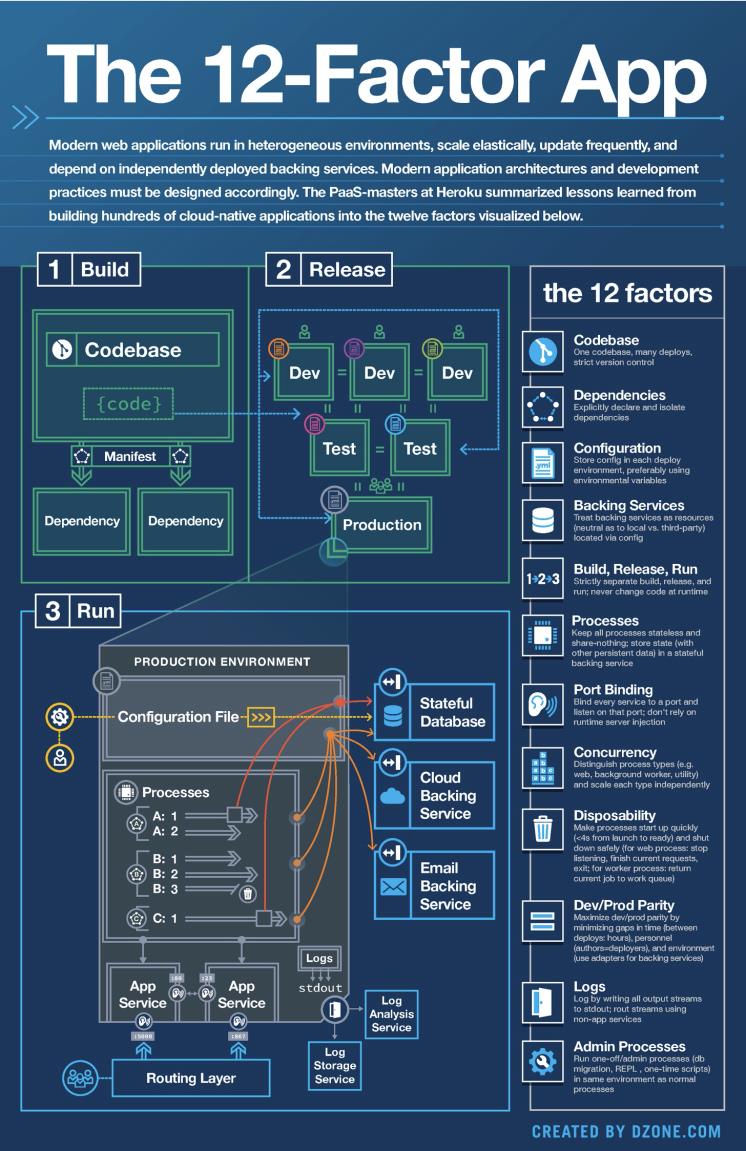
Kubernetes 作为容器的分布式编排调度系统,进一步提升了容器应用的可移植性。K8s 通过一系列抽象如 Loadbalance Service / Ingress / CNI / CSI,帮助业务应用可以屏蔽底层基础设施的实现差异,灵活迁移。通过这样的能力,我们可以实现工作负载在数据中心、边缘计算和云环境的动态迁移。 在应用架构中,我们需要避免将静态环境信息,比如 IP / mac 地址等与应用逻辑耦合。在微服务架构中,可以利用 Zookeeper/Nacos 等实现服务的注册发现;在 Kubernetes 中,我们可以通过 Service / Service Mesh 减少对服务端点 IP 的依赖。此外,对应用状态的持久化也尽可能通过分布式存储或者云服务等实现,这样可以大大提升应用架构可伸缩性和自愈能力。
根据”墨菲定律“ — “Anything that can go wrong will go wrong”。分布式系统可能受到硬件、软件等因素、或者内部和外部的人为破坏。云计算比自建数据中心提供了更高 SLA、更加安全的基础设施,但是我们在应用架构设计时依然要时刻关注系统的可用性,关注潜在的”黑天鹅“风险。 系统化的稳定性需要在软件架构,运维体系和组织保障等方面全局考虑。在架构层面,阿里经济体有着非常丰富的经验,比如防御式设计、限流、降级、故障隔离等,而且也向社区贡献了 Sentinel、ChaosBlade 等优秀的开源项目。 本文,我们将会谈谈几个在云原生时代可以进一步思考的地方。个人的总结是 “Failures can and will happen, anytime, anywhere. Fail fast, fail small, fail often and recover quickly.”
首先是“Failures can and will happen”,我们需要提升服务器的可替换性。在业界有一个非常流行的隐喻:“Pets vs. Cattle”,宠物和家畜。我们面对一个架构选择:对于应用所在服务器我们是需要精心伺候,防止系统宕机,出现问题后不惜一切代价抢救 (Pet);还是倾向于出现问题后,可以通过简单抛弃和替代进行恢复(Cattle)。云原生架构的建议是:允许失败发生,确保每个服务器,每个组件都能够在不影响系统的情况下发生故障并且具备自愈和可替代能力。这个设计原则的基础是应用配置和持久化状态与具体运行环境的解耦。Kubernetes 的自动化运维体系让服务器的可替换性变得更加简单。 此外是 “Fail fast, fail small, recover quickly” 。立即失效(Fail fast)是一个非常反直觉的设计原则,它背后的哲学是既然故障无法避免,问题越及早暴露、应用越容易恢复,进入生产环境的问题就越少。采用了 Fail-fast 策略以后,我们的关注点将从如何穷尽系统中的问题转移到如何快速地发现和优雅处理失败。只要跑的够快,故障就追不上我。:-) 在研发流程上,通过集成测试尽可能在早期发现应用存在的问题。在应用级别,可以采用断路器(Circuit Breaker)等模式防止一个依赖服务的局部故障引起全局问题;此外通过 K8s 的健康监测、可观测性可以实现对应用故障的探知,通过服务网格的断路器功能,可以将故障发现、流量切换和快速自愈这些能力外置到应用实现之外,由系统能力保障。Fail small 的本质在于控制故障的影响范围——爆炸半径。这个原则在架构设计和服务设计上都需要我们持续关注。 最后是“Fail often”,混沌工程是一种在生产环境周期性引入故障变量,验证系统对非预期故障防御的有效性的思想。Netflix 引入混沌工程概念解决微服务架构的稳定性挑战,也得到了众多互联网公司的广泛应用。在云原生时代又有了更多新的手段,Kubernetes 让我们可以轻松注入故障,杀死 pod,模拟应用失效和自愈过程。利用服务网格我们可以对服务间流量进行更加复杂的故障注入,比如 Istio 可以模拟缓慢响应、服务调用失败等故障场景,帮助我们验证服务间的耦合性,提升系统的稳定性。
为了解决上述挑战,社区提出了 Service Mesh(服务网格)架构,它将业务逻辑与服务治理能力解耦。下沉到基础设施,在服务的消费者和提供者两侧以独立进程的方式部署。这样既达到了去中心化的目的,保障了系统的可伸缩性;也实现了服务治理和业务逻辑的解耦,二者可以独立演进不相互干扰,提升了整体架构演进的灵活性;同时服务网格架构减少了对业务逻辑的侵入性,降低了多语言支持的复杂性。 Google、IBM、Lyft 主导发起的 Istio 项目就是服务网格架构的一个典型的实现,也成为了新的现象级“网红”项目。 上图是 Istio 的架构,逻辑上分为数据平面和控制平面。数据平面负责服务之间的数据通信。应用和以 sidecar 方式部署的智能代理 Envoy 成对出现。其中由 Envoy 负责截获和转发应用网络流量,收集遥测数据并且执行服务治理策略。在最新的架构中, istiod 作为控制平面中负责配置的管理、下发、证书管理等。Istio 提供了一系列通用服务治理能力,比如:服务发现和负载均衡、渐进式交付(灰度发布)、混沌注入与分析、全链路追踪和零信任网络安全等。可以供上层业务系统将其编排到自己的 IT 架构和发布系统之中。 服务网格在架构上实现了数据平面与控制平面的分离,这是一个非常优雅的架构选择。企业客户对数据平面有着多样化的需求,比如支持等多样化协议(如 Dubbo),需要定制化的安全策略和可观测性接入等。服务控制平面的能力也是快速变化的,比如从基础的服务治理到可观测性,再到安全体系、稳定性保障等等。但是控制平面与数据平面之间的 API 是相对稳定的。 CNCF 建立了通用数据平面 API 工作组(Universal Data Plane API Working Group / UDPA-WG),以制定数据平面的标准 API。通用数据平面 API(UDPA)的目标是:为 L4/L7 数据平面配置提供实现无关的标准化 API,类似于 OpenFlow 在 SDN 中对 L2/L3/L4 所扮演的角色。UDPA API 涵盖服务发现、负载均衡、路由发现、监听器配置、安全发现、负载报告、运行状况检查委托等。 UDPA API 基于现有的 Envoy xDS API 逐步演进,目前除支持 Envoy 之外,将支持客户端负载均衡实现 (比如 gRPC-LB),更多数据平面代理,硬件负载均衡和移动客户端等等。 我们知道 Service Mesh 不是银弹,其架构选择是通过增加一个服务代理来换取架构的灵活性和系统的可演化性,但是也增加了部署复杂性(sidecar 管理)和性能损失(增加两跳)。UDPA 的标准化和发展将给服务网格架构带来的新一次变化。 gRPC 在最新版本中提供了对 UDPA 负载均衡的。 “proxyless” 服务网格概念浮出水面,一个概念示意图如下: gRPC 应用直接从控制平面获取服务治理的策略, gPRC 应用之间直接通信无需额外代理。这个可以看到开放的服务网格技术的雄心,进化成为一套跨语言的服务治理框架,可以兼顾标准化、灵活性与运行效率。Google 的托管服务网格产品已经率先提供了对 “proxyless” gRPC 应用的支持。
2. 新一代分布式应用运行时
对于分布式应用,Bilgin Ibryam 在
文中分析并总结了典型的四大类需求:
生命周期(Lifecycle)
网络(Networking)
状态(State)
捆绑(Binding)
熟悉传统企业架构的同学可能发现,传统的 Java EE (现在改名为 Jakarta EE )应用服务器的目标也是解决类似的问题。一个典型 Java EE 应用服务器的架构如下图所示:应用生命周期由各种应用容器管理,如 Web 容器、EJB 容器等。应用的安全管理、事务管理、连接池管理都是交给应用服务器完成。应用可以通过 JDBC 、JMS 等标准 API 接口访问外部的企业中间件,如数据库、消息队列等。 不同的外部中间件通过 Java Connector Architecture 规范实现与应用服务器的插拔。应用通过 JNDI 在运行时实现与具体资源的动态绑定。Java EE 将系统的 cross-cutting concern下沉到应用服务器来解决,让开发者只关注应用的业务逻辑,开发效率有了较好的提升;同时减轻应用对环境和中间件实现的依赖,比如可以在开发环境中用 ActiveMQ ,在生产环境中使用 IBM MQ 替换,而无需修改应用逻辑。 在架构上,Java EE 是一个大的单体应用平台,拖慢了自身架构迭代的速度,跟不上时代的变化。由于 Java EE 过于复杂、沉重,在微服务兴起之后已经被大多数开发者所遗忘。
Serverless 具备很多优势, 比如:降低运维成本,提升系统安全性,提升研发效率,加速业务交付等等。然而 Serverless 还有一些不能回避的问题需要我们来做判断: 成本管理:对于“Pay as you go”的收费模式的一个弱点是:无法准确预测具体会产生多少费用,这于许多组织预算管理的方式不同。 厂商锁定:即使 Serverless 应用基于开放的语言和框架,但是多数Serverless应用还依赖一些非标准化的 BaaS(Backend as a Service)服务,如对象储存、Key- Value 数据库、认证、日志、和监控等。 调试和监控:与传统应用开发相比, Serverless 应用的调试与监控工具能力还不完善。良好的可观测性是将 Serverless 计算的重要助力。 架构复杂性:Serverless 开发者无需关注底层基础设施的复杂性,但是应用架构的复杂性需要格外关注。事件驱动架构和细粒度函数微服务,与传统开发模式非常不同。大家需要根据业务需求和自己的技术能力,在合适的场景应用,然后逐渐扩大应用范围。