Object类中有哪些方法,分别有什么作用?
Posted 诺狗w
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Object类中有哪些方法,分别有什么作用?相关的知识,希望对你有一定的参考价值。
Object类中有哪些方法,分别有什么作用?
getClass
public final native Class<?> getClass();
这是一个 final 方法,我们在子类中无法覆写,通过调用这个方法可以得到实例对象所属类型对应的 Class 对象
hashCode
public native int hashCode();
这个方法算出来的哈希值是存放在对象头的 markword 中的(第一次调用时计算,后续不会再改动),哈希表工作时,就是根据对象的哈希值(再经过几步运算)来决定把这个对象放在哪个链表中,如果我们不覆写,那么是由一个 native 方法计算出,并且根据给定虚拟机参数的不同有不同的计算策略:
//通过"-XX:hashCode=4"可以设置hashCode方法的计算策略
//注意,有些策略是实验性的,要先通过"-XX:+UnlockExperimentalVMOptions"来允许使用这些策略
if (hashCode == 0) {
//一个随机数
value = os::random();
} else if (hashCode == 1) {
//在对象地址的基础上做一些运算
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom;
} else if (hashCode == 2) {
//固定值1
value = 1;
} else if (hashCode == 3) {
//一个自增的值
value = ++GVars.hcSequence;
} else if (hashCode == 4) {
//对象地址
value = cast_from_oop<intptr_t>(obj);
} else {
//JDK8默认的策略
//涉及四个数字,一个是和线程相关的随机数,另外三个是常量,经过运算后得出哈希值
unsigned t = Self->_hashStateX;
t ^= (t << 11);
Self->_hashStateX = Self->_hashStateY;
Self->_hashStateY = Self->_hashStateZ;
Self->_hashStateZ = Self->_hashStateW;
unsigned v = Self->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
Self->_hashStateW = v;
value = v;
}
equals
public boolean equals(Object obj) {
return (this == obj);
}
这个方法是用来比较两个对象是否相同的,我们可以在子类中覆写这个方法,从而让对象按照我们的想法来比较是否相同
对于基本数据类型,我们可以直接用 == 来判断值是否相同,而对于引用类型,用 == 比较的是两个对象的内存地址是否相同
观察 Object 类提供的 equals 方法的默认实现,可以发现就是调用了 ==,因此,如果我们不为子类覆写这个方法,那么无论用 == 还是 equals 方法其实比较的都是内存地址,如果我们想要自定义比较的方式,一定要覆写这个方法
此外,需要注意的是,如果我们覆写了 equals 方法,一般也要把 hashCode 方法一起覆写了,并且要满足两个准则:
- 如果两个对象的 equals 结果为 true,那么这两个对象的哈希值一定得相同(保证相同元素一定得在同一个链表里)
- 如果两个对象的哈希值相同,并不要求两个对象的 equals 结果一定为 true(因为同一个链表里的元素不一定相同)
如果两个方法都不覆写,其实天然就是满足这两个准则的:
- 如果 equals 返回 true,说明内存地址相同,也就是说这两个引用指向的其实是同一个对象,同一个对象的哈希值当然是一样的
- 如果哈希值相同,只能说明比较巧,因为默认的哈希算法是随机的,两个地址不同的对象算出同一个哈希值也不是不可能
试想,如果只覆写了 equals 方法,假如现在有 person1 和 person2 两个相同的对象(内存地址不同,但 equals 返回 true),我们先把 person1:999 放到哈希表中,理论上我们可以通过 person2 来 get 到 999,但实际上,由于 hashCode 方法还是使用的默认的随机数,因此 person1 和 person2 的哈希值大概率是不同的,因此 person1 可能会被放到 table[10] 的位置,而在根据 person2 查找的时候可能会到 table[3] 的地方去找,那肯定是找不到的,只有保证哈希值相同,那么在根据 person2 查找时才会也到 table[10] 的位置进行查找,这才满足了我们使用哈希表的本意
clone
protected native Object clone() throws CloneNotSupportedException;
首先,要是想让某个类的实例对象支持 clone 操作,需要让这个类继承 Cloneable 接口,并且覆写 clone 这个方法,最简单的一个实现是这样子的:
class Person implements Cloneable {
public String name;
public Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
但这样 clone 出来的对象有个问题,虽然这确实是两个对象(内存地址不同),但它们的 name 却还是同一个对象:
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person("chen", 20);
Person p2 = (Person) p1.clone();
//false
System.out.println(p1 == p2);
//true
System.out.println(p1.name == p2.name);
}
}
这其实就是一个浅拷贝,如果想要完成深拷贝,即想要让 clone 出来的对象的属性也是独一份的,此时 clone 方法就不能写那么简单了:
class Body implements Cloneable {
public Head head;
public Body(Head head) {
this.head = head;
}
@Override
protected Object clone() throws CloneNotSupportedException {
Body newBody = (Body) super.clone();
//属性也得是clone出来的
newBody.head = (Head) this.head.clone();
return newBody;
}
}
这里想要 clone 一个 Body 对象,如果按照之前写法,虽然能得到一个新的 Body 对象,但这两个对象的 Head 还是同一份,因此,我们需要在 Body 的 clone 方法中把 Head 也 clone 一份,并且交给新的 Body 对象,这样一来得到的 Body 对象就是一个深拷贝的结果了
但需要注意的是,这样写有两点要求:
- Head 这个类型也得实现了自己 clone 方法
- Head 这个类中不再有其它的引用属性,如果有,比如 Face 这个引用属性,那么就得按同样的道理让 Face 也实现 clone 方法,并在 Head 的 clone 中让这个 Face 也是 clone 出来的,否则这是一个不彻底的深拷贝
下面三张图依次展示了浅拷贝、深拷贝、不彻底的深拷贝:

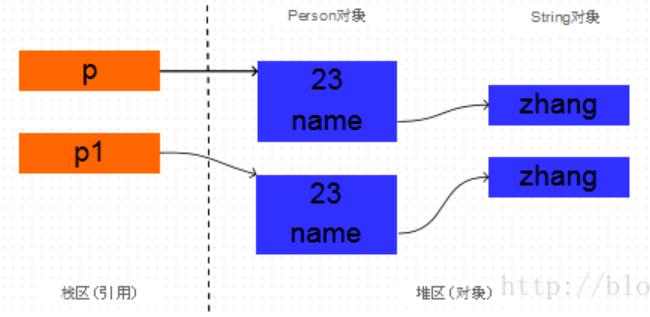

toString
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
把当前对象转变为一个字符串,在默认的实现中,这个字符串的内容为当前类的类名以及该实例对象的哈希值
大多数情况下我们都会对该方法进行覆写,从而转换为一个能体现出对象信息的字符串
wait
public final native void wait(long timeoutMillis) throws InterruptedException;
假如有多个线程在并发访问某个对象,现在线程 A 成功获取这个对象的锁,此时如果 A 执行了 wait 方法,就会让自己进入等待状态,并且释放对象的锁,让其它线程去竞争
注意,对于一个等待中的线程,就算对象的锁是空闲的,也不会去竞争,需要区别于阻塞状态,阻塞中的线程一旦发现对象的锁空闲就会去竞争
notify
public final native void notify();
还是前面的场景,现在线程 A B C 都处于等待状态,对象的锁在线程 D 手中,此时如果 D 执行了 notify 方法,就会随机唤醒一个等待中的线程,假如唤醒了 A,那么 A 就会从等待状态进入阻塞状态,在 D 释放锁之后,线程 A 会和阻塞中的其它线程一起竞争这个锁,但等待状态下的 B C 不会参与竞争
notifyAll
public final native void notifyAll();
notifyAll 和 notify 的唯一区别在于,notify 是随机唤醒一个等待中的线程,而 notifyAll 是唤醒所有等待中的线程,其它都是一样的
finalize
protected void finalize() throws Throwable { }
这个实例方法只有在以下三个条件都满足时才会触发:
- 在可达性分析中,垃圾收集器发现该对象与 GC Roots 不可达
- 该对象所属类覆写了 finalize 方法
- 该对象的 finalize 方法还未触发过
因此,这个实例方法是在对象将要被回收时才会触发的,理论上可以在这个方法里做两件事情:
- 对象自救,即在方法中重新把自己和某个引用联系起来,从而避免被回收
- 个人认为是一个比较鸡肋的功能
- 做一些资源的释放,比如文件流的关闭等等
- 虽然可以,但不可靠,因为虚拟机只会让这个方法开始执行,但不保证会等它执行完毕(以免占用太多时间,影响其它垃圾的回收工作),所以可能没等资源释放完虚拟机就不管了,因此,如果真的要释放资源的话还不如放在 finally 代码块中,没必要写在这个方法里
综上,finalize 是一个没什么用的方法,从 JDK9 开始这个方法也被标识为了 Deprecated,建议不要使用这个方法
学习过程中,部分内容参考了网上的文章,如有侵权必删
以上是关于Object类中有哪些方法,分别有什么作用?的主要内容,如果未能解决你的问题,请参考以下文章