Faiss使用多线程出现的性能问题
Posted ~victor~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Faiss使用多线程出现的性能问题相关的知识,希望对你有一定的参考价值。
Faiss使用多线程出现的性能问题
faiss在增加CPU的情况下,反而出现效率低下的问题。
从理论上看,作为一个CPU/GPU计算型的应用,更多的核意味着更大的计算吞吐能力,性能只会越来越好才是。
在实际过程中,通过taskset命令分配更多的核给faiss只会带来更长响应时间以及更大的响应时间偏差(variation)。
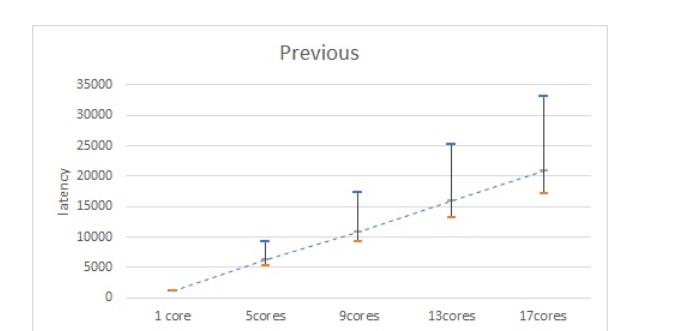
faiss的主要流程:建库(train)、校验(sanity check)、搜索。
由于建库是一次性操作,就不考虑建库带来的影响。对校验分析,也没有发现需要耗时太多的时间,那么主要问题就在搜索上面。
对于”核心越多,性能越差”的奇怪表现,搜索阶段又分两个部分,一个是quantizer,一个是search_preassigned。考虑应该跟线程的计算有关,于是将nprobe值和batch设置强置为1,从算法上保证search_preassigned只能用单核单线程。结果发现多核cpu依然满载。
那么直接用perf top命令查看系统调用栈。发现在多核、单线程的模式下占比最高的居然是libgomp,而真正的benchmark(6-IVFPQ)只占了很少的CPU资源。
这就是核心的问题了:
- Faiss的多核心是通过openMP实现的。
- 默认OMP_NUM_THREADS等于所有可用的CPU数,即OpenMP默认将会在启动与核心数相同的线程数作为线程池。
- 默认情况下,openmp假定所有的调用都是计算密集型的。为了减少线程启动/唤醒过程需要上下文开销,系统必须时刻保证每一个线程都是alive状态。换句话说,要让线程活着,OpenMP会让线程池的每个线程做大量的无意义计算占据时间片而不是wait挂起。
- quantizer 的过程中系统启动了omp线程池,理论上在修改后的search_preassigned开始后,线程池已经没有任何意义。但在放任不管的情况下,系统的每个核心的CPU使用率都会被空白计算占据,理论上100%。主线程结束之前线程池不会自己销毁。
- 这个时候如果位于主线程上的search_preassigned函数需要执行,那就不得不与OMP线程池抢占CPU time。这就是核心越多性能越差的原因。而放大这个影响的原因是我们的测试程序经过了变态级别的优化之后导致OMP的线程维护开销远远大于任务的CPU开销(微秒级响应,少于0.1个最小上下文)。这个测试事实上成为了某种程度“系统调度时延”测量。这个结果恰恰反应了预期。
剩下的就是解这个问题了,那只要在合适的时候让线程池销毁所有线程就迎刃而解了。OpenMP的实现是基于编译器的,发现没有办法可以直接实现目的,只有两个对应的环境变量可以缓解:
- GOMP_SPINCOUNT=
omp线程经过了n个spin lock之后便被挂起。自然,n值越小就越早的挂起线程。 - OMP_WAIT_POLICY=PASSIVE 通过使用wait方法挂起 omp线程。对应的ACTIVE 意味着线程池中的线程始终处于活动状态——消耗大量的CPU。
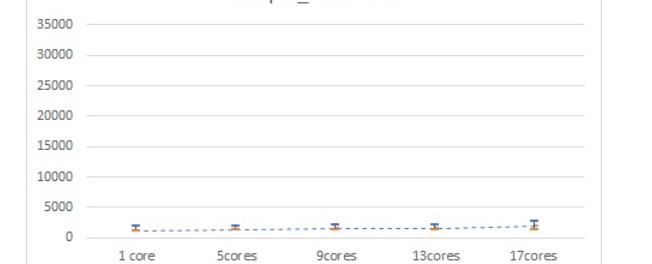
看上去效果还是不错的。
PS:并没有对所有情况进行测试,现在的结果指向是由于faiss依赖的openblat库中额外的omp线程池出现了问题导致主线程性能受到影响。理论上多线程也会如此,只是概率上导致看上去性能不是线性下降。
然后OMP_WAIT_POLICY的问题,主要是对在openmp下使用OpenBLAS的BLAS实现的时候起作用,此外,如果用了MKL库,一定条件下的MKL同样也会触发。
然后在faiss建立索引(train),也可能会出现这种情况,使用最新的faiss1.6.5及以后建立索引,CPU占用率明显有下降。
参考:http://www.litrin.net/2020/03/26/faiss的多线程效率问题/
https://www.cnblogs.com/yhzhou/p/10568728.html
https://www.cnblogs.com/yangyangcv/archive/2012/03/23/2413335.html
以上是关于Faiss使用多线程出现的性能问题的主要内容,如果未能解决你的问题,请参考以下文章